
Heim >Web-Frontend >View.js >Eine eingehende Analyse des Diff-Algorithmus in Vue2
Eine eingehende Analyse des Diff-Algorithmus in Vue2

- 青灯夜游nach vorne
- 2023-02-28 19:40:501963Durchsuche
Der Diff-Algorithmus ist ein effizienter Algorithmus, der Baumknoten auf derselben Ebene vergleicht und so die Notwendigkeit vermeidet, den Baum Schicht für Schicht zu durchsuchen und zu durchlaufen. Wie viel wissen Sie über den Diff-Algorithmus? Der folgende Artikel wird Ihnen eine ausführliche Analyse des Diff-Algorithmus von vue2 geben. Ich hoffe, er wird Ihnen hilfreich sein!

Da ich beim Ansehen von Live-Interviews oft nach dem Diff-Algorithmus gefragt wurde und der Autor selbst häufig Vue2 verwendet, habe ich vor, den Diff-Algorithmus von Vue2 zu studieren Aber vielleicht weil ich den Diff-Algorithmus für relativ esoterisch halte, habe ich es aufgeschoben, ihn zu lernen, aber vor kurzem habe ich mich auf ein Vorstellungsgespräch vorbereitet und dachte, ich würde ihn früher oder später lernen Gelegenheit, den Diff-Algorithmus zu verstehen? Der Autor hat einen Tag damit verbracht, ihn zu studieren, und kann die Essenz des Diff-Algorithmus nicht vollständig verstehen.
? Dies gilt tatsächlich als Studiennotiz des Autors und der überarbeitete Artikel stellt nur die persönliche Meinung des Autors dar. Auf Fehler können Sie im Kommentarbereich hinweisen Gleichzeitig ist dieser Artikel sehr lang, daher werden die Leser gebeten, geduldig zu sein. Nach der Lektüre geht der Autor davon aus, dass Sie den Diff-Algorithmus besser verstehen werden. Ich denke, dieser Artikel ist besser als die meisten Artikel im Internet, die derzeit den Diff-Algorithmus erklären, da dieser Artikel vom Problem ausgeht und jedem beibringt, wie man denkt, anstatt direkt von der Antwort auszugehen, genau wie das Lesen der Antwort, die sich anfühlt Dieser Artikel erklärt Schritt für Schritt, wie jeder die Feinheiten des Diff-Algorithmus spüren kann. Gleichzeitig haben wir auch ein kleines Experiment durchgeführt, um jedem eine intuitivere Erfahrung mit dem Diff-Algorithmus zu ermöglichen.
Warum den Diff-Algorithmus verwenden?
Virtuelles DOM
Weil die unterste Ebene von Vue2 tatsächlich ein Objekt ist Der ungefähre Prozess ist:
- Parsen Sie zuerst die Vorlagenzeichenfolge, bei der es sich um die
.vue-Datei handelt..vue文件 - 然后转换成 AST 语法树
- 接着生成 render 函数
- 最后调用 render 函数,就能生成虚拟 DOM 【相关推荐:vuejs视频教程、web前端开发】
最小量更新
其实框架为了性能才使用的虚拟 DOM,因为 js 生成 DOM 然后展示页面是很消耗性能的,如果每一次的更新都把整个页面重新生成一遍那体验肯定不好,所以需要找到两个页面中变化的地方,然后只要把变化的地方用 js 更新 (可能是增加、删除或者更新) 一下就行了,也就是最小量更新。 那么怎么实现最小量更新呢?那么就要用 Diff 算法了,那么 Diff 算法对比的到底是什么呢?可能这是刚学 Diff 算法比较容易误解的地方,其实比对的是新旧虚拟 DOM,所以 Diff 算法就是找不同,找到两次虚拟 DOM 的不同之处,然后将不同反应到页面上,这就实现了最小量更新,如果只更新变化的地方那性能肯定更好。
页面更新流程
其实这个比较难解释,作者也就大致说一下,学了 Vue 的都知道这个框架的特点之一就有数据响应式,什么是响应式,也就是数据更新页面也更新,那么页面是怎么知道自己要更新了呢?其实这就是这个框架比较高明的地方了,大致流程如下:
- 之前也说了会运行 render 函数,那么运行 render 函数的时候会被数据劫持,也就是进入
Object.defineProperty的get,那么在这里收集依赖,那么是谁收集依赖呢?是每个组件,每个组件就是一个 Watcher,会记录这个组件内的所有变量 (也就是依赖),当然每个依赖 (Dep) 也会收集自己所在组件的 Watcher; - 然后当页面中的数据发生变化,那么就会出发
Object.defineProperty的set,在这个函数里面数据就会通知每个 Watcher 更新页面,然后每个页面就会调用更新方法,这个方法就是patchDann konvertieren Sie sie in einen AST-Syntaxbaum. - Dann generieren Sie die Renderfunktion.
- Rufen Sie schließlich die Renderfunktion auf um das virtuelle DOM zu generieren [Verwandte Empfehlungen:vuejs Video-Tutorial a>, Web-Frontend-Entwicklung]
Minimale Aktualisierung
🎜🎜Tatsächlich verwendet das Framework nur virtuelles DOM für die Leistung, da js DOM generiert und dann die Seite anzeigt, was sehr leistungsintensiv ist, wenn die gesamte Seite jedes Mal neu generiert wird Wird aktualisiert, wird die Erfahrung definitiv nicht gut sein, daher müssen zwei Seiten gefunden werden. Verwenden Sie dann einfach js, um die geänderten Orte (es kann sein, dass sie hinzugefügt, gelöscht oder aktualisiert werden) mit einem Klick zu aktualisieren, was das Minimum ist Anzahl der Updates. Wie erreicht man also die Mindestanzahl an Updates? Dann müssen wir den Diff-Algorithmus verwenden. Was genau vergleicht der Diff-Algorithmus? Vielleicht ist es hier leicht, den Diff-Algorithmus zu missverstehen, wenn man ihn zum ersten Mal lernt. 🎜Tatsächlich vergleicht er das alte und das neue virtuelle DOM🎜, also besteht der Diff-Algorithmus darin, den Unterschied zu finden, den Unterschied zwischen den beiden virtuellen DOMs , und spiegeln Sie dann den Unterschied auf der Seite wider. Dadurch wird die geringste Anzahl an Aktualisierungen erreicht, wenn nur die geänderten Stellen aktualisiert werden. 🎜🎜Seitenaktualisierungsprozess🎜🎜🎜Tatsächlich ist dies schwer zu erklären. Der Autor wird eine kurze Einführung geben, die eines der Merkmale davon kennt Framework ist Datenreaktionsfähigkeit. Was ist Reaktionsfähigkeit? Das heißt, die Seite wird auch aktualisiert, wenn die Daten aktualisiert werden. Woher weiß die Seite also, dass sie aktualisiert werden muss? Tatsächlich ist dies der clevere Teil dieses Frameworks: 🎜🎜🎜Wie bereits erwähnt, wird die Renderfunktion ausgeführt. Wenn die Renderfunktion ausgeführt wird, werden die Daten gekapert, d. h. Geben Sie
Object.definePropertysgetein, dann werden hier Abhängigkeiten gesammelt. Wer sammelt dann Abhängigkeiten? Jede Komponente ist ein Watcher, der alle Variablen (d. h. Abhängigkeiten) in dieser Komponente aufzeichnet 🎜🎜 Wenn sich die Daten auf der Seite ändern, wird derSatzvonObject.definePropertyin dieser Funktion ausgelöst. Die Daten benachrichtigen alle. Ein Beobachter aktualisiert die Seite, und dann ruft jede Seite die Aktualisierungsmethode auf. 🎜🎜Dann müssen wir den Umfang der Änderung zwischen den beiden Seiten ermitteln. Dann müssen wir den Diff-Algorithmus verwenden. 🎜🎜Nachdem Sie endlich den Änderungsbetrag gefunden haben, können Sie die Seite aktualisieren. Tatsächlich wird sie während der Suche aktualisiert, um das Verständnis für alle zu erleichtern getrennt🎜
Eine kurze Einführung in den Diff-Algorithmus
Wenn man in einem Interview fragt, was der Diff-Algorithmus ist, wird jeder auf jeden Fall ein paar Wörter sagen, wie zum Beispiel head-to-head, tail-to-tail, tail -to-head, head-to-tail, Depth-First-Traversal (dfs), Same-Level-Vergleich Ähnlich wie diese Wörter, obwohl ich es sagen kann Ein oder zwei Sätze, es ist nur ein Kratzer.
Tatsächlich hat der Autor einen auf CSDN veröffentlichten Artikel über den Diff-Algorithmus gelesen, der viel gelesen wurde. Der Autor hat das Gefühl, dass er ihn nicht klar verstanden hat, oder er hat ihn verstanden, aber nicht erklärt Dann wird der Autor seine eigenen verwenden. Lassen Sie mich meine Erkenntnisse mit Ihnen teilen. 头头、尾尾、尾头、头尾、深度优先遍历(dfs)、同层比较 类似这些话语,虽然能说一两句其实也是浅尝辄止。
其实作者看了 CSDN 上发的关于 Diff 算法的文章,就是阅读量很高的文章,作者觉得他也没讲明白,可能他自己没明白,或者自己明白了但是没讲清楚,那么作者会用自己的感悟和大家分享一下。
Diff 算法的前提
为了让大家能够了解清楚,这里先说明一下函数调用流程:
- patch
- patchVnode
- updateChildren
Diff 算法的 前提 这个是很重要的,可能大家会问什么是前提?不就是之前说的那些比较嘛?说的没错但也不对,因为 Diff 算法到达之前说的 头头、尾尾、尾头、头尾 这一步的前提就是两次对比的节点是 相同的,这里的相同不是大家想的完全相同,只是符合某些条件就是相同了,为了简化说明,文章就只考虑一个标签只包含 key 和 标签名(tag),那么之前说的相同就是 key 相同以及 tag 相同,为了证明作者的说法是有点正确的,那么这里也贴上源码:
// https://github.com/vuejs/vue/blob/main/src/core/vdom/patch.ts
// 36行
function sameVnode(a, b) {
return (
a.key === b.key &&
a.asyncFactory === b.asyncFactory &&
((a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)) ||
(isTrue(a.isAsyncPlaceholder) && isUndef(b.asyncFactory.error)))
)
}如果怕乱了,下面的可以省略不看也没事不影响整体了解,下面只是为了考虑所有情况才加的一个判断: 那么如果两个虚拟 DOM 不相同其实就不用继续比较了,而且如果相同也不用比较了,这里的相同是真的完全相同,也就是两个虚拟 DOM 的地址是一样的,那么也贴上源码:
function patchVnode(......) {
if (oldVnode === vnode) {
return
}
......
}到目前为止大家可能会比较乱,现在总结一下:
- 在
patch函数里比较的是新老虚拟 DOM 是否是key 相同以及 tag 相同,如果不相同那么就直接替换,如果相同用patchVnode
说了这么多,其实作者也就想表达一个观点,就是只有当两次比较的虚拟 DOM 是 相同的 才会考虑 Diff 算法,如果不符合那直接把原来的删除,替换新的 DOM 就行了。
patchVnode 函数
这个函数里的才是真正意义上的 Diff 算法,那么接下来会结合源码向大家介绍一下。
源码中核心代码在 patch.ts 的 638 行至 655 行。
其实,目前介绍 patchVnode 的都是直接对着源码来介绍的,但是大家可能不清楚为啥要这么分类,那么作者在这里就让大家明白为什么这么分类,首先在这里说一个结论:
- 就是
text属性和children属性不可能同时存在,这个需要大家看模板解析源码部分
那么在对比新旧节点的情况下,主要比较的就是是否存在 text 和 children
Die Prämisse des Diff-Algorithmus
Die Voraussetzung des Diff-Algorithmus ist sehr wichtig. Sie fragen sich vielleicht, was die Prämisse ist. Sind es nicht nur die zuvor erwähnten Vergleiche? Das stimmt, ist aber auch falsch, denn der Diff-Algorithmus erreicht die zuvor erwähnten Werte head, tail, tail, head, tail. Die Voraussetzung für diesen Schritt ist, dass die zweimal verglichenen Knoten gleich sind /code> code>, die Ähnlichkeit ist hier nicht genau die gleiche, wie jeder denkt, aber sie ist dieselbe, wenn sie bestimmte Bedingungen erfüllt. Um die Erklärung zu vereinfachen, berücksichtigt der Artikel nur ein Tag, das nur <code>key und <code> Tag-Name (Tag), dann habe ich zuvor gesagt, dass der Schlüssel und der Tag gleich sind, um zu beweisen, dass der Autor Die Aussage ist einigermaßen richtig, der Quellcode wird auch hier veröffentlicht:
| Wenn Sie Angst vor Verwirrung haben, können Sie Folgendes weglassen, ohne es sich anzusehen, und es hat keinen Einfluss auf das Gesamtverständnis. Das Folgende ist nur eine zu berücksichtigende Beurteilung alle Situationen: Wenn also die beiden virtuellen DOMs nicht gleich sind, besteht keine Notwendigkeit, den Vergleich fortzusetzen, und wenn sie gleich sind, ist kein Vergleich erforderlich. Die Ähnlichkeit ist hier wirklich genau gleich, dh die Adressen der beiden Virtuelle DOMs sind die gleichen, also fügen Sie auch den Quellcode ein: | Alle sind bisher vielleicht verwirrt: | Nachdem ich so viel gesagt habe, möchte der Autor tatsächlich auch einen Standpunkt zum Ausdruck bringen, nämlich nur Wenn die beiden verglichenen virtuellen DOMs gleich sind, wird der Diff-Algorithmus dies tun Wenn sie nicht konsistent sind, löschen Sie einfach das Original und ersetzen Sie es durch das neue DOM. |
patchVnode-Funktion |
|---|---|---|---|---|
| Tatsächlich wird die aktuelle Einführung von patchVnode direkt in den Quellcode eingeführt, aber Sie wissen möglicherweise nicht, warum er auf diese Weise klassifiziert ist. Daher ist der Autor hier, um allen verständlich zu machen, warum er auf diese Weise klassifiziert ist Lassen Sie mich eine Schlussfolgerung ziehen: | Also beim Vergleich alter und neuer Knoten besteht der Hauptvergleich darin, ob text und untergeordnete Elemente vorhanden sind . Dann gibt es die folgenden neun Situationen |
Situationen | ||
| alte Knotenkinder | neuer Knotentext | neue Knotenkinder | 1 | |
| ❎ | ❎ | ❎ | 2 | |
| ✅ | ❎ | ❎ | 3 | |
| ❎ | ❎ | ❎ | 4 | |
| ❎ | ❎ | ✅ | 5 | |
| ✅ | ❎ | ✅ | 6 | |
| ❎ | ❎ | ✅ | 7 | |
| ❎ | ✅ | ❎ | 8 |
按照上面的表格,因为如果新节点有文本节点,其实老节点不管是什么都会被替换掉,那么就可以按照 新节点 text 是否存在来分类,其实 Vue 源码也是这么来分类的:
if (isUndef(vnode.text)) {
// 新虚拟 DOM 有子节点
} else if (oldVnode.text !== vnode.text) {
// 如果新虚拟 DOM 是文本节点,直接用 textContent 替换掉
nodeOps.setTextContent(elm, vnode.text)
}那么如果有子节点的话,那应该怎么分类呢?我们可以按照每种情况需要做什么来进行分类,比如说:
- 第一种情况,我们啥都不用做,因此也可以不用考虑
- 第二种情况,我们应该把原来 DOM 的
textContent设置为'' - 第三种情况,我们也应该把原来 DOM 的
textContent设置为'' - 第四种情况,我们应该加入新的子节点
- 第五种情况,这个情况比较复杂,需要对比新老子节点的不同
- 第六种情况,我们应该把原来的
textContent设置为''后再加入新的子节点
那么通过以上六种情况 (新虚拟 DOM 不含有 text,也就是不是文本节点的情况),我们可以很容易地进行归类:
- 分类 1️⃣:
第二种情况和第三种情况。进行的是操作是:把原来 DOM 的textContent设置为'' - 分类 2️⃣:
第四种情况和第六种情况。进行的是操作是:如果老虚拟 DOM 有text,就置空,然后加入新的子节点 - 分类 3️⃣:
第五种情况。进行的是操作是:需要进行精细比较,即对比新老子节点的不同
其实源码也是这么来进行分类的,而且之前说的 同层比较 也就得出来了,因为每次比较都是比较的同一个父节点每一个子元素 (这里的子元素包括文本节点和子节点) 是否相同,而 深度优先遍历(dfs) 是因为每次比较中,如果该节点有子节点 (这里的子节点指的是有 children 属性,而不包括文本节点) 的话需要进行递归遍历,知道最后到文本节点结束。
⭕️ 这里需要搞清楚子节点和子元素的区别和联系
然后我们来看看源码是怎么写吧,只看新虚拟 DOM 不含有 text,也就是不是文本节点的情况:
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch)
// 递归处理,精细比较
// 对应分类 3️⃣
updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
if (__DEV__) {
checkDuplicateKeys(ch) // 可以忽略不看
}
// 对应分类 2️⃣
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 对应分类 1️⃣
removeVnodes(oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// 对应分类 1️⃣
nodeOps.setTextContent(elm, '')
}
}❓我们可以看到源码把分类 1️⃣ 拆开来了,这是因为如果老虚拟 DOM 有子节,那么可能绑定了一些函数,需要进行解绑等一系列操作,作者也没自信看,大致瞄了一眼,但是如果我们要求不高,如果只是想自己手动实现 Diff 算法,那么没有拆开的必要。
作者觉得这么讲可能比网上其他介绍 Diff 算法的要好,其他的可能直接给你说源码是怎么写的,可能没有说明白为啥这么写,但是通过之前这么分析讲解后可能你对为什么这么写会有更深的理解和帮助吧。
updateChildren 函数
同层比较
因为当都含有子节点,即都包含 children 属性后,需要精细比较不同,不能像之前那些情况一样进行简单处理就可以了
那么这个函数中就会介绍大家经常说的 头头、尾尾、尾头、头尾 比较了,其实这不是 Vue 提出来的,是很早就提出来的算法,就一直沿用至今,大家可以参考【snabbdom 库】
? 在这之前我们要定义四个指针 newStartIdx、newEndIdx、oldStartIdx 和 oldEndIdx,分别指向 新头节点、新尾节点、旧头节点 与 旧尾节点
循环条件如下:
while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
......
}其实这个比较也就是按人类的习惯来进行比较的,比较顺序如下 :
- 1️⃣
新头节点与旧头节点:++newStartIdx和++oldStartIdx - 2️⃣
新尾节点与旧尾节点:--newEndIdx和--oldEndIdx - 3️⃣
新尾节点与旧头节点:需要将旧头节点移动到旧尾节点之前,为什么要这么做,讲起来比较复杂,记住就好,然后--newEndIdx和++oldStartIdx - 4️⃣
新头节点与旧尾节点:需要将旧尾节点移动到旧头节点之前,为什么要这么做,讲起来比较复杂,记住就好,然后++newStartIdx和--oldEndIdx - 5️⃣ 如果都没有匹配的话,就把
新头节点在旧节点列表 (也就是 children 属性的值) 中进行查找,查找方式按照如下:- 如果有
key就把key在oldKeyToIdx进行匹配,oldKeyToIdx根据旧节点列表中元素的key生成对应的下标 - 如果没有,就按顺序遍历旧节点列表找到该节点所在的下标
- 如果在旧节点列表是否找到也分为两种情况:
- 找到了,那么只要将
新头节点添加到旧头节点之前即可 - 没找到,那么需要创建新的元素然后添加到
旧头节点之前 - 然后把这个节点设置为
undefined
- 找到了,那么只要将
- 如果有
根据循环条件我们可以得到两种剩余情况,如下:
- 6️⃣ 如果
oldStartIdx > oldEndIdx说明老节点先遍历完成,那么新节点比老节点多,就要把newStartIdx与newEndIdx之间的元素添加 - 7️⃣ 如果
newStartIdx > newEndIdx说明新节点先遍历完成,那么老节点比新节点多,就要把oldStartIdx与oldEndIdx之间的元素删除
其实我们上面还没有考虑如果节点为 undefined 的情况,因为在上面也提到过,如果四种都不匹配后会将该节点置为 undefined,也只有旧节点列表中才有,因此要在开头考虑这两种情况:
- 8️⃣ 当
oldStartVnode为undefined:++oldStartIdx - 9️⃣ 当
oldEndVnode为undefined:--oldEndIdx
那么我们来看源码怎么写的吧,其中用到的函数可以查看源码附录:
// https://github.com/vuejs/vue/blob/main/src/core/vdom/patch.ts
// 439 行至 556 行
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
// 情况 8️⃣
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
// 情况 9️⃣
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
// 情况 1️⃣
patchVnode(...)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
// 情况 2️⃣
patchVnode(...)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
// Vnode moved right
// 情况 3️⃣
patchVnode(...)
canMove &&
nodeOps.insertBefore(
parentElm,
oldStartVnode.elm,
nodeOps.nextSibling(oldEndVnode.elm)
)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
// 情况 4️⃣
patchVnode(...)
canMove &&
nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 情况 5️⃣
if (isUndef(oldKeyToIdx)) // 创建 key -> index 的 Map
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
// 找到 新头节点 的下标
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// New element
// 如果没找到
createElm(...)
} else {
// 如果找到了
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(...)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// same key but different element. treat as new element
createElm(...)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
// 情况 6️⃣
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(...)
} else if (newStartIdx > newEndIdx) {
// 情况 7️⃣
removeVnodes(...)
}如果问为什么这么比较,回答就是经过很多人很多年的讨论得出的,其实只要记住过程就行了,如果想要更深了解 Diff 算法,可以去 B 站看【尚硅谷】Vue源码解析之虚拟DOM和diff算法
v-for 中为什么要加 key
这个问题面试很常见,但是可能大部分人也就只会背八股,没有完全理解,那么经过以上的介绍,我们可以得到自己的理解:
- 首先,如果不加 key 的话,那么就不会去 Map 里匹配 (O(1)),而是循环遍历整个列表 (O(n)),肯定加 key 要快一点,性能更高
- 其次,如果不加 key 那么在插入或删除的时候就会出现,原本不是同一个节点的元素被认为是相同节点,上面也有说过是
sameVnode函数判断的,因此可能会有额外 DOM 操作
为什么说可能有额外 DOM 操作呢?这个和插入的地方有关,之后会讨论,同理删除也一样
证明 key 的性能
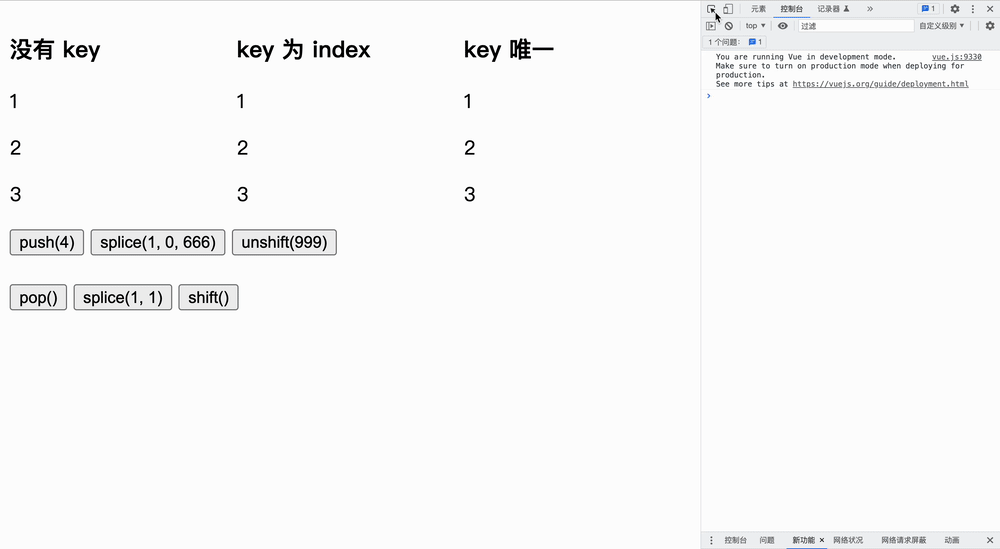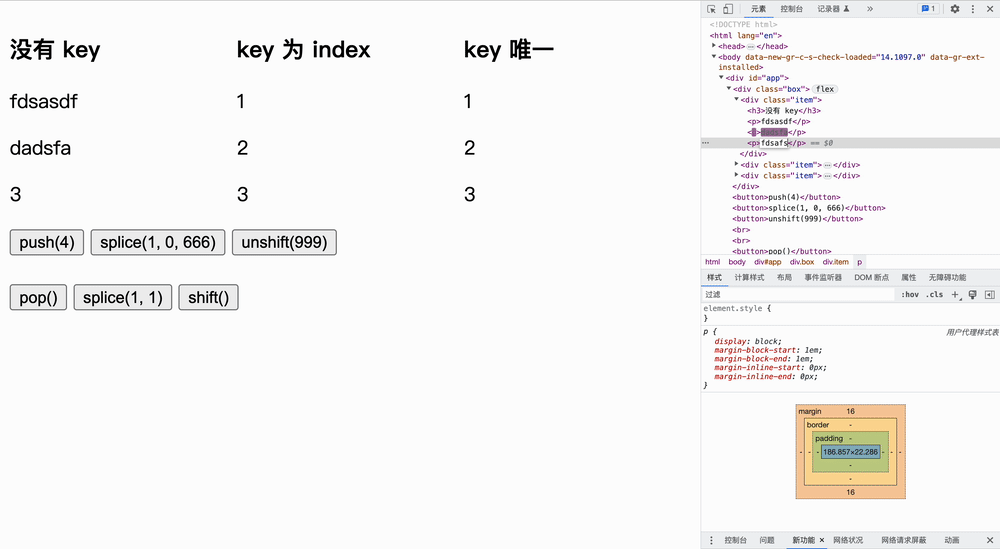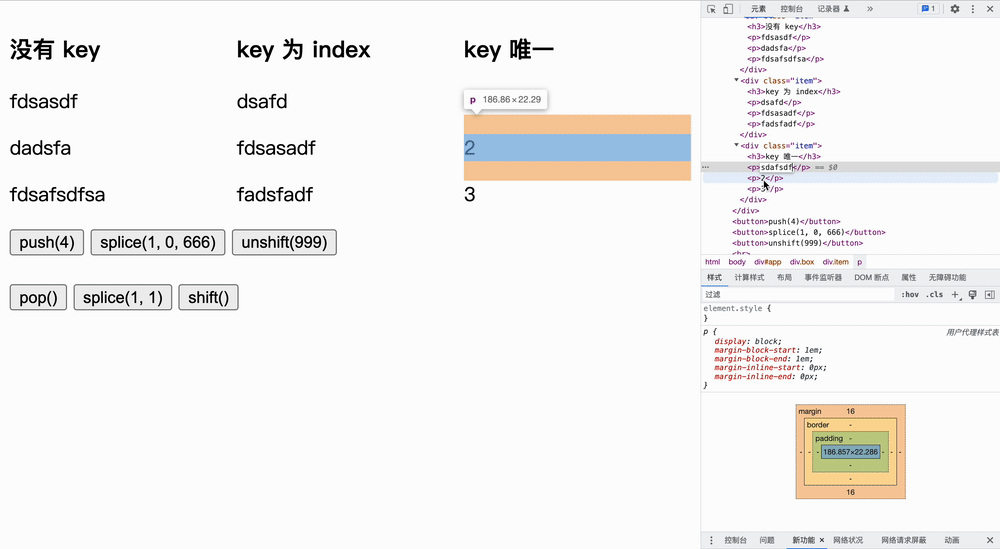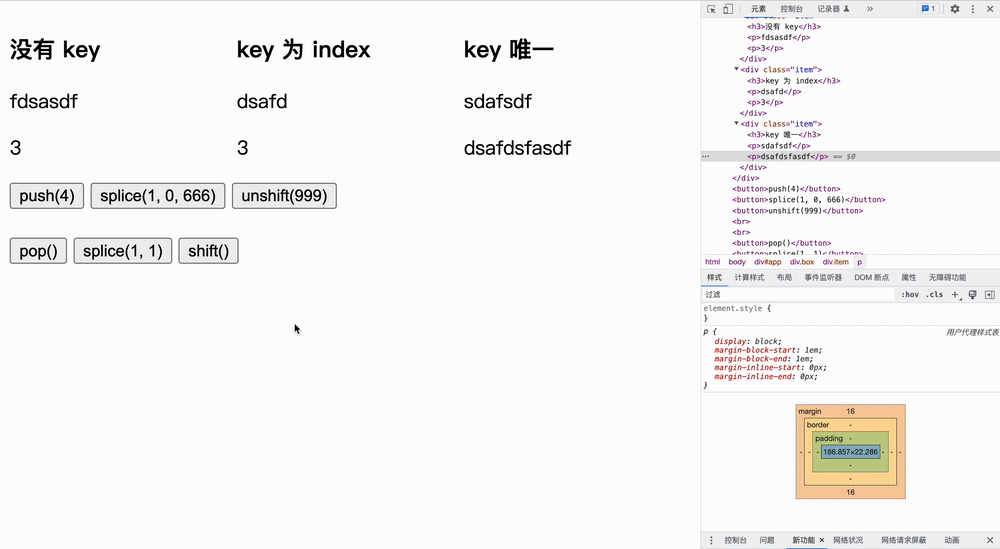
我们分为三个实验:没有 key、key 为 index、key 唯一,仅证明加了 key 可以进行最小化更新操作。
实验代码
有小伙伴评论说可以把代码贴上这样更好,那么作者就把代码附上 ?:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script>
<style>
.box {
display: flex;
flex-direction: row;
}
.item {
flex: 1;
}
</style>
</head>
<body>
<div id="app">
<div>
<div>
<h3>没有 key</h3>
<p v-for="(item, index) in list">{{ item }}</p>
</div>
<div>
<h3>key 为 index</h3>
<p v-for="(item, index) in list" :key="index">{{ item }}</p>
</div>
<div>
<h3>key 唯一</h3>
<p v-for="(item, index) in list" :key="item">{{ item }}</p>
</div>
</div>
<button @click="click1">push(4)</button>
<button @click="click2">splice(1, 0, 666)</button>
<button @click="click3">unshift(999)</button>
<br /><br />
<button @click="click4">pop()</button>
<button @click="click5">splice(1, 1)</button>
<button @click="click6">shift()</button>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
show: false,
list: [1, 2, 3],
},
methods: {
click1() {
this.list.push(4);
},
click2() {
this.list.splice(1, 0, 666);
},
click3() {
this.list.unshift(999);
},
click4() {
this.list.pop();
},
click5() {
this.list.splice(1, 1);
},
click6() {
this.list.shift();
}
},
})
</script>
</body>
</html>增加实验
实验如下所示,我们首先更改原文字,然后点击按钮**「观察节点发生变化的个数」**:
在队尾增加

在队内增加
在队首增加
删除实验
在队尾删除
在队内删除
在队首删除
实验结论
增加实验
表格为每次实验中,每种情况的最小更新量,假设列表原来的长度为 n
| 实验 | 没有 key | key 为 index | key 唯一 |
|---|---|---|---|
| 在队尾增加 | 1 | 1 | 1 |
| 在队中增加 | n - i + 1 | n - i + 1 | 1 |
| 在队首增加 | n + 1 | n + 1 | 1 |
删除实验
表格为每次实验中,每种情况的最小更新量,假设列表原来的长度为 n
| 实验 | 没有 key | key 为 index | key 唯一 |
|---|---|---|---|
| 在队尾删除 | 1 | 1 | 1 |
| 在队中删除 | n - i | n - i | 1 |
| 在队首删除 | n | n | 1 |
通过以上实验和表格可以得到加上 key 的性能和最小量更新的个数是最小的,虽然在 在队尾增加 和 在队尾删除 的最小更新量相同,但是之前也说了,如果没有 key 是要循环整个列表查找的,时间复杂度是 O(n),而加了 key 的查找时间复杂度为 O(1),因此总体来说加了 key 的性能要更好。
写在最后
本文从源码和实验的角度介绍了 Diff 算法,相信大家对 Diff 算法有了更深的了解了,如果有问题可私信交流或者评论区交流,如果大家喜欢的话可以点赞 ➕ 收藏 ?
源码函数附录
列举一些源码中出现的简单函数
setTextContent
function setTextContent(node: Node, text: string) {
node.textContent = text
}isUndef
function isUndef(v: any): v is undefined | null {
return v === undefined || v === null
}isDef
function isDef<T>(v: T): v is NonNullable<T> {
return v !== undefined && v !== null
}insertBefore
function insertBefore(
parentNode: Node,
newNode: Node,
referenceNode: Node
) {
parentNode.insertBefore(newNode, referenceNode)
}nextSibling
function nextSibling(node: Node) {
return node.nextSibling
}createKeyToOldIdx
function createKeyToOldIdx(children, beginIdx, endIdx) {
let i, key
const map = {}
for (i = beginIdx; i <= endIdx; ++i) {
key = children[i].key
if (isDef(key)) map[key] = i
}
return map
}Das obige ist der detaillierte Inhalt vonEine eingehende Analyse des Diff-Algorithmus in Vue2. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ein Artikel über globale Wächter in Vue
- [Empfohlen] Die 9 beliebtesten Vue UI-Bibliotheken
- Eine kurze Analyse der Verwendung von Axios und Vue zur Implementierung einer einfachen Wetterabfrage
- Ein Artikel, der kurz das Problem der Wertübertragung zwischen übergeordneten und untergeordneten Komponenten in Vue analysiert
- [Organisation und Freigabe] 8 praktische Vue-Entwicklungstipps
- Lassen Sie uns über die technischen Prinzipien der Entwicklung kleiner Programme mit Vue sprechen