
Heim >Technologie-Peripheriegeräte >KI >Ohne Parameter zu häufen oder sich auf die Zeit zu verlassen, beschleunigt Meta den ViT-Trainingsprozess und erhöht den Durchsatz um das Vierfache.
Ohne Parameter zu häufen oder sich auf die Zeit zu verlassen, beschleunigt Meta den ViT-Trainingsprozess und erhöht den Durchsatz um das Vierfache.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 09:21:071003Durchsuche
In diesem Stadium wird das Visual Transformer (ViT)-Modell häufig in verschiedenen Computer-Vision-Aufgaben wie Bildklassifizierung, Zielerkennung und -segmentierung eingesetzt und kann SOTA-Ergebnisse bei der visuellen Darstellung und Erkennung erzielen. Da die Leistung von Computer-Vision-Modellen oft positiv mit der Anzahl der Parameter und der Trainingszeit korreliert, hat die KI-Community mit immer größeren ViT-Modellen experimentiert.
Aber es sollte beachtet werden, dass das Feld auf einige große Engpässe gestoßen ist, da die Modelle beginnen, die Größenordnung von Teraflops zu überschreiten. Das Training eines einzelnen Modells kann Monate dauern und Tausende von GPUs erfordern, was die Anforderungen an Beschleuniger erhöht und zu umfangreichen ViT-Modellen führt, die viele Praktiker ausschließen.
Um den Einsatzbereich des ViT-Modells zu erweitern, haben Meta-KI-Forscher effizientere Trainingsmethoden entwickelt. Es ist sehr wichtig, das Training für eine optimale Beschleunigernutzung zu optimieren. Dieser Prozess ist jedoch zeitaufwändig und erfordert erhebliches Fachwissen. Um ein geordnetes Experiment auf die Beine zu stellen, müssen Forscher aus unzähligen möglichen Optimierungen wählen: Jede der Millionen von Operationen, die während einer Trainingssitzung durchgeführt werden, kann durch Ineffizienzen behindert werden.
Meta AI hat herausgefunden, dass es die Rechen- und Speichereffizienz verbessern kann, indem es eine Reihe von Optimierungen auf die ViT-Implementierung in seiner Bildklassifizierungs-Codebasis PyCls anwendet. Bei ViT-Modellen, die mit PyCIs trainiert wurden, kann die Methode von Meta AI die Trainingsgeschwindigkeit und den Durchsatz pro Beschleuniger (TFLOPS) verbessern.
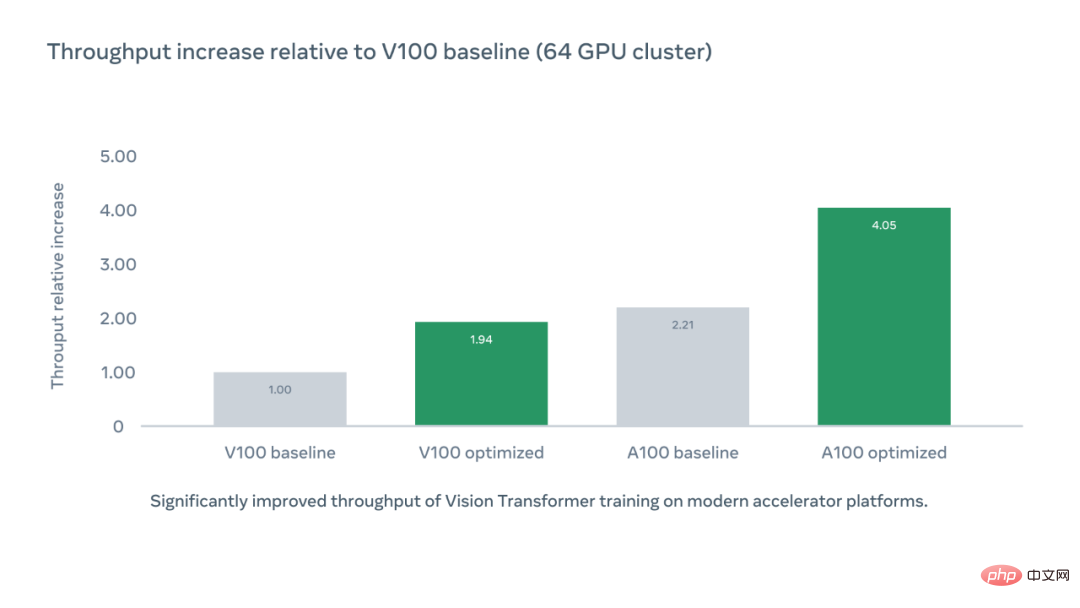
Die folgende Grafik zeigt den relativen Anstieg des Beschleunigerdurchsatzes pro Chip im Vergleich zur V100-Basislinie unter Verwendung der optimierten Codebasis-PyCIs. Der A100-optimierte Beschleunigerdurchsatz beträgt das 4,05-fache des V100-Basislinie.
Wie es funktioniert
Meta AI analysierte zunächst die PyCIs-Codebasis, um potenzielle Ursachen für eine geringe Trainingseffizienz zu identifizieren, und konzentrierte sich schließlich auf die Wahl der Zahlenformate. Standardmäßig verwenden die meisten Anwendungen ein 32-Bit-Gleitkommaformat mit einfacher Genauigkeit, um neuronale Netzwerkwerte darzustellen. Die Konvertierung in ein 16-Bit-Format mit halber Genauigkeit (FP16) kann den Speicherbedarf und die Ausführungszeit eines Modells reduzieren, verringert jedoch häufig auch die Genauigkeit.
Die Forscher wählten eine Kompromisslösung, nämlich gemischte Präzision. Damit führt das System Berechnungen in einem Format mit einfacher Genauigkeit durch, um das Training zu beschleunigen und den Speicherverbrauch zu reduzieren, während die Ergebnisse gleichzeitig in einfacher Genauigkeit gespeichert werden, um die Genauigkeit aufrechtzuerhalten. Anstatt Teile des Netzwerks manuell in Halbpräzision umzuwandeln, experimentierten sie mit verschiedenen Modi des automatischen Mixed-Precision-Trainings, das automatisch zwischen digitalen Formaten wechselt. Die automatische gemischte Präzision in fortgeschritteneren Modi basiert hauptsächlich auf Operationen mit halber Genauigkeit und Modellgewichten. Die von den Forschern verwendeten ausgewogenen Einstellungen können das Training erheblich beschleunigen, ohne dass die Genauigkeit darunter leidet.
Um den Prozess effizienter zu gestalten, nutzten die Forscher den Trainingsalgorithmus Fully Sharder Data Parallel (FSDP) in der FairScale-Bibliothek, der Parameter, Verläufe und Optimiererzustände auf der GPU fragmentiert. Durch den FSDP-Algorithmus können Forscher mit weniger GPUs größere Modelle erstellen. Darüber hinaus haben wir den MTA-Optimierer, einen gepoolten ViT-Klassifikator und ein Batch-Second-Input-Tensor-Layout verwendet, um redundante Transponierungsoperationen zu überspringen.
Die X-Achse der folgenden Abbildung zeigt mögliche Optimierungen und die Y-Achse zeigt die relative Steigerung des Beschleunigerdurchsatzes im Vergleich zum DDP-Benchmark (Distributed Data Parallel) beim Training mit ViT-H/16.
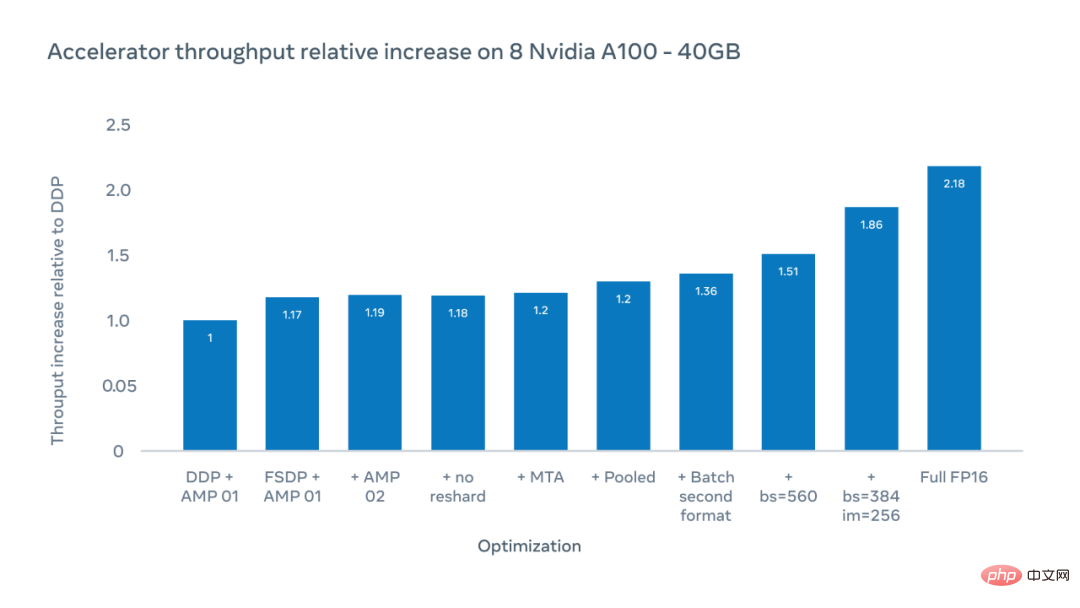
Die Forscher erreichten eine 1,51-fache Steigerung des Beschleunigerdurchsatzes, gemessen als Anzahl der pro Sekunde auf jedem Beschleunigerchip ausgeführten Gleitkommaoperationen, bei einer Gesamtpatchgröße von 560. Durch die Erhöhung der Bildgröße von 224 Pixel auf 256 Pixel konnten sie den Durchsatz auf das 1,86-fache steigern. Eine Änderung der Bildgröße bedeutet jedoch eine Änderung der Hyperparameter, was sich auf die Genauigkeit des Modells auswirkt. Beim Training im vollständigen FP16-Modus erhöht sich der relative Durchsatz auf das 2,18-fache. Obwohl die Genauigkeit manchmal verringert war, verringerte sich die Genauigkeit in Experimenten um weniger als 10 %.
Die Y-Achse der folgenden Abbildung ist die Epochenzeit, die Dauer des letzten Trainings für den gesamten ImageNet-1K-Datensatz. Hier konzentrieren wir uns auf tatsächliche Trainingszeiten für bestehende Konfigurationen, die typischerweise eine Bildgröße von 224 Pixeln verwenden.
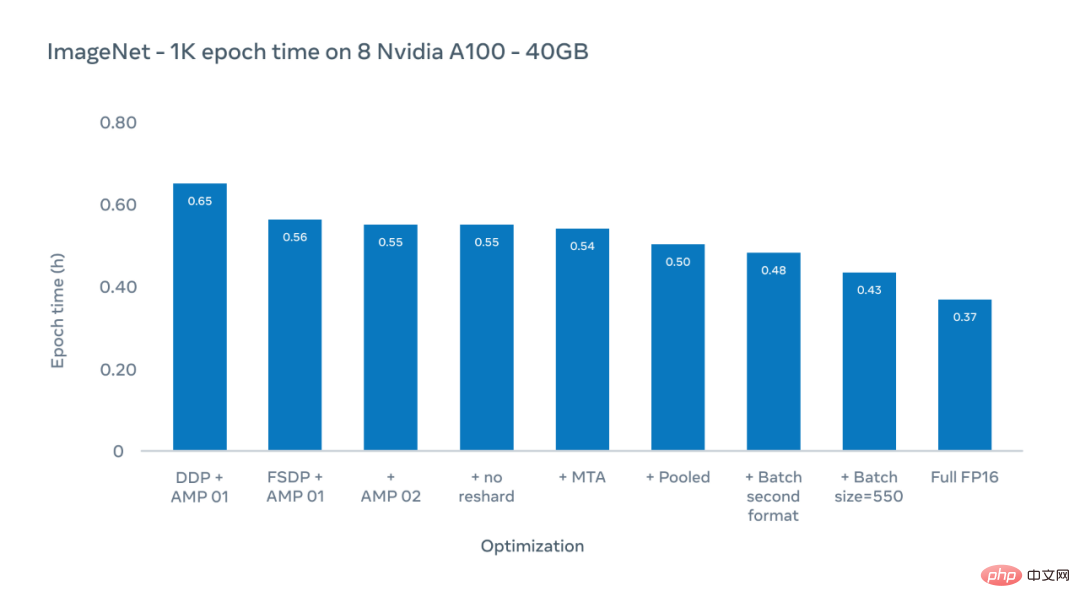
Meta-KI-Forscher verwendeten ein Optimierungsschema, um die Epochenzeit (die Dauer einer Trainingssitzung für den gesamten ImageNet-1K-Datensatz) von 0,65 Stunden auf 0,43 Stunden zu reduzieren.
Die X-Achse der folgenden Abbildung stellt die Anzahl der A100-GPU-Beschleunigerchips in einer bestimmten Konfiguration dar, und die Y-Achse stellt den absoluten Durchsatz in TFLOPS pro Chip dar.
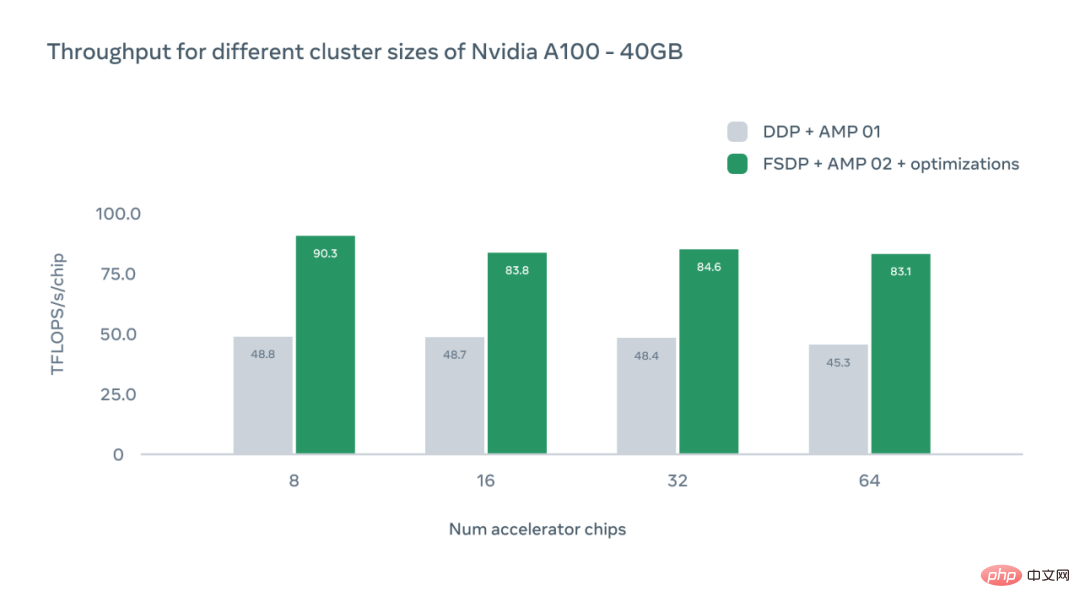
Die Studie diskutiert auch die Auswirkungen verschiedener GPU-Konfigurationen. In jedem Fall erreichte das System einen höheren Durchsatz als das DDP-Basisniveau (Distributed Data Parallel). Mit zunehmender Anzahl an Chips können wir aufgrund des Overheads der Kommunikation zwischen Geräten einen leichten Rückgang des Durchsatzes beobachten. Allerdings ist Metas System selbst mit 64 GPUs 1,83-mal schneller als der DDP-Benchmark.
Bedeutung neuer Forschungsergebnisse
Durch die Verdoppelung des erreichbaren Durchsatzes beim ViT-Training kann die Größe des Trainingsclusters effektiv verdoppelt werden, und durch die Verbesserung der Beschleunigerauslastung werden die CO2-Emissionen von KI-Modellen direkt reduziert. Da die jüngste Entwicklung großer Modelle den Trend zu größeren Modellen und längeren Trainingszeiten mit sich gebracht hat, wird erwartet, dass diese Optimierung dem Forschungsbereich dabei helfen wird, den Stand der Technik weiter voranzutreiben, die Durchlaufzeiten zu verkürzen und die Produktivität zu steigern.
Das obige ist der detaillierte Inhalt vonOhne Parameter zu häufen oder sich auf die Zeit zu verlassen, beschleunigt Meta den ViT-Trainingsprozess und erhöht den Durchsatz um das Vierfache.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr