
Heim >Technologie-Peripheriegeräte >KI >Sprechen Sie über die datenzentrierte KI hinter dem GPT-Modell
Sprechen Sie über die datenzentrierte KI hinter dem GPT-Modell

- 王林nach vorne
- 2023-04-11 23:55:011537Durchsuche
Künstliche Intelligenz (KI) macht große Fortschritte bei der Veränderung der Art und Weise, wie wir leben, arbeiten und mit Technologie interagieren. Ein Bereich, in dem in letzter Zeit erhebliche Fortschritte erzielt wurden, ist die Entwicklung großer Sprachmodelle (LLMs) wie GPT-3, ChatGPT und GPT-4. Diese Modelle können Aufgaben wie Sprachübersetzung, Textzusammenfassung und Beantwortung von Fragen genau ausführen.

Obwohl es schwer ist, die ständig wachsenden Modellgrößen von LLMs zu ignorieren, ist es auch wichtig zu erkennen, dass ihr Erfolg größtenteils auf den großen Mengen hochwertiger Daten beruht, die zu ihrer Schulung verwendet werden.
In diesem Artikel geben wir einen Überblick über die jüngsten Fortschritte im LLM aus einer datenzentrierten KI-Perspektive. Wir werden GPT-Modelle durch eine datenzentrierte KI-Linse untersuchen, ein wachsendes Konzept in der Data-Science-Community. Wir enthüllen die datenzentrierten KI-Konzepte hinter dem GPT-Modell, indem wir drei datenzentrierte KI-Ziele diskutieren: Trainingsdatenentwicklung, Inferenzdatenentwicklung und Datenpflege.
Large Language Model (LLM) und GPT-Modell
LLM ist ein natürliches Sprachverarbeitungsmodell, das darauf trainiert ist, Wörter im Kontext abzuleiten. Die grundlegendste Funktion von LLM besteht beispielsweise darin, fehlende Marker im gegebenen Kontext vorherzusagen. Zu diesem Zweck werden LLMs darauf trainiert, die Wahrscheinlichkeit jedes Kandidatenworts aus riesigen Datenmengen vorherzusagen. Die folgende Abbildung ist ein anschauliches Beispiel für die Verwendung von LLM im Kontext zur Vorhersage der Wahrscheinlichkeit fehlender Marker.

GPT-Modell bezieht sich auf eine Reihe von LLMs, die von OpenAI erstellt wurden, wie GPT-1, GPT-2, GPT-3, InstructGPT, ChatGPT/GPT-4 usw. Wie andere LLMs basiert die Architektur des GPT-Modells hauptsächlich auf Transformers, das Text- und Ortseinbettungen als Eingaben verwendet und Aufmerksamkeitsebenen verwendet, um die Beziehungen von Token zu modellieren.
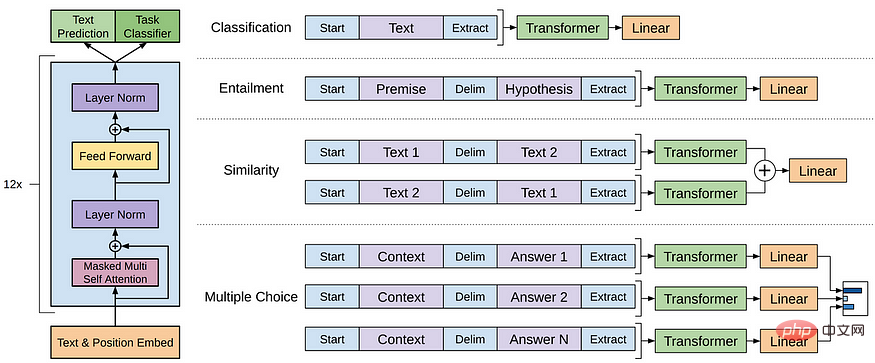
GPT-1-Modellarchitektur
Spätere GPT-Modelle verwenden eine ähnliche Architektur wie GPT-1, außer dass sie mehr Modellparameter und mehr Ebenen, eine größere Kontextlänge, versteckte Ebenengröße usw. verwenden.

Was ist datenzentrierte künstliche Intelligenz?
Datenzentrierte KI ist eine neue Denkweise zum Aufbau von KI-Systemen. Datenzentrierte KI ist die Disziplin der systematischen Gestaltung der Daten, die zum Aufbau künstlicher Intelligenzsysteme verwendet werden.
In der Vergangenheit haben wir uns hauptsächlich darauf konzentriert, bessere Modelle zu erstellen (modellzentrierte KI), wenn die Daten im Wesentlichen unverändert sind. Allerdings kann dieser Ansatz in der Praxis zu Problemen führen, da er verschiedene Probleme, die in den Daten auftreten können, wie Ungenauigkeiten bei der Beschriftung, Duplikate und Verzerrungen, nicht berücksichtigt. Daher führt eine „Überanpassung“ eines Datensatzes nicht unbedingt zu einem besseren Modellverhalten.
Im Gegensatz dazu konzentriert sich datenzentrierte KI auf die Verbesserung der Qualität und Quantität der Daten, die zum Aufbau von KI-Systemen verwendet werden. Das bedeutet, dass die Aufmerksamkeit auf den Daten selbst liegt und das Modell vergleichsweise fester ist. Die Verwendung eines datenzentrierten Ansatzes zur Entwicklung von KI-Systemen hat in realen Szenarien ein größeres Potenzial, da die für das Training verwendeten Daten letztendlich die maximalen Fähigkeiten des Modells bestimmen.
Es sollte beachtet werden, dass es einen grundlegenden Unterschied zwischen „datenzentriert“ und „datengesteuert“ gibt. Letzteres legt nur den Schwerpunkt auf die Verwendung von Daten zur Steuerung der Entwicklung künstlicher Intelligenz und konzentriert sich in der Regel immer noch auf die Entwicklung von Modellen und nicht auf Daten.

Vergleich zwischen datenzentrierter KI und modellzentrierter KI
Das datenzentrierte KI-Framework enthält drei Ziele:
- Trainingsdatenentwicklung ist die Sammlung und Produktion umfangreicher, qualitativ hochwertiger Daten zur Unterstützung des Trainings von Modellen für maschinelles Lernen. Bei der Entwicklung von Inferenzdaten geht es darum, neue Bewertungssätze zu erstellen, die detailliertere Einblicke in das Modell liefern oder durch Dateneingabe bestimmte Funktionen des Modells auslösen können.
- Datenpflege soll die Qualität und Zuverlässigkeit von Daten in einer dynamischen Umgebung sicherstellen. Die Datenpflege ist von entscheidender Bedeutung, da reale Daten nicht einmal erstellt werden, sondern eine fortlaufende Pflege erfordern.
 Warum datenzentrierte KI das GPT-Modell erfolgreich macht
Warum datenzentrierte KI das GPT-Modell erfolgreich macht
Vor ein paar Monaten twitterte Yann LeCun, dass ChatGPT nichts Neues sei. Tatsächlich sind alle in ChatGPT und GPT-4 verwendeten Techniken (Transformatoren, verstärkendes Lernen aus menschlichem Feedback usw.) überhaupt nicht neu. Sie erzielten jedoch Ergebnisse, die mit früheren Modellen nicht möglich waren. Was ist also der Grund für ihren Erfolg?
Trainingsdatenentwicklung.Die Menge und Qualität der zum Training von GPT-Modellen verwendeten Daten hat sich durch bessere Datenerfassung, Datenkennzeichnung und Datenaufbereitungsstrategien erheblich verbessert.
GPT-1:
BooksCorpus-Datensatz wird für das Training verwendet. Der Datensatz enthält 4629,00 MB Rohtext, der verschiedene Buchgenres wie Abenteuer, Fantasy und Liebesromane abdeckt.- -Datenzentrierte KI-Strategie: Keine.
– Ergebnisse: Die Verwendung von GPT-1 für diesen Datensatz verbessert die Leistung nachgelagerter Aufgaben durch Feinabstimmung.
GPT-2: Verwendung von WebText im Training. Dies ist ein interner Datensatz innerhalb von OpenAI, der durch das Scrapen ausgehender Links von Reddit erstellt wurde. - – Datenzentrierte KI-Strategie: (1) Kuratieren/filtern Sie Daten nur mit ausgehenden Links von Reddit, die mindestens 3 Karma verdienen. (2) Verwenden Sie die Tools Dragnet und Newspaper, um saubere Inhalte zu extrahieren. (3) Verwenden Sie Deduplizierung und andere heuristische Bereinigungen.
-Ergebnis: Ergibt nach dem Filtern 40 GB Text. GPT-2 erzielt robuste Zero-Shot-Ergebnisse ohne Feinabstimmung.
GPT-3: Das Training von GPT-3 basiert hauptsächlich auf Common Crawl. - -Datenzentrierte KI-Strategie: (1) Trainieren Sie einen Klassifikator, um Dokumente mit geringer Qualität basierend auf der Ähnlichkeit jedes Dokuments mit WebText (Dokumente mit hoher Qualität) herauszufiltern. (2) Verwenden Sie MinHashLSH von Spark, um Dokumente zu verschleiern und zu deduplizieren. (3) Datenerweiterung mit WebText, Buchkorpus und Wikipedia.
- Ergebnis: 45 TB Klartext gefiltert, um 570 GB Text zu erhalten (nur 1,27 % der Daten wurden für diese Qualitätsfilterung ausgewählt). GPT-3 übertrifft GPT-2 in der Null-Proben-Einstellung deutlich.
GPT anweisen: Lassen Sie die menschliche Bewertung die GPT-3-Antworten so anpassen, dass sie den menschlichen Erwartungen besser entsprechen. Sie entwickelten einen Test für Annotatoren, und nur diejenigen, die den Test bestanden, kamen für die Annotation in Frage. Sie haben sogar eine Umfrage entworfen, um sicherzustellen, dass die Annotatoren voll in den Annotationsprozess eingebunden sind. - -Datenzentrierte KI-Strategie: (1) Optimieren Sie das Modell durch überwachtes Training unter Verwendung von Antworten auf von Menschen bereitgestellte Eingabeaufforderungen. (2) Sammeln Sie Vergleichsdaten, um ein Belohnungsmodell zu trainieren, und verwenden Sie dieses Belohnungsmodell dann, um GPT-3 durch verstärkendes Lernen mit menschlichem Feedback (RLHF) zu optimieren.
- Ergebnisse: InstructGPT zeigt einen besseren Realismus und weniger Voreingenommenheit, d. h. eine bessere Ausrichtung.
ChatGPT/GPT-4: OpenAI hat keine Details bekannt gegeben. Aber wie wir alle wissen, folgt ChatGPT/GPT-4 weitgehend dem Design des vorherigen GPT-Modells und verwendet immer noch RLHF, um das Modell zu optimieren (möglicherweise mit mehr und qualitativ hochwertigeren Daten/Labels). Es ist allgemein anerkannt, dass GPT-4 mit zunehmender Modellgewichtung größere Datensätze verwendet. - Inferenzdatenentwicklung. Da neuere GPT-Modelle leistungsfähig genug geworden sind, können wir verschiedene Ziele erreichen, indem wir Hinweise oder Inferenzdaten anpassen, während das Modell fixiert ist. Beispielsweise können wir eine Textzusammenfassung durchführen, indem wir den zusammenzufassenden Text und Anweisungen wie „Zusammenfassen“ oder „TL;DR“ bereitstellen, um den Argumentationsprozess zu leiten.
Stellen Sie sich rechtzeitig ein
 Das Entwerfen der richtigen Argumentationsaufforderungen ist eine herausfordernde Aufgabe. Es basiert stark auf Heuristiken. Eine gute Umfrage fasst die verschiedenen Werbemethoden zusammen. Manchmal können selbst semantisch ähnliche Hinweise sehr unterschiedliche Ergebnisse haben. In diesem Fall ist möglicherweise eine Soft-Cue-basierte Kalibrierung erforderlich, um die Varianz zu reduzieren.
Das Entwerfen der richtigen Argumentationsaufforderungen ist eine herausfordernde Aufgabe. Es basiert stark auf Heuristiken. Eine gute Umfrage fasst die verschiedenen Werbemethoden zusammen. Manchmal können selbst semantisch ähnliche Hinweise sehr unterschiedliche Ergebnisse haben. In diesem Fall ist möglicherweise eine Soft-Cue-basierte Kalibrierung erforderlich, um die Varianz zu reduzieren.

Die Forschung zur Entwicklung von LLM-Inferenzdaten befindet sich noch in einem frühen Stadium. In naher Zukunft können im LLM weitere inferenzielle Datenentwicklungstechniken angewendet werden, die für andere Aufgaben verwendet wurden.
Datenpflege. ChatGPT/GPT-4 wird als kommerzielles Produkt nicht nur einmal trainiert, sondern auch kontinuierlich aktualisiert und gepflegt. Offensichtlich haben wir keine Möglichkeit zu wissen, wie die Datenpflege außerhalb von OpenAI erfolgt. Daher diskutieren wir einige allgemeine datenzentrierte KI-Strategien, die mit GPT-Modellen verwendet wurden oder höchstwahrscheinlich verwendet werden:
- Kontinuierliche Datenerfassung: Unsere Tipps, wenn wir ChatGPT/GPT-4/ verwenden. Das Feedback kann wiederum verwendet werden von OpenAI, um ihre Modelle weiterzuentwickeln. Möglicherweise wurden Qualitätsmetriken und Sicherungsstrategien entworfen und implementiert, um während des Prozesses qualitativ hochwertige Daten zu sammeln.
- Tools zum Datenverständnis: Es können verschiedene Tools entwickelt werden, um Benutzerdaten zu visualisieren und zu verstehen, ein besseres Verständnis der Benutzerbedürfnisse zu fördern und die Richtung zukünftiger Verbesserungen zu bestimmen.
- Effiziente Datenverarbeitung: Angesichts des schnellen Wachstums der Anzahl der ChatGPT/GPT-4-Benutzer ist ein effizientes Datenverwaltungssystem erforderlich, um eine schnelle Datenerfassung zu erreichen.

Das Bild oben ist ein Beispiel dafür, wie ChatGPT/GPT-4 Benutzerfeedback durch „Likes“ und „Dislikes“ sammelt.
Was die Data-Science-Community aus dieser LLM-Welle lernen kann
Der Erfolg von LLM hat die künstliche Intelligenz revolutioniert. Künftig kann LLM den Lebenszyklus der Datenwissenschaft weiter revolutionieren. Wir machen zwei Vorhersagen:
- Datenzentrierte künstliche Intelligenz wird wichtiger. Nach Jahren der Forschung ist das Modelldesign sehr ausgereift, insbesondere nach Transformer. Daten werden in Zukunft zu einem Schlüsselfaktor für die Verbesserung von KI-Systemen. Wenn das Modell leistungsfähig genug ist, müssen wir es außerdem nicht mehr in unserer täglichen Arbeit trainieren. Stattdessen müssen wir nur geeignete Inferenzdaten entwerfen, um Erkenntnisse aus dem Modell zu erforschen. Daher wird die Forschung und Entwicklung datenzentrierter KI den zukünftigen Fortschritt vorantreiben.
- LLM wird bessere datenzentrierte Lösungen für künstliche Intelligenz ermöglichen
Viele mühsame datenwissenschaftliche Aufgaben können mit Hilfe von LLM effizienter ausgeführt werden. ChaGPT/GPT-4 ermöglicht es beispielsweise bereits, funktionierenden Code zu schreiben, um Daten zu verarbeiten und zu bereinigen. Darüber hinaus können mit LLM sogar Trainingsdaten erstellt werden. Beispielsweise kann die Verwendung von LLM zur Generierung synthetischer Daten die Modellleistung beim Text Mining verbessern.

Das obige ist der detaillierte Inhalt vonSprechen Sie über die datenzentrierte KI hinter dem GPT-Modell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr