
Heim >Technologie-Peripheriegeräte >KI >Xishanju-KI-Technikexperte Huang Hongbo: Praktische Integration von Verstärkungslernen und Verhaltensbäumen in Spielen
Xishanju-KI-Technikexperte Huang Hongbo: Praktische Integration von Verstärkungslernen und Verhaltensbäumen in Spielen

- 王林nach vorne
- 2023-04-09 14:31:091897Durchsuche
Am 6. und 7. August 2022 findet die AISummit Global Artificial Intelligence Technology Conference wie geplant statt. Auf dem Unterforum „Artificial Intelligence Frontier Exploration“, das am Nachmittag des 7. stattfand, brachte Huang Hongbo, technischer Experte für künstliche Intelligenz in Xishanju, einen Themenvortrag zum Thema „Praktische Kombination von Verstärkungslernen und Verhaltensbäumen in Spielen“ und erläuterte dabei ausführlich die Auswirkungen der Verstärkung Lernen im Spielbereich.
Huang Hongbo sagte, dass die Implementierung der Reinforcement-Learning-Technologie nicht in der Verbesserung des Algorithmus liegt, sondern in der Kombination der Reinforcement-Learning-Technologie mit Deep Learning und Spielplanung, um eine vollständige Lösung zu bilden und diese umzusetzen.
Reinforcement Learning macht Spiele intelligenter
Die Implementierung von Reinforcement Learning in Spielen kann Spiele intelligenter und spielbarer machen. Dies ist der Hauptzweck des Einsatzes von Reinforcement Learning in Spielen.
„Reinforcement Learning ist ein maschinelles Lernparadigma, das die Strategie des Agenten trainiert, damit eine Reihe von Entscheidungen getroffen werden können.“ Huang Hongbo sagte, dass der Zweck des Agenten darin besteht, Aktionen basierend auf Beobachtungen der Umgebung auszugeben. Diese Aktionen führen zu mehr Beobachtungen und Belohnungen. Das Training erfordert viel Versuch und Irrtum, da der Agent mit der Umgebung interagiert, und die Strategie kann mit jeder Iteration verbessert werden.
In einem Spiel ist der Agent, der Maßnahmen ergreift oder ein Verhalten ausführt, der Spielagent. Betrachten Sie einen Charakter oder einen Roboter in einem Spiel. Er muss den Zustand des Spiels verstehen, wo sich der Spieler befindet, und dann sollte auf der Grundlage dieser Beobachtung eine Entscheidung basierend auf der Situation des Spiels getroffen werden. Beim Reinforcement Learning werden Entscheidungen durch Belohnungen gesteuert, die im Spiel als Highscores oder für das Erreichen neuer Levels zur Erreichung bestimmter Ziele bereitgestellt werden können.
Huang Hongbo sagte, das Coolste an der Spielsituation sei, dass die Strategie des Agenten unter dem Druck des Spiels trainiert werde. Es könnte beispielsweise lernen, mit einem Angriff umzugehen oder sich zu verhalten, um ein bestimmtes Ziel zu erreichen.
Die Rolle des Verhaltensbaums im Spiel
Ein Verhaltensbaum ist eine Baumstruktur, die logische Knoten und Verhaltensknoten enthält. Normalerweise können Sie jede Situation in einen Knotentyp abstrahieren, die Knoten gemäß den Spezifikationen schreiben und diese Knoten dann zu einem Baum verbinden. Jedes Mal, wenn der Benutzer nach einem Verhalten sucht, beginnt er beim Wurzelknoten des Baums und findet ein Verhalten, das mit den aktuellen Daten jedes Knotens übereinstimmt.
Einfach ausgedrückt: Wenn der Kopplungsgrad jedes KI-Moduls hoch und die Granularität groß ist, erfordert eine Änderung häufig eine große Anzahl von Änderungen, und es kann leicht zu einer großen Menge doppelten Codes kommen. Das Aufkommen von Verhaltensbäumen hat Spieleentwicklern ein „quadratisches Notizbuch“ zur Verfügung gestellt, das es KI-Entwicklern ermöglicht, bequemer eine Reihe von KI-Frameworks zu erstellen, die wiederverwendbar, einfach zu erweitern und zu warten sind. Man kann sagen, dass Verstärkungslernen durch Training erreicht wird und der Verhaltensbaum eine Kombination aus mehreren else- und if-Anweisungen ist.
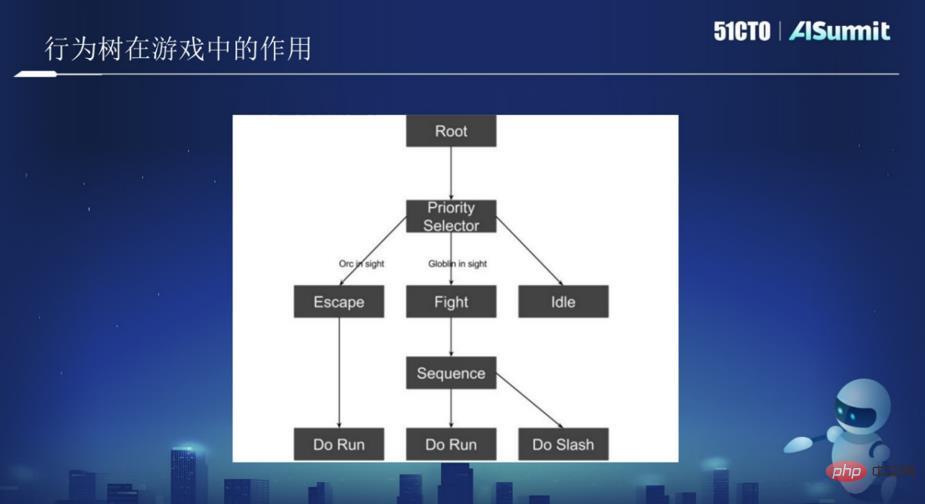
Wie im Bild oben gezeigt, gibt es im Bild einen Wurzelknoten und darunter einen Baumknoten. Zu den Baumknoten gehören Flucht, Angriff, Wandern usw. Stellen Sie sich das Bild oben als eine KI oder einen Roboter vor und lassen Sie ihn durch den Dschungel patrouillieren. Wenn die KI einen ORC-Ork sieht und feststellt, dass sie den ORC nicht besiegen kann, wenn diese Bedingung ausgelöst wird, rennt die KI weg und führt bei der Flucht die Aktion „Run“ aus. Wenn festgestellt wird, dass das Kämpfen einfacher ist, wird die Kampfoperation ausgeführt.
Im Bild oben gibt es zwei Knoten, einen ist Root, der der Wurzelknoten ist, und einer ist der Selector-Knoten, der der logische Knoten ist. Alle Knoten werden in einer bestimmten Reihenfolge von links nach rechts ausgeführt. Dies ist ein Verhaltensbaum. Daher müssen Sie nur die entsprechende Logik in jeden Knoten schreiben, damit die KI einige verwandte Aktionen ausführen kann. Mehrere Verhaltensbäume bilden schließlich ein Spiel.
Die Kombination aus Verstärkungslernen und Verhaltensbäumen macht das Spiel reicher.
Wie kann man die Kombination aus Verstärkungslernen und Verhaltensbäumen nutzen, um das Spiel reicher zu machen? Dies ist eine schwierige Anwendung, die in vielen Spielen besprochen werden muss.
Lasst uns vorher besprechen, wann es besser ist, Reinforcement Learning einzusetzen und unter welchen Umständen es besser ist, Verhaltensbäume zu nutzen. Huang Hongbo sagte, dass, wenn es keine Möglichkeit gibt, das Ziel mithilfe von Verhaltensbäumen zu erreichen, Verstärkungslernen eingesetzt werden kann. Beispielsweise kann bei FPS (Ego-Shooter) ermittelt werden, wie viel Feuerkraft eingesetzt werden sollte, auf wen geschossen werden sollte und auf welche Art Anzahl der Waffen usw. Es ist schwieriger, Entscheidungen mithilfe von Verhaltensbäumen zu treffen. Im Allgemeinen ist es besser, Verstärkungslernen zu verwenden.
Wann werden Verhaltensbäume verwendet? Wenn Sie beispielsweise im Spiel auf ein Hindernis stoßen und darüber springen müssen, können Sie dafür entweder Verstärkungslernen oder einen Verhaltensbaum verwenden. Aber wenn wir dazu Verstärkungslernen nutzen, wird das Training sehr mühsam sein. Da es in dieser Situation nur eine Möglichkeit gibt, nämlich zu überspringen, ist es einfacher, einen Verhaltensbaum zu verwenden.
Es ist nicht schwer herauszufinden, dass es eine bessere Lösung ist, wenn Verstärkungslernen und Verhaltensbäume kombiniert und in Spielen verwendet werden. Huang Hongbo sagte, dass es zwei relativ große Implementierungsmethoden für die Kombination von Verstärkungslernen und Verhaltensbäumen gibt: Eine basiert auf Verstärkungslernen und wird durch Verhaltensbäume ergänzt. Die andere basiert auf Verhaltensbäumen und wird durch Verstärkungslernen ergänzt.
Verhaltensbaumseite: Mit dem Verhaltensbaum als Haupt-KI-Bewegungsmethode empfängt der Verhaltensbaum Obs-Eingaben vom Spielclient und schreibt entsprechende Verhaltensbaumverhaltensweisen für Obs entsprechend seiner eigenen Zielsituation in jedem Verhalten des Verhaltensbaums , einige Knoten, die Verstärkungslernen erfordern, um Entscheidungen zu treffen, werden an Verstärkungslernen übergeben. Dann ist hier Verstärkungslernen erforderlich, um entsprechendes Training für einige spezifische Szenarien durchzuführen.
Verstärkungslernseite: Die Gesamtstrategie besteht darin, mehrere Modelle zu trainieren, jedes Modell führt eine Strategie aus und bettet sie dann in den Verhaltensbaum ein.
Huang Hongbo sagte, dass von diesen beiden verschiedenen Implementierungsmethoden, welche besser ist, unterschiedliche Überlegungen basierend auf unterschiedlichen Situationen, unterschiedlichen Anwendungen und unterschiedlichen Spielen erforderlich sind, sodass dies nicht verallgemeinert werden kann.
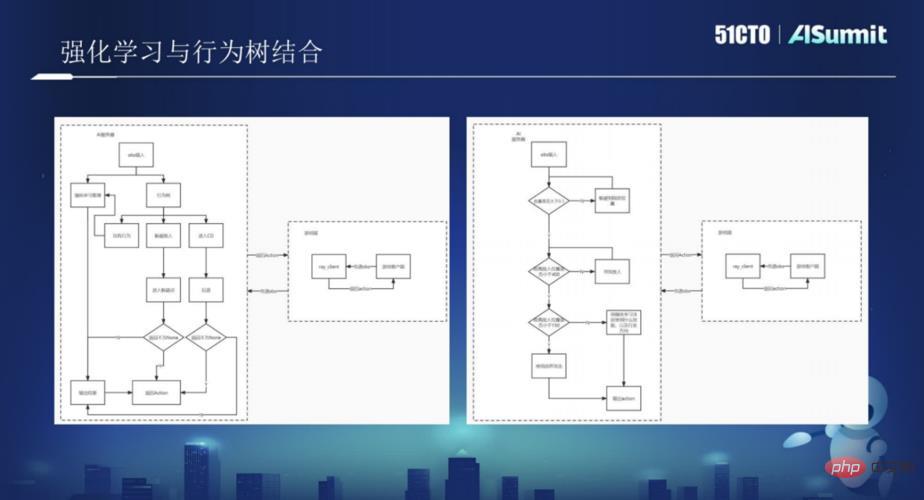
Im Folgenden stellte Huang Hongbo das von Xishanju übernommene technische Framework für Verstärkungslernen und Verhaltensbäume detailliert vor und stellte in Kombination mit einer großen Anzahl von Spielfällen detailliert vor, wie Verhaltensbäume und Verstärkungslernen verwendet werden Spiele. Kombinieren Sie sie, um das Spiel reicher zu machen. Benutzer, die sich für die Fallpraxis interessieren, sollten sich vielleicht die wunderbaren Sharing-Videos der AISummit Global Artificial Intelligence Technology Conference ansehen. (https://www.php.cn/link/53253027fef2ab5162a602f2acfed431)
Das obige ist der detaillierte Inhalt vonXishanju-KI-Technikexperte Huang Hongbo: Praktische Integration von Verstärkungslernen und Verhaltensbäumen in Spielen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr