
Heim >Datenbank >MySQL-Tutorial >Machen Sie sich mit dem Datenbankpufferpool (Pufferpool) in MySQL vertraut
Machen Sie sich mit dem Datenbankpufferpool (Pufferpool) in MySQL vertraut

- 青灯夜游nach vorne
- 2023-02-09 20:11:072410Durchsuche

Für Tabellen, die die InnoDB-Speicher-Engine verwenden, wird der Speicherplatz in Seiteneinheiten verwaltet, als grundlegende Granularität für das Ein- und Auslagern zwischen Speicher und Festplatte. Wenn wir eine Seite von der Festplatte in den Speicher laden, wird Festplatten-E/A durchgeführt. Der Overhead der Festplatten-E/A wirkt sich stark auf die Gesamtleistung aus, wenn wir die entsprechende Seite direkt aus dem Speicher lesen würden. Würde dies den durch die Festplatten-E/A verursachten Leistungsverlust verringern und die Effizienz erheblich verbessern? Auf dieser Grundlage erschien der Pufferpool (
Pufferpool). Lassen Sie uns als Nächstes über den Pufferpool in InnoDB sprechen.Buffer Pool) 出现了,那么接下来,我们就来谈谈InnoDB中的Buffer Pool。
缓冲池(Buffer Pool)
有人会想,既然缓冲池这么好,那我们将所有数据都存储到缓冲池中不就好了,不不不,缓冲池是操作系统分配的一片连续的内存。而内存相比于磁盘的容量小得多,并且价格昂贵。那么操作系统会给缓冲池分配多少内存呢?
- 默认情况下,缓冲池的大小为128MB;
当然,如果你的机器的内存容量非常大,可以在配置文件中配置启动选项参数innodb_buffer_pool_size单位是字节,最小不能小于5MB。
缓冲池的内部结构
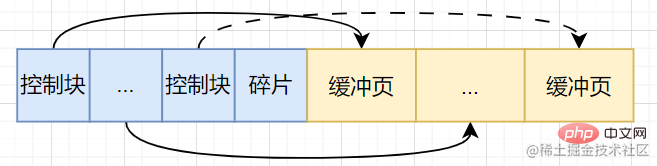
缓冲池将操作系统分配的这一片连续的内存,划分成若干个大小默认为16KB的页(缓冲页)【此时还没有真正的磁盘页被缓存到Buffer Pool中】,当我们从磁盘中换入一个页到缓冲池中,如何分配位置呢?因此就需要一些控制信息来标识这些缓冲池中的缓冲页,这些控制信息都存放在一个叫控制块的内存区域中,与缓冲页一一对应。控制块的大小也是固定的。因此在这片连续的内存空间中,难免会产生内存碎片。综上,缓冲池的内部结构如下:
- 缓冲页
- 控制块:页号、缓冲页在缓冲池中的地址、链表节点信息等。
- 内存碎片【若内存分配得当,内存碎片可有可无】
缓冲池的管理
上面在控制块中提到了链表节点信息,那么链表节点是用来做什么的呢?是为了更好的管理缓冲池中的页。而链表就是用来链接控制块的,因为控制块与缓冲页是一一对应的。
1)空闲链表
将所有空闲的缓冲页对应的控制块链接起来,形成的链表。
解决的问题:从磁盘中换入一个页到缓冲池中,如何区分缓冲池中的哪个页是空闲的呢?而有了空闲链表之后,换入一个磁盘页到缓冲池中时,就直接从空闲链表中获取一个空闲的缓冲页,并将磁盘页中对应的信息填到缓冲页对应的控制块中,然后将该控制块从空闲链表中删除即可。
2)更新链表
若修改了缓冲池中的缓冲页的数据,导致其与磁盘中数据不一致,该页称为脏页。将所有脏页对应的控制块链接起来形成更新链表,在将来的某个时间根据该链表将对应缓存页的数据刷新到磁盘中。
3)LRU链表
缓冲池的大小是有限的,如果缓存的页超出了缓冲池的大小,即没有空闲的缓冲页了,当有新的页要添加到缓冲池中时,采取LRU的策略将旧的缓冲页从缓冲池中移除,然后将新的页添加进来。由于LRU链表涉及的内容较多,我们接下来单独介绍。
LRU链表所蕴含的“哲理”
先提一下预读机制
在I/O上的优化机制,预读顾名思义,会异步地把某些页面加载到缓冲池中,预计很快就会需要这些页面,这些请求在一个范围内引入所有页面,就是所谓的 局部性原理,目的是减少磁盘I/O。
了解预读机制之前,先回顾一下InnoDB逻辑存储单元:表空间(tablespace)→段(segment )→区(extent)→页(page)。其中特意提一下区,后面会用到:一个区就是物理位置上连续的64个页
Pufferpool
Einige Leute denken vielleicht, dass wir, da der Pufferpool so gut ist, warum nicht alle Daten im Pufferpool speichern? Das ist in Ordnung, nein, nein, nein,Der Pufferpool ist ein zusammenhängender Speicher, der vom Betriebssystem zugewiesen wird. Speicher hat eine viel geringere Kapazität als Festplatten und ist teuer. Wie viel Speicher wird das Betriebssystem dem Pufferpool zuweisen? 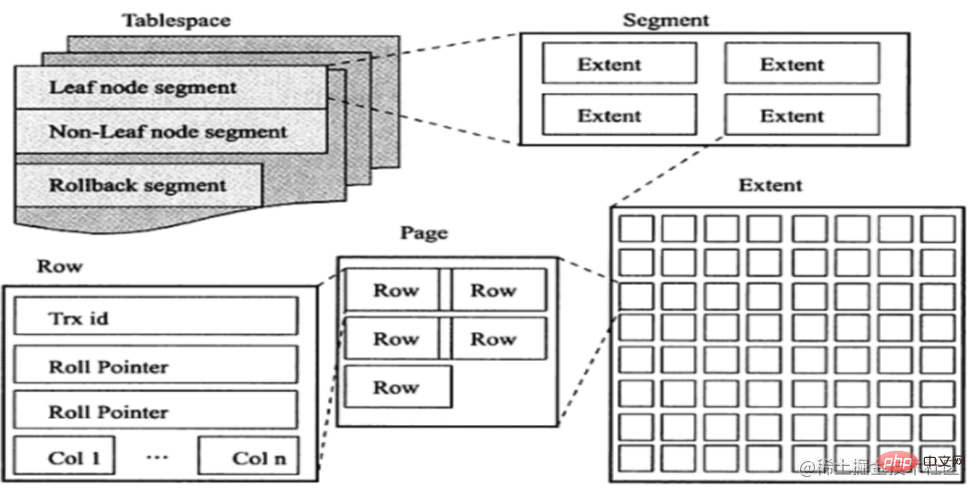
- Standardmäßig beträgt die Größe des Pufferpools 128 MB
innodb_buffer_pool_sizeDie Einheit ist Byte und das Minimum darf nicht weniger als 5 MB betragen.
Interne Struktur des Pufferpools
🎜Der Pufferpool unterteilt den vom Betriebssystem zugewiesenen kontinuierlichen Speicher in mehrere Seiten (Pufferseiten) mit einer Standardgröße von 16 KB [ Zu diesem Zeitpunkt wurden keine echten Festplattenseiten im Pufferpool zwischengespeichert.] Wie weisen wir den Speicherort zu, wenn wir eine Seite von der Festplatte in den Pufferpool übertragen? Daher sind einige Steuerinformationen erforderlich, um die Pufferseiten in diesen Pufferpools zu identifizieren. Diese Steuerinformationen werden in einem Speicherbereich namens Steuerblock gespeichert und entsprechen eins zu eins der Pufferseite. Die Größe des Steuerblocks ist ebenfalls festgelegt. Daher kommt es in diesem kontinuierlichen Speicherplatz zwangsläufig zu einer Speicherfragmentierung. Zusammenfassend ist die interne Struktur des Pufferpools wie folgt: 🎜- Pufferseite
- Steuerblock: Seitennummer, Adresse der Pufferseite im Pufferpool, Informationen zum verknüpften Listenknoten , usw.
- Speicherfragmentierung [Wenn der Speicher richtig zugewiesen ist, ist eine Speicherfragmentierung verzichtbar]
 🎜
🎜Pufferpoolverwaltung
🎜 Die verlinkte Die Informationen zu Listenknoten werden oben im Steuerblock erwähnt. Wofür werden die verknüpften Listenknoten verwendet? Dies dient dazu, die Seiten im Pufferpool besser zu verwalten. Die verknüpfte Liste wird zum Verknüpfen von Steuerblöcken verwendet, da zwischen Steuerblöcken und Pufferseiten eine Eins-zu-eins-Entsprechung besteht. 🎜1) Freie verknüpfte Liste
🎜 Verknüpfen Sie die Steuerblöcke, die allen freien Pufferseiten entsprechen, um eine verknüpfte Liste zu bilden. 🎜🎜🎜Problem gelöst: Wie kann man beim Auslagern einer Seite von der Festplatte in den Pufferpool unterscheiden, welche Seite im Pufferpool frei ist? Bei der freien verknüpften Liste wird beim Auslagern einer Festplattenseite in den Pufferpool eine freie Pufferseite direkt aus der freien verknüpften Liste abgerufen und die entsprechenden Informationen auf der Festplattenseite werden in den Steuerblock gefüllt, der der Pufferseite entspricht. und dann einfach den Kontrollblock aus der freien verknüpften Liste löschen. 🎜2) Verknüpfte Liste aktualisieren
🎜Wenn die Daten der Pufferseite im Pufferpool geändert werden, was dazu führt, dass sie nicht mit den Daten auf der Festplatte übereinstimmen, wird die Diese Seite wird als schmutzige Seite bezeichnet. Verknüpfen Sie die Steuerblöcke, die allen schmutzigen Seiten entsprechen, um eine verknüpfte Aktualisierungsliste zu bilden, und aktualisieren Sie die Daten der entsprechenden Cache-Seite zu einem bestimmten Zeitpunkt in der Zukunft basierend auf dieser verknüpften Liste auf der Festplatte. 🎜3) LRU-verknüpfte Liste
🎜Die Größe des Pufferpools ist begrenzt. Wenn die zwischengespeicherten Seiten die Größe des Pufferpools überschreiten, ist kein freier Puffer vorhanden Wenn eine neue Seite zum Pufferpool hinzugefügt werden soll, wird die LRU-Strategie übernommen, um die alte Pufferseite aus dem Pufferpool zu entfernen und dann die neue Seite hinzuzufügen. Da die verknüpfte LRU-Liste viele Inhalte enthält, werden wir sie als nächstes separat vorstellen. 🎜Die in der LRU-verknüpften Liste enthaltene „Philosophie“
Lassen Sie mich zunächst den Vorlesemechanismus erwähnen h2>🎜In I Der Optimierungsmechanismus für /O lädt, wie der Name schon sagt, bestimmte Seiten asynchron in den Pufferpool. Diese Seiten werden voraussichtlich bald alle Seiten in einem Bereich einführen ist das sogenannte 🎜LokalitätsprinzipDer Zweck besteht darin, die Festplatten-E/A zu reduzieren. 🎜🎜Bevor wir den Read-Ahead-Mechanismus verstehen, schauen wir uns die logische Speichereinheit von InnoDB an: Tablespace → Segment → Extent → Seite. Es werden speziell Bereiche erwähnt, die später verwendet werden: Ein Bereich ist eine fortlaufende 64 Seite an einem physischen Ort, das heißt, die Größe eines Bereichs beträgt 1 MB.🎜🎜🎜🎜🎜Die Vorlesung Der Mechanismus kann in die folgenden zwei Typen unterteilt werden: 🎜
-
Lineares Vorauslesen: Eine Technik, die anhand des sequentiellen Zugriffs auf Seiten im Pufferpool vorhersagt, welche Seiten möglicherweise bald benötigt werden. Durch Konfigurieren des Parameters innodb_read_ahead_threshold wird eine asynchrone Leseanforderung ausgelöst, um alle Seiten im nächsten Bereich in den Pufferpool zu lesen, wenn die Seiten eines bestimmten Bereichs, auf die nacheinander zugegriffen wird, den Wert dieses Parameters überschreiten.
-
Zufälliges Vorauslesen: Kann basierend auf Seiten, die sich bereits im Pufferpool befinden, vorhersagen, wann Seiten benötigt werden, unabhängig von der Reihenfolge, in der diese Seiten gelesen werden. Wenn 13 aufeinanderfolgende Seiten desselben Extents im Pufferpool gefunden werden, gibt InnoDB asynchron eine Anfrage aus, um die verbleibenden Seiten des Extents vorab abzurufen. Das zufällige Lesen wird durch die Konfiguration der Variablen innodb_random_read_ahead gesteuert.
Wie verwaltet herkömmliches LRU Pufferseiten?
Verwenden Sie den LRU-Algorithmus, um die zuletzt verwendeten Pufferseiten zu verwalten und eine entsprechende verknüpfte Liste zur einfachen Eliminierung zu erstellen.
Wenn auf eine Seite zugegriffen wird [d. h. wenn kürzlich darauf zugegriffen wurde]
- Die Seite befindet sich im Pufferpool. Verschieben Sie den entsprechenden Steuerblock an den Kopf der LRU-verknüpften Liste.
- Die Seite befindet sich nicht im Pufferpool. Entfernen Sie sie zumindest Fügen Sie die zuletzt verwendete Seite am Ende hinzu und entfernen Sie sie von der Festplatte. Laden Sie die Seite und platzieren Sie sie an der Spitze der LRU-verknüpften Liste.
Warum verwendet InnoDB also nicht einen so intuitiven LRU-Algorithmus? Die Gründe sind wie folgt:
-
Read-Ahead-Fehler
Die Seiten im Pufferpool, die im Voraus gelesen werden, werden an der Spitze der LRU-verknüpften Liste platziert, aber viele von ihnen werden möglicherweise nicht gelesen.
-
Pufferpoolverschmutzung
Das Laden vieler weniger häufig verwendeter Seiten in den Pufferpool führt dazu, dass häufiger verwendete Seiten aus dem Pufferpool entfernt werden. Zum Beispiel: vollständiger Tabellenscan
Wie verwaltet die optimierte LRU Pufferseiten?
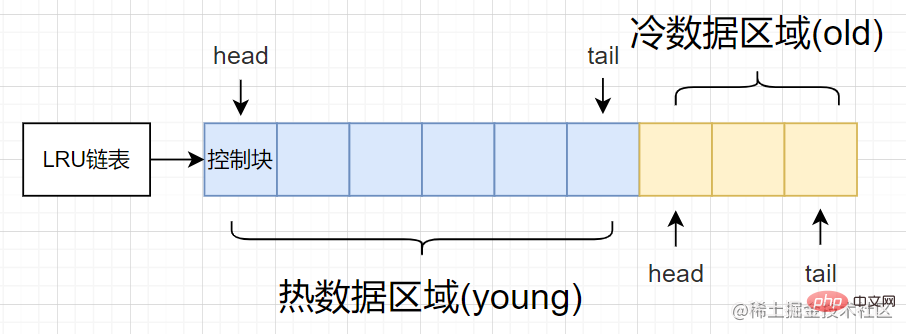
Basierend auf den oben genannten Mängeln unterteilt die optimierte spezifische Methode die traditionelle LRU-verknüpfte Liste in zwei Teile: Hot-Data-Bereich [junger Bereich] und Cold-Datenbereich [alter Bereich]
- Hot-Data-Bereich [junger Bereich] : Nutzungshäufigkeit Hohe Pufferseite
- Kalter Datenbereich [älterer Bereich]: Bereich mit geringer Nutzungshäufigkeit
Das Strukturdiagramm sieht wie folgt aus:
Wie in der Abbildung gezeigt, der heiße Datenbereich und der kalte Wenn der Datenbereich unterschiedliche Anteile einnimmt, können wir den Anteil des „kalten Datenbereichs“ über die Startoption innodb_old_blocks_pct steuern. innodb_old_blocks_pct启动选项来控制冷数据区域所占比例。
改进后的LRU如何更好的解决预读失效问题呢?
- 某个页在初次加载到缓冲池中时,先淘汰掉冷数据区域尾部的控制块(即其对应的页淘汰掉),然后新页对应的控制块会先放到冷数据区域的头部。
- 若后续该页不被进行访问就会慢慢从冷数据区域中被淘汰掉,总体不会影响热数据区域访问频繁的缓冲页。
改进后的LRU如何更好的解决缓冲池污染问题呢?
先说结论,并没有很好的优化这个问题,原因如下【以全表扫描为例】:
- 某个初次访问的页同样会放到冷数据区域的头部,但后续访问又会将其放到热数据区域的头部,这样同样会把访问频率较高的页给挤掉。
那么到底该如何解决缓冲池污染问题呢?
- 缓冲池引入了冷数据区域时间窗口机制,即只有后续访问该页与第一访问该页的时间间隔大于规定的窗口值,就会将该页从冷数据区域移到热数据区域的头部。小于规定的窗口值,就不会进行移动操作。
- 同样,窗口值可通过
innodb_old_blocks_time
Wie kann die verbesserte LRU das Problem des Read-Ahead-Fehlers besser lösen?
Wenn eine Seite zum ersten Mal in den Pufferpool geladen wird, wird zuerst der Steuerblock am Ende des kalten Datenbereichs entfernt (dh die entsprechende Seite wird entfernt) und dann der entsprechende Steuerblock Die neue Seite wird zunächst im Kaltdatenbereich platziert.
- Wenn später nicht auf die Seite zugegriffen wird, wird sie langsam aus dem kalten Datenbereich entfernt. Im Allgemeinen hat dies keine Auswirkungen auf die häufig aufgerufenen Pufferseiten im heißen Datenbereich.
- Wie kann die verbesserte LRU das Problem der Pufferpoolverschmutzung besser lösen?
Lassen Sie uns zunächst über die Schlussfolgerung sprechen. Die Gründe dafür sind folgende:
🎜Eine zum ersten Mal besuchte Seite wird ebenfalls an der Spitze platziert des Kaltdatenbereichs, aber nachfolgende Besuche Es wird an der Spitze des Hot-Datenbereichs platziert, wodurch auch Seiten mit höherer Zugriffshäufigkeit verdrängt werden. 🎜🎜🎜Wie lässt sich also das Problem der Pufferpoolverschmutzung lösen? 🎜🎜🎜Der Pufferpool führt den Zeitfenstermechanismus für den kalten Datenbereich ein. Das heißt, solange das Zeitintervall zwischen dem nachfolgenden Zugriff auf die Seite und dem ersten Zugriff auf die Seite größer als der angegebene Fensterwert ist, wird die Seite verschoben vom Kaltdatenbereich zum Heißdatenbereich. Wenn der Fensterwert kleiner als der angegebene Wert ist, wird der Verschiebevorgang nicht ausgeführt. 🎜🎜Ähnlich kann der Fensterwert über den Parameterinnodb_old_blocks_time [Einheit ms] festgelegt werden, und 1 s filtert die meisten Vorgänge wie vollständige Tabellenscans heraus. Beispielsweise darf bei einem vollständigen Tabellenscan das Zeitintervall zwischen mehreren Zugriffen auf eine Seite 1 Sekunde nicht überschreiten. 🎜🎜🎜Pufferpool vs. Abfragecache🎜🎜🎜Sind Pufferpool und Abfragecache dasselbe? →Nein 🎜🎜🎜🎜Der Pufferpool versucht, häufig verwendete Daten zu speichern. Wenn nicht, wird festgestellt, ob sich die Seite im Pufferpool befindet Wenn vorhanden, wird die Seite direkt über den Speicher oder die Festplatte im Pufferpool gespeichert und dann gelesen. 🎜🎜Der Abfrage-Cache speichert die Abfrageergebnisse im Voraus, sodass Sie die Ergebnisse direkt abrufen können, ohne sie beim nächsten Mal auszuführen. Es ist zu beachten, dass der Abfragecache in MySQL nicht den Abfrageplan zwischenspeichert, sondern die entsprechenden Ergebnisse der Abfrage. Die Trefferbedingungen sind streng und solange sich die Datentabelle ändert, wird der Abfragecache ungültig, sodass die Trefferquote niedrig ist. 🎜🎜🎜【Verwandte Empfehlungen: 🎜MySQL-Video-Tutorial🎜】🎜Das obige ist der detaillierte Inhalt vonMachen Sie sich mit dem Datenbankpufferpool (Pufferpool) in MySQL vertraut. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Unterschiede zwischen Nosql und MySQL?
- So komprimieren Sie großen Textspeicher in MySQL
- Was soll ich tun, wenn der MySQL-Dienst nicht gestartet werden kann?
- Ein Artikel, der kurz analysiert, wie MySQL das Phantomleseproblem löst
- So installieren Sie PHP und MySQL in Redhat
- Verfügt MySQL über temporäre Variablen?