
Heim >Datenbank >MySQL-Tutorial >Eine kurze Analyse der Datenspeicherstruktur in MySQL
Eine kurze Analyse der Datenspeicherstruktur in MySQL

- 青灯夜游nach vorne
- 2023-02-13 19:43:241623Durchsuche
In diesem Artikel wird hauptsächlich aus der Perspektive der InnoDB-Datenspeicherstruktur analysiert, unter welchen Umständen die SQL-Abfrageeffizienz verringert wird. Ich sehe oft einige Artikel im Internet, die sich darüber beschweren. Wenn die Datenmenge groß ist, wird die Abfrageeffizienz stark verringert. Wenn viele verwandte Tabellen vorhanden sind, nimmt die Abfrageeffizienz ab. Die Datenmenge in einer einzelnen Tabelle sollte eine Million usw. nicht überschreiten.

Datenbankversion: 8.0 Engine: InnoDB Referenzmaterial: Nuggets-Broschüre „MySQL von Grund auf verstehen“. Wenn Sie Zeit haben, empfehle ich Ihnen, es selbst zu lesen.
Beispieltabelle:
CREATE TABLE `hospital_info` ( `pk_id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `id` varchar(36) NOT NULL COMMENT '外键', `hospital_code` varchar(36) NOT NULL COMMENT '医院编码', `hospital_name` varchar(36) NOT NULL COMMENT '医院名称', `is_deleted` tinyint DEFAULT NULL COMMENT '是否删除 0否 1是', `gmt_created` datetime DEFAULT NULL COMMENT '创建时间', `gmt_modified` datetime DEFAULT NULL COMMENT 'gmt_modified', `gmt_deleted` datetime(3) DEFAULT '9999-12-31 23:59:59.000' COMMENT '删除时间', PRIMARY KEY (`pk_id`), KEY `hospital_code` (`hospital_code`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医院信息';
InnoDB-Zeilenformat
Ausgehend von einer Datenzeile wollen wir zunächst das Speicherformat einer einzelnen Datenzeile verstehen.
Derzeit gibt es 4 Zeilenformate, nämlich Kompakt, Redundant, Dynamisch und KomprimiertZeilenformat.
Es besteht im Allgemeinen keine Notwendigkeit, es beim Erstellen einer Tabelle absichtlich anzugeben. Versionen 5.7 und höher verwenden standardmäßig Dynamisch.
Jedes Zeilenformat ist ähnlich. Hier nehmen wir Compact als Beispiel, um kurz zu verstehen, wie jede Datenzeile aufgezeichnet wird. 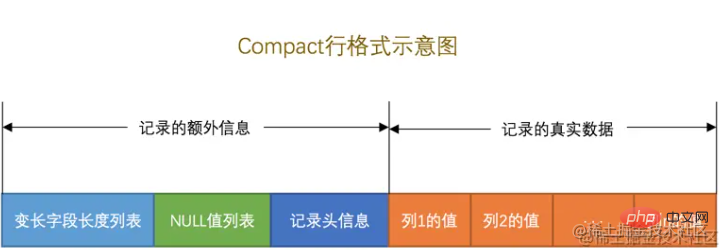
Wie im Bild oben gezeigt. Unterteilt in zwei Teile: „Zusätzliche Informationen“ und „Echte Daten“.
Feldliste mit variabler Länge
Das ist im Allgemeinen interessanter: Wenn Sie ein Feld definieren, müssen Sie den Typ und die Länge des Feldes angeben,
Zum Beispiel: KrankenhauscodeFelddefinitionVARCHAR (in der Beispieltabelle 36). Bei der tatsächlichen Verwendung verwendet die Feldlänge „hospital_code“ nur 32 Bit. Was passiert mit den verbleibenden 4 Charakteren? Wenn Sie leere Zeichen zwangsweise ausfüllen würden, wäre das nicht eine Verschwendung von 4 Zeichen Speicher? Wenn es nicht ausgefüllt ist, wie kann dann ermittelt werden, wie viele Zeichen im aktuellen Feld gespeichert sind? Wie viel Speicher nimmt es ein?
Zu diesem Zeitpunkt wird die Liste der Felder mit variabler Länge
in umgekehrter Reihenfolgenach Feld sortiert, wobei 1 bis 2 Bytes verwendet werden, um die tatsächliche Länge jedes Feldes mit variabler Länge aufzuzeichnen. Dadurch kann der Speicherplatz effektiv genutzt werden. Ähnliche Felder:
VARBINARY, verschiedene TEXT-Typen, verschiedene BLOB-Typen. Entsprechend gibt es auch „Felder mit fester Länge“, wie zum Beispiel: CHAR(10)
Dieser Feldtyp belegt bei der Initialisierung standardmäßig den Platz der angegebenen Zeichenlänge Es ist relativ verschwenderisch und es wird allgemein empfohlen, die Länge nach Bedarf festzulegen.Natürlich existiert die „Liste variabler Längenfelder“ nicht unbedingt. Wenn der definierte Feldtyp kein „Feld variabler Länge“ hat, existiert er nicht.
Erweiterung:
Bei Feldern vom Typ TEXT oder BLOB wird die Länge möglicherweise nicht auf einer Seite gespeichert. In diesem Fall werden die meisten Daten auf anderen Seiten aufgezeichnet und die Adresse der nächsten Datenseite bleibt erhalten im aktuellen Datensatz.NULL-Werteliste
Beim tatsächlichen Speichern von Daten können in einigen Spalten NULL
-Werte gespeichert werden. Wenn diese Werte in realen Daten aufgezeichnet werden, wird Speicherplatz verschwendet. ImCompact-Format werden diese Spalten mit NULL-Werten einheitlich verwaltet und in einer NULL-Werteliste gespeichert. Wenn kein Feld in einer Datenzeile NULL
ist, wird diese Spalte nicht generiert.Die Speichermethode ist auch recht interessant, sie wird binär in umgekehrter Reihenfolge aufgezeichnet
.Anhand einer Beispieltabelle zur Analyse gibt es drei Felder in der Tabelle: is_deleted
,gmt_created, gmt_modified, die möglicherweise leer sind. Unter der Annahme, dass sowohl gmt_created als auch gmt_modified in einem Datensatz leer sind, sollte die entsprechende NULL-Werteliste wie folgt aussehen.
Erweitern:
MySQL unterstützt die binäre Datenspeicherung, und die vollständige Nutzung kann eine große Menge an Speicherplatz reduzieren. 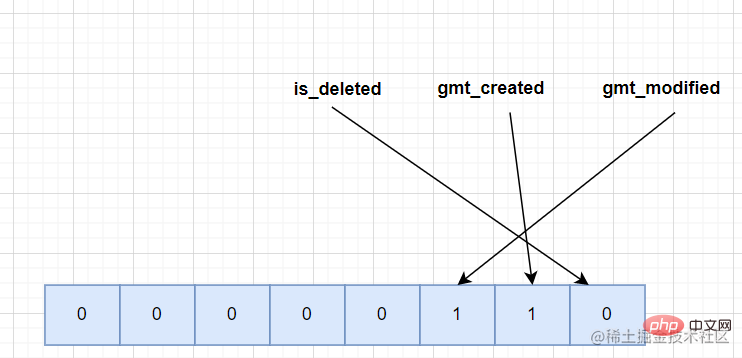
Datensatz-Header-Informationen
Datensatz-Header-Informationen bestehen aus festen 5 Zeichen, die 40 Binärbits lang sind.
Zunächst einmal zum Verständnis hier ein interessanteres Logo: 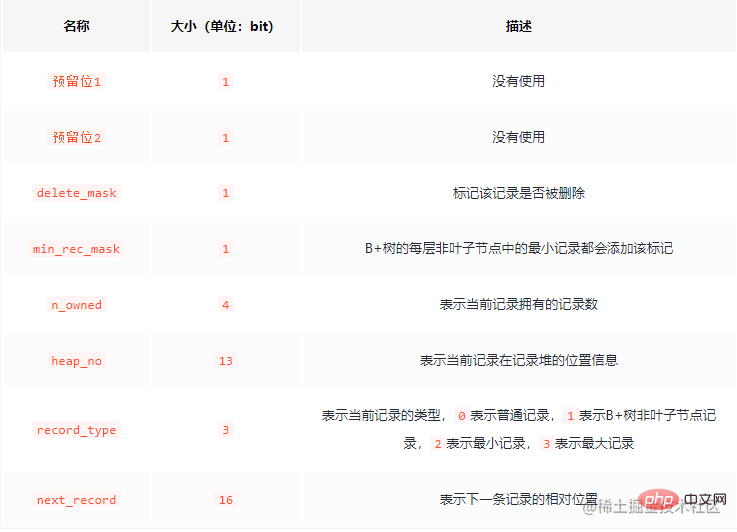 delete_mask
delete_mask
verknüpfte Liste, die als wiederverwendbarer Speicherplatz verwendet werden kann. Echte Datendaten aufzeichnen
Tatsächlich gibt es dazu nichts zu sagen, es geht darum, echte Nicht-NULL-Daten aufzuzeichnen.
Im Internet taucht häufig die Frage auf:Was passiert, wenn der Primärschlüssel nicht festgelegt ist?
Unter InnoDB ist der Primärschlüssel die eindeutige Kennung eines Datensatzes. Wenn der Benutzer ihn nicht angibt, wählt MySQL einen aus dem Einzigartigen (eindeutigen) Schlüssel als Primärschlüssel aus. Es wird ein Schlüssel mit dem Namen row_idhide-Spalte als Primärschlüssel hinzugefügt. Zusätzlich werden die beiden Spalten
transaction_id (Transaktions-ID)und roll_pointer (Rollback-Zeiger) hinzugefügt.
ZusammenfassungDie vier Zeilenformate sind sehr ähnlich, daher werde ich sie nicht einzeln vorstellen. Sie sind in zwei Teile unterteilt: „Zusätzliche Informationen“ und „echte Daten“. Der Unterschied besteht hauptsächlich im Inhalt des Datensatzes „Zusatzinformationen“ und der Speicherung von Feldern variabler Länge.
InnoDB-DatenseiteDas Konzept der Datenseite ist Ihnen wahrscheinlich bekannt. Es ist die Grundeinheit für InnoDB zur Verwaltung des Speicherplatzes. Die Größe einer einzelnen Seite beträgt im Allgemeinen
16 KB. Viele verschiedene Arten von Seiten sind für unterschiedliche Zwecke konzipiert, wie zum Beispiel: eine Seite zum Speichern von Tabellenbereichs-Header-Informationen, eine Seite zum Speichern von Puffer einfügen-Informationen, eine Seite zum Speichern von INODE-Informationen, eine Seite zum Speichern von Rückgängigmachen Protokollinformationen usw. . Der Seitenbereich ist wie folgt aufgeteilt:
Es gibt insgesamt 7 Komponenten. Beschreiben wir die 7 Teile grob. 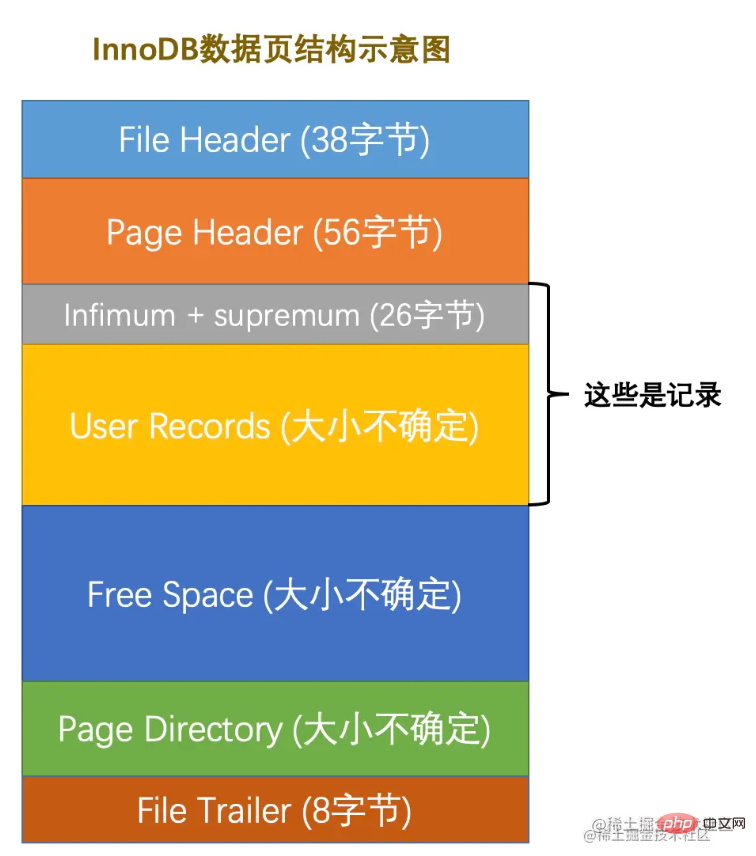
Es gibt viele Attribute in 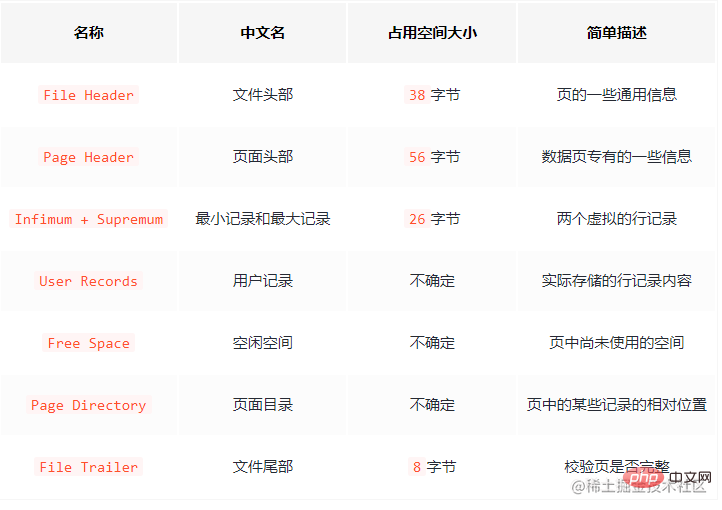 Dateikopf
Dateikopf
Seitenkopf. Ich werde sie hier nicht einzeln vorstellen, solange Sie wissen, dass diese beiden Stellen einige Attribute von Seite aufzeichnen : Seitennummer, vorherige Seite und die Seitennummer der nächsten Seite, der Seitentyp, die Speichernutzung der Seite usw. Lassen Sie mich hier sprechen: Seiten sind durch eine doppelt verknüpfte Liste verbunden. Der Datensatz ist eine einzelne Halskette. File Trailer
wird verwendet, um die Integrität von Seitendaten zu überprüfen. Wenn Seitendaten vom Speicher auf die Festplatte neu geschrieben werden, müssen sie überprüft werden, um eine Beschädigung der Datenseite zu verhindern.Konzentrieren Sie sich auf Benutzerdatensätze (benutzter Speicherplatz)
undFreier Speicherplatz (verbleibender Speicherplatz), hier werden die tatsächlichen Datensätze gespeichert. Darüber hinaus identifizieren Infimum
undSupremum den minimalen bzw. maximalen Datensatz. Das heißt, wenn eine Seite generiert wird, enthält sie standardmäßig diese beiden Datensätze. Aber keine Sorge, diese beiden Datensätze werden nur als Kopf und Ende der Datenverknüpfungsliste verwendet und haben keinen Einfluss auf die tatsächlichen Daten. Zusammenfassend ist die Speicherung von Datensätzen auf der Seite wie folgt:
Einfach ausgedrückt handelt es sich um die
Konvertierung von freiem Speicherplatz in Benutzerdatensätze, wenn der freie Speicherplatz erschöpft ist voll. 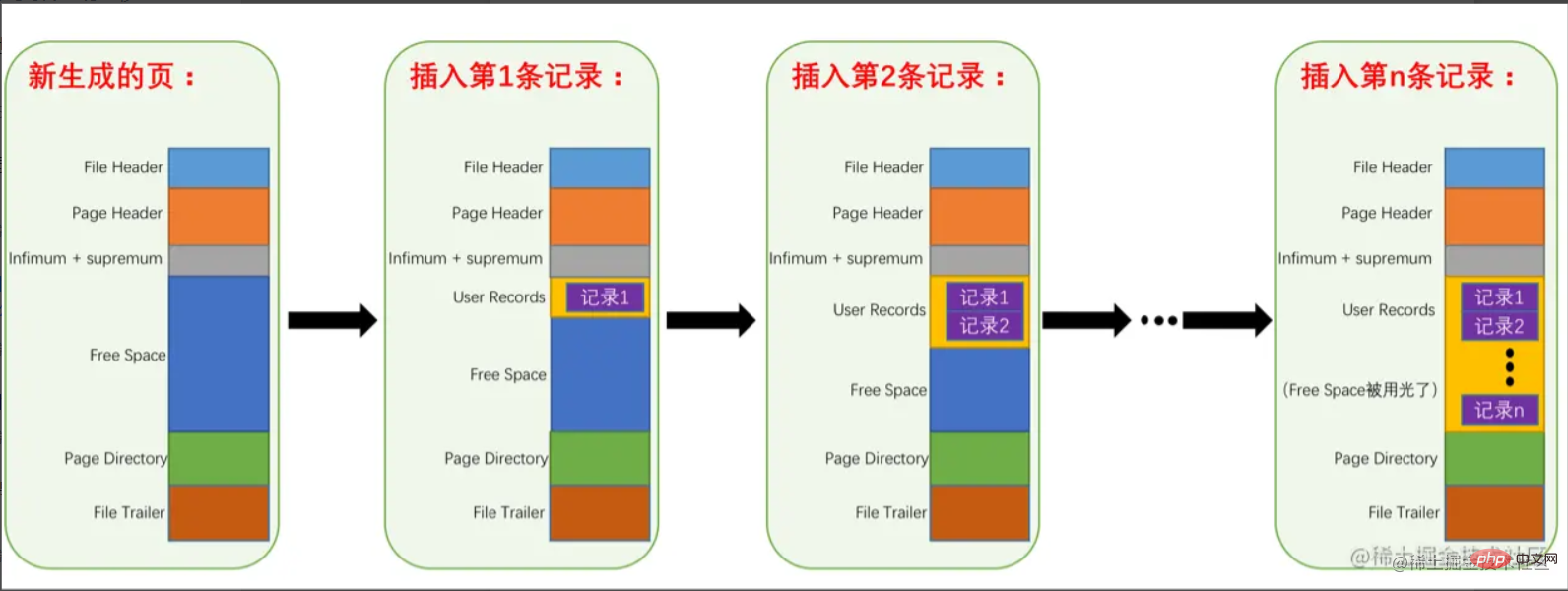 Zu diesem Zeitpunkt wurden die Daten in die Datenseite geschrieben. Wie nehme ich es heraus? Wir wissen oben, dass der Datensatz aus einer einzelnen verknüpften Liste besteht. Müssen wir vom Infimum
Zu diesem Zeitpunkt wurden die Daten in die Datenseite geschrieben. Wie nehme ich es heraus? Wir wissen oben, dass der Datensatz aus einer einzelnen verknüpften Liste besteht. Müssen wir vom Infimum
Natürlich kann der Entwicklungschef von MySQL nicht so dumm sein, sonst schaffe ich es, haha.
Hier müssen wirPage Directory
(Seitenverzeichnis) erwähnen. Auf der Seite werden die Daten gruppiert und derAdressoffset des letzten Datensatzes in jeder Gruppe wird separat extrahiert und der Reihe nach im „Seitenverzeichnis“ am Ende der Seite gespeichert Es heißt „slot“. Darüber hinaus wird im Header des letzten Datensatzes (n_owned) auch gespeichert, wie viele Datensätze es in der Gruppe gibt. Das Seitenverzeichnis besteht aus Slots. Das Gesamtstrukturdiagramm sieht wie folgt aus:
Sobald Sie das Verzeichnis haben, ist die Abfrage relativ einfach. Für eine schnelle Suche können Sie die 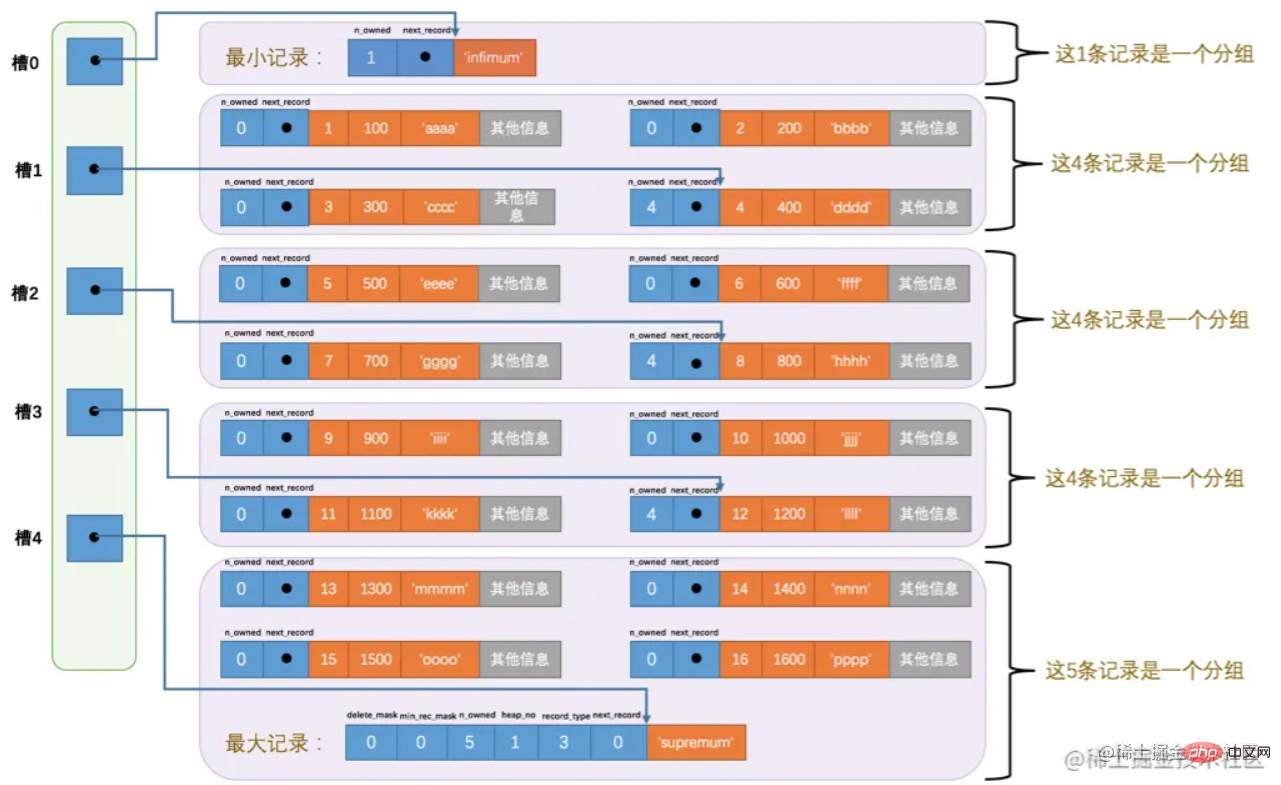 Dichotomie-Methode
Dichotomie-Methode
Angenommen, Sie möchten die Daten abfragen, deren Primärschlüsseldatensatz 6 ist.
1) Berechnen Sie die mittlere Slot-Position, die (0+4)/2 = 2 ist. Der Primärschlüssel des Datensatzes, der dem extrahierten Slot entspricht, ist 8, da 8>6. 2) Stellen Sie auf die gleiche Weise den größten Slot auf 2 ein, also (0+2)/2 =1. Der Primärschlüssel, der Slot 1 entspricht, ist 4. Da 4 Um die nachfolgende Beschreibung zu erleichtern, wird das Datenformular der Seite vereinfacht, wie in der folgenden Abbildung dargestellt.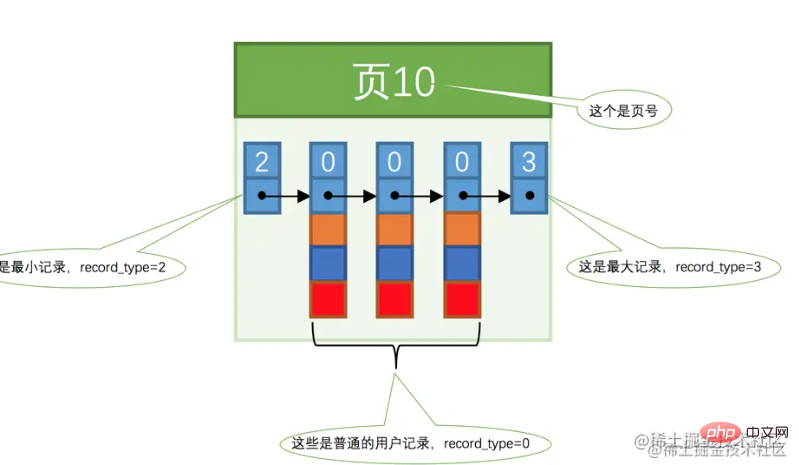 B+Tree Index
B+Tree Index
Sie können genauso gut über eine Frage nachdenken, wie bereits erwähnt. Die Datenseiten sind durch eine doppelt verknüpfte Liste verknüpft, etwa wie in der Abbildung unten dargestellt: Wie Sie in der obigen Abbildung sehen können,
sind die Seitenzahlen nicht fortlaufend und 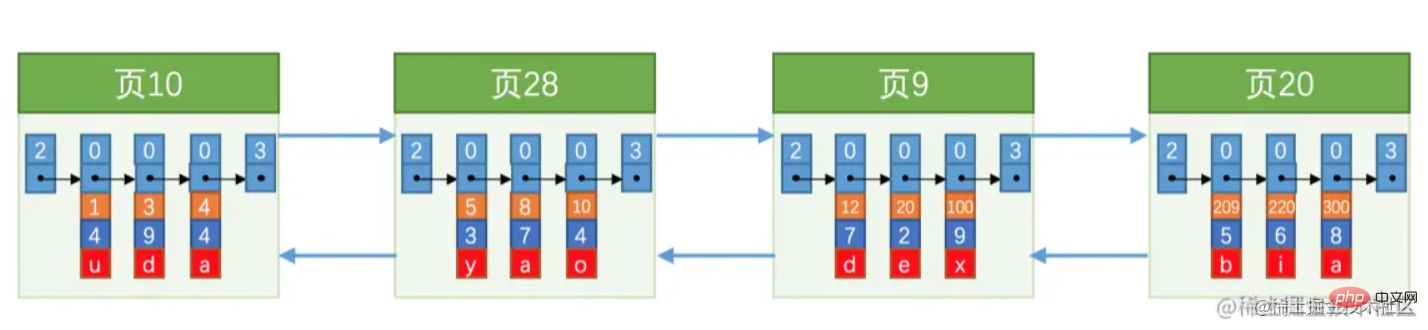 sind nicht unbedingt fortlaufende Speicherplätze (denken Sie an Folgendes). Satz) Werde darüber reden).
sind nicht unbedingt fortlaufende Speicherplätze (denken Sie an Folgendes). Satz) Werde darüber reden).
Angenommen, dass jede Seite 3 Datensätze speichern kann und jetzt 100.000 Datensätze gespeichert werden müssen, werden 30.000 Datenseiten benötigt. Zu diesem Zeitpunkt werden wir mit dem gleichen Abfrageproblem konfrontiert wie zu viele Daten auf einer einzelnen Seite, und das können wir nicht durchquere sie einzeln. Zu diesem Zeitpunkt wird auch ein Verzeichnis benötigt, das schnell abgefragt werden kann. Dieses Verzeichnis ist „Index“.
Basierend auf der in der Abbildung oben gezeigten Datenseite kann die folgende Indexstruktur gebildet werden: 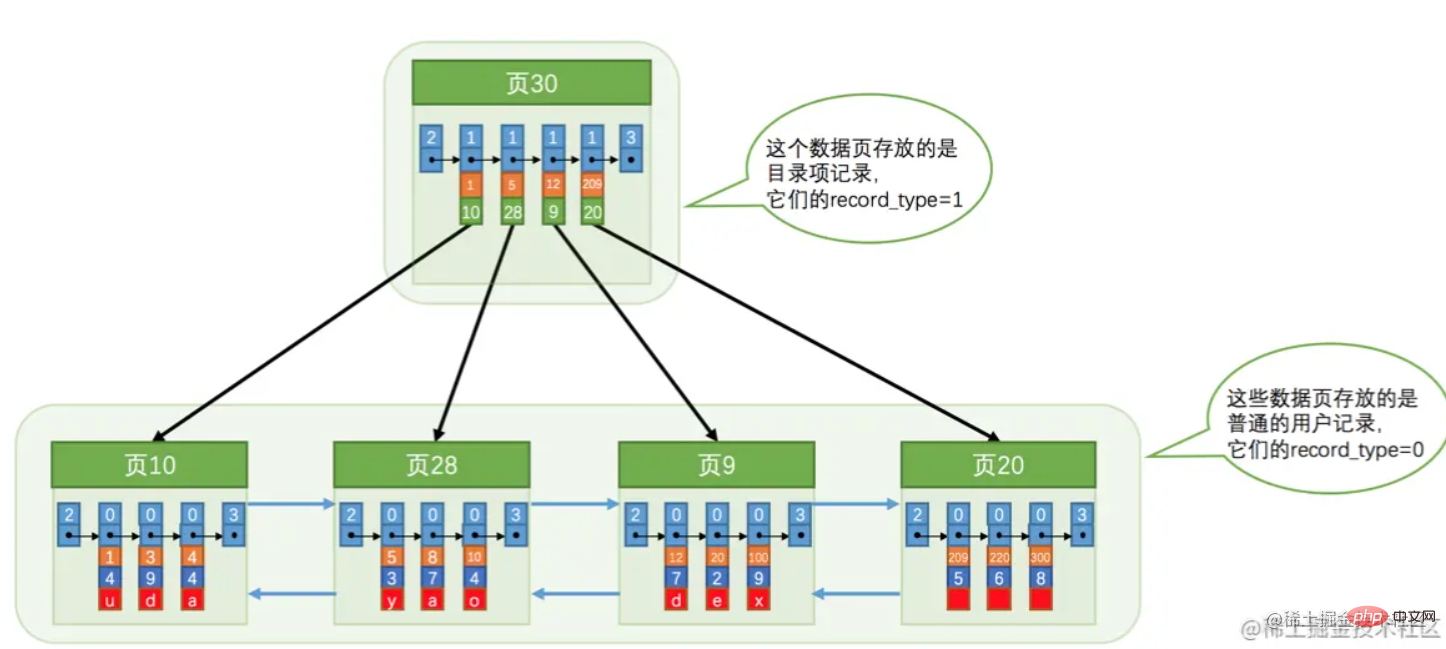 Dies wird oft als Clustered-Index bezeichnet, und die Blätter sind Daten. Hierbei ist zu beachten, dass „Seite 30“ den Primärschlüssel und die Seitennummer speichert, auf der er sich befindet.
Wenn eine einzelne Indexseite voll ist, wird sie geteilt. Erzeugt eine Baumstruktur wie unten gezeigt.
Dies wird oft als Clustered-Index bezeichnet, und die Blätter sind Daten. Hierbei ist zu beachten, dass „Seite 30“ den Primärschlüssel und die Seitennummer speichert, auf der er sich befindet.
Wenn eine einzelne Indexseite voll ist, wird sie geteilt. Erzeugt eine Baumstruktur wie unten gezeigt. 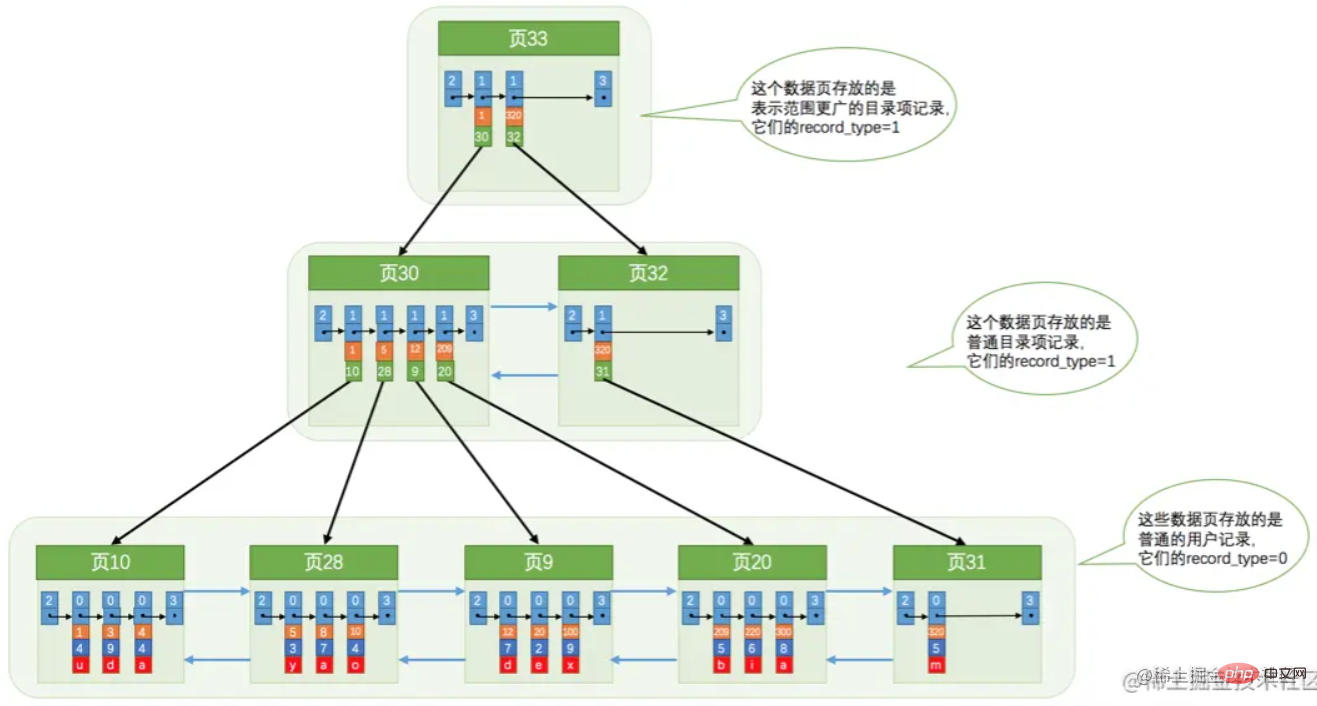 Das obige Bild ist jedoch aus Gründen der Kennzeichnungsfreundlichkeit nicht ganz korrekt. Zuerst sollte ein Wurzelknoten generiert werden. Wenn der Wurzelknoten voll ist, wird er geteilt. Der Wurzelknoten zeichnet die Indexseiteninformationen nach der Aufteilung auf.
Das obige Bild ist jedoch aus Gründen der Kennzeichnungsfreundlichkeit nicht ganz korrekt. Zuerst sollte ein Wurzelknoten generiert werden. Wenn der Wurzelknoten voll ist, wird er geteilt. Der Wurzelknoten zeichnet die Indexseiteninformationen nach der Aufteilung auf.
Einfach ausgedrückt ist es wie das Wachstum eines Baumes, angefangen bei den Wurzeln bis hin zum Stamm, den Zweigen, den Blättern usw.
Sekundärer IndexDie Idee ist die gleiche wie beim Clustered-Index. Der Unterschied besteht darin, dass die Blattknoten des sekundären Index keine echten Daten sind, sondern der Primärschlüssel der Daten. Sie müssen die Operation „Tabelle zurückgeben“ ausführen, um die tatsächlichen Daten zu erhalten.
TabellenbereichBisher kennen wir bereits die Speicherstruktur eines einzelnen Datenelements sowie die kleinste Seite der Speicherdateneinheit. Die Datenseiten sind durch eine doppelt verknüpfte Liste verbunden und die Datenseiten sind nicht unbedingt fortlaufend.
Zu diesem Zeitpunkt tritt ein Problem auf. Was passiert, wenn die Seiten der Datensätze in derselben Tabelle in den Speicheradressen zu weit voneinander entfernt sind? Stellen Sie sich vor, dass sie nach Peking, New York und London reisen, um drei Personen zu finden. Man muss sie einzeln suchen und verschwendet viel Zeit auf der Reise. Wenn Sie sie in einem Land oder sogar einer Stadt sammeln, geht es viel schneller.
So entstand das Konzept von
District. Ein Bereich besteht aus 64 aufeinanderfolgenden Seiten. Standardmäßig belegt ein Bereich 1M Speicher. Bei der Beantragung von Speicher belegt dieser jeweils 1 MB Speicherplatz und die Datenseiten liegen nebeneinander, wodurch das Problem der „zufälligen E/A“ bis zu einem gewissen Grad gelöst wird. Auf der Grundlage von Bereichen werden die Blattknoten und Nicht-Blattknoten des B+-Baums in verschiedenen Bereichen aufgezeichnet, um die Abfrageeffizienz effektiver zu verbessern. Die Menge dieser Bereiche wird als „Segment“ bezeichnet. Nach diesem Konzept müssen Sie zum Einfügen des ersten Datensatzes zwei Bereichsräume, einen Clustered-Index-Wurzelknoten und eine Datenseite beantragen. Diesmal müssen Sie 2 MB Speicherplatz beantragen! Ich habe nichts getan und der 2M-Speicherplatz ist weg. Ist das vernünftig? Offensichtlich ist das unvernünftig.
Also haben wir uns das Konzept des „Fragmentbereichs“ ausgedacht. Der fragmentierte Bereich gehört direkt zum Tabellenbereich und gehört zu keinem Segment. Der Prozess der Speicherzuweisung ändert sich wie folgt:
1) Beim ersten Einfügen von Daten wird der Speicherplatz als einzelne Seite aus dem Fragmentbereich zugewiesen.2) Wenn ein Segment 32 Fragmentbereichsseiten belegt hat, wird der Platz als vollständiger Bereich zugewiesen.
Der Tabellenbereich ist außerdem unterteilt in:Systemtabellenbereich
undUnabhängiger Tabellenbereich
Darüber hinaus gibt es auch dieXDES-Eintragsdatenstruktur einer Zone. Der Inhalt ist zu umfangreich und kompliziert. Wenn Sie mehr wissen möchten, können Sie das Originalbuch lesen. Denken
1) Sind mehr Indizes besser? Welche Auswirkungen wird es haben, wenn es mehr gibt?Je mehr, desto besser. Wie Sie oben sehen können, erfordern Indexdatensätze auch Speicherverbrauch. Jeder Index entspricht einem B+-Baum, und jeder Baum erfordert zwei Segmente, um Blattknoten bzw. Nicht-Blattknoten aufzuzeichnen. Dies führt zu einer großen Speicherverschwendung. Das ist nicht inakzeptabel, schließlich besteht die Bedeutung des Index selbst darin, Raum gegen Zeit zu tauschen. Wir müssen jedoch wissen, dass das Hinzufügen, Löschen und Ändern von Daten zu Änderungen im Index führt, was eine Neuzuweisung von Knoten durch den Index sowie das Recycling und die Zuweisung von Seitenspeicher erfordert. Dies sind alles E/A-Vorgänge. Wenn zu viele Indizes vorhanden sind, führt dies zwangsläufig zu einer Leistungseinbuße.
Daher kann die sinnvolle Verwendung gemeinsamer Indizes das Problem zu vieler Einzelindizes lösen. Darüber hinaus hat der Index eine Längenbeschränkung und zu lange Felder sind nicht für die Indizierung geeignet.
2) Warum ist die Effizienz der Indexabfrage so hoch?Dies ist tatsächlich ein Algorithmusproblem. Nehmen Sie als Beispiel an, dass die Indexseiten von Nicht-Blattknoten jeweils 1000 Daten aufzeichnen können und jeder Blattknoten 500 Daten aufzeichnen kann B+-Baum (Wurzelknoten nicht mitgezählt), er kann 1000
1000500 Datensätze speichern. Ein Index mit einer dreischichtigen Struktur kann so viele Datensätze speichern, dass jedes Mal nur wenige Abfragen erforderlich sind, um die Daten zu finden, sodass die Effizienz natürlich hoch ist. Tatsächlich sind die Daten, die auf einer einzelnen Indexseite aufgezeichnet werden können, viel größer.
In ähnlicher Weise können Sie hier über ein Problem nachdenken. Wenn das einzelne Datenelement im Blattknoten so groß ist, dass eine Datenseite nur 3 Datensätze speichern kann, erhöht sich die Tiefe des B+-Baums Es ist sinnvoll, den einzelnen Datensatz in der Tabelle zu reduzieren. Die Größe ist ebenfalls eine Optimierung. 3) Wird die SQL-Ausführung langsam sein, wenn die Datenmenge groß ist? Tatsächlich möchte ich mich wirklich über dieses Problem beschweren. Die Abfrageeffizienz von Millionen von Daten beträgt xx Sekunden, was zu langsam ist. Es lässt sich nicht leugnen, dass die Leistung von MySQL tatsächlich schwächer ist als die einiger Datenbanken, aber bei Millionen von Daten wird es langsam sein. Überlegen Sie, ob Ihr SQL- und Tabellenstrukturdesign angemessen ist. Ganz zu schweigen von Abfragen auf Millionenebene, selbst Dutzende Millionen Ebenen können Abfragen auf Millisekundenebene erreichen.
Nur über die Menge zu reden, ist Unsinn. Sie müssen sich tatsächlich die von der Sperre belegte Speichergröße ansehen, wenn Ihre Tabelle Hunderte von Feldern enthält oder Felder mit extrem langen Zeichen vorhanden sind. Dann können dich nicht einmal die Götter retten. Der Artikel stellt hauptsächlich das Konzept der MySQL-Datenstruktur vor. Der größte Teil des Inhalts stammt aus dem Buch „Understanding MySQL from the Root“. Es wurden viele Vereinfachungen vorgenommen, die als Grundlage für das Verständnis einiger Konzepte dienen können. Wenn es Fehler oder Auslassungen gibt, danke für die Korrektur. 【Verwandte Empfehlungen: MySQL-Video-Tutorial】Zusammenfassung
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der Datenspeicherstruktur in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ein Artikel über die schnelle Migration von MySQL-Daten
- Bringen Sie Ihnen Schritt für Schritt bei, wie Sie MySQL auf einem Mac installieren und es mit phpMyAdmin visualisieren
- Interviewer: Lassen Sie uns über den zweistufigen Übermittlungsmechanismus von MySQL sprechen.
- Machen Sie sich mit dem Datenbankpufferpool (Pufferpool) in MySQL vertraut
- Ein Artikel, der darüber spricht, wie der Knoten MySQL-Verarbeitungsanweisungen kapselt
- Lassen Sie uns ausführlich über Transaktionsfunktionen und Implementierungsprinzipien in MySQL sprechen