
Heim >Technologie-Peripheriegeräte >KI >Entwicklung von KI-Sicherheitssystemen mithilfe von Edge-Biometrie
Entwicklung von KI-Sicherheitssystemen mithilfe von Edge-Biometrie

- WBOYnach vorne
- 2023-04-11 20:55:141579Durchsuche
Übersetzer |. Zhu Xianzhong
Rezensent |. Arbeitsplatzsicherheit kann in Unternehmen, die vertrauliche Informationen verarbeiten oder mehrere Büros mit Tausenden von Mitarbeitern haben, eine mühsame und zeitraubende Belastung darstellen. Elektronische Schlüssel gehören zu den Standardoptionen zur Automatisierung von Sicherheitssystemen, in der Praxis gibt es jedoch immer noch viele Nachteile wie verlorene, vergessene oder gefälschte Schlüssel.
Biometrische Daten sind eine zuverlässige Alternative zu herkömmlichen Sicherheitsmaßnahmen, da sie das Konzept der Authentifizierung „was Sie sind“ darstellen. Dies bedeutet, dass Benutzer ihre einzigartigen Merkmale wie Fingerabdrücke, Iris, Stimme oder Gesicht verwenden können, um nachzuweisen, dass sie Zugang zu einem Raum haben. Durch den Einsatz biometrischer Daten als Authentifizierungsmethode wird sichergestellt, dass Schlüssel nicht verloren, vergessen oder gefälscht werden können. Daher werden wir in diesem Artikel über unsere Erfahrungen bei der Entwicklung von Edge-Biometrie sprechen, einer Kombination aus Edge-Geräten, künstlicher Intelligenz und Biometrie zur Implementierung eines Sicherheitsüberwachungssystems auf Basis der Technologie der künstlichen Intelligenz.
Was ist Edge-Biometrie?
Lassen Sie uns zunächst klären: Was ist Edge AI? In der traditionellen KI-Architektur ist es üblich, Modelle und Daten getrennt von Bediengeräten oder Hardwaresensoren in der Cloud bereitzustellen. Dies zwingt uns dazu, die Cloud-Server in einem ordnungsgemäßen Zustand zu halten, eine stabile Internetverbindung aufrechtzuerhalten und für Cloud-Dienste zu bezahlen. Wenn bei einem Ausfall der Internetverbindung kein Zugriff auf den Remote-Speicher möglich ist, wird die gesamte KI-Anwendung unbrauchbar.
„Im Gegensatz dazu besteht die Idee von Edge AI darin, Anwendungen mit künstlicher Intelligenz näher am Gerät bereitzustellen. Edge-Geräte verfügen möglicherweise über eigene GPUs, sodass wir Eingaben lokal auf dem Gerät verarbeiten können.“ Es gibt viele Vorteile, wie z. B. eine geringere Latenz, da alle Vorgänge lokal auf dem Gerät ausgeführt werden, und auch die Gesamtkosten und der Stromverbrauch werden geringer, da das Gerät problemlos von einem Standort zum anderen transportiert werden kann. Da kein großes Ökosystem erforderlich ist, sind die Bandbreitenanforderungen im Vergleich zu herkömmlichen Sicherheitssystemen, die auf stabile Internetverbindungen angewiesen sind, geringer, da die Daten auch bei geschlossener Verbindung im internen Speicher des Geräts gespeichert werden können zuverlässig und robust.“
– Daniel Lyadov (Python Engineer bei MobiDev)
Der einzige nennenswerte Nachteil ist, dass die gesamte Verarbeitung innerhalb kurzer Zeit auf dem Gerät erfolgen muss, die Hardwarekomponenten müssen leistungsstark genug sein und betriebsbereit sein -to-date, um diese Funktionalität zu aktivieren.
Für biometrische Authentifizierungsaufgaben wie Gesichts- oder Stimmerkennung sind die schnelle Reaktion und Zuverlässigkeit des Sicherheitssystems entscheidend. Da wir ein nahtloses Benutzererlebnis und angemessene Sicherheit gewährleisten möchten, bietet der Einsatz von Edge-Geräten diese Vorteile.
Biometrische Informationen wie Gesichter und Stimmen von Mitarbeitern scheinen sicher genug zu sein, da sie einzigartige Muster darstellen, die neuronale Netze erkennen können. Darüber hinaus ist diese Art von Daten einfacher zu erfassen, da die meisten Unternehmen bereits Fotos ihrer Mitarbeiter in ihrem CRM oder ERP haben. Auf diese Weise können Sie auch Datenschutzprobleme vermeiden, indem Sie Fingerabdruckproben Ihrer Mitarbeiter sammeln.
In Kombination mit Spitzentechnologie können wir ein flexibles KI-Sicherheitskamerasystem für die Eingänge von Arbeitsbereichen erstellen. Im Folgenden diskutieren wir, wie wir ein solches System basierend auf den Entwicklungserfahrungen unseres eigenen Unternehmens und mit Hilfe von Edge-Biometrie implementieren können.
Design eines Überwachungssystems mit künstlicher Intelligenz
Der Hauptzweck dieses Projekts besteht darin, Mitarbeiter am Büroeingang mit nur einem Blick in die Kamera zu authentifizieren. Das Computer-Vision-Modell ist in der Lage, das Gesicht einer Person zu erkennen, es mit zuvor aufgenommenen Fotos zu vergleichen und dann das automatische Öffnen der Tür zu steuern. Als zusätzliche Maßnahme wird auch die Unterstützung der Sprachüberprüfung hinzugefügt, um zu verhindern, dass das System in irgendeiner Weise betrogen wird. Die gesamte Pipeline besteht aus 4 Modellen, die für die Ausführung unterschiedlicher Aufgaben von der Gesichtserkennung bis zur Spracherkennung verantwortlich sind.
Alle diese Maßnahmen werden über ein einziges Gerät durchgeführt, das als Video-/Audio-Eingangssensor fungiert, und über einen Controller, der Sperr-/Entsperrbefehle sendet. Als Edge-Gerät haben wir uns für den Jetson Xavier von NVIDIA entschieden. Diese Wahl wurde hauptsächlich aufgrund der Nutzung des GPU-Speichers des Geräts (entscheidend für die Beschleunigung der Inferenz bei Deep-Learning-Projekten) und des hochverfügbaren Jetpack-SDK von NVIDIA getroffen, das Geräte unterstützt, die auf Python 3-Encode-Umgebungen basieren. Daher besteht keine zwingende Notwendigkeit, DS-Modelle in ein anderes Format zu konvertieren, und fast alle Codebasen können von DS-Ingenieuren an das Gerät angepasst werden. Darüber hinaus besteht keine Notwendigkeit, von einer Programmiersprache in eine andere umzuschreiben.
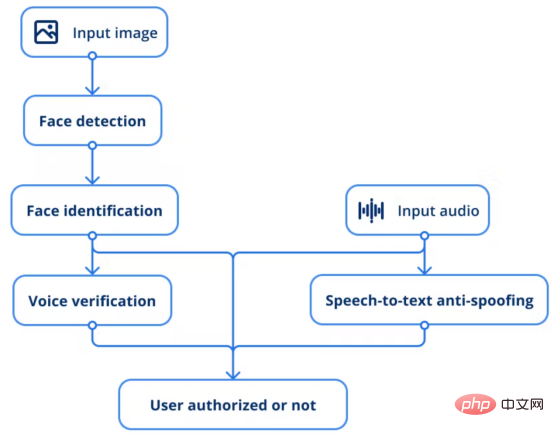
KI-Sicherheitssystem-Workflow
Gemäß der obigen Beschreibung folgt der gesamte Prozess dem folgenden Ablauf:
1. Stellen Sie das Eingabebild dem Gesichtserkennungsmodell zur Verfügung, um den Benutzer zu finden.
2. Das Gesichtserkennungsmodell führt eine Inferenz durch, indem es Vektoren extrahiert und sie mit vorhandenen Mitarbeiterfotos vergleicht, um festzustellen, ob es sich um dieselbe Person handelt.
3. Ein anderes Modell besteht darin, die Stimme einer bestimmten Person durch Stimmproben zu überprüfen.
4. Darüber hinaus wird eine Voice-to-Text-Anti-Spoofing-Lösung eingesetzt, um jede Art von Spoofing-Technologie zu verhindern.
Lassen Sie uns als Nächstes jeden Implementierungslink besprechen und den Schulungs- und Datenerfassungsprozess im Detail erläutern.
Datenerfassung
Bevor Sie sich mit den Systemmodulen befassen, achten Sie unbedingt auf die verwendete Datenbank. Unser System ist darauf angewiesen, den Nutzern sogenannte Referenz- oder Ground-Truth-Daten zur Verfügung zu stellen. Die Daten umfassen derzeit vorberechnete Gesichts- und Stimmvektoren für jeden Benutzer, die wie eine Zahlenreihe aussehen. Das System speichert außerdem erfolgreiche Login-Daten für zukünftige Umschulungen. Vor diesem Hintergrund haben wir uns für die einfachste Lösung entschieden: SQLite DB. Mit dieser Datenbank werden alle Daten in einer Datei gespeichert, die einfach zu durchsuchen und zu sichern ist, und die Lernkurve für Data-Science-Ingenieure ist kürzer.
Da für die Gesichtserkennung Fotos aller Mitarbeiter erforderlich sind, die das Büro betreten dürfen, verwenden wir Gesichtsfotos, die in der Unternehmensdatenbank gespeichert sind. Jetson-Geräte, die an Bürotüren angebracht sind, erfassen auch Gesichtsdatenproben, wenn Personen die Gesichtsverifizierung zum Öffnen von Türen verwenden.
Anfangs waren keine Sprachdaten verfügbar, also organisierten wir eine Datenerfassung und baten die Leute, 20-Sekunden-Clips aufzunehmen. Anschließend verwenden wir das Sprachverifizierungsmodell, um den Vektor jeder Person abzurufen und ihn in der Datenbank zu speichern. Sie können Sprachproben mit jedem Audioeingabegerät erfassen. In unserem Projekt verwenden wir ein tragbares Telefon und eine Webcam mit eingebautem Mikrofon, um den Ton aufzuzeichnen.
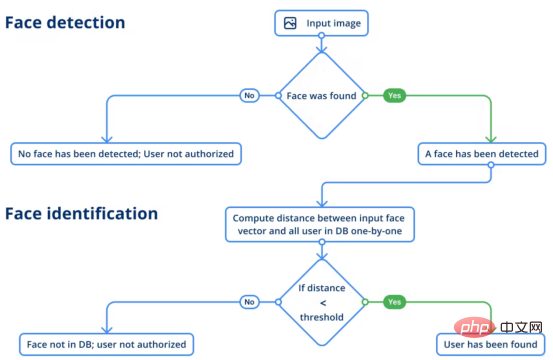
Gesichtserkennung
Die Gesichtserkennung kann feststellen, ob in einer bestimmten Szene ein Gesicht vorhanden ist. Wenn dies der Fall ist, sollte das Modell die Koordinaten jedes Gesichts angeben, damit Sie wissen, wo sich jedes Gesicht auf dem Bild befindet, einschließlich Gesichtsorientierungspunkten. Diese Informationen sind wichtig, da wir ein Gesicht im Begrenzungsrahmen empfangen müssen, um im nächsten Schritt die Gesichtserkennung ausführen zu können.
Für die Gesichtserkennung haben wir das RetinaFace-Modell und die MobileNet-Schlüsselkomponenten aus dem InsightFace-Projekt verwendet. Das Modell gibt für jedes erkannte Gesicht auf dem Bild vier Koordinaten zusammen mit fünf Gesichtsbeschriftungen aus. Tatsächlich können Bilder, die aus unterschiedlichen Winkeln oder mit unterschiedlichen Optiken aufgenommen wurden, die Proportionen des Gesichts aufgrund von Verzerrungen verändern. Dies kann dazu führen, dass das Modell Schwierigkeiten hat, die Person zu identifizieren.
Um diesem Bedarf gerecht zu werden, werden Gesichtsmarkierungen zum Morphing verwendet, einer Technik, die die Unterschiede verringert, die zwischen diesen Bildern derselben Person bestehen können. Daher sehen die erhaltenen beschnittenen und verzerrten Oberflächen ähnlicher aus und die extrahierten Gesichtsvektoren sind genauer.
Gesichtserkennung
Der nächste Schritt ist die Gesichtserkennung. In dieser Phase muss das Modell die Person anhand des gegebenen Bildes (d. h. des erhaltenen Bildes) erkennen. Die Identifizierung erfolgt mit Hilfe von Referenzen (Ground-Truth-Daten). Hier vergleicht das Modell also zwei Vektoren, indem es den Distanzwert der Differenz zwischen ihnen misst, um festzustellen, ob es sich um dieselbe Person handelt, die vor der Kamera steht. Der Bewertungsalgorithmus vergleicht es mit einem ersten Foto, das uns von einem Mitarbeiter vorliegt.
Die Gesichtserkennung erfolgt mithilfe des SE-ResNet-50-Architekturmodells. Um die Modellergebnisse robuster zu machen, wird das Bild gespiegelt und gemittelt, bevor die Gesichtsvektoreingabe erfolgt. Zu diesem Zeitpunkt läuft der Benutzeridentifizierungsprozess wie folgt ab:
ECAPA-TDNN-Architektur verwendet haben, die auf dem VoxCeleb2Datensatz des SpeechBrain-Frameworks trainiert wurde, was bei der Validierung von Mitarbeitern eine viel bessere Arbeit leistete.
Allerdings erfordern die Audioclips noch eine gewisse Vorverarbeitung. Ziel ist es, die Qualität der Audioaufnahme zu verbessern, indem der Ton erhalten bleibt und aktuelle Hintergrundgeräusche reduziert werden. Allerdings beeinträchtigen alle Testtechniken die Qualität von Sprachverifizierungsmodellen erheblich. Höchstwahrscheinlich verändert selbst die geringste Rauschunterdrückung die Audioeigenschaften der Sprache in der Aufnahme, sodass das Modell die Person nicht korrekt authentifizieren kann. Zusätzlich haben wir die Länge der Audioaufnahme untersucht und wie viele Wörter der Benutzer aussprechen sollte. Als Ergebnis dieser Untersuchung haben wir eine Reihe von Empfehlungen abgegeben. Das Fazit lautet: Die Dauer einer solchen Aufnahme sollte mindestens 3 Sekunden betragen und es sollten ca. 8 Wörter vorgelesen werden. Speech-to-Text-Anti-SpoofingDie letzte Sicherheitsmaßnahme besteht darin, dass das System Speech-to-Text-Anti-Spoofing anwendet, das auf Fotos von Mitarbeitern zu bekommen, um das Gesichtsverifizierungsmodul auszutricksen, ist eine machbare Aufgabe, ebenso wie das Aufzeichnen von Sprachproben. Speech-to-Text-Anti-Spoofing deckt keine Szenarien ab, in denen ein Eindringling versucht, mithilfe von Fotos und Audioaufnahmen von autorisiertem Personal in ein Büro einzudringen. Die Idee ist einfach: Wenn sich jede Person authentifiziert, spricht sie den vom System vorgegebenen Satz. Eine Phrase besteht aus einer Reihe zufällig ausgewählter Wörter. Obwohl die Anzahl der Wörter in einer Phrase nicht so groß ist, ist die tatsächliche Anzahl möglicher Kombinationen recht groß. Durch die Anwendung zufällig generierter Phrasen eliminieren wir die Möglichkeit, das System auszutricksen, was dazu führen würde, dass ein autorisierter Benutzer eine große Anzahl aufgezeichneter Phrasen sprechen müsste. Ein Foto eines Benutzers reicht nicht aus, um ein KI-Sicherheitssystem mit diesem Schutz auszutricksen. Vorteile des Edge Biometric SystemsAn diesem Punkt können Benutzer mit unserem Edge Biometric System einem einfachen Prozess folgen, bei dem sie einen zufällig generierten Satz sprechen müssen, um die Tür zu öffnen. Darüber hinaus bieten wir KI-Überwachungsdienste für Büroeingänge durch Gesichtserkennung an.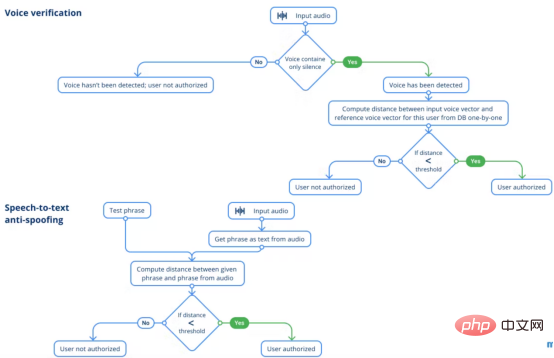
——Daniel Lyadov (Python-Ingenieur bei MobiDev)
Übersetzer-Einführung
Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Weifang Ein Computerlehrer in eine Universität und ein Veteran in der freiberuflichen Programmierbranche.
Originaltitel: Entwicklung von KI-Sicherheitssystemen mit Edge Biometrics#🎜 🎜# von Dmitriy Kisil
Das obige ist der detaillierte Inhalt vonEntwicklung von KI-Sicherheitssystemen mithilfe von Edge-Biometrie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr