
Heim >Datenbank >MySQL-Tutorial >InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM
InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM

- coldplay.xixinach vorne
- 2021-02-02 09:16:082601Durchsuche
MySQL-TutorialWarum B+Tree für den in der Kolumne vorgestellten Index verwenden? Die erste Frage des Interviewers zum Thema MySQL war damals noch nicht erwartet Dieser junge Mann befolgte keine Kampfethik und folgte nicht der Routine. Als er nach MySQL-bezogenen Kenntnissen gefragt wurde, fragte er alle nach Indexoptimierung, Indexfehlern und anderen damit zusammenhängenden Problemen. Warum sind die Speicherdateien unterschiedlich? Selbst wenn Sie den MVCC-Mechanismus untersuchen, reicht dies aus. Deshalb werde ich dieses Mal diesen Teil der Wissenspunkte zusammenfassen.
Warum müssen Sie einen Index erstellen? Zunächst einmal wissen wir alle, dass der Zweck des Indexaufbaus darin besteht, die Abfragegeschwindigkeit zu erhöhen. Warum kann ein Index also die Abfragegeschwindigkeit erhöhen? Schauen wir uns ein schematisches Diagramm eines Index an. 
select * from Table where id = 15 dann wird in Ermangelung eines Index ein vollständiger Tabellenscan durchgeführt, d. h. eine Suche nach der anderen bis zum id gefunden wird. =15, die Zeitkomplexität dieses Datensatzes ist O(n); Was wäre, wenn wir ihn mit einem Index abfragen? Zunächst wird eine binäre Suche im Indexwert basierend auf id=15 durchgeführt. Die Effizienz der binären Suche ist sehr hoch und ihre Zeitkomplexität beträgt O(logn). Die Datenmenge ist ebenfalls relativ groß und wird daher im Allgemeinen nicht im Speicher, sondern direkt auf der Festplatte gespeichert. Daher ist zum Lesen des Dateiinhalts auf der Festplatte zwangsläufig eine Festplatten-E/A erforderlich.
Warum verwendet MySQL B+Tree für die Indizierung? Wie oben erwähnt, werden Indexdaten im Allgemeinen auf der Festplatte gespeichert, die Berechnung der Daten muss jedoch im Speicher erfolgen. Wenn die Indexdatei groß ist, ist dies nicht möglich Wenn Sie also den Index für die Datensuche verwenden, werden mehrere Festplatten-E/A-Vorgänge ausgeführt, um die Indexdaten stapelweise in den Speicher zu laden.
Hash-Typ
Derzeit stehen bei MySQL tatsächlich zwei Indexdatentypen zur Auswahl: einer ist BTree (eigentlich B+Tree) und der andere Hash. 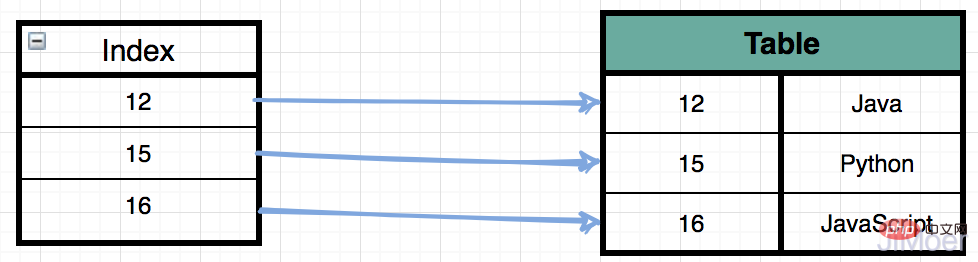
Aber warum entscheiden sich die meisten Menschen im tatsächlichen Einsatz für BTree? select * from Table where id = 15 那么在没有索引的情况下其实是会进行全表扫描的,就是挨个去找,直到找到id=15的这条记录,时间复杂度是O(n);
如果在有索引的情况下去进行查询呢。首先会根据id=15,在索引值里面进行二分查找,二分查找的效率是很高的,它的时间复杂度是O(logn);
这就是索引为什么能提高查询效率了,但是索引数据的量也是比较大的,所以一般并不是存储在内存中的,都是直接存储在磁盘中的,所以对磁盘中的文件内容进行读取,免不了要进行磁盘IO。
MySQL的索引为什么使用B+Tree
上面我们也说了,索引数据一般是存储在磁盘中的,但是计算数据都是要在内存中进行的,如果索引文件很大的话,并不能一次都加载进内存,所以在使用索引进行数据查找的时候是会进行多次磁盘IO,将索引数据分批的加载到内存中,<strong>因此一个好的索引的数据结构,在得到正确的结果前提下,一定是磁盘IO次数最少的。</strong>
Hash类型
目前MySQL其实是有两种索引数据类型可以选择的,一个是BTree(实际是B+Tree)、一个Hash。
但是为什么在实际的使用过程中,基本上大部分都是选择BTree呢?
因为如果使用Hash类型的索引,MySQL在创建索引的时候,会对索引数据进行一次Hash运算,这样根据Hash值就能快速的定位到磁盘指针了,就算数据量很大,也能快速精准的定位到数据。
- 但是像
select * from Table where id > 15Denn wenn Sie einen Hash-Typ-Index verwenden, führt MySQL beim Erstellen des Index eine Hash-Operation für die Indexdaten durch. Auf diese Weise kann der Festplattenzeiger schnell anhand des Hash-Werts lokalisiert werden groß, es kann schnell und genau durchgeführt werden, um die Daten zu lokalisieren.
select * from Table where id > Auch Hash-Typ-Indizes können nicht sortiert werden.
Obwohl die unterste Schicht von MySQL eine Reihe von Verarbeitungen durchgeführt hat, ist es immer noch nicht vollständig garantiert, dass keine Hash-Kollisionen auftreten.
Binärbaum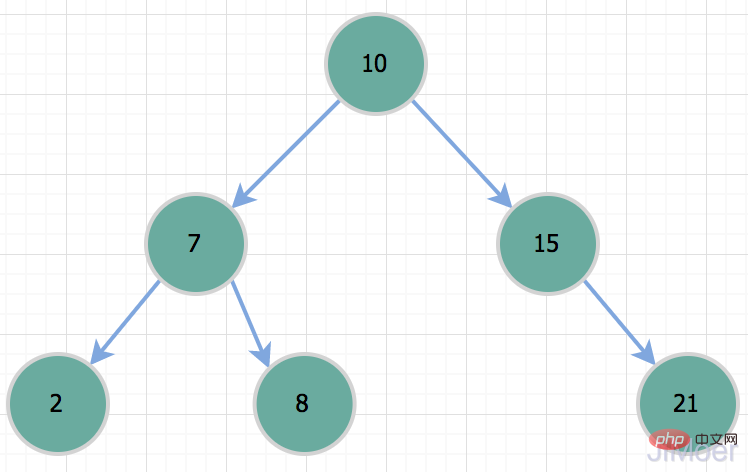
Warum hat MySQL dann keinen Binärbaum als Indexdatenstruktur? Wir alle wissen, dass Binärbäume Daten durch binäre Suche lokalisieren, daher ist der Effekt gut und die Zeitkomplexität beträgt O(logn). in einen Baum Ein Stick ist eine einseitig verknüpfte Liste. Zu diesem Zeitpunkt degeneriert seine Zeitkomplexität auf O(n); 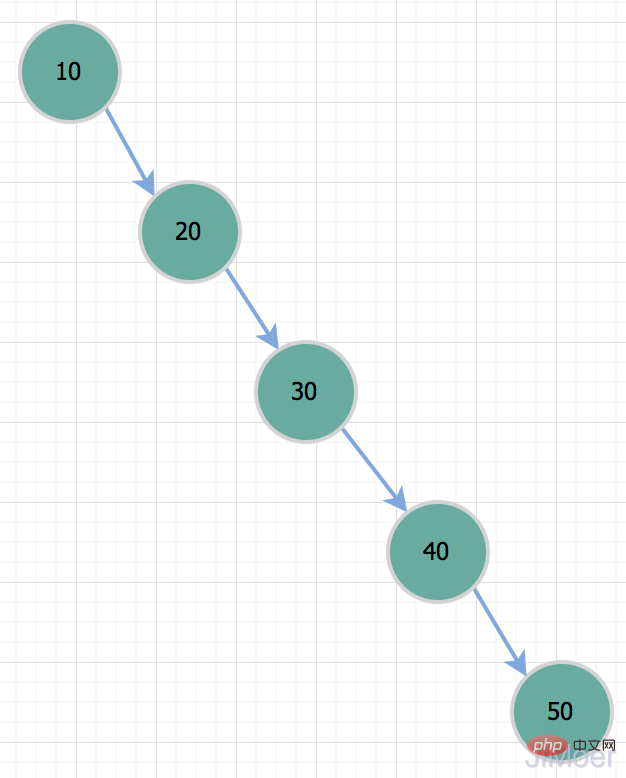
Wenn wir also den Datensatz mit der ID = 50 abfragen möchten, ist dies tatsächlich dasselbe wie ein vollständiger Tabellenscan. Aufgrund dieser Situation ist der Binärbaum nicht als Indexdatenstruktur geeignet.
Ausgeglichener Binärbaum
Da ein Binärbaum unter besonderen Umständen zu einer verknüpften Liste degeneriert, warum kann er dann nicht ausgeglichen werden?
Der Höhenunterschied der untergeordneten Knoten eines ausgeglichenen Binärbaums darf 1 nicht überschreiten. Wie der Binärbaum in der Abbildung unten hat der Knoten mit dem Schlüssel 15 eine Höhe des linken untergeordneten Knotens von 0 und eine Höhe des rechten untergeordneten Knotens von 1. Der Höhenunterschied überschreitet 1 nicht, daher ist der Baum unten ein ausgeglichener Binärbaum.  Da das Gleichgewicht aufrechterhalten werden kann, beträgt die Komplexität der Abfragezeit O (logN). Was das Aufrechterhalten des Gleichgewichts betrifft, sind hauptsächlich einige Linksdrehungen, Rechtsdrehungen usw. erforderlich. Die spezifischen Details zur Aufrechterhaltung des Gleichgewichts sind nicht der Hauptinhalt dieses Artikels. Ich möchte mehr darüber erfahren. Sie können selbst suchen.
Da das Gleichgewicht aufrechterhalten werden kann, beträgt die Komplexität der Abfragezeit O (logN). Was das Aufrechterhalten des Gleichgewichts betrifft, sind hauptsächlich einige Linksdrehungen, Rechtsdrehungen usw. erforderlich. Die spezifischen Details zur Aufrechterhaltung des Gleichgewichts sind nicht der Hauptinhalt dieses Artikels. Ich möchte mehr darüber erfahren. Sie können selbst suchen.
Was sind die Probleme bei der Verwendung dieser Datenstruktur zum Erstellen von MySQL-Indizes?
- Zu viele Festplatten-IOs: In MySQL liest eine IO-Operation nur einen Knoten. Wenn ein Knoten höchstens zwei untergeordnete Knoten hat, gibt es nur den Abfragebereich dieser beiden untergeordneten Knoten, daher muss er genau sein Spezifisch Beim Abrufen von Daten sind mehrere Lesevorgänge erforderlich. Wenn der Baum sehr tief ist, wird eine große Menge an Festplatten-E/A durchgeführt. Die Leistung nimmt natürlich ab.
- Geringe Speicherplatznutzung: Für einen ausgeglichenen Binärbaum speichert jeder Knotenwert ein Schlüsselwort, einen Datenbereich und Zeiger auf zwei untergeordnete Knoten. Daher ist das Laden nur einer so kleinen Datenmenge in einem aufwändigen E/A-Vorgang wirklich übertrieben.
- Der Abfrageeffekt ist instabil: Wenn in einem ausgeglichenen Binärbaum mit einer sehr tiefen Höhe die abgefragten Daten zufällig der Wurzelknoten sind, werden sie schnell gefunden. Wenn es sich bei den abgefragten Daten zufällig um einen Blattknoten handelt, Dann werden mehrere Festplatten-E/As gefunden, und die Antwortzeit liegt möglicherweise nicht in der gleichen Größenordnung wie die des Root-Knotens.
Obwohl der Binärbaum das Gleichgewichtsproblem löst, bringt er auch neue Probleme mit sich, das heißt, aufgrund der Tiefe seines eigenen Baums führt er zu einer Reihe von Effizienzproblemen.
Um das Problem des Ausgleichs von Binärbäumen zu lösen, ist Balance Tree die bessere Wahl.
Balance Tree-B-Tree
B-Tree bedeutet ausgeglichener Multi-Tree. Im Allgemeinen bezeichnen wir die Anzahl der Unterknoten im B-Tree als die Reihenfolge des B-Trees. Normalerweise wird m zur Darstellung der Reihenfolge verwendet. Wenn m 2 ist, handelt es sich um einen ausgeglichenen Binärbaum.
Jeder Knoten eines B-Baums kann höchstens m-1 Schlüsselwörter haben, und es müssen mindestens Math.ceil(m/2)-1 Schlüsselwörter gespeichert werden, alle Blattknoten Alle auf dem gleichen Boden. Das Bild unten zeigt einen B-Baum 4. Ordnung. Math.ceil(m/2)-1个关键字,所有的叶子节点都在同一层。如下图就是一个4阶的B-Tree。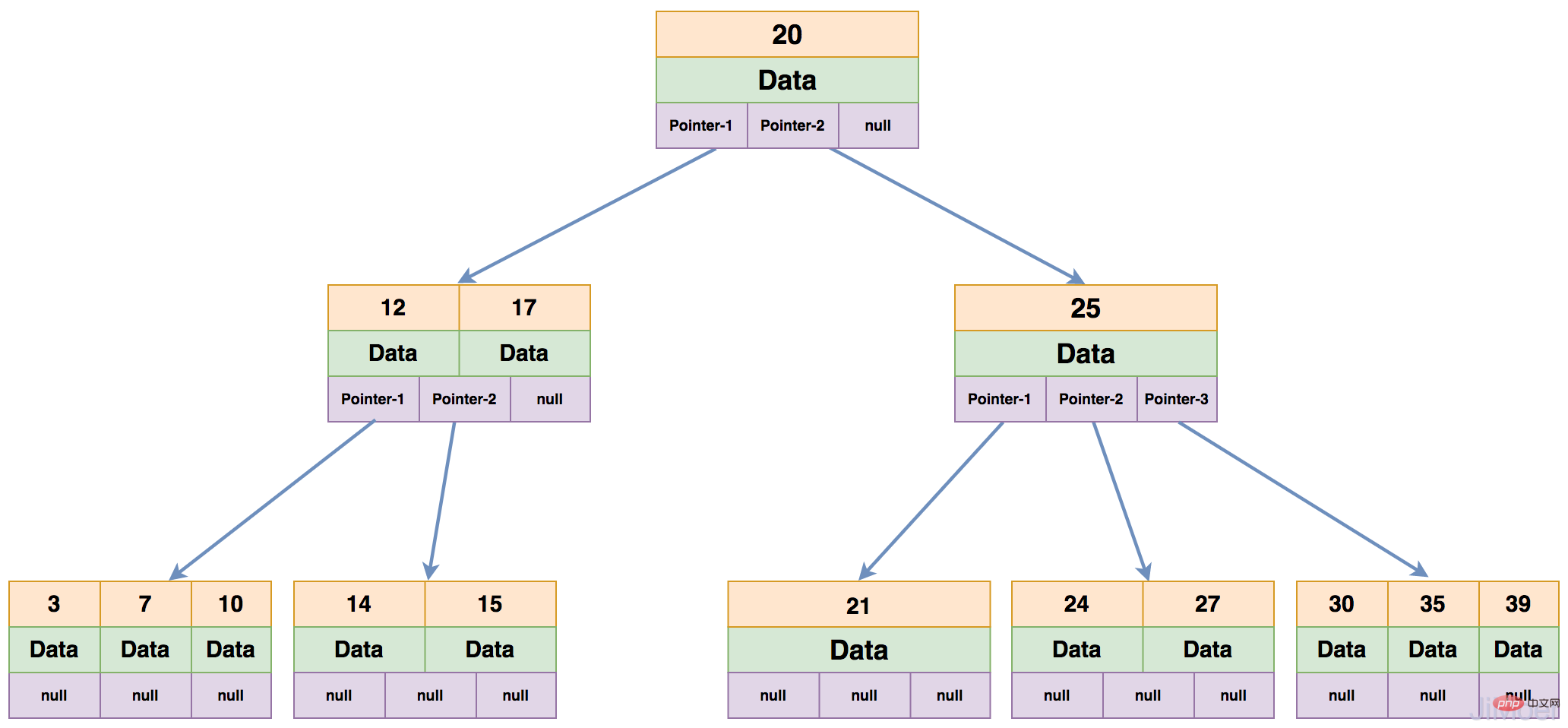
那么我们看一下B-Tree是如何进行查找数据的:
- 若是查询id=7的数据,先将关键字20的节点加载进内存,判断出7比20小;
- 那么加载第一个子节点,若查询的数据等于12或17则直接返回,不等于就继续向下找,发现7小于12;
- 那么继续加载第一个子节点中去,找到7之后,直接将7下面的data数据返回。
这样整个操作其实进行了3次IO操作,但实际上一般的B-Tree每层都是有很多分支(通常都大于100)。
MySQL为了能更好的利用磁盘的IO能力,将操作页的大小设置为了16K,即每个节点的大小为16K。如果每个节点中的关键字都是int类型的,那么就是4个字节,若数据区的大小为8个字节,节点指针再占4个字节,那么B-Tree的每个节点中可以保存的关键字个数为:(16*1000) / (4+8+4)=1000,每个节点最多可存储1000个关键字,每一个节点最多可以有1001个分支节点。
这样在查询索引数据的时候,一次磁盘IO操作可以将1000个关键字,读取到内存中进行计算,B-Tree的一次磁盘IO的操作,顶上平衡二叉数据的N次磁盘IO操作了。
要注意的是:B-Tree为了保证数据的平衡,会做一系列的操作,这个保持平衡的过程比较耗时间,所以在创建索引的时候,要选择合适的字段,并且不要过多的创建索引,创建索引过多的话,在更新数据的时候,更新索引的过程也比较耗时。
还有就是不要选择低区分度字段值作为索引,例如性别字段,总共就两个值,那么就有可能会造成B-Tree的深度过大,索引效率降低。
B+Tree
B-Tree已经很好的解决平衡InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM的问题了,并且也能保证查询效率了,那么为什么会有B+Tree呢?
我们先来B+Tree是什么样子的。
B+Tree是B-Tree的变种,B+Tree的每个节点关键字和m阶的公式关系和B-Tree的不一样了。
首先每个节点的子节点数量和每个节点可存储的关键字比例是1:1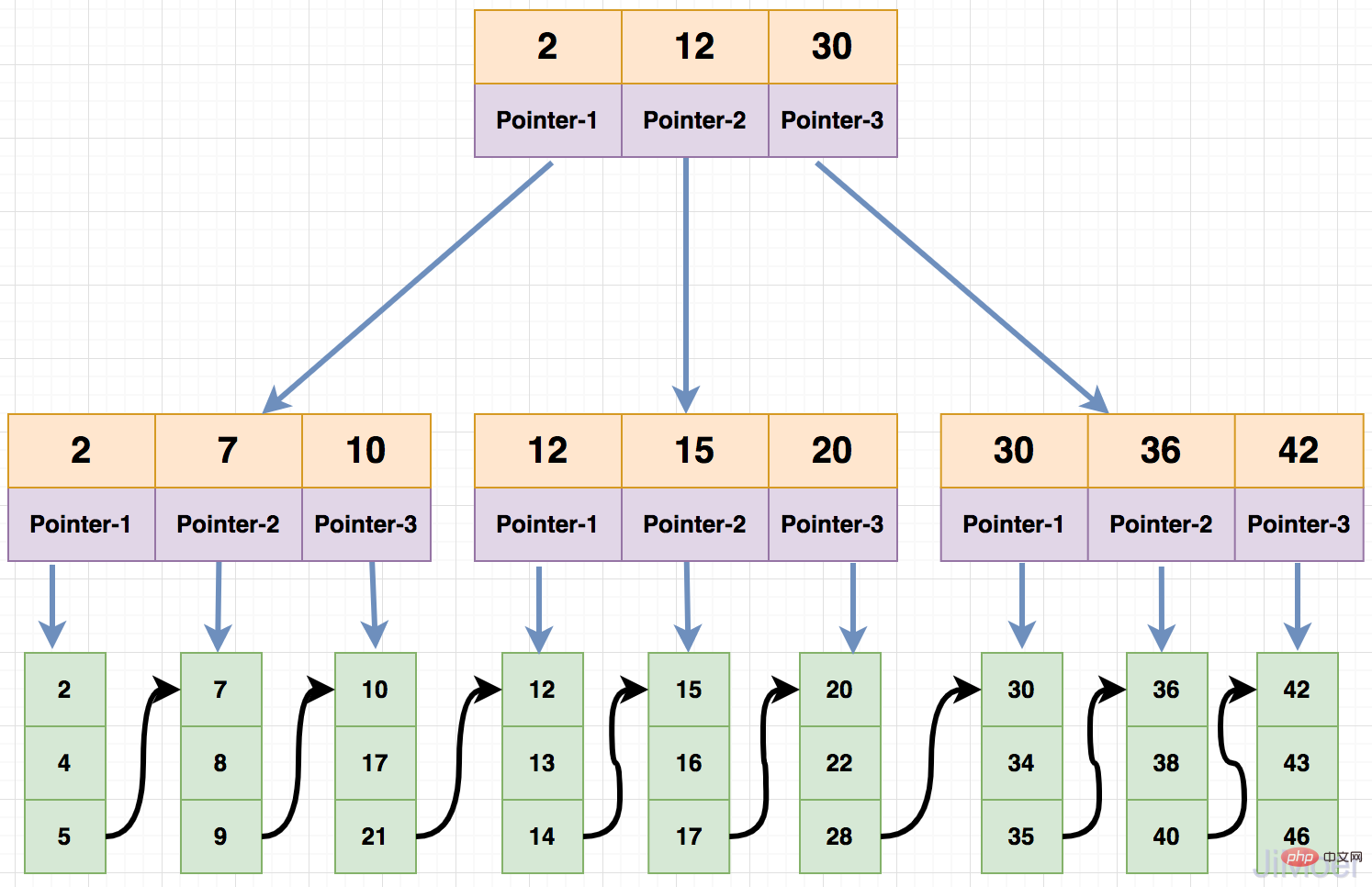 Dann werfen wir einen Blick darauf B – So sucht Tree nach Daten
Dann werfen wir einen Blick darauf B – So sucht Tree nach Daten
:
(16*1000) / (4+8+4)=1000 Jeder Knoten kann bis zu 1000 Schlüsselwörter speichern und jeder Knoten kann bis zu 1001 Zweigknoten haben. 🎜🎜Auf diese Weise kann bei der Abfrage von Indexdaten eine Festplatten-E/A-Operation 1000 Schlüsselwörter zur Berechnung in den Speicher einlesen. Eine Festplatten-E/A-Operation von B-Tree wird durch N Festplatten-E/A-Operationen zum Ausgleichen von Binärdaten gekrönt. 🎜🎜🎜Es ist zu beachten, dass🎜: 🎜B-Tree führt eine Reihe von Vorgängen durch, um das Gleichgewicht der Daten sicherzustellen. Dieser Prozess zur Aufrechterhaltung des Gleichgewichts ist zeitaufwändig, daher ist dies bei der Erstellung des Index der Fall , müssen Sie geeignete Felder auswählen und nicht zu viele Indizes erstellen. Wenn Sie zu viele Indizes erstellen, ist die Aktualisierung des Index bei der Aktualisierung von Daten zeitaufwändiger. 🎜🎜🎜Außerdem 🎜Wählen Sie keine Feldwerte mit geringer Diskriminierung als Indizes, wie z. B. das Geschlechtsfeld, das insgesamt nur zwei Werte hat. Dies kann dazu führen, dass die Tiefe des B-Baums zu groß wird und die Indizierungseffizienz nimmt ab. 🎜🎜🎜🎜B+Tree🎜🎜🎜B-Tree hat das Problem ausgeglichener Binärbäume sehr gut gelöst und kann auch die Abfrageeffizienz gewährleisten. Warum gibt es also B+Tree? 🎜🎜Sehen wir uns zunächst an, wie B+Tree aussieht. 🎜🎜B+Tree ist eine Variante von B-Tree. Die Formelbeziehung zwischen jedem Knotenschlüsselwort und der m-Reihenfolge von B+Tree unterscheidet sich von der von B-Tree. 🎜🎜Erstens beträgt das Verhältnis der Anzahl der untergeordneten Knoten jedes Knotens zu den Schlüsselwörtern, die in jedem Knoten gespeichert werden können, 1:1. Zweitens beträgt das linke geschlossene Intervall beim Abfragen von Daten Wird für die Abfrage verwendet und es gibt keine Daten im Zweigknoten. Es werden nur die Schlüsselwörter und untergeordneten Knotenpunkte gespeichert, und die Daten werden in den Blattknoten gespeichert. 🎜🎜🎜 Dann schauen wir uns an, wie man eine Datenabfrage in B+Tree durchführt. 🎜🎜Zum Beispiel: 🎜- Wenn wir nun die Daten mit id=2 abfragen möchten, nehmen wir zuerst den Wurzelknoten heraus und laden ihn in den Speicher. Wir werden feststellen, dass
id=2im Wurzelknoten vorhanden ist. Da die Daten im linken geschlossenen Intervall gespeichert werden, befinden sich id alle auf dem ersten untergeordneten Knoten des Wurzelknotens;
id=2存在于根节点,因为是左闭合区间存储数据,所以id的都在根节点的第一个子节点上;<li>那么取出第一个子节点,加载到内存中,发现当前节点存在<code>id=2的关键字,并且已经到了叶子节点了,那么直接取出叶子节点中的数据返回。
现在来看一下B-Tree和B+Tree的区别
- B+Tree的查询采用的左闭合区间,这样能更好的支持了自增索引的查询效果,所以一般在创建主键的时候通常都是自增的。这一点和B-Tree是不一样的。
- B+Tree中的根节点和分支节点上是不保存数据的,关键字相关的数据只保存在叶子节点上,这样保证了查询效果的稳定,任何查询都要走到叶子节点才能获取数据。而B-Tree在分支节点中保存了数据,若是命中关键字则直接返回数据。
- B+Tree的叶子节点是顺序排列的,并且相邻的两个叶子节点中具有顺序引用的关系,这样能更好的支持了范围查询。而B-Tree是没有这个顺序关系的。
MySQL的索引为什么选择了B+Tree
经过上面的层层分析,现在我们可以总结一下MySQL为什么选择了B+Tree作为它索引的数据结构呢。
首先和平衡InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM相比,B+Tree的深度更低,节点保存关键字更多,磁盘IO次数更少,查询计算效率更好。
B+Tree的全局扫描能力更强,若是想根据索引数据对数据表进行全局扫描,B-Tree会将整棵树进行扫描,然后逐层遍历。而B+Tree呢,只需要遍历叶子节点即可,因为叶子节点之间存在顺序引用的关系。
B+Tree的磁盘IO读写能力更强,因为B+Tree的每个分支节点上只保存了关键字,这样每次磁盘IO在读写的时候,一页16K数据量可以存储更多的关键字了,每个节点上保存的关键字也比B-Tree更多了。这样B+Tree的一次磁盘IO加载的数据比B-Tree的多很多了。
B+Tree数据结构中有天然的排序能力,比其他数据结构排序能力更强而且排序时,是通过分支节点来进行的,若是需要将分支节点加载到内存中排序,一次加载的数据更多。
B+Tree的查询效果更稳定,因为所有的查询都是需要扫描到叶子节点才将数据返回的。效果只是稳定而不一定是最优,若是直接查询B-Tree的根节点数据,那么B-Tree只需要一次磁盘IO就可以直接将数据返回,反而是效果最优。
经过以上几点的分析,MySQL最终选择了B+Tree作为了它的索引的数据结构。
InnDB的数据存储文件和MyISAM的有何不同?
上面总结了MySQL的索引的数据结构,这次就可以说第二个问题了,因为这个问题其实和MySQL的索引还是有一定的关系的。
下面来看一下,先找到服务器桑MySQL存储数据的目录:
登录MySQL,打开MySQL的命令行界面:输入show variables like '%datadir%';,就能看到存储数据的目录了。
我的服务器中MySQL的存储数据的目录是在:
/var/lib/mysql/
进入到这个目录里后,能看到所有数据库的目录,新建一个study_test的数据库。
然后就进入
/var/lib/mysql/study_test
这个目录下,目前就只有一个文件,这个文件是用来记录创建数据库时配置的字符集的内容。
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt
现在新建两个表,第一个表的引擎类型选择InnoDB,第二个表的引擎类型选择MyISAM。
student_innodb:
CREATE TABLE `student_innodb` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='innodb引擎表';
student_myisam:
CREATE TABLE `student_myisam` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='myISAM引擎类型表';
将两个表创建完成后,我们再进入到/var/lib/mysql/study_testNehmen Sie dann den ersten untergeordneten Knoten heraus und laden Sie ihn hinein Überprüfen Sie den Speicher und stellen Sie fest, dass der aktuelle Knoten das Schlüsselwort id= 2 hat und den Blattknoten erreicht hat. Rufen Sie dann die Daten im Blattknoten direkt ab und geben Sie sie zurück.
Die Abfrage von B+Tree verwendet das linke geschlossene Intervall, was besser sein kann Es unterstützt den Abfrageeffekt der automatischen Inkrementierung des Index, sodass beim Erstellen des Primärschlüssels normalerweise eine automatische Inkrementierung erfolgt. Dies unterscheidet sich von B-Tree.
Auf dem Wurzelknoten und den Zweigknoten werden nur auf den Blattknoten Daten gespeichert Die Abfrage muss zum Blattknoten gehen, um Daten zu erhalten. B-Tree speichert Daten in Verzweigungsknoten und wenn das Schlüsselwort getroffen wird, werden die Daten direkt zurückgegeben. 🎜Die Blattknoten von B+Tree sind sequentiell angeordnet, und die beiden benachbarten Blattknoten haben eine sequentielle Referenzbeziehung, die Bereichsabfragen besser unterstützen kann. B-Tree hat diese Bestellbeziehung nicht.Warum hat MySQL B+Tree als Index ausgewählt?
🎜Nach der obigen Analyseebene können wir nun zusammenfassen, warum MySQL B+Tree als Index ausgewählt hat Index. Wie sieht es mit der Datenstruktur des Index aus? 🎜- 🎜🎜Erstens hat B+Tree im Vergleich zu ausgeglichenen Binärbäumen eine geringere Tiefe, mehr Knoten speichern Schlüsselwörter, weniger Festplatten-E/A-Zeiten und eine bessere Abfrageberechnungseffizienz. 🎜🎜🎜B+Tree verfügt über stärkere globale Scanfunktionen. Wenn Sie die Datentabelle basierend auf Indexdaten global scannen möchten, scannt B-Tree den gesamten Baum und dann schichtweise Schichtdurchquerung. Bei B+Tree müssen Sie nur die Blattknoten durchlaufen, da zwischen den Blattknoten eine sequentielle Referenzbeziehung besteht. 🎜🎜🎜Die Festplatten-IO-Lese- und Schreibfunktionen von B+Tree sind stärker, da auf jedem Zweigknoten von B+Tree nur Schlüsselwörter gespeichert werden, sodass jedes Mal Festplatten-IO gelesen und geschrieben wird Zu diesem Zeitpunkt konnte eine Seite mit 16 KB Daten mehr Schlüsselwörter speichern, und jeder Knoten konnte mehr Schlüsselwörter speichern als B-Tree. Auf diese Weise lädt B+Tree viel mehr Daten in einem Festplatten-IO als B-Tree. 🎜🎜🎜Die B+Tree-Datenstruktur verfügt über eine natürliche Sortierfähigkeit, die stärker ist als andere Datenstrukturen. Die Sortierung erfolgt über Verzweigungsknoten sortiert in den Speicher geladen, wobei mehr Daten gleichzeitig geladen werden. 🎜🎜🎜Der Abfrageeffekt von B+Tree ist stabiler, da alle Abfragen die Blattknoten scannen müssen, bevor die Daten zurückgegeben werden. Der Effekt ist nur stabil, aber nicht unbedingt optimal. Wenn die Stammknotendaten von B-Tree direkt abgefragt werden, kann B-Tree die Daten mit nur einem Festplatten-IO direkt zurückgeben, aber der Effekt ist optimal. 🎜
Schauen wir uns zunächst das Verzeichnis an, in dem der MySQL-Server Daten speichert:
Melden Sie sich bei MySQL an und öffnen Sie die MySQL-Befehlszeilenschnittstelle: Geben Sie
show variables like '%datadir%'; können Sie das Verzeichnis sehen, in dem die Daten gespeichert sind. <br> Das Verzeichnis, in dem MySQL Daten auf meinem Server speichert, ist: 🎜<pre class="brush:php;toolbar:false">-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt-rw-r----- 1 mysql mysql 8650 1月 31 10:41 student_innodb.frm-rw-r----- 1 mysql mysql 114688 1月 31 10:41 student_innodb.ibd-rw-r----- 1 mysql mysql 8650 1月 31 10:58 student_myisam.frm-rw-r----- 1 mysql mysql 0 1月 31 10:58 student_myisam.MYD-rw-r----- 1 mysql mysql 1024 1月 31 10:58 student_myisam.MYI</pre>🎜Nachdem Sie dieses Verzeichnis eingegeben haben, können Sie die Verzeichnisse aller Datenbanken sehen und eine neue Datenbank mit <code>study_test erstellen. Geben Sie dann das Verzeichnis 🎜rrreee🎜 ein. Derzeit wird nur eine Datei verwendet, um den Inhalt des beim Erstellen der Datenbank konfigurierten Zeichensatzes aufzuzeichnen. 🎜rrreee🎜Erstellen Sie nun zwei neue Tabellen, wählen Sie InnoDB als Engine-Typ der ersten Tabelle und MyISAM als Engine-Typ der zweiten Tabelle aus. 🎜🎜student_innodb: 🎜rrreee🎜student_myisam: 🎜rrreee🎜Nachdem wir die beiden Tabellen erstellt haben, geben wir dann
/var/lib/mysql/study_test ein Werfen Sie einen Blick darauf: 🎜rrreee🎜 Durch die Dateien im Verzeichnis können Sie sehen, dass nach dem Erstellen der Tabelle noch mehrere Dateien vorhanden sind. Dies zeigt auch die Dateiunterschiede zwischen der InnoDB-Engine-Typentabelle und der MyISAM-Engine-Typentabelle. 🎜🎜Jede dieser Dateien hat ihre eigene Rolle: 🎜<ul>
<li>Es gibt zwei Tabellendateien in der InnoDB-Engine: <ul>
<li>*.frm Dieser Dateityp ist die Definitionsdatei der Tabelle. </li>
<li>*.ibd Bei diesem Dateityp handelt es sich um eine Daten- und Indexspeicherdatei. Tabellendaten und Indizes werden aggregiert und gespeichert, und die Daten können direkt über den Index abgefragt werden. </li>
</ul>
</li>
<li>Es gibt drei Tabellendateien in der MyIASM-Engine: <ul>
<li>*.frm Dieser Dateityp ist die Definitionsdatei der Tabelle. </li>
<li>*.MYD Bei diesem Dateityp handelt es sich um eine Tabellendatendatei, und alle Daten in der Tabelle werden in dieser Datei gespeichert. </li>
<li>*.MYI Dieser Dateityp ist die Indexdatei der Tabelle, und die Indexdaten der MyISAM-Speicher-Engine werden separat gespeichert. </li>
</ul>
</li>
</ul>
<p><strong>MyISAM-Datenspeicher-Engine, Index und Datenspeicherstruktur</strong></p>
<p>MyISAM-Speicher-Engine speichert die Indexdaten beim Speichern des Index separat, und der B+Baum des Index zeigt letztendlich auf den physischen Ort, an dem die Daten vorhanden sind Adresse, keine konkreten Daten. Suchen Sie dann die spezifischen Daten in der Datendatei (*.MYD) entsprechend der physischen Adresse. </p>
<p>Wie in der folgenden Abbildung dargestellt: <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/26588e767b94b5a39e8f185e76cae063-6.png" class="lazy" alt="InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM"><br> Wenn dann mehrere Indizes vorhanden sind, verweisen mehrere Indizes auf dieselbe physische Adresse. <br> Wie in der folgenden Abbildung gezeigt: <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/26588e767b94b5a39e8f185e76cae063-7.png" class="lazy" alt="InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM"><br> Durch diese Struktur können wir sehen, dass sich die Indizes der Speicher-Engine von MyISAM alle auf derselben Ebene befinden und die Indexstrukturen und Abfragemethoden für Primärschlüssel und Nicht-Primärschlüssel genau gleich sind . </p>
<p><strong>InnoDB-Datenspeicher-Engine, Index und Datenspeicherstruktur</strong></p>
<p>Zunächst ist der InnoDB-Index in einen Clustered-Index und einen Nicht-Clustered-Index unterteilt. In jedem B+Tree werden Schlüsselwörter gespeichert Zweigknoten und Daten werden auf Blattknoten gespeichert. <br> „<strong>Clustering</strong>“ bedeutet, dass die Datenzeilen nacheinander in einer bestimmten Reihenfolge dicht beieinander gespeichert werden. Eine Tabelle kann nur einen Clustered-Index haben, da es nur eine Möglichkeit gibt, Daten in einer Tabelle zu speichern. Im Allgemeinen wird der Primärschlüssel als Clustered-Index verwendet. Wenn kein Primärschlüssel vorhanden ist, generiert InnoDB eine ausgeblendete Spalte als Primäre Schlüssel standardmäßig. </p>
<p>Wie in der folgenden Abbildung gezeigt: <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/27f866e22cb81ea08dc42142d3144f58-8.png" class="lazy" alt="InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM"><br> Nicht gruppierter Index, auch Sekundärindex genannt. Obwohl Schlüsselwörter auch auf jedem Zweigknoten von B + Baum gespeichert werden, handelt es sich bei den Blattknoten nicht um gespeicherte Daten, sondern um Primärschlüsselwerte. Beim Abfragen von Daten über den Sekundärindex wird zunächst der den Daten entsprechende Primärschlüssel abgefragt und dann die spezifische Datenzeile basierend auf dem Primärschlüssel abgefragt. </p>
<p>Wie in der folgenden Abbildung dargestellt: <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/15fa41611b09e0b7309f0c140547ed0f-9.png" class="lazy" alt="InnoDB-Datenspeicherdateien unterscheiden sich von MyISAM"><br> Aufgrund der Designstruktur des nicht gruppierten Index muss der nicht gruppierte Index beim Abfragen zweimal indiziert werden. Der Vorteil dieses Designs kann sicherstellen, dass die Datenmigration einmal erfolgt Zu diesem Zeitpunkt muss nur der Primärschlüsselindex aktualisiert werden und der nicht gruppierte Index muss nicht berührt werden. Außerdem wird das Problem der Speicherung physischer Adressen wie MyISAM-Indizes und der Notwendigkeit, alle Indizes während der Datenmigration neu zu verwalten, vermieden. </p>
<p><strong>Zusammenfassung</strong></p>
<p>Dieses Mal habe ich die Datenstruktur des MySQL-Index und die Dateispeicherstruktur klar zusammengefasst. Später im eigentlichen Arbeitsprozess kann ich beim Entwerfen des Index auch die Datenstruktur umfassender berücksichtigen ermöglicht Ihnen zu überlegen, welche Situationen indiziert werden sollten und welche nicht, wenn Sie tatsächlich SQL schreiben. </p>
<ul>
<li>MySQL verwendet B+Tree als Datenstruktur des Index, da die Tiefe von B+Tree gering ist, die Knoten mehr Schlüsselwörter speichern und die Anzahl der Festplatten-E/As geringer ist, wodurch eine höhere Abfrageeffizienz gewährleistet wird. </li>
<li>B+Tree kann sicherstellen, dass der Abfrageeffekt von MySQL stabil ist, unabhängig davon, ob es sich um einen Primärschlüsselindex oder einen Nicht-Primärschlüsselindex handelt. Der Blattknoten muss jedes Mal abgefragt werden B+Tree ist dasselbe, und um die automatische Inkrementierung von Primärschlüsseln besser zu unterstützen, ist der Abfrageknotenbereich von B+Tree links geschlossen und rechts offen. </li>
<li>MyISAM-Speicher-Engine von MySQL, <strong>Tabellendaten</strong> und <strong>Indexdaten</strong> werden jeweils in zwei Dateien gespeichert, da der B+Tree-Blattknoten seines eigenen Index auf die Festplattenadresse der Tabellendaten zeigt nicht in Primärschlüssel und Nicht-Primärschlüssel unterteilt, daher wird er separat gespeichert, um den Index besser einheitlich verwalten zu können. </li>
<li>MySQLs InnoDB-Speicher-Engine, <strong>Tabellendaten</strong> und <strong>Indexdaten</strong> werden in einer Datei gespeichert, da InnoDBs Der Blattknoten des Clustered-Index zeigt auf die spezifische Datenzeile. Um die Stabilität des Abfrageeffekts sicherzustellen, muss die InnoDB-Tabelle über einen Clustered-Index verfügen. Beim Abrufen des Index ruft der Sekundärindex die Daten zuerst ab Index Der Primärschlüsselwert und ruft dann basierend auf dem Primärschlüssel bestimmte Daten aus dem Clustered-Index ab. </li>
</ul>
<blockquote><p><strong>Verwandte kostenlose Lernempfehlungen: </strong><a href="https://www.php.cn/course/list/51.html" target="_blank"><strong>MySQL-Video-Tutorial</strong></a></p></blockquote>Das obige ist der detaillierte Inhalt vonInnoDB-Datenspeicherdateien unterscheiden sich von MyISAM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Zusammenfassung der häufigen MySQL-Fehleranalyse und -Lösungen
- Beherrschen Sie MYSQL Advanced
- Über Laravel, das das MySQL-only_full_group_by-Problem löst
- So konvertieren Sie Nulldaten in MySQL
- Python realisiert das Crawlen von Weibo-Hot-Suchen und das Speichern dieser in MySQL
- Vorstellung der MySQL-Lösung zur Optimierung großer Tabellen