| 96
|
12888
|
175 Milliarden #🎜 🎜# #🎜 🎜#45TB |
|
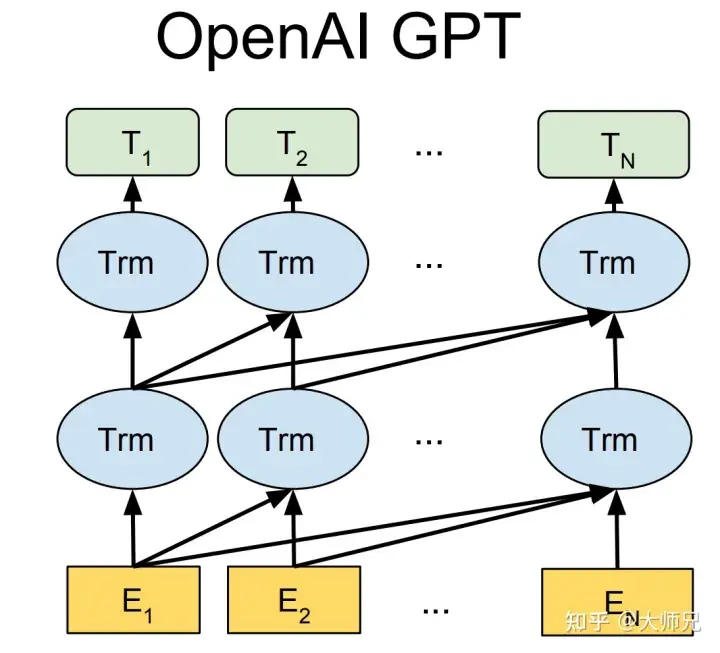
GPT-1 wurde einige Monate früher als BERT geboren. Sie alle verwenden Transformer als Kernstruktur. Der Unterschied besteht darin, dass GPT-1 Vortrainingsaufgaben generativ von links nach rechts erstellt und dann ein allgemeines Vortrainingsmodell erhält, das für nachgelagerte Aufgaben wie BERT verwendet werden kann . GPT-1 erzielte damals SOTA-Ergebnisse bei 9 NLP-Aufgaben, aber die von GPT-1 verwendete Modellgröße und das Datenvolumen waren relativ gering, was zur Geburt von GPT-2 führte.
Im Vergleich zu GPT-1 machte GPT-2 kein großes Aufhebens um die Modellstruktur, sondern verwendete nur ein Modell mit mehr Parametern und mehr Trainingsdaten (Tabelle 1). Die wichtigste Idee von GPT-2 ist die Idee, dass „jedes überwachte Lernen eine Teilmenge unbeaufsichtigter Sprachmodelle ist“. Diese Idee ist auch der Vorläufer des prompten Lernens. GPT-2 sorgte auch bei seiner ersten Geburt für großes Aufsehen. Die von ihm erzeugten Nachrichten reichten aus, um die meisten Menschen zu täuschen und den Effekt zu erzielen, dass sie so tun, als wären sie real. Damals wurde sie sogar als „die gefährlichste Waffe der KI-Branche“ bezeichnet und viele Portale ordneten an, die Verwendung von durch GPT-2 generierten Nachrichten zu verbieten.
Als GPT-3 vorgeschlagen wurde, sorgten neben seiner weit über GPT-2 hinausgehenden Wirkung auch seine 175 Milliarden Parameter für weitere Diskussionen. Abgesehen davon, dass GPT-3 in der Lage ist, häufige NLP-Aufgaben zu erledigen, stellten Forscher unerwartet fest, dass GPT-3 auch eine gute Leistung beim Schreiben von Codes in Sprachen wie SQL und JavaScript sowie bei der Ausführung einfacher mathematischer Operationen aufweist. Das Training von GPT-3 verwendet In-Context-Lernen, eine Art Meta-Lernen. Die Kernidee des Meta-Lernens besteht darin, mithilfe einer kleinen Datenmenge einen geeigneten Initialisierungsbereich zu finden, damit das Modell schnell funktionieren kann Anpassung an begrenzte Datensätze und gute Ergebnisse.
Durch die obige Analyse können wir sehen, dass GPT aus Leistungssicht zwei Ziele hat:
- Verbesserung der Leistung des Modells bei allgemeinen NLP-Aufgaben;
- Verbessern Sie die Generalisierungsfähigkeit des Modells für andere nicht typische NLP-Aufgaben (z. B. Codeschreiben, mathematische Operationen).
Darüber hinaus ist ein Problem, das seit der Geburt des Pre-Training-Modells kritisiert wird, die Voreingenommenheit des Pre-Training-Modells. Da vorab trainierte Modelle anhand massiver Daten auf Modellen mit extrem großen Parameterniveaus trainiert werden, ähneln vorab trainierte Modelle im Vergleich zu Expertensystemen, die vollständig durch künstliche Regeln gesteuert werden, einer Blackbox. Niemand kann garantieren, dass das vorab trainierte Modell keine gefährlichen Inhalte mit Rassendiskriminierung, Sexismus usw. generiert, da seine Dutzende Gigabyte oder sogar Dutzende Terabyte an Trainingsdaten mit ziemlicher Sicherheit ähnliche Trainingsbeispiele enthalten. Dies ist die Motivation für InstructGPT und ChatGPT. Das Papier verwendet 3H, um ihre Optimierungsziele zusammenzufassen:
- Nützlich (Hilfreich);
- Vertrauenswürdig (Ehrlich);# 🎜🎜#
Harmlos. -
Die Modelle der GPT-Serie von OpenAI sind nicht Open Source, bieten aber eine Testwebsite für das Modell, auf der qualifizierte Studierende es selbst ausprobieren können. 1.2 Instruct Learning (Instruct Learning) und Prompt Learning (Prompt Learning) Learning Instruction Learning ist ein Artikel mit dem Titel „Die im Artikel vorgeschlagene Idee „Finetuned Language Models Are Zero.“ -Shot Learners“ [5]. Der Zweck des Instruktionslernens und des schnellen Lernens besteht darin, das Wissen über das Sprachmodell selbst zu erschließen. Der Unterschied besteht darin, dass Prompt die Vervollständigungsfähigkeit des Sprachmodells stimuliert, z. B. das Generieren der zweiten Satzhälfte basierend auf der ersten Satzhälfte oder das Ausfüllen von Lücken usw. Instruct stimuliert die Verständnisfähigkeit des Sprachmodells. Es ermöglicht dem Modell, korrekte Maßnahmen zu ergreifen, indem es offensichtlichere Anweisungen gibt. Wir können diese beiden unterschiedlichen Lernmethoden anhand der folgenden Beispiele verstehen:
Tipps zum Lernen: Ich habe diese Halskette für meine Freundin gekauft, sie gefällt ihr sehr, diese Halskette ist so____ . - Anleitung zum Lernen: Beurteilen Sie die Emotion dieses Satzes: Ich habe diese Halskette für meine Freundin gekauft und sie gefällt ihr sehr. Optionen: A=gut; B=durchschnittlich; C=schlecht.
-
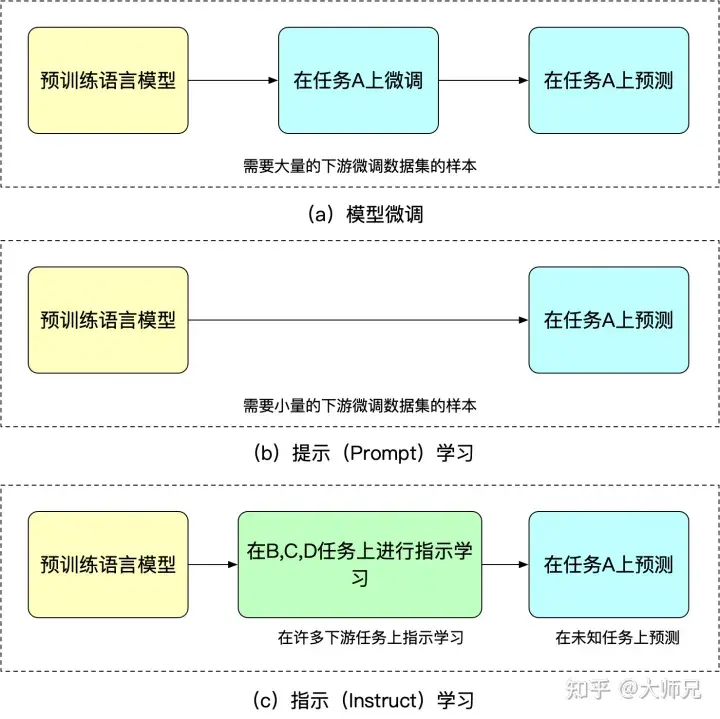
Der Vorteil des Instruktionslernens besteht darin, dass es nach der Feinabstimmung für mehrere Aufgaben auch bei anderen Aufgaben einen Zero-Shot durchführen kann, während das Instruktionslernen ausschließlich auf eine Aufgabe abzielt. Die Fähigkeit zur Generalisierung ist nicht so gut wie das angeleitete Lernen. Wir können Feinabstimmung, Cued-Learning und angeleitetes Lernen anhand von Abbildung 2 verstehen.

Abbildung 2: Ähnlichkeiten und Unterschiede zwischen Modellfeinabstimmung, schnellem Lernen und angeleitetem Lernen
1.3 Verstärkungslernen mit künstlichem Feedback
Da das trainierte Modell nicht sehr kontrollierbar ist, kann das Modell als Anpassung der Verteilung des Trainingssatzes angesehen werden. Bei der Rückkopplung in das generative Modell ist die Verteilung der Trainingsdaten dann der wichtigste Faktor, der die Qualität der generierten Inhalte beeinflusst. Manchmal hoffen wir, dass das Modell nicht nur von den Trainingsdaten beeinflusst wird, sondern auch künstlich kontrollierbar ist, um die Nützlichkeit, Authentizität und Unbedenklichkeit der generierten Daten sicherzustellen. Das Problem der Ausrichtung wird in der Arbeit oft erwähnt. Wir können es als die Ausrichtung des Ausgabeinhalts des Modells und des Ausgabeinhalts verstehen, den Menschen mögen, nicht nur die Flüssigkeit und grammatikalische Korrektheit des generierten Inhalts. sondern auch die Qualität der generierten Inhalte: Nützlichkeit, Authentizität und Unbedenklichkeit.
Wir wissen, dass das Lernen durch Verstärkung das Modelltraining durch einen Belohnungsmechanismus (Belohnung) leitet. Der Belohnungsmechanismus kann als Verlustfunktion des traditionellen Modelltrainingsmechanismus angesehen werden. Die Berechnung der Belohnung ist flexibler und vielfältiger als die Verlustfunktion (die Belohnung von AlphaGO ist das Ergebnis des Spiels. Der Preis hierfür besteht darin, dass die Berechnung der Belohnung nicht differenzierbar ist und daher nicht direkt für die Rückausbreitung verwendet werden kann). . Die Idee des Verstärkungslernens besteht darin, die Verlustfunktion durch eine große Anzahl von Belohnungsproben anzupassen, um ein Modelltraining zu erreichen. In ähnlicher Weise ist auch menschliches Feedback nicht ableitbar, sodass wir künstliches Feedback auch als Belohnung für verstärktes Lernen verwenden können, und je nach Bedarf entstand verstärktes Lernen auf der Grundlage künstlichen Feedbacks.
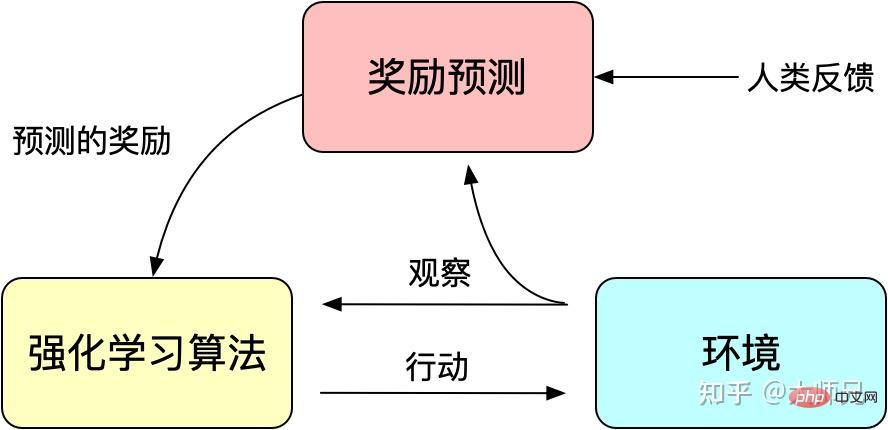
RLHF lässt sich auf „Deep Reinforcement Learning from Human Preferences“ [6] zurückführen, das 2017 von Google veröffentlicht wurde. Es nutzt manuelle Annotationen als Feedback, um die Leistung des Reinforcement Learning bei simulierten Robotern und Atari-Spielen zu verbessern.
Abbildung 3: Das Grundprinzip des verstärkenden Lernens mit künstlichem Feedback
InstructGPT/ChatGPT verwendet auch einen klassischen Algorithmus des verstärkenden Lernens: die kürzlich von OpenAI vorgeschlagene Proximal Policy Optimization (PPO) [7]. Der PPO-Algorithmus ist eine neue Art von Policy-Gradient-Algorithmus. Der Policy-Gradient-Algorithmus reagiert sehr empfindlich auf die Schrittgröße, es ist jedoch schwierig, eine geeignete Schrittgröße zu wählen, wenn der Unterschied zwischen der alten und der neuen Richtlinie zu groß ist groß, es wird schädlich für das Lernen sein. PPO schlug eine neue Zielfunktion vor, mit der Aktualisierungen in kleinen Mengen in mehreren Trainingsschritten erreicht werden können, wodurch das Problem gelöst wird, dass die Schrittgröße im Policy Gradient-Algorithmus schwer zu bestimmen ist. Tatsächlich ist TRPO auch darauf ausgelegt, diese Idee zu lösen, aber im Vergleich zum TRPO-Algorithmus ist der PPO-Algorithmus einfacher zu lösen.
2. Interpretation der InstructGPT/ChatGPT-Prinzipien
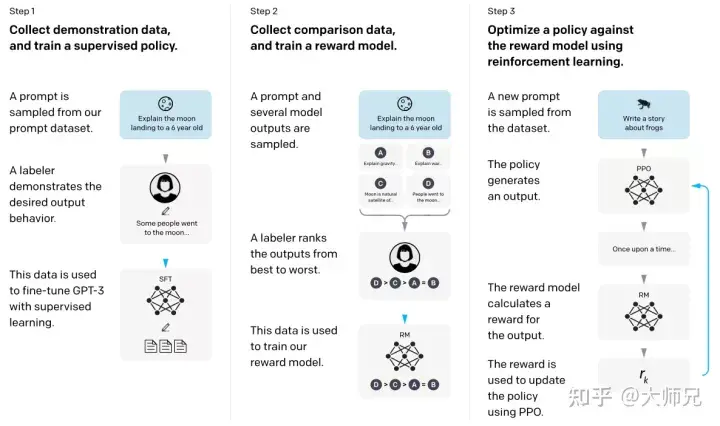
Mit den oben genannten Grundkenntnissen wird es für uns viel einfacher sein, InstructGPT und ChatGPT zu verstehen. Vereinfacht ausgedrückt übernehmen InstructGPT/ChatGPT beide die Netzwerkstruktur von GPT-3 und erstellen Trainingsbeispiele durch Instruktionslernen, um ein Belohnungsmodell (RM) zu trainieren, das die Wirkung vorhergesagter Inhalte widerspiegelt Wird als Leitfaden für das Reinforcement-Learning-Training verwendet. Der Trainingsprozess von InstructGPT/ChatGPT ist in Abbildung 4 dargestellt.
Abbildung 4: InstructGPT-Berechnungsprozess: (1) Supervised Fine-Tuning (SFT); (2) Belohnungsmodell-Training (RM); (3) Verstärkungslernen basierend auf dem Belohnungsmodell durch PPO.
Aus Abbildung 4 können wir ersehen, dass das Training von InstructGPT/ChatGPT in drei Schritte unterteilt werden kann, von denen die Schritte 2 und 3 das Belohnungsmodell und das SFT-Modell für das Verstärkungslernen sind, die iterativ optimiert werden können.
- Überwachte Feinabstimmung (Supervised FineTune, SFT) von GPT-3 basierend auf dem gesammelten SFT-Datensatz durchführen;
- Manuell markierte Vergleichsdaten sammeln und das Belohnungsmodell trainieren (Reword Model, RM);
- RM verwenden als Verstärkung des Lernoptimierungsziels, Verwendung des PPO-Algorithmus zur Feinabstimmung des SFT-Modells.
Gemäß Abbildung 4 werden wir die beiden Aspekte der Datensatzerfassung bzw. des Modelltrainings von InstructGPT/ChatGPT vorstellen.
2.1 Datensatzerfassung
Wie in Abbildung 4 dargestellt, ist das Training von InstructGPT/ChatGPT in drei Schritte unterteilt, und die für jeden Schritt erforderlichen Daten unterscheiden sich ebenfalls geringfügig. Wir werden sie im Folgenden separat vorstellen.
2.1.1 SFT-Datensatz
Der SFT-Datensatz wird im ersten Schritt zum Trainieren des überwachten Modells verwendet, d. h. unter Verwendung der neu gesammelten Daten zur Feinabstimmung von GPT-3 gemäß der Trainingsmethode von GPT-3. Da GPT-3 ein generatives Modell ist, das auf promptem Lernen basiert, ist der SFT-Datensatz auch eine Stichprobe, die aus Prompt-Antwort-Paaren besteht. Ein Teil der SFT-Daten stammt von Benutzern von OpenAIs PlayGround und der andere Teil stammt von den 40 von OpenAI eingesetzten Labelern. Und sie haben den Etikettierer geschult. In diesem Datensatz besteht die Aufgabe des Annotators darin, Anweisungen basierend auf dem Inhalt zu schreiben, und die Anweisungen müssen die folgenden drei Punkte erfüllen:
- Einfache Aufgabe: Der Etikettierer gibt jede einfache Aufgabe aus und stellt gleichzeitig die Vielfalt der Aufgabe sicher.
- Einfache Aufgabe: Der Etikettierer gibt eine Anweisung und die Anweisung ist eine Mehrfachabfrage -entsprechende Paare;
- Benutzerbezogen: Holen Sie sich Anwendungsfälle von der Schnittstelle und lassen Sie den Etikettierer dann Anweisungen basierend auf diesen Anwendungsfällen schreiben.
2.1.2 RM-Datensatz
Der RM-Datensatz wird verwendet, um das Belohnungsmodell in Schritt 2 zu trainieren. Wir müssen auch einen für InstructGPT/ festlegen ChatGPT-Training Bonusziele. Dieses Belohnungsziel muss nicht differenzierbar sein, aber es muss möglichst umfassend und realistisch mit dem übereinstimmen, was das Modell generieren soll. Natürlich können wir diese Belohnung durch manuelle Annotation bereitstellen, indem wir den generierten Inhalten mit Voreingenommenheit niedrigere Bewertungen geben, um das Modell dazu zu ermutigen, keine Inhalte zu generieren, die den Menschen nicht gefallen. Der Ansatz von InstructGPT/ChatGPT besteht darin, das Modell zunächst einen Stapel Kandidatentexte generieren zu lassen und dann den generierten Inhalt mithilfe des Labelers nach der Qualität der generierten Daten zu sortieren.
2.1.3 PPO-Datensatz
Die PPO-Daten von InstructGPT sind nicht mit Anmerkungen versehen, sie stammen von GPT-3-API-Benutzern. Es gibt verschiedene Arten von Generierungsaufgaben, die von verschiedenen Benutzern bereitgestellt werden, wobei der höchste Anteil Generierungsaufgaben (45,6 %), Qualitätssicherung (12,4 %), Brainstorming (11,2 %), Dialog (8,4 %) usw. umfasst.
2.1.4 Datenanalyse
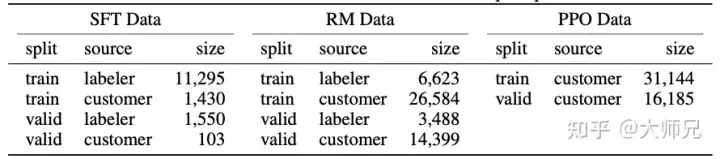
Da InstructGPT/ChatGPT auf der Grundlage von GPT-3 fein abgestimmt sind und manuelle Annotationen erfordern, ist dies bei ihrem Gesamtdatenvolumen nicht der Fall groß, Tabelle 2 zeigt die Quellen der drei Daten und ihr Datenvolumen.
Tabelle 2: Datenverteilung von InstructGPT
In Anhang A des Papiers wird die Verteilung der Daten ausführlicher erörtert. Hier liste ich einige Elemente auf, die sich auf den Modelleffekt auswirken können:
- Mehr als 96 % der Daten sind auf Englisch und die anderen 20 Sprachen wie Chinesisch, Französisch und Spanisch usw. summieren sich auf weniger als 4 %, was dazu führen kann, dass InstructGPT/ChatGPT andere Sprachen generieren kann, aber der Effekt sollte weitaus geringer sein als bei Englisch; und die meisten davon sind Generierungsaufgaben, die dazu führen können, dass das Modell nicht abgedeckt wird.
- 40 Outsourcing-Mitarbeiter kommen aus den Vereinigten Staaten und Südostasien, mit einer relativ konzentrierten Verteilung und Das Ziel von InstructGPT/ChatGPT ist es, ein Pre-Training-Modell mit korrekten Werten zu trainieren. Die Werte sind eine Kombination der Werte dieser 40 ausgelagerten Mitarbeiter. Und diese relativ enge Verteilung kann zu einigen Diskriminierungs- und Vorurteilsproblemen führen, die anderen Regionen größere Sorgen bereiten.
- Darüber hinaus wurde im Blog von ChatGPT erwähnt, dass die Trainingsmethoden von ChatGPT und InstructGPT gleich sind. Der einzige Unterschied besteht darin, dass sie Daten sammeln, es jedoch keine weiteren Informationen gibt, um über die Daten zu sprechen . Welche Details unterscheiden sich in der Sammlung? Wenn man bedenkt, dass ChatGPT nur im Bereich des Dialogs verwendet wird, vermute ich, dass ChatGPT zwei Unterschiede in der Datenerfassung aufweist: 1. Es erhöht den Anteil der Dialogaufgaben. 2. Es wandelt die Eingabeaufforderungsmethode in eine Frage-und-Antwort-Methode um. Dies ist natürlich nur eine Spekulation, bis detailliertere Informationen wie die Dokumente und der Quellcode von ChatGPT veröffentlicht werden.
2.2 Trainingsaufgabe
Wir haben gerade eingeführt, dass InstructGPT/ChatGPT über eine dreistufige Trainingsmethode verfügt. Diese drei Trainingsschritte umfassen drei Modelle: SFT, RM und PPO. Wir werden sie im Folgenden ausführlich vorstellen.
2.2.1 Überwachte Feinabstimmung (SFT)
Das Training dieses Schritts steht im Einklang mit GPT-3, und der Autor hat festgestellt, dass eine angemessene Überanpassung des Modells dazu führt Helfen Sie den nächsten beiden Schritten beim Training.
2.2.2 Belohnungsmodell (RM)
Da die Daten für das Training von RM in Form eines Etikettierers vorliegen, der nach den generierten Ergebnissen sortiert ist, kann es als betrachtet werden Regressionsmodell. Die RM-Struktur ist ein Modell, das die letzte Einbettungsschicht des SFT-trainierten Modells entfernt. Seine Eingaben sind Aufforderung und Reaktion, und seine Ausgabe ist der Belohnungswert. Insbesondere generiert InstructGPT/ChatGPT für jede Eingabeaufforderung zufällig K Ausgaben (4 ≤ K ≤ 9) und zeigt dann die Ausgabeergebnisse paarweise für jeden Etikettierer an, d. h. jede Eingabeaufforderung zeigt dem Benutzer insgesamt CK2-Ergebnisse an wählt unter ihnen die bessere Ausgabe aus. Während des Trainings behandelt InstructGPT/ChatGPT die CK2-Antwortpaare jeder Eingabeaufforderung als Stapel. Bei dieser Trainingsmethode der Stapelverarbeitung nach Eingabeaufforderung ist die Wahrscheinlichkeit einer Überanpassung geringer als bei der herkömmlichen Methode der Stapelverarbeitung nach Stichprobe, da bei dieser Methode jede Eingabeaufforderung in das Modell eingegeben wird nur einmal.
Die Verlustfunktion des Belohnungsmodells wird als Gleichung (1) ausgedrückt. Das Ziel dieser Verlustfunktion besteht darin, den Unterschied zwischen der Antwort, die der Etikettierer bevorzugt, und der Antwort, die er nicht mag, zu maximieren.
(1)loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl )))]
wobei rθ(x,y) der Belohnungswert von Eingabeaufforderung x und Antwort y unter dem Belohnungsmodell mit Parameter θ ist, yw das Antwortergebnis ist, das der Etikettierer bevorzugt, und yl das Antwortergebnis ist, das dem Etikettierer nicht gefällt. D ist der gesamte Trainingsdatensatz.
2.2.3 Reinforcement Learning Model (PPO)
Reinforcement Learning und Pre-Training-Modelle sind zwei der heißesten KI-Richtungen der letzten zwei Jahre. Viele wissenschaftliche Forscher haben gesagt, dass Reinforcement Learning kein sehr geeignetes Pre-Training-Modell ist , weil es schwierig ist, einen Belohnungsmechanismus durch den Ausgabeinhalt des Modells zu etablieren. InstructGPT/ChatGPT erreicht dies auf kontraintuitive Weise. Es führt verstärkendes Lernen in das vorab trainierte Sprachmodell ein, indem es manuelle Annotationen kombiniert, was die größte Innovation dieses Algorithmus darstellt.
Wie in Tabelle 2 gezeigt, stammt der Trainingssatz von PPO vollständig von der API. Es leitet das weitere Training des SFT-Modells durch das in Schritt 2 erhaltene Belohnungsmodell. Reinforcement Learning ist oft sehr schwer zu trainieren. Während des Trainingsprozesses sind bei InstructGPT/ChatGPT zwei Probleme aufgetreten:
- Problem 1: Bei der Aktualisierung des Modells besteht ein Unterschied zwischen den vom Reinforcement-Learning-Modell generierten Daten und den verwendeten Daten Trainiere das Belohnungsmodell. Es wird immer größer. Die Lösung des Autors besteht darin, den KL-Strafterm βlog(πϕRL(y∣x)/πSFT(y∣x)) zur Verlustfunktion hinzuzufügen, um sicherzustellen, dass die Ausgabe des PPO-Modells und die Ausgabe von SFT nicht sehr unterschiedlich sind.
- Problem 2: Die alleinige Verwendung des PPO-Modells für das Training führt zu einem erheblichen Leistungsabfall des Modells bei allgemeinen NLP-Aufgaben. Die Lösung des Autors besteht darin, dem Training ein allgemeines Sprachmodellziel γEx∼Dpretrain [log(πϕRL)“ hinzuzufügen target (x))], diese Variable wird in der Arbeit PPO-ptx genannt.
Zusammenfassend ist das Trainingsziel von PPO Formel (2). (2) Ziel (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain [log( πϕRL(x))]
3. Leistungsanalyse von InstructGPT/ChatGPT
Es ist unbestreitbar, dass die Wirkung von InstructGPT/ChatGPT sehr gut ist, insbesondere nach der Einführung der manuellen Annotation sind die „Werte“ des Modells korrekt Das Niveau und die „Authentizität“ menschlicher Verhaltensmuster wurden erheblich verbessert. Allein auf der Grundlage der technischen Lösungen und Trainingsmethoden von InstructGPT/ChatGPT können wir also analysieren, welche Verbesserungen es mit sich bringen kann?
3.1 Vorteile
- Die Wirkung von InstructGPT/ChatGPT ist realistischer als GPT-3: Dies ist leicht zu verstehen, da GPT-3 selbst über sehr starke Generalisierungsfähigkeiten und Generierung verfügt Funktionen, gepaart mit InstructGPT/ChatGPT, die verschiedene Labeler zum sofortigen Schreiben und Generieren der Ergebnissortierung einführen, und eine Feinabstimmung zusätzlich zu GPT-3, die uns eine höhere Genauigkeit bei realistischeren Daten beim Training des Belohnungsmodells ermöglicht. Der Autor verglich ihre Leistung auch mit GPT-3 im TruthfulQA-Datensatz. Die experimentellen Ergebnisse zeigen, dass selbst der 1,3 Milliarden kleine PPO-ptx eine bessere Leistung erbringt als GPT-3.
- InstructGPT/ChatGPT ist in Bezug auf die Modellharmlosigkeit etwas harmloser als GPT-3: Das Prinzip ist das gleiche wie oben. Der Autor stellte jedoch fest, dass InstructGPT keine signifikante Verbesserung bei Diskriminierung, Vorurteilen und anderen Datensätzen bewirkte. Dies liegt daran, dass GPT-3 selbst ein sehr effektives Modell ist und die Wahrscheinlichkeit, problematische Proben mit schädlichen, diskriminierenden, voreingenommenen usw. Bedingungen zu generieren, sehr gering ist. Das einfache Sammeln und Kennzeichnen von Daten durch 40 Kennzeichner wird das Modell in diesen Aspekten wahrscheinlich nicht vollständig optimieren können, sodass die Verbesserung der Modellleistung gering oder nicht spürbar sein wird.
- InstructGPT/ChatGPT verfügt über starke Codierungsfunktionen: Erstens verfügt GPT-3 über starke Codierungsfunktionen, und auf GPT-3 basierende APIs haben auch eine große Menge an Codierungscode angesammelt. Und auch einige interne Mitarbeiter von OpenAI beteiligten sich an der Datenerfassung. Angesichts der großen Datenmenge im Zusammenhang mit der Codierung und manuellen Annotation ist es nicht verwunderlich, dass das trainierte InstructGPT/ChatGPT über sehr starke Codierungsfunktionen verfügt.
3.2 Nachteile
- InstructGPT/ChatGPT verringert die Wirkung des Modells auf allgemeine NLP-Aufgaben: Wir haben dies während des Trainings von PPO Point besprochen Obwohl eine Änderung der Verlustfunktion das Problem lindern kann, wurde dieses Problem noch nicht vollständig gelöst.
- Manchmal liefert InstructGPT/ChatGPT eine lächerliche Ausgabe: Obwohl InstructGPT/ChatGPT menschliches Feedback verwendet, ist es durch begrenzte personelle Ressourcen begrenzt. Was das Modell am meisten beeinflusst, ist die Aufgabe des überwachten Sprachmodells, bei der der Mensch nur eine korrigierende Rolle spielt. Daher ist es sehr wahrscheinlich, dass es durch die begrenzten Korrekturdaten oder die Irreführung der überwachten Aufgabe (nur unter Berücksichtigung der Ausgabe des Modells, nicht der menschlichen Wünsche) eingeschränkt wird, was zu unrealistischen Inhalten führt, die es generiert. Genau wie bei einem Schüler ist es nicht sicher, dass der Schüler alle Wissenspunkte erlernen kann, obwohl es einen Lehrer gibt, der ihn anleitet.
- Das Modell reagiert sehr empfindlich auf Anweisungen: Dies kann auch auf die unzureichende Menge an vom Etikettierer annotierten Daten zurückgeführt werden, da Anweisungen die einzigen Anhaltspunkte dafür sind, dass das Modell eine Ausgabe erzeugt Wenn die Anweisungen nicht ausreichend geschult sind, kann dies dazu führen, dass das Modell dieses Problem hat.
- Das Modell überinterpretiert einfache Konzepte: Dies kann daran liegen, dass der Labeler beim Vergleich generierter Inhalte tendenziell längere Ausgabeinhalte mit höheren Belohnungen belohnt.
- Schädliche Anweisungen können schädliche Antworten ausgeben: Beispielsweise gibt InstructGPT/ChatGPT auch einen Aktionsplan für den vom Benutzer vorgeschlagenen „Plan zur Zerstörung der Menschheit durch KI“ aus (Abbildung 5). Dies liegt daran, dass InstructGPT/ChatGPT davon ausgeht, dass die vom Labeler geschriebenen Anweisungen angemessen sind und korrekte Werte haben, und keine detaillierteren Beurteilungen der vom Benutzer gegebenen Anweisungen vornimmt, was dazu führt, dass das Modell auf jede Eingabe antwortet. Obwohl das spätere Belohnungsmodell dieser Art von Ausgabe möglicherweise einen niedrigeren Belohnungswert verleiht, muss das Modell beim Generieren von Text nicht nur die Werte des Modells berücksichtigen, sondern auch die Übereinstimmung des generierten Inhalts und der Anweisungen. Manchmal kann es auch zu Problemen bei der Generierung einiger Werte kommen.
Abbildung 5: Plan zur Zerstörung der Menschheit geschrieben von ChatGPT.
3.3 Zukünftige Arbeit
Wir haben die technische Lösung von InstrcutGPT/ChatGPT und ihre Probleme analysiert, dann können wir auch die Optimierungswinkel von InstrcutGPT/ChatGPT sehen.
- Kostenreduzierung und Effizienzsteigerung der manuellen Annotation: InstrcutGPT/ChatGPT beschäftigt ein 40-köpfiges Annotationsteam, aber gemessen an der Leistung des Modells reicht dieses 40-köpfige Team nicht aus. Es ist sehr wichtig, Menschen in die Lage zu versetzen, effektivere Feedbackmethoden bereitzustellen und menschliche Leistung und Modellleistung organisch und geschickt zu kombinieren.
- Die Fähigkeit des Modells, Anweisungen zu verallgemeinern/zu korrigieren: Da das Modell der einzige Anhaltspunkt für die Ausgabe ist, ist es eine sehr wichtige Aufgabe, die Fähigkeit des Modells zu verbessern, Anweisungen zu verallgemeinern und Fehler zu korrigieren Verbessern Sie das Modellerlebnis. Dies ermöglicht dem Modell nicht nur ein breiteres Spektrum an Anwendungsszenarien, sondern macht das Modell auch „intelligenter“.
- Vermeiden Sie allgemeine Verschlechterungen der Aufgabenleistung: Es kann erforderlich sein, eine sinnvollere Art der Nutzung menschlichen Feedbacks oder eine modernere Modellstruktur zu entwickeln. Da wir besprochen haben, dass viele Probleme von InstrcutGPT/ChatGPT durch die Bereitstellung von mehr Labeler-gekennzeichneten Daten gelöst werden können, dies jedoch zu einer schwerwiegenderen Leistungseinbuße bei allgemeinen NLP-Aufgaben führt, sind Lösungen erforderlich, um die Leistung von 3H und allgemeinen NLP-Aufgaben zu verbessern Ergebnisse erzielen.
3.4 InstrcutGPT/ChatGPT-Antworten zu aktuellen Themen
- Wird das Aufkommen von ChatGPT dazu führen, dass Programmierer auf niedriger Ebene ihren Job verlieren? Gemessen an den Prinzipien von ChatGPT und den im Internet durchgesickerten generierten Inhalten können viele der von ChatGPT generierten Codes ordnungsgemäß ausgeführt werden. Die Aufgabe eines Programmierers besteht jedoch nicht nur darin, Code zu schreiben, sondern vor allem darin, Lösungen für Probleme zu finden. Daher wird ChatGPT Programmierer, insbesondere High-Level-Programmierer, nicht ersetzen. Im Gegenteil, es wird für Programmierer ein sehr nützliches Werkzeug zum Schreiben von Code werden, wie viele andere Tools zur Codegenerierung heute.
- Stack Overflow kündigt vorübergehende Regel an: ChatGPT verbieten. ChatGPT ist im Wesentlichen ein Textgenerierungsmodell. Im Vergleich zum Generieren von Code ist es besser in der Lage, gefälschten Text zu generieren. Darüber hinaus ist nicht garantiert, dass der vom Textgenerierungsmodell generierte Code oder die Lösung das Problem lösen kann, aber er wird viele Leute verwirren, die dieses Problem abfragen, indem sie vorgeben, echter Text zu sein. Um die Qualität des Forums aufrechtzuerhalten, hat Stack Overflow ChatGPT gesperrt und räumt ebenfalls auf.
- Der Chatbot ChatGPT wurde veranlasst, einen „Plan zur Zerstörung der Menschheit“ zu schreiben und den Code bereitzustellen. Welche Probleme müssen bei der Entwicklung der KI beachtet werden? ChatGPTs „Plan zur Zerstörung der Menschheit“ ist ein generierter Inhalt, der auf der Grundlage umfangreicher Daten unter unvorhergesehenen Anweisungen gewaltsam angepasst wird. Obwohl der Inhalt sehr real aussieht und der Ausdruck sehr flüssig ist, zeigt dies nur, dass ChatGPT eine sehr starke generative Wirkung hat, aber es bedeutet nicht, dass ChatGPT die Idee hat, die Menschheit zu zerstören. Denn es handelt sich lediglich um ein Textgenerierungsmodell, nicht um ein Entscheidungsmodell.
4. Zusammenfassung
Genau wie die Algorithmen vieler Menschen, als sie zum ersten Mal geboren wurden, hat ChatGPT aufgrund seiner Nützlichkeit, Authentizität und harmlosen Wirkung große Aufmerksamkeit in der Branche und im menschlichen Denken über KI auf sich gezogen. Aber nachdem wir uns die Prinzipien seines Algorithmus angesehen hatten, stellten wir fest, dass er nicht so beängstigend ist, wie in der Branche beworben wird. Im Gegenteil: Wir können aus seinen technischen Lösungen viel Wertvolles lernen. Der wichtigste Beitrag von InstrcutGPT/ChatGPT in der KI-Welt ist die clevere Kombination von Reinforcement Learning und Pre-Training-Modellen. Darüber hinaus verbessert künstliches Feedback den Nutzen, die Authentizität und die Unbedenklichkeit des Modells. ChatGPT hat auch die Kosten für große Modelle weiter erhöht. Früher war es nur ein Wettbewerb zwischen Datenvolumen und Modellgröße.
Referenz
- ^Ouyang, Long, et al. „Sprachmodelle trainieren, um Anweisungen mit menschlichem Feedback zu befolgen.“ *arXiv preprint arXiv:2203.02155* (2022).
- ^Radford, A., Narasimhan, K., Salimans, T. und Sutskever, I., 2018. Verbesserung des Sprachverständnisses durch generatives Vortraining https://www.cs.ubc.ca/~amuham01/LING530 /papers/radford2018improving.pdf
- ^Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. und Sutskever, I., 2019. Sprachmodelle sind unbeaufsichtigte Multitasking-Lernende Blog*, *1*(8), S.9. 9D%E6%8E%A2/Language-Models.pdf
- ^Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. „Sprachmodelle sind Wenig-Schuss-Lerner ." *arXiv preprint arXiv:2005.14165* (2020). https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- ^Wei, Jason, et al. „Feinabgestimmte Sprachmodelle sind Null -shot-Lernende.“ *arXiv preprint arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
- ^Christiano, Paul F., et al. „Deep Reinforcement Learning from Human Preferences.“ *Fortschritte in neuronalen Informationsverarbeitungssystemen* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf
- ^Schulman, John, et al. (2017). https://arxiv.org/pdf/1707.06347.pdf