
Heim >Technologie-Peripheriegeräte >KI >Sie wissen nicht, wie Sie Modelle für maschinelles Lernen einsetzen? 15 Bilder entführen Sie in das TensorFlow-Bereitstellungsframework!
Sie wissen nicht, wie Sie Modelle für maschinelles Lernen einsetzen? 15 Bilder entführen Sie in das TensorFlow-Bereitstellungsframework!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-11 18:10:031652Durchsuche

Eröffnung
Vor ein paar Tagen unterhielt ich mich mit einem Freund, Xiao Li, der seit drei Jahren in der Entwicklung tätig ist, und erfuhr, dass sein Unternehmen ein Projekt im Zusammenhang mit maschinellem Lernen durchführt. Kürzlich erhielt er den Auftrag, das trainierte Modell für maschinelles Lernen bereitzustellen. Dies beunruhigt Xiao Li. Er beschäftigt sich seit fast einem halben Jahr mit der Datenerfassung, Datenbereinigung, dem Aufbau von Umgebungen, dem Modelltraining und der Modellbereitstellung .
Also habe ich auf der Grundlage meiner eigenen Erfahrung eine populärwissenschaftliche Studie zum Einsatz von Modellen für maschinelles Lernen durchgeführt. Wie in Abbildung 1 gezeigt, übergeben wir bei der herkömmlichen Programmierung Regeln und Daten an das Programm, um die gewünschten Antworten zu erhalten. Beim maschinellen Lernen trainieren wir die Regeln jedoch durch die Antworten und Daten.
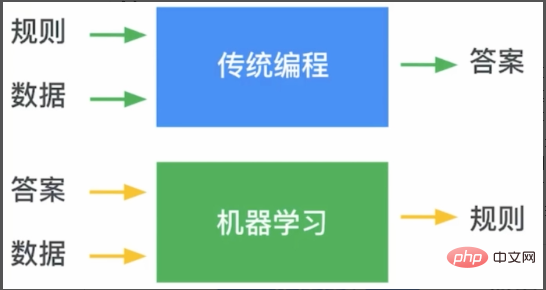
Abbildung 1 Der Unterschied zwischen traditioneller Programmierung und maschinellem Lernen
Der Modelleinsatz von maschinellem Lernen besteht darin, diese Regel (Modell) auf dem Terminal bereitzustellen, auf dem maschinelles Lernen angewendet werden muss. Wie in Abbildung 2 dargestellt, kann das durch maschinelles Lernen trainierte Modell als Funktion, API oder SDK verstanden werden und auf dem entsprechenden Terminal (der graue Teil in der Abbildung) bereitgestellt werden. Nach der Bereitstellung verfügt das Terminal über die vom Modell bereitgestellten Funktionen. Zu diesem Zeitpunkt können durch Eingabe neuer Daten die vorhergesagten Ergebnisse gemäß den Regeln (Modell) erhalten werden.
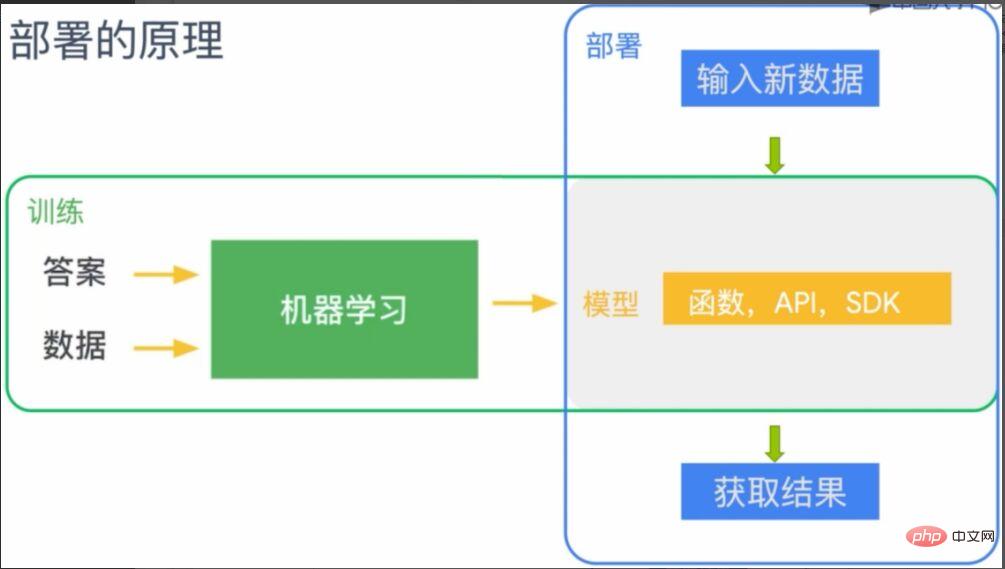
Abbildung 2 Prinzip der Bereitstellung von Modellen für maschinelles Lernen
TensorFlow-Bereitstellungsframework für maschinelles Lernen
Xiao Li sagte, er habe verstanden, nachdem er meine Einführung gehört hatte, und erzählte mir bitte mit großem Interesse die vollständige Bereitstellungssituation ihres Projekts Sag es mir, ich möchte dich um meine Meinung bitten. Wie in Abbildung 3 dargestellt, möchten sie ein Bilderkennungsmodell auf iOS-, Android-, Raspberry Pi-, Webbrowser- und Serverseite bereitstellen.
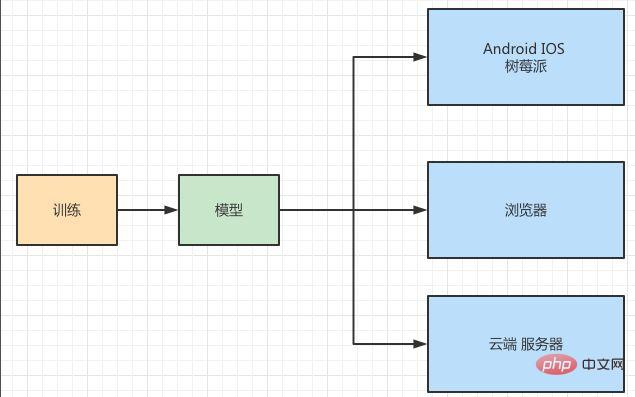
Abbildung 3 Modellbereitstellungsszenario
Aus dem Bereitstellungsanwendungsszenario weist es die Eigenschaften von leichtgewichtig und plattformübergreifend auf. Das gleiche Modell für maschinelles Lernen muss auf mehreren verschiedenen Plattformen bereitgestellt werden, und jede Plattform verfügt über unterschiedliche Speicher- und Rechenfunktionen. Gleichzeitig müssen die Verfügbarkeit, Leistung, Sicherheit und Skalierbarkeit des Modellbetriebs berücksichtigt und eine relativ stabile große Plattform verwendet werden. Deshalb habe ich ihm das Machine-Learning-Deployment-Framework von TensorFlow empfohlen. Wie in Abbildung 4 dargestellt, bietet das Bereitstellungsframework von TensorFlow Komponentenunterstützung für verschiedene Plattformen. Unter ihnen reagieren Android, IOS und Raspberry Pi auf TensorFlow Lite, ein Modellbereitstellungsframework, das speziell für mobile Endgeräte verwendet wird. Die Browserseite kann TensorFlow.js verwenden und die Serverseite kann TensorFlow Serving verwenden.
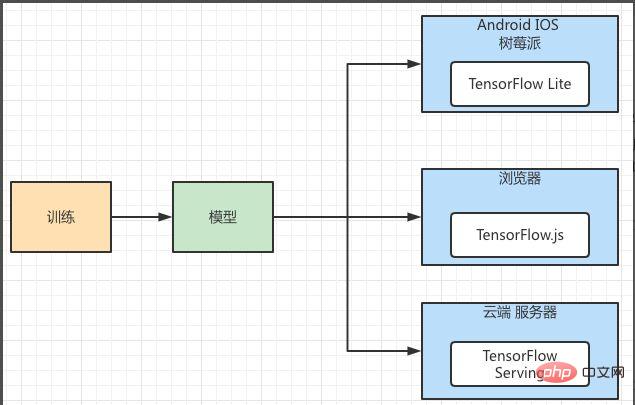
Abbildung 4 TensorFlow-Modellbereitstellungsframework für maschinelles Lernen
TensorFlow Lite-Tatsächlicher Betrieb
Xiao Li wollte mehr über den spezifischen Bereitstellungsprozess erfahren. Ich hatte zufällig ein Projekt in der Hand, das das Bereitstellungsframework von TensorFlow verwendete , also Zeigen Sie ihm den Vorgang. Bei diesem Projekt geht es darum, das Modell „Katzen- und Hundeerkennung“ auf Android-Telefonen bereitzustellen. Da iOS, Android, Raspberry Pi und Browser allesamt Clients sind, können ihre Rechenressourcen nicht mit denen des Servers verglichen werden. Insbesondere mobile Anwendungen zeichnen sich durch geringes Gewicht, geringe Latenz, hohe Effizienz, Datenschutz, Energieeinsparung usw. aus. Daher hat TensorFlow ihre Bereitstellung speziell entwickelt und verwendet TensorFlow Lite für die Bereitstellung.
Die Verwendung von TensorFlow Lite zum Bereitstellen eines Modells erfordert drei Schritte:
- Verwenden Sie TensorFlow, um das Modell zu trainieren.
- In das TensorFlow Lite-Format konvertieren.
- Verwenden Sie zum Laden und Ausführen den TensorFlow Lite-Interpreter.
Im ersten Schritt haben wir das Modelltraining abgeschlossen. Der zweite Schritt besteht darin, das generierte Modell in ein Musterformat zu konvertieren, das TensorFlow Lite erkennen und verwenden kann. Wie oben erwähnt, müssen bei der Verwendung des Modells auf dem mobilen Endgerät verschiedene Aspekte berücksichtigt werden, sodass ein spezielles Dateiformat für das mobile Endgerät generiert werden muss. Der dritte Schritt besteht darin, die konvertierte TensorFlow Lite-Datei in den mobilen Interpreter zu laden und auszuführen.
Da unser Fokus auf der Modellbereitstellung liegt, wird der erste Schritt des Modelltrainings vorübergehend übersprungen, d. h. es wird davon ausgegangen, dass Sie das Modell bereits trainiert haben. Den zweiten Schritt der Modellkonvertierung finden Sie in Abbildung 5. Das TensorFlow-Modell wird über den Konverter in eine Modelldatei mit dem Suffix „.tflite“ konvertiert, dann auf verschiedenen Plattformen veröffentlicht und über den Interpreter auf jeder Plattform verarbeitet. Erklären und laden.
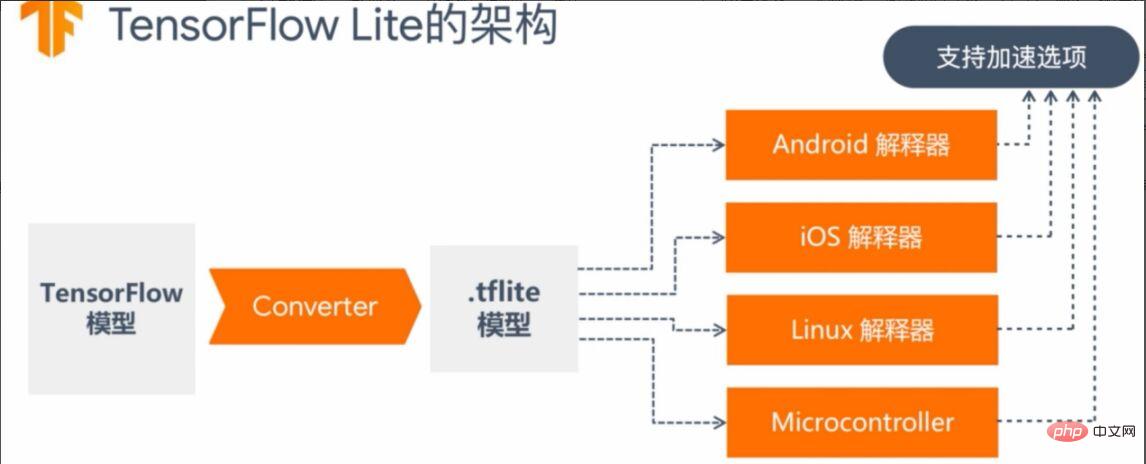
Abbildung 5 TensorFlow Lite-Modellkonvertierungsarchitektur
Modellspeicherung und -konvertierung
Die Architektur von TensorFlow Lite wird oben vorgestellt. Hier müssen Sie das Modell als TensorFlow-Modell speichern und konvertieren. Wie in Abbildung 6 gezeigt, rufen wir die Methode „saved_model.save“ in TensorFlow auf, um das Modell (trainiertes Modell) im angegebenen Verzeichnis zu speichern.
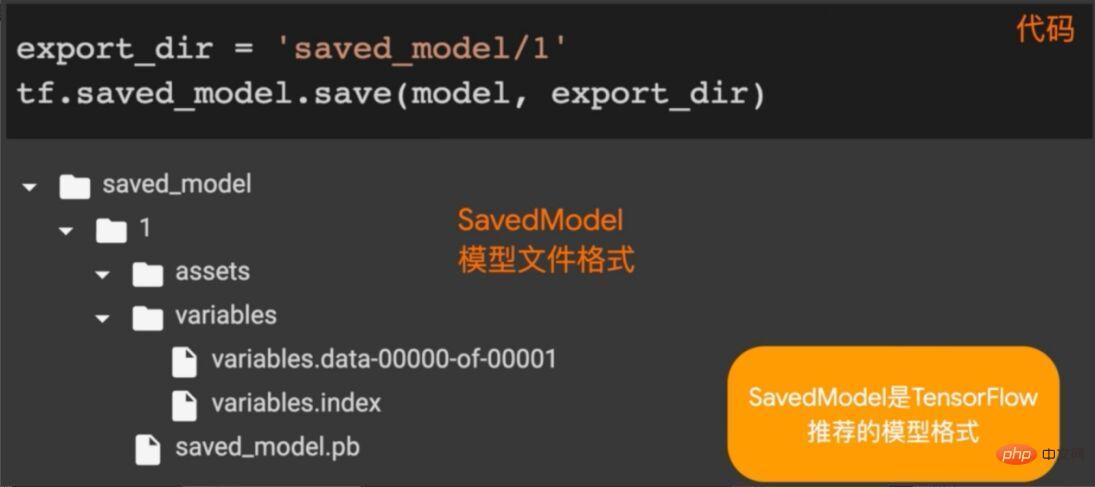
Abbildung 6 Speichern des TensorFlow-Modells
Nach dem Speichern des Modells ist es an der Zeit, das Modell zu konvertieren. Rufen Sie wie in Abbildung 7 gezeigt die Methode from_saved_model im TFLiteConverter-Paket in TensorFlow Lite auf, um das zu generieren Konverter-Instanz (Modellkonverter) und rufen Sie dann die Konvertierungsmethode im Konverter auf, um das Modell zu konvertieren und die konvertierte Datei im angegebenen Verzeichnis zu speichern.
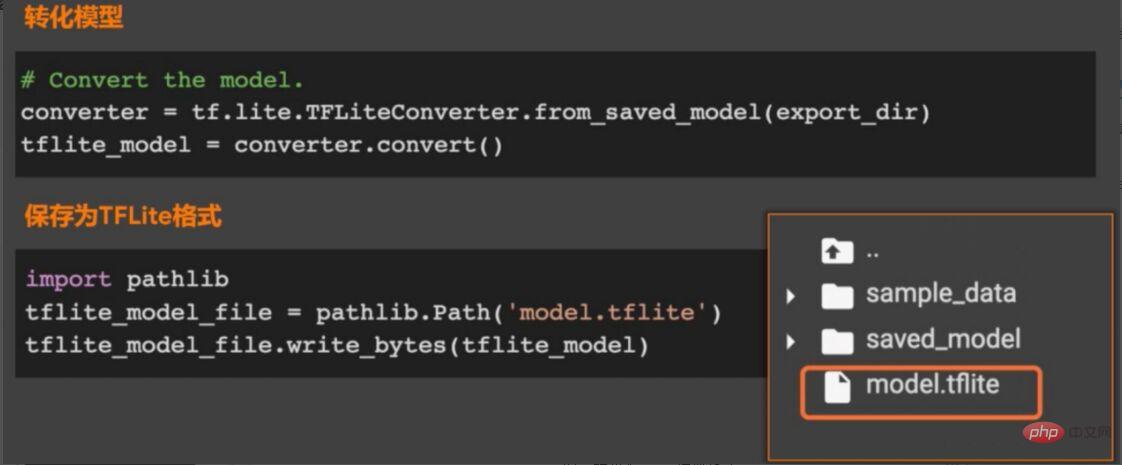
Abbildung 7 Konvertieren in das TFlite-Modellformat
Laden Sie das Anwendungsmodell
Da es sich bei diesem Beispiel um die Modellbereitstellung des Android-Systems handelt, muss die Abhängigkeit von TensorFlow Lite in Android eingeführt werden. Führen Sie, wie in Abbildung 8 gezeigt, die Abhängigkeit von TensorFlow Lite ein und setzen Sie noCompress in aaptOptions auf „tflite“, was bedeutet, dass Dateien mit „tflite“ nicht komprimiert werden. Wenn die Komprimierung festgelegt ist, erkennt das Android-System möglicherweise keine tflite-Dateien.
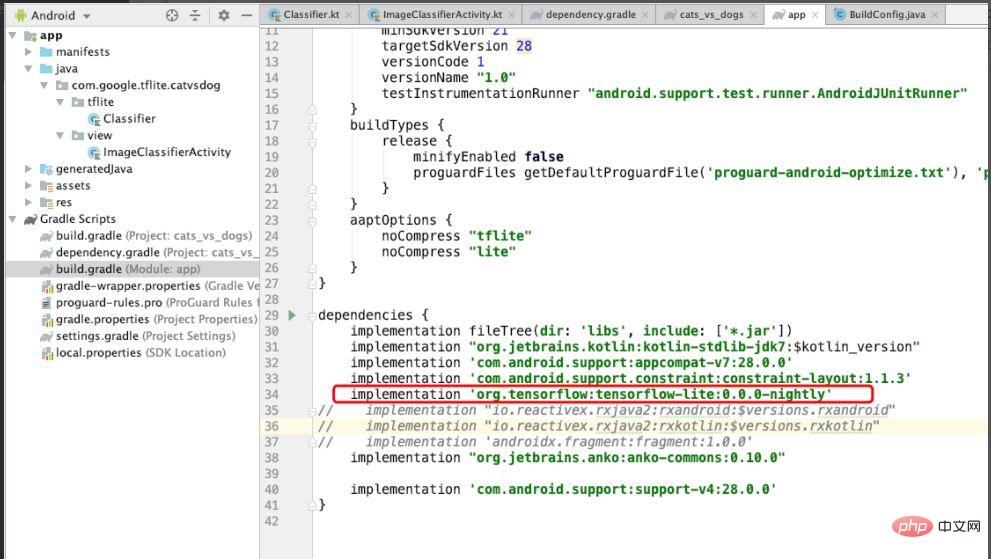
Abbildung 8 Im Projekt eingeführte Abhängigkeiten von TensorFlow Lite
Kopieren Sie nach der Konfiguration der Abhängigkeiten die konvertierte TFlite-Datei in die Assets-Datei, wie in Abbildung 9 dargestellt. Diese Datei wird später geladen die maschinelles Lernen durchführen.
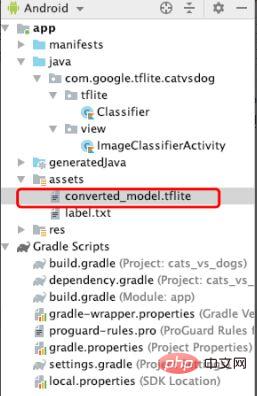
Abbildung 9 Hinzufügen der Tflite-Datei
Nach dem Hinzufügen der Tflite-Datei erstellen wir einen Classifier-Klassifizierer, um „Katzen- und Hunde“-Bilder zu klassifizieren. Wie in Abbildung 10 gezeigt, wird der Interpreter in init in Classifer initialisiert, die Methode „loadModuleFlie“ aufgerufen, um die tflite-Datei zu laden, und die Klassifizierungsbezeichnung (labelList) wird hier angegeben. Die Bezeichnung lautet hier „cat dog“.
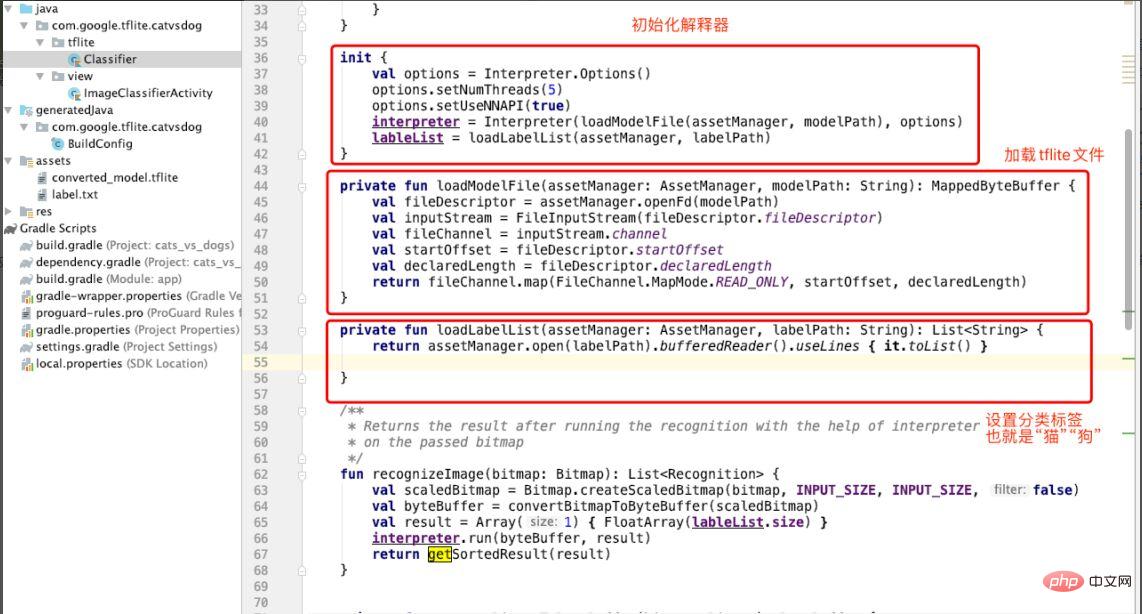
Abbildung 10 Initialisierung des Interpreters
Nach der Erstellung des Klassifikators wird das Katzen- und Hundeklassifizierungsmodell zur Identifizierung des Bildes verwendet. Das heißt, in der Classifier-Klasse ist der Eingabeparameter der Methode „convertBitmapToByteBuffer“ das Bild der Katze und des Hundes, auf das wir besonders achten rot in der for-Schleife. Konvertieren Sie die grünen und blauen Kanäle, legen Sie das Konvertierungsergebnis in einen ByteBuffer und geben Sie es zurück. Die Methode „recoginzeImage“ ruft „convertBitmapToByteBuffer“ auf und verwendet die Ausführungsmethode des Interpreters, um Bilderkennungsarbeiten durchzuführen, d. h. mithilfe eines Modells für maschinelles Lernen, um Bilder von Katzen und Hunden zu identifizieren.
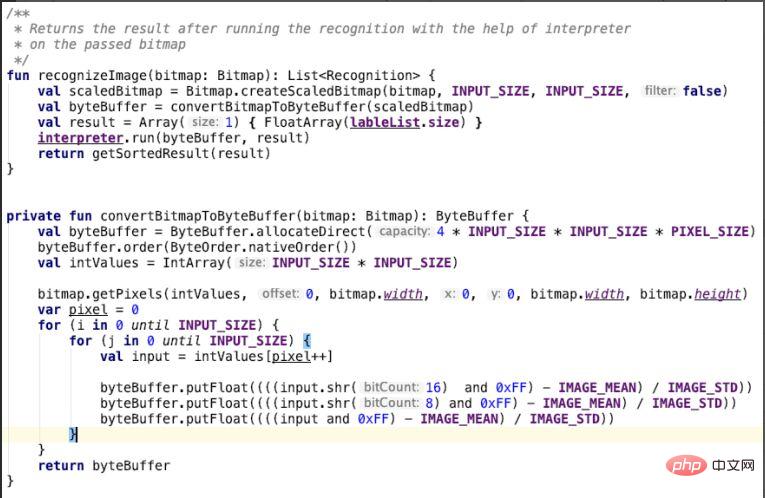
Abbildung 11 Bilder erkennen
Der obige grafische Transformationsprozess ist zu abstrakt, wir werden ihn wie in Abbildung 12 konkretisieren. Das von uns eingegebene Bild ist das 395 * 500-Bild in der oberen linken Ecke des Bildes, wodurch das Bild in der Bildansicht in eine Bitmap-Form konvertiert wird. Da unsere Modelleingabe ein 224*224-Format erfordert, ist eine Konvertierung erforderlich. Als nächstes werden die Pixel in ein 224*224 ByteBuffer-Array eingefügt und gespeichert, und schließlich werden die RGB-Pixel (rot, grün und blau) als Eingabeparameter des Modells normalisiert (geteilt durch 255).
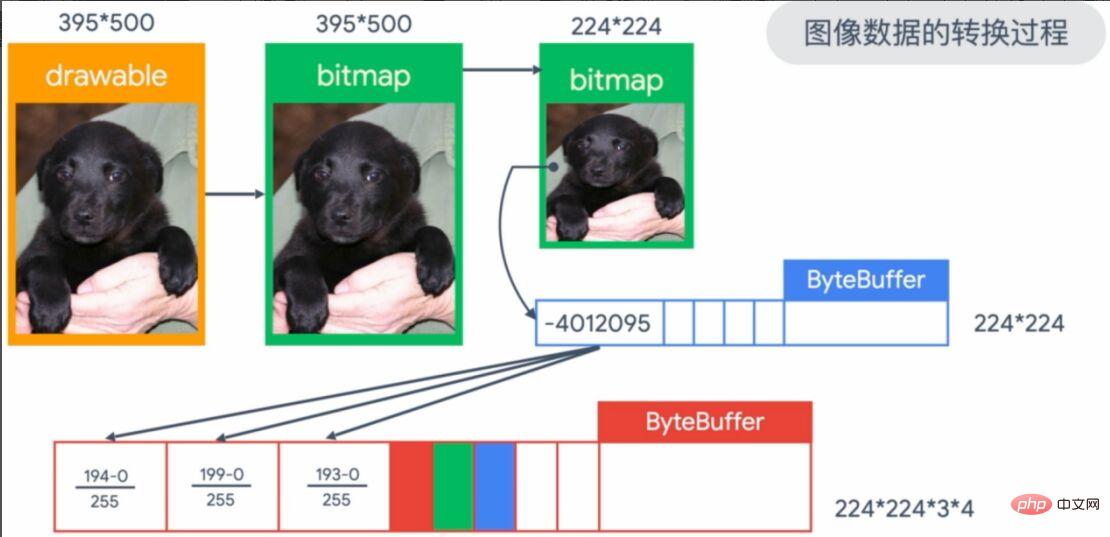
Abbildung 12 Der Konvertierungsprozess des Eingabebildes
An diesem Punkt ist das Laden und Anwenden des maschinellen Lernmodells abgeschlossen. Natürlich sind auch die Eingabedateien und das Layout unverzichtbar. Wie in Abbildung 13 gezeigt, speichern wir die Bilder, die vorhergesagt werden müssen (Katzen- und Hundebilder), im Zeichenordner. Erstellen Sie dann die Datei „activity_image_classifier.xml“ unter dem Layout, um die ImageView zu erstellen und zu speichern.
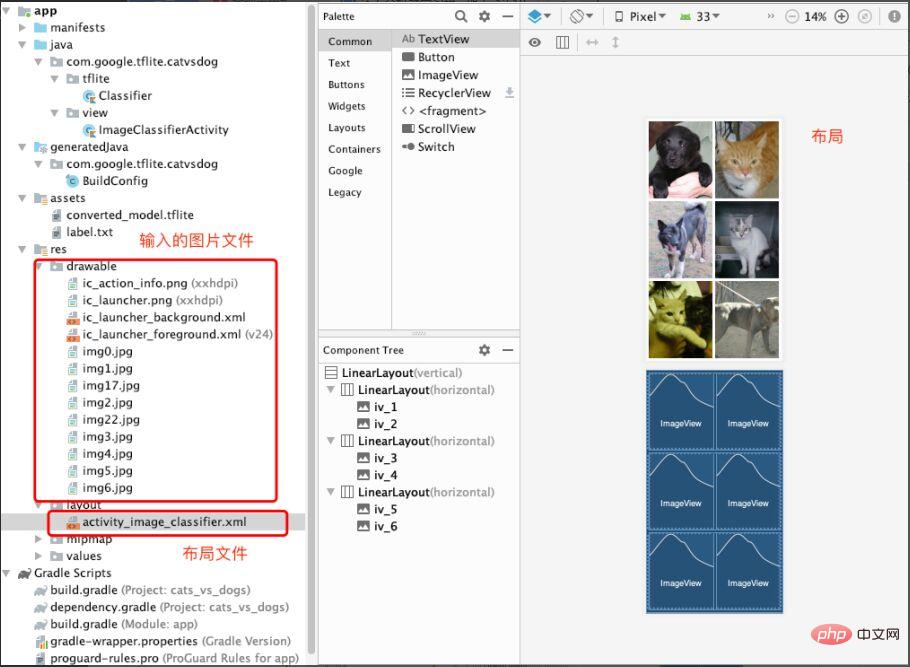
Abbildung 13 Eingabebilddateien und Layoutdateien
Schließlich erstellen Sie eine ImageClassifierActivity, um Bilder anzuzeigen und auf Ereignisse zu reagieren, die Bilder identifizieren. Binden Sie, wie in Abbildung 14 gezeigt, das Onclick-Ereignis jedes Bildes in der initViews-Methode und rufen Sie dann die Recoginzie-Image-Methode in der Onclick-Methode auf, um das Bild zu identifizieren.

Abbildung 14 Bilderkennung in Onclick durchführen
Werfen wir einen Blick auf den Effekt. Wie in Abbildung 15 dargestellt, wird beim Klicken auf das entsprechende Bild eine „Hund“-Eingabeaufforderung angezeigt, die das Vorhersageergebnis angibt.

Abbildung 15 Demonstrationseffekt
Die Überprüfung des gesamten Prozesses ist nicht kompliziert. Ich fasse das TensorFlow Lite-Bereitstellungsmodell in den folgenden Schritten zusammen:
- Speichern Sie das Modell für maschinelles Lernen.
- Konvertieren Sie das Modell in das TFlite-Format.
- Laden Sie das Modell im TFlite-Format.
- Verwenden Sie den Interpreter, um das Modell zu laden.
- Ergebnisse der Eingabeparametervorhersage.
Studenten, die ihre Fähigkeiten zur TensorFlow-Modellbereitstellung weiter erlernen möchten, können die offiziellen Kurse von TensorFlow erlernen, ein Konto beim MOOC der chinesischen Universität registrieren und kostenlos lernen: https://www.php cn /link/1f5f6ad95cc908a20bb7e30ee28a5958
Es gibt auch Online-Bereitstellungserklärungen und Fragen und Antworten von Google-Entwicklerexperten. Ich empfehle Studenten, die ein vorläufiges Verständnis der TensorFlow-Bereitstellungsfunktionen erlangen möchten, darauf zu achten https ://www.php.cn/link/e046ede63264b10130007afca077877f
Ende
Nachdem Xiao Li sich meine Erklärung zur Modellbereitstellung für maschinelles Lernen angehört und den TensorFlow-Bereitstellungsprozess verstanden hatte, war er noch gespannter darauf, die praktische Bereitstellung auszuprobieren. Ich denke, der Bereitstellungsprozess mit TensorFlow ist logisch klar, die Methode ist einfach und leicht zu implementieren und für Entwickler mit 3-5 Jahren Erfahrung ist der Einstieg einfach. Darüber hinaus bietet TensorFlow offiziell den „TensorFlow Introductory Practical Course“ an, der für Anfänger ohne Vorkenntnisse im maschinellen Lernen geeignet ist: https://www.php.cn/link/bf2fe6582ed9ead9161a3d6f6b1d6858 #🎜🎜 #
Vorstellung des Autors Cui Hao, 51CTO-Community-Redakteur, leitender Architekt, verfügt über 20 Jahre Architekturerfahrung. Er war einst als technischer Experte bei HP tätig, nahm an mehreren Projekten zum maschinellen Lernen teil und schrieb und übersetzte mehr als 20 beliebte technische Artikel zu maschinellem Lernen, NLP usw. Autor von „Distributed Architecture Principles and Practice“.Das obige ist der detaillierte Inhalt vonSie wissen nicht, wie Sie Modelle für maschinelles Lernen einsetzen? 15 Bilder entführen Sie in das TensorFlow-Bereitstellungsframework!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr