
Heim >Technologie-Peripheriegeräte >KI >LazyPredict: Wählen Sie das beste ML-Modell für Sie!
LazyPredict: Wählen Sie das beste ML-Modell für Sie!

- 王林nach vorne
- 2023-04-06 20:45:071683Durchsuche
In diesem Artikel wird die Verwendung von LazyPredict zum Erstellen einfacher ML-Modelle erläutert. Das Merkmal der Erstellung von Modellen für maschinelles Lernen durch LazyPredict besteht darin, dass nicht viel Code erforderlich ist und eine Anpassung mehrerer Modelle ohne Änderung von Parametern durchgeführt werden kann, wodurch unter vielen Modellen das Modell mit der besten Leistung ausgewählt wird.
Zusammenfassung
In diesem Artikel wird die Verwendung von LazyPredict zum Erstellen einfacher ML-Modelle erläutert. Das Merkmal der Erstellung von Modellen für maschinelles Lernen durch LazyPredict besteht darin, dass nicht viel Code erforderlich ist und eine Anpassung mehrerer Modelle ohne Änderung von Parametern durchgeführt werden kann, wodurch unter vielen Modellen das Modell mit der besten Leistung ausgewählt wird.

Dieser Artikel enthält den folgenden Inhalt:
- Einführung
- Installation des LazyPredict-Moduls
- Implementierung von LazyPredict im Klassifizierungsmodell
- Implementierung im Regressionsmodell
- Zusammenfassung
Einführung
LazyPredict ist als das bekannteste bekannt advanced of Das Python-Softwarepaket revolutioniert die Art und Weise, wie Modelle für maschinelles Lernen entwickelt werden. Durch die Verwendung von LazyPredict können schnell und nahezu ohne Codierung verschiedene Grundmodelle erstellt werden, wodurch Zeit für die Auswahl des Modells gewonnen wird, das am besten zu unseren Daten passt.
Der Hauptvorteil von LazyPredict besteht darin, dass es die Modellauswahl erleichtert, ohne dass eine umfangreiche Parameterabstimmung des Modells erforderlich ist. LazyPredict bietet eine schnelle und effiziente Möglichkeit, das beste Modell zu finden und an Ihre Daten anzupassen.
Als nächstes wollen wir in diesem Artikel mehr über die Verwendung von LazyPredict erfahren.
Installation des LazyPredict-Moduls
Die Installation der LazyPredict-Bibliothek ist eine sehr einfache Aufgabe. Genau wie die Installation jeder anderen Python-Bibliothek ist die Installation so einfach wie eine Codezeile.
!pip install lazypredict
Implementierung von LazyPredict in einem Klassifizierungsmodell
In diesem Beispiel verwenden wir den Brustkrebsdatensatz aus dem Sklearn-Paket.
Jetzt laden wir die Daten.
from sklearn.datasets import load_breast_cancer from lazypredict.Supervised import LazyClassifier data = load_breast_cancer() X = data.data y= data.target
Um das beste Klassifikatormodell auszuwählen, setzen wir nun den „LazyClassifier“-Algorithmus ein. Diese Eigenschaften und Eingabeparameter sind für diese Klasse geeignet.
LazyClassifier( verbose=0, ignore_warnings=True, custom_metric=None, predictions=False, random_state=42, classifiers='all', )
Dann wenden Sie das Modell auf die geladenen Daten an und passen es an.
from lazypredict.Supervised import LazyClassifier from sklearn.model_selection import train_test_split # split the data X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state =0) # build the lazyclassifier clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None) # fit it models, predictions = clf.fit(X_train, X_test, y_train, y_test) # print the best models print(models)
Nachdem wir den obigen Code ausgeführt haben, erhalten wir die folgenden Ergebnisse:
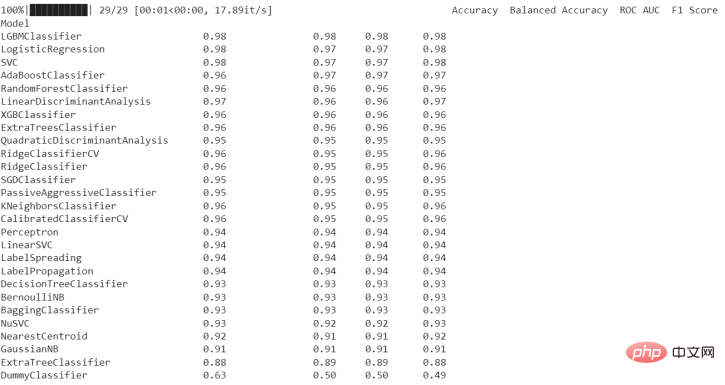
Anschließend können wir die folgende Arbeit ausführen, um die Details des Modells anzuzeigen.
model_dictionary = clf.provide_models(X_train,X_test,y_train,y_test)
Als nächstes legen Sie den Namen des Modells fest, um detaillierte Schrittinformationen anzuzeigen.
model_dictionary['LGBMClassifier']

Hier können wir sehen, dass SimpleImputer für den gesamten Datensatz und dann StandardScaler für die numerischen Funktionen verwendet wird. Es gibt keine kategorialen oder ordinalen Merkmale in diesem Datensatz, aber wenn es welche gäbe, würden OneHotEncoder bzw. OrdinalEncoder verwendet. Das LGBTMClassifier-Modell empfängt die Daten nach der Transformation und Klassifizierung.
Das interne maschinelle Lernmodell von LazyClassifier nutzt die Sci-Kit-Learn-Toolbox zur Auswertung und Anpassung. Wenn die LazyClassifier-Funktion aufgerufen wird, erstellt sie automatisch verschiedene Modelle und passt sie an unsere Daten an, darunter Entscheidungsbäume, Zufallswälder, Support-Vektor-Maschinen usw. Zur Bewertung dieser Modelle werden eine Reihe von von Ihnen bereitgestellten Leistungsmetriken verwendet, z. B. Präzision, Rückruf oder F1-Score. Der Trainingssatz dient der Anpassung, während der Testsatz der Auswertung dient.
Nach der Bewertung und Anpassung des Modells stellt LazyClassifier eine Zusammenfassung der Bewertungsergebnisse (wie in der Tabelle oben gezeigt) sowie eine Liste der Top-Modelle und Leistungsmetriken für jedes Modell bereit. Da keine manuelle Abstimmung oder Auswahl von Modellen erforderlich ist, können Sie schnell und einfach die Leistung vieler Modelle bewerten und das Modell auswählen, das am besten zu Ihren Daten passt.
LazyPredict in Regressionsmodellen implementieren
Mit der Funktion „LazyRegressor“ kann die gleiche Aufgabe noch einmal für Regressionsmodelle durchgeführt werden. Importieren wir einen für die Regressionsaufgabe geeigneten Datensatz (unter Verwendung des Boston-Datensatzes).
Jetzt passen wir unsere Daten mit LazyRegressor an.
from lazypredict.Supervised import LazyRegressor from sklearn import datasets from sklearn.utils import shuffle import numpy as np # load the data boston = datasets.load_boston() X, y = shuffle(boston.data, boston.target, random_state=0) X = X.astype(np.float32) # split the data X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state =0) # fit the lazy object reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None) models, predictions = reg.fit(X_train, X_test, y_train, y_test) # print the results in a table print(models)
Die Ergebnisse der Codeausführung sind wie folgt:
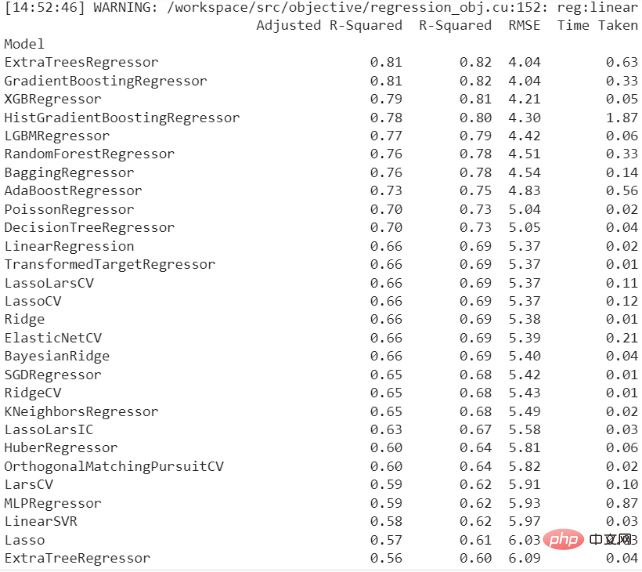
以下是对最佳回归模型的详细描述:
model_dictionary = reg.provide_models(X_train,X_test,y_train,y_test) model_dictionary['ExtraTreesRegressor']

这里可以看到SimpleImputer被用于整个数据集,然后是StandardScaler用于数字特征。这个数据集中没有分类或序数特征,但如果有的话,会分别使用OneHotEncoder和OrdinalEncoder。ExtraTreesRegressor模型接收了转换和归类后的数据。
结论
LazyPredict库对于任何从事机器学习行业的人来说都是一种有用的资源。LazyPredict通过自动创建和评估模型的过程来节省选择模型的时间和精力,这大大提高了模型选择过程的有效性。LazyPredict提供了一种快速而简单的方法来比较几个模型的有效性,并确定哪个模型系列最适合我们的数据和问题,因为它能够同时拟合和评估众多模型。
阅读本文之后希望你现在对LazyPredict库有了直观的了解,这些概念将帮助你建立一些真正有价值的项目。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:LazyPredict: A Utilitarian Python Library to Shortlist the Best ML Models for a Given Use Case,作者:Sanjay Kumar
Das obige ist der detaillierte Inhalt vonLazyPredict: Wählen Sie das beste ML-Modell für Sie!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr