
Heim >Technologie-Peripheriegeräte >KI >Der Weg zur praktischen Umsetzung der intelligenten Sprachtechnologie von Soul
Der Weg zur praktischen Umsetzung der intelligenten Sprachtechnologie von Soul

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 09:21:031295Durchsuche
Autor|. Liu Zhongliang
Zusammenstellung|. Lu Im sozialen Bereich stellt die intelligente Sprachtechnologie höhere Anforderungen.
Vor ein paar Tagen hielt Liu Zhongliang, der Leiter des Sprachalgorithmus von Soul, auf der AISummit Global Artificial Intelligence Technology Conference, die von 51CTO veranstaltet wurde, eine Grundsatzrede mit dem Titel „The Road to Practicing Soul Intelligent Voice Technology“, die auf einigen davon basiert Souls Geschäftsszenarien und Shared Soul verfügen über einige praktische Erfahrungen in der intelligenten Sprachtechnologie.
Der Inhalt der Rede ist nun wie folgt aufgebaut, in der Hoffnung, alle zu inspirieren.
Souls Sprachanwendungsszenario
Soul ist ein immersives soziales Szenario, das auf der Grundlage von Interessendiagrammen empfohlen wird. In diesem Szenario gibt es viele Sprachaustausche, sodass in der vergangenen Zeit viele Daten gesammelt wurden. Gegenwärtig gibt es etwa Millionen Stunden pro Tag. Wenn man bei Sprachanrufen etwas Stille, Lärm usw. herausnimmt und nur diese aussagekräftigen Audioclips zählt, ergeben sich etwa 6 bis 7 Milliarden Audioclips. Die Hauptzugänge zum Voice-Geschäft von Soul sind wie folgt:Voice Party
Gruppen können Räume erstellen, in denen viele Benutzer Voice-Chats führen können.Video-Party
Tatsächlich möchten die meisten Benutzer der Soul-Plattform ihr Gesicht nicht zeigen oder sich bloßstellen. Deshalb haben wir ein selbst entwickeltes 3D-Avatar-Bild oder eine Kopfbedeckung erstellt, die Benutzer verwenden können, um den Benutzern zu helfen, sich mehr auszudrücken sich gut ausdrücken oder sich ohne Druck ausdrücken.Werwolf-Spiel
ist auch ein Raum, in dem viele Leute das Spiel zusammen spielen können.Voice Matching
Ein einzigartigeres Szenario ist Voice Matching, oder es ist dasselbe wie ein Anruf bei WeChat, das heißt, Sie können eins zu eins chatten.Basierend auf diesen Szenarien haben wir selbst entwickelte Sprachfunktionen entwickelt, die sich hauptsächlich auf zwei Hauptrichtungen konzentrieren: Die erste ist die natürliche Mensch-Computer-Interaktion und die zweite das Verständnis und die Generierung von Inhalten. Es gibt vier Hauptaspekte: Der erste ist Spracherkennung und Sprachsynthese; der zweite ist Sprachanalyse und Sprachanimation. Das Bild unten zeigt die von uns verwendeten gängigen Sprachtools, zu denen hauptsächlich Sprachanalyse, wie Klangqualität, Soundeffekte usw., gehören Musik. Dann gibt es noch die Spracherkennung, wie z. B. die Erkennung von Chinesisch, die Erkennung von Gesangsstimmen und das gemischte Lesen von Chinesisch und Englisch. Die dritte bezieht sich auf die Sprachsynthese, beispielsweise Unterhaltungsumwandlung, Sprachumwandlung und Angelegenheiten im Zusammenhang mit der Gesangssynthese. Die vierte ist die Sprachanimation, die hauptsächlich einige textgesteuerte Mundformen, sprachgesteuerte Mundformen und andere Sprachanimationstechnologien umfasst.
Basierend auf diesen Sprachalgorithmusfunktionen verfügen wir über viele Sprachanwendungsformen, wie z. B. Sprachqualitätserkennung, einschließlich Verbesserung, Sprachüberprüfung, Textsynchronisation, Sprachthemen, virtuelle Umgebungsgeräusche, wie diese räumlichen 3D-Soundeffekte , usw. . Im Folgenden finden Sie eine Einführung in die Technologien, die in den beiden Geschäftsszenarien Sprachüberprüfung und Avatar verwendet werden.
Überprüfung von Sprachinhalten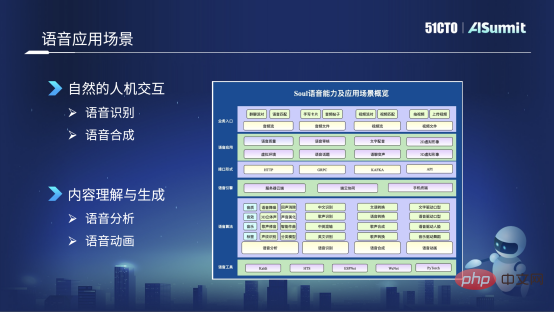
End-to-End-Spracherkennungssystem
Das Bild unten ist ein End-to-End-Spracherkennungs-Framework, das wir derzeit verwenden. Zunächst wird ein Fragment des Benutzeraudios zur Merkmalsextraktion erfasst Derzeit verwendete Funktionen Wir haben hauptsächlich Alfa-Bank-Funktionen verwendet und in einigen Szenarien versucht, vorab trainierte Funktionen wie Wav2Letter zu verwenden. Nach Erhalt der Audiofunktionen wird eine Endpunkterkennung durchgeführt, die erkennt, ob die Person spricht und ob der Audioclip eine menschliche Stimme hat. Derzeit werden im Wesentlichen einige klassische Energie-VD und Modell-DNVD verwendet.
Nachdem wir diese Funktionen erhalten haben, senden wir sie an ein akustisches Bewertungsmodul. Zu Beginn haben wir Transformer CDC für dieses akustische Modell verwendet, und es wurde nun zu Conformer CDC iteriert. Nach dieser akustischen Bewertung senden wir eine Reihe von Sequenzbewertungen an den Decoder. Der Decoder ist für die Dekodierung des Textes verantwortlich und führt basierend auf den Erkennungsergebnissen eine zweite Bewertung durch. In diesem Prozess verwenden wir im Wesentlichen einige Modelle wie das traditionelle EngelM-Modell und einige derzeit gängigere Transformer-Deep-Learning-Modelle für die Neubewertung. Schließlich werden wir auch eine Nachbearbeitung durchführen, wie z. B. eine gewisse Zeichensetzungserkennung, Textregulierung, Satzglättung usw., und schließlich ein aussagekräftiges und genaues Texterkennungsergebnis erhalten, wie z. B. „2022 Global Artificial Intelligence Conference“.
Im End-to-End-Spracherkennungssystem sprechen wir tatsächlich hauptsächlich im akustischen Bewertungsteil. Wir verwenden Ende -to-End-Technologie und andere Hauptsächlich einige traditionelle und einige klassische Deep-Learning-Methoden.
Beim Aufbau des oben genannten Systems sind wir tatsächlich auf viele Probleme gestoßen:
# 🎜🎜## 🎜🎜#- zu wenig überwachte akustische Daten Das ist auch etwas, dem normalerweise jeder begegnet. Die Hauptgründe sind: Zuerst müssen Sie sich das Audio anhören, bevor Sie es mit Anmerkungen versehen können. Zweitens sind auch die Etikettierungskosten sehr hoch. Daher ist das Fehlen dieses Teils der Daten ein allgemeines Problem für alle.
- Der Modellerkennungseffekt ist schlecht Dafür gibt es viele Gründe. Der erste Grund besteht darin, dass beim Lesen von gemischtem Chinesisch und Englisch oder in mehreren Bereichen die Verwendung eines allgemeinen Modells zur Identifizierung relativ schlecht ist.
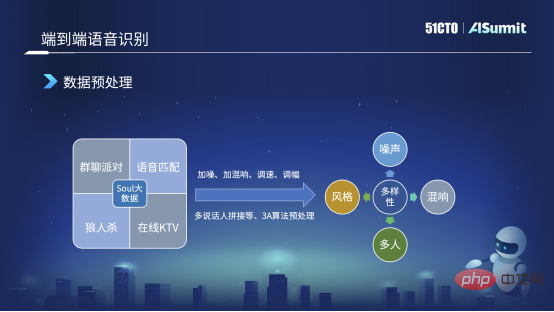
- Das Modell ist langsam wenige Wir lösen dieses Problem hauptsächlich auf die folgenden drei Arten. Datenvorverarbeitung
Zusätzlich zu diesen Methoden werden wir eine gezielte Datenvorverarbeitung oder Datenerweiterung durchführen, um einige Probleme zu beheben, die in unseren Geschäftsszenarien auftreten. Ich habe zum Beispiel gerade erwähnt, dass es bei einer Gruppenchat-Party leicht zu Überlappungen mehrerer Sprecher kommen kann. Deshalb werden wir ein Audio-Splicing mit mehreren Sprechern erstellen, was bedeutet, dass wir die Audioclips der drei Sprecher ABC ausschneiden und tun es zusammen. Datenerweiterung.
Da einige Audio- und Videoanrufe eine grundlegende 3D-Algorithmus-Vorverarbeitung für das gesamte Audio-Frontend durchführen, z. B. automatische Echounterdrückung, intelligente Rauschunterdrückung usw. Daher gilt: Wir werden auch einige Vorverarbeitungen von 3D-Algorithmen durchführen, um sie an Online-Nutzungsszenarien anzupassen.
Nach der Datenvorverarbeitung auf diese Weise können wir eine Vielzahl von Daten erhalten, z. B. Daten mit Rauschen, etwas Nachhall, mehreren Personen oder sogar mehreren Stilen. Diese Art von Daten wird erweitert. Wir erweitern beispielsweise 10.000 Stunden auf etwa 50.000 Stunden oder sogar 80.000 bis 90.000 Stunden. In diesem Fall wird die Abdeckung und Breite der Daten sehr hoch sein.
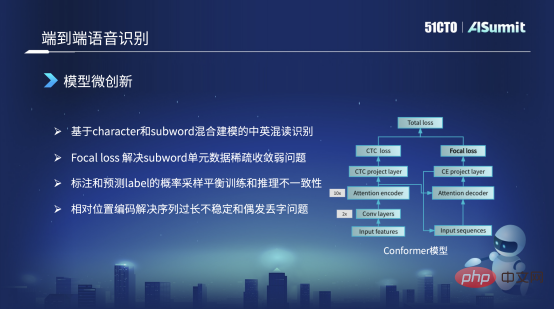
Modell-Mikroinnovation
Das Hauptgerüst des von uns verwendeten Modells ist immer noch die Konformerstruktur. Auf der linken Seite dieser Conformer-Struktur befindet sich das klassische Encoder-CDC-Framework. Auf der rechten Seite befindet sich ein Achtung-Decoder. Aber allen ist aufgefallen, dass im Loss auf der rechten Seite die ursprüngliche Conformer-Struktur ein CE-Loss war und wir sie hier durch einen Focal Loss ersetzt haben. Der Hauptgrund ist, dass wir Focal Loss verwenden, um das Problem der Nichtkonvergenz von spärlichen Einheiten und spärlichem Datentraining zu lösen, oder das Problem des schlechten Trainings, das gelöst werden kann.
Der zweite Punkt ist, dass unsere Trainingsstrategie zum Beispiel auch einige gemischte Trainingsmethoden in der Trainingsstrategie verwenden wird. Wenn wir beispielsweise den Dekodierteil der Eingabe trainieren, werden wir dies tun Verwenden Sie Präzisionstraining. Die Ziel-Label-Sequenzdaten werden als Eingabe verwendet. Aber wenn das Trainingsmodell konvergiert, werden wir in der späteren Phase einen Teil der vorhergesagten Etiketten mit einer bestimmten Wahrscheinlichkeit als Eingabe des Decoders abtasten, um einige Tricks auszuführen. Was löst dieser Trick hauptsächlich? Es ist das Phänomen, dass die Eingabemerkmale des Trainingsmodells und des Online-Inferenzmodells inkonsistent sind. Auf diese Weise können wir einen Teil davon lösen.
Aber es gibt noch ein anderes Problem: Im ursprünglichen Conformer-Modell oder dem von Vnet oder ESPnet bereitgestellten Modell sind die absoluten Positionsinformationen standardmäßig. Allerdings können absolute Positionsinformationen das Identifikationsproblem nicht lösen, wenn die Sequenz zu lang ist. Daher werden wir die absoluten Positionsinformationen in relative Positionscodierung umwandeln, um dieses Problem zu lösen. Auf diese Weise können auch Probleme gelöst werden, die während des Erkennungsprozesses auftreten, wie z. B. die Wiederholung einiger Wörter oder der gelegentliche Verlust von Wörtern oder Wörtern.
Inferenzbeschleunigung
Das erste ist das akustische Modell. Wir werden das autoregressive Modell auf diese Methode basierend auf der Encoder-CDC+WFST-Dekodierung ändern und zunächst einen Teil der Erkennungsergebnisse lösen, wie z. B. NBest. 10beste oder 20beste. Basierend auf 20best senden wir es für eine zweite Neubewertung an Decorde Rescore. Dadurch können Zeitabhängigkeiten vermieden und die parallele Berechnung oder Argumentation von GPT erleichtert werden.
Zusätzlich zur klassischen Beschleunigungsmethode verwenden wir auch eine hybride Quantifizierungsmethode, das heißt, im Prozess des Deep Learning Forward Reasoning verwenden wir 8Bit für einen Teil der Berechnung, jedoch im Kernteil, beispielsweise im Finanzbereich Funktionen Wir verwenden für diesen Teil immer noch 16bit, hauptsächlich weil wir ein angemessenes Gleichgewicht zwischen Geschwindigkeit und Genauigkeit herstellen wollen.
Nach diesen Optimierungen ist die gesamte Inferenzgeschwindigkeit relativ hoch. Aber während unseres eigentlichen Startvorgangs haben wir auch einige kleine Probleme entdeckt, die meiner Meinung nach als Trick angesehen werden können.
Auf der Ebene des Sprachmodells gibt es in unserer Szene zum Beispiel viel Chat-Text, aber es gibt auch Gesang. Wir brauchen das gleiche Modell, um sowohl das Sprechen als auch das Singen zu lösen. In Bezug auf Sprachmodelle wie Chat-Text ist dieser normalerweise fragmentiert und kurz. Nach unseren Experimenten stellten wir fest, dass das Drei-Elemente-Modell besser ist, das Fünf-Elemente-Modell jedoch keine Verbesserung brachte.
Aber zum Beispiel ist der Text beim Singen relativ lang und die Satzstruktur und Grammatik relativ fest, sodass während des Experiments fünf Yuan besser sind als drei Yuan. In diesem Fall verwenden wir eine Hybridgrammatik, um das Sprachmodell des Chattexts und des Gesangstexts gemeinsam zu modellieren. Wir verwenden das Mischmodell „Drei Yuan + Fünf Yuan“, aber diese „Drei Yuan + Fünf Yuan“-Mischung ist kein Unterschied im herkömmlichen Sinne. Wir machen keinen Unterschied, sondern verwenden die Drei-Yuan-Grammatik des Chattens Nehmen Sie den Vier-Yuan-Gesang und die Fünf-Yuan-Grammatik und verschmelzen Sie sie direkt. Das auf diese Weise erhaltene Arpa ist derzeit kleiner und schneller im Decodierungsprozess. Noch wichtiger ist, dass es weniger Videospeicher beansprucht. Denn beim Dekodieren auf der GPU ist die Videospeichergröße festgelegt. Daher müssen wir die Größe des Sprachmodells bis zu einem gewissen Grad steuern, um den Erkennungseffekt durch das Sprachmodell so weit wie möglich zu verbessern.
Nach einigen Optimierungen und Tricks des akustischen Modells und des Sprachmodells ist unsere aktuelle Inferenzgeschwindigkeit auch sehr hoch. Die Echtzeitrate kann grundsätzlich das Niveau von 0,1 oder 0,2 erreichen.

Virtuelle Simulation
hilft Benutzern vor allem dabei, sich stressfreier oder natürlicher und freier auszudrücken, indem sie Geräusche, Mundformen, Ausdrücke, Körperhaltungen usw. erzeugt. Die Kerntechnologie dahinter ist die multimodale Sprachsynthese.
Multimodale Sprachsynthese
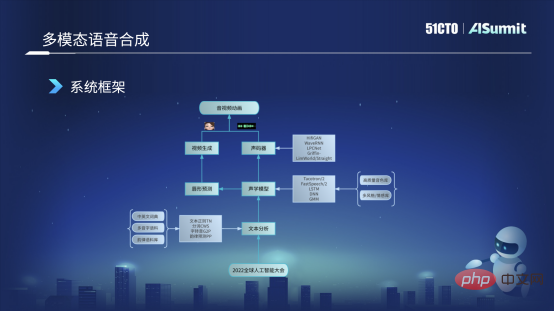
Die folgende Abbildung zeigt das Grundgerüst des derzeit verwendeten Sprachsynthesesystems. Zuerst erhalten wir den Eingabetext des Benutzers, z. B. „2022 Global Artificial Intelligence Conference“, und senden ihn dann an das Textanalysemodul. Dieses Modul analysiert den Text hauptsächlich unter verschiedenen Aspekten, z. B. der Textregulierung und einigen Wörtern Segmentierung, das Wichtigste ist die Selbstübertragung, die Umwandlung von Wörtern in Phoneme sowie einige Reimvorhersage- und andere Funktionen. Nach dieser Textanalyse können wir einige sprachliche Merkmale des Satzes des Benutzers ermitteln und diese Merkmale an das akustische Modell senden. Für das akustische Modell verwenden wir derzeit hauptsächlich einige Modellverbesserungen und Schulungen basierend auf dem FastSpeech-Framework.
Das akustische Modell erhält akustische Merkmale wie Mel-Merkmale oder Informationen wie Dauer oder Energie, und sein Merkmalsfluss wird in zwei Teile unterteilt. Wir werden einen Teil davon an den Vocoder senden, der hauptsächlich zur Erzeugung von Audiowellenformen verwendet wird, die wir anhören können. Die andere Strömungsrichtung wird an die Lippenformvorhersage gesendet. Über das Lippenformvorhersagemodul können wir den BS-Koeffizienten vorhersagen, der der Lippenform entspricht. Nachdem wir den BS-Merkmalswert erhalten haben, senden wir ihn an das Videogenerierungsmodul, das in der Verantwortung des visuellen Teams liegt und einen virtuellen Avatar generieren kann, bei dem es sich um ein virtuelles Bild mit Mundform und -ausdruck handelt. Am Ende werden wir den virtuellen Avatar und das Audio zusammenführen und schließlich Audio- und Videoanimationen generieren. Dies ist das Grundgerüst und der Grundprozess unserer gesamten multimodalen Sprachsynthese.
Hauptprobleme im multimodalen Sprachsyntheseprozess:
- Die Qualität der Sprachklangbibliotheksdaten ist relativ schlecht.
- Die Qualität des synthetischen Klangs ist schlecht.
- Die Audio- und Videoverzögerung ist groß und Mundform und Stimme stimmen nicht überein.
Die Verarbeitungsmethode von Soul ähnelt der Verbesserung des End-to-End-Spracherkennungssystems.
Datenvorverarbeitung
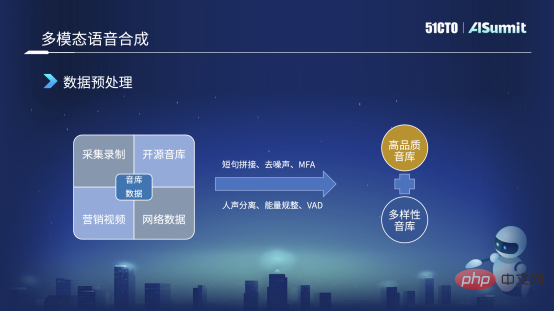
Unsere Soundbibliothek stammt aus vielen Quellen. Das Bild links ist das erste, das wir sammeln und aufnehmen werden. Zweitens sind wir natürlich dem Open-Source-Datenunternehmen sehr dankbar, das einige Soundbibliotheken als Open Source bereitstellen wird, und wir werden sie auch für einige Experimente verwenden. Drittens wird es auf unserer Plattform einige öffentliche Marketingvideos auf Unternehmensebene geben. Bei der Erstellung der Videos haben wir einige hochwertige Moderatoren eingeladen, sodass auch die Tonqualität sehr hochwertig ist. Viertens sind einige öffentliche Netzwerkdaten, z. B. im Dialogprozess, einige Klangfarben von relativ hoher Qualität, daher werden wir auch einige crawlen und dann einige Vorannotationen vornehmen, hauptsächlich um einige interne Experimente und Vorschulungen durchzuführen.
Angesichts der Komplexität dieser Daten haben wir einige Datenvorverarbeitungen durchgeführt, wie z. B. das Zusammenfügen kurzer Sätze während des Erfassungsprozesses Für die Dauer der Soundbibliothek werden wir kurze Sätze herausschneiden und dabei einige Stille entfernen. Wenn die Stille zu lang ist, wird sie eine gewisse Wirkung haben.
Zweitens ist es eine Rauschunterdrückung. Beispielsweise werden wir in den Netzwerkdaten oder Marketingvideos, die wir erhalten, das Rauschen durch einige Methoden zur Sprachverbesserung entfernen.
Drittens handelt es sich bei den meisten aktuellen Anmerkungen tatsächlich um Phonetik-zu-Zeichen-Anmerkungen, aber die Grenzen von Phonemen werden derzeit grundsätzlich nicht als Anmerkungen verwendet, sodass wir die Grenzen von Phonemen normalerweise über diese Informationen zur erzwungenen MFA-Ausrichtungsmethode erhalten .
Die folgende Stimmtrennung ist etwas ganz Besonderes, da das Marketingvideo Hintergrundmusik enthält. Daher führen wir eine Stimmtrennung durch, entfernen die Hintergrundmusik und erhalten trockene Stimmdaten. Wir führen auch eine gewisse Energieregulierung durch, und ein Teil der VAD erfolgt hauptsächlich in Dialog- oder Netzwerkdaten. Ich verwende VAD, um effektive menschliche Stimmen zu erkennen, und verwende sie dann, um eine Voranmerkung oder ein Vortraining durchzuführen.
Modell-Mikroinnovation
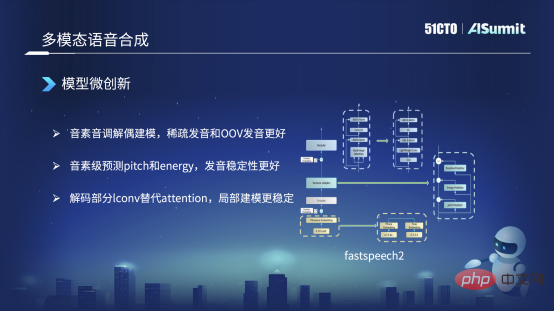
Bei der Erstellung von FastSpeech haben wir hauptsächlich Änderungen in drei Aspekten vorgenommen. Der Typ links im Bild ist das Grundmodell von FastSpeech. Die erste Änderung, die wir vorgenommen haben, besteht darin, dass wir Phoneme und Töne für die Modellierung entkoppeln. Das heißt, unter normalen Umständen konvertiert unser Text-Frontend Abfolge von Phonemen, wie im Bild links, eine monotone Abfolge von Phonemen wie „Hallo“. Aber wir werden es in den rechten Teil aufteilen, also in zwei Teile, das heißt, der linke Teil ist eine Phonemsequenz, die nur Phoneme und keine Töne enthält. Das rechte hat nur Töne und keine Phoneme. In diesem Fall senden wir sie jeweils an ein ProNet (Sound) und erhalten zwei Einbettungen. Die beiden Einbettungen werden zusammengeschnitten, um die vorherige Einbettungsmethode zu ersetzen. In diesem Fall besteht der Vorteil darin, dass das Problem der spärlichen Aussprache oder einiger Aussprachen, die nicht in unserem Trainingskorpus enthalten sind, grundsätzlich gelöst werden kann.
Die zweite Möglichkeit, die wir geändert haben, besteht darin, dass die ursprüngliche Methode darin besteht, zuerst eine Dauer vorherzusagen, was im Bild rechts dargestellt ist, und dann basierend auf dieser Dauer den Klangsatz zu erweitern und dann die Energie und Tonhöhe vorherzusagen. Jetzt haben wir die Reihenfolge geändert. Wir werden Tonhöhe und Energie basierend auf der Phonemebene vorhersagen und sie dann nach der Vorhersage auf die Dauer auf Frameebene erweitern. Dies hat den Vorteil, dass die Aussprache während des gesamten Ausspracheprozesses des gesamten Phonems relativ stabil ist. Dies ist eine Änderung in unserem Szenario.
Der dritte Punkt ist, dass wir im Decoder-Teil, dem oberen Teil, eine alternative Änderung vorgenommen haben. Der ursprüngliche Decoder verwendete die Attention-Methode, aber wir sind jetzt auf die Iconv- oder Convolution-Methode umgestiegen. Dieser Vorteil liegt darin begründet, dass Self-Attention zwar sehr aussagekräftige historische Informationen und Kontextinformationen erfassen kann, seine Fähigkeit zur schrittweisen Modellierung jedoch relativ gering ist. Nach dem Wechsel zur Faltung sind wir besser in der Lage, mit dieser Art der lokalen Modellierung umzugehen. Beispielsweise kann bei der Aussprache das gerade erwähnte Phänomen, dass die Aussprache relativ stumm oder unscharf ist, grundsätzlich gelöst werden. Dies sind einige der wichtigsten Änderungen, die wir derzeit vornehmen.
Gemeinsames Akustikmodell
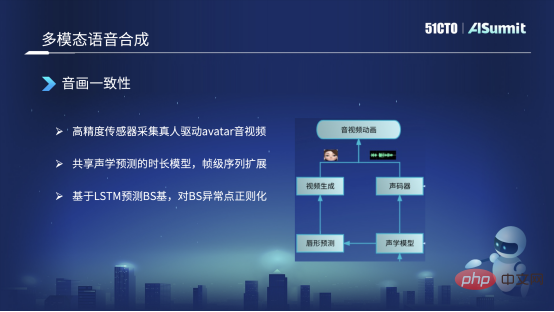
Die linke Seite ist die synthetisierte Mundform und die rechte Seite ist die synthetisierte Stimme. Sie teilen sich einige Encoder- und Dauerinformationen im Akustikmodell.
Wir haben hauptsächlich drei Aktionen durchgeführt. Der erste besteht darin, dass wir tatsächlich einige hochpräzise Daten sammeln, zum Beispiel einige echte Menschen, die einige hochpräzise Sensoren tragen, um das von uns vorhergesagte Avatar-Bild zu steuern, hochauflösendes Audio und Video zu erhalten und dies zu tun einige Anmerkungen. Auf diese Weise erhalten Sie einige synchronisierte Text-, Audio- und Videodaten.
Zweitens kann auch erwähnt werden, wie wir die Konsistenz von Audio und Video lösen? Da wir den Ton zunächst durch Textsynthese synthetisieren, erstellen wir eine Vorhersage vom Ton zur Mundform. In diesem Prozess wird eine Asymmetrie auf der Rahmenebene angezeigt. Derzeit verwenden wir diese Methode zum Teilen des akustischen Modells zwischen der synthetisierten Mundform und der synthetisierten Stimme und tun dies, nachdem die Sequenz auf Frame-Ebene erweitert wurde. Derzeit kann eine Ausrichtung auf Bildebene garantiert werden, um die Konsistenz von Audio und Video sicherzustellen.
Schließlich verwenden wir derzeit keine sequenzbasierte Methode zur Vorhersage der Mundform oder der BS-Basis. Wir verwenden LSTM zur Vorhersage der BS-Basis. Nach dem vorhergesagten BS-Koeffizienten können wir jedoch einige Anomalien vorhersagen. Wenn die BS-Basis beispielsweise zu groß oder zu klein ist, wird die Mundform zu weit geöffnet oder sogar zu klein ändern. Der Umfang darf nicht zu groß sein und wird in einem angemessenen Bereich gesteuert. Derzeit ist es grundsätzlich möglich, die Konsistenz von Audio und Video sicherzustellen.
Zukunftsaussichten
Erstens: Multimodale Erkennung In Situationen mit hohem Geräuschpegel wird Audio mit der Mundform für eine multimodale Erkennung kombiniert, um die Erkennungsgenauigkeit zu verbessern.
Die zweite ist die multimodale Sprachsynthese und Echtzeit-Sprachkonvertierung, die die Emotions- und Stileigenschaften des Benutzers beibehalten kann, aber nur die Klangfarbe des Benutzers in eine andere Klangfarbe umwandelt.
Das obige ist der detaillierte Inhalt vonDer Weg zur praktischen Umsetzung der intelligenten Sprachtechnologie von Soul. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr