
Heim >Backend-Entwicklung >Python-Tutorial >Python realisiert das Crawlen von Weibo-Hot-Suchen und das Speichern dieser in MySQL
Python realisiert das Crawlen von Weibo-Hot-Suchen und das Speichern dieser in MySQL

- coldplay.xixinach vorne
- 2021-01-27 17:45:132403Durchsuche

Kostenlose Lernempfehlung: Python-Video-Tutorial
Python crawlt Weibo-Hot-Suchen und speichert sie in MySQL
Zielanalyse- Eins: Holen Sie sich die Daten
- Zweitens: Link zur Datenbank
- Gesamtcode
- Der endgültige Effekt
- Nicht viel Unsinn, gehen Sie einfach zum Bild
Lassen Sie uns analysieren, wie die Implementierung erfolgt
die verwendete Bibliothekimport requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd
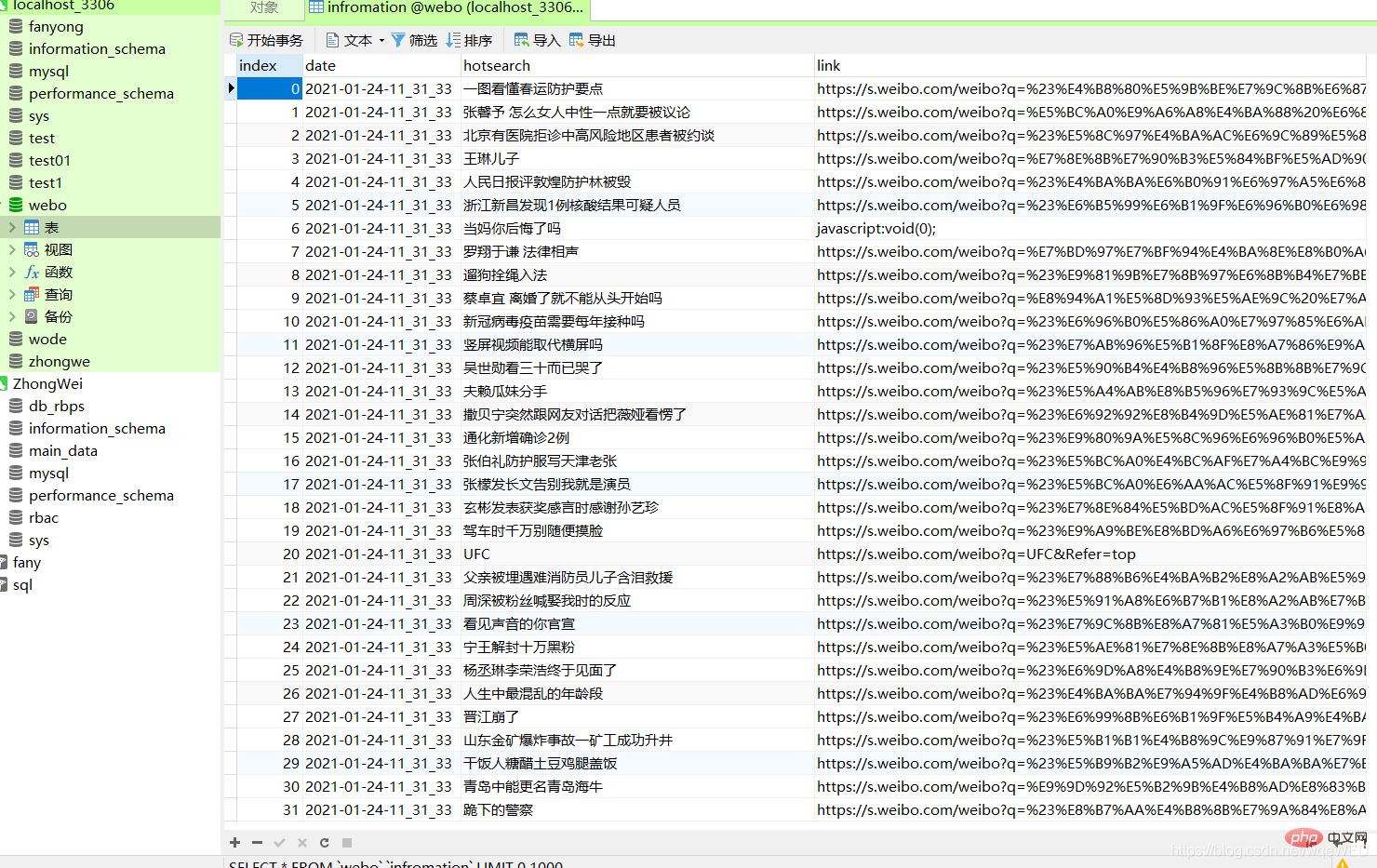
Zielanalyse
Dies ist ein heiß gesuchter Link auf Weibo: Klicken Sie auf mich, um zur Zielseite zu gelangen
Zuerst wir Verwenden Sie Selenium, um die Zielwebseite eine Anfrage zu stellenDann verwenden wir XPath, um die Webseitenelemente zu lokalisieren, durchlaufen sie, um alle Daten zu erhalten Dann verwenden wir Pandas, um ein Dataframe-Objekt zu generieren und es direkt in der Datenbank zu speichern
1: Holen Sie sich die Daten 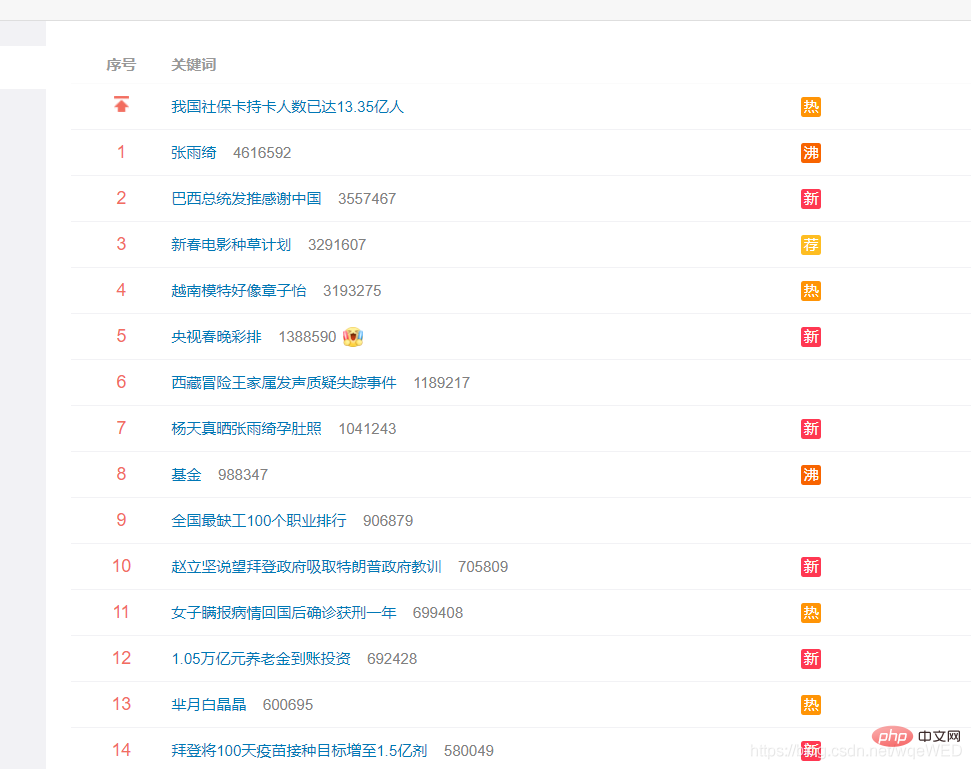
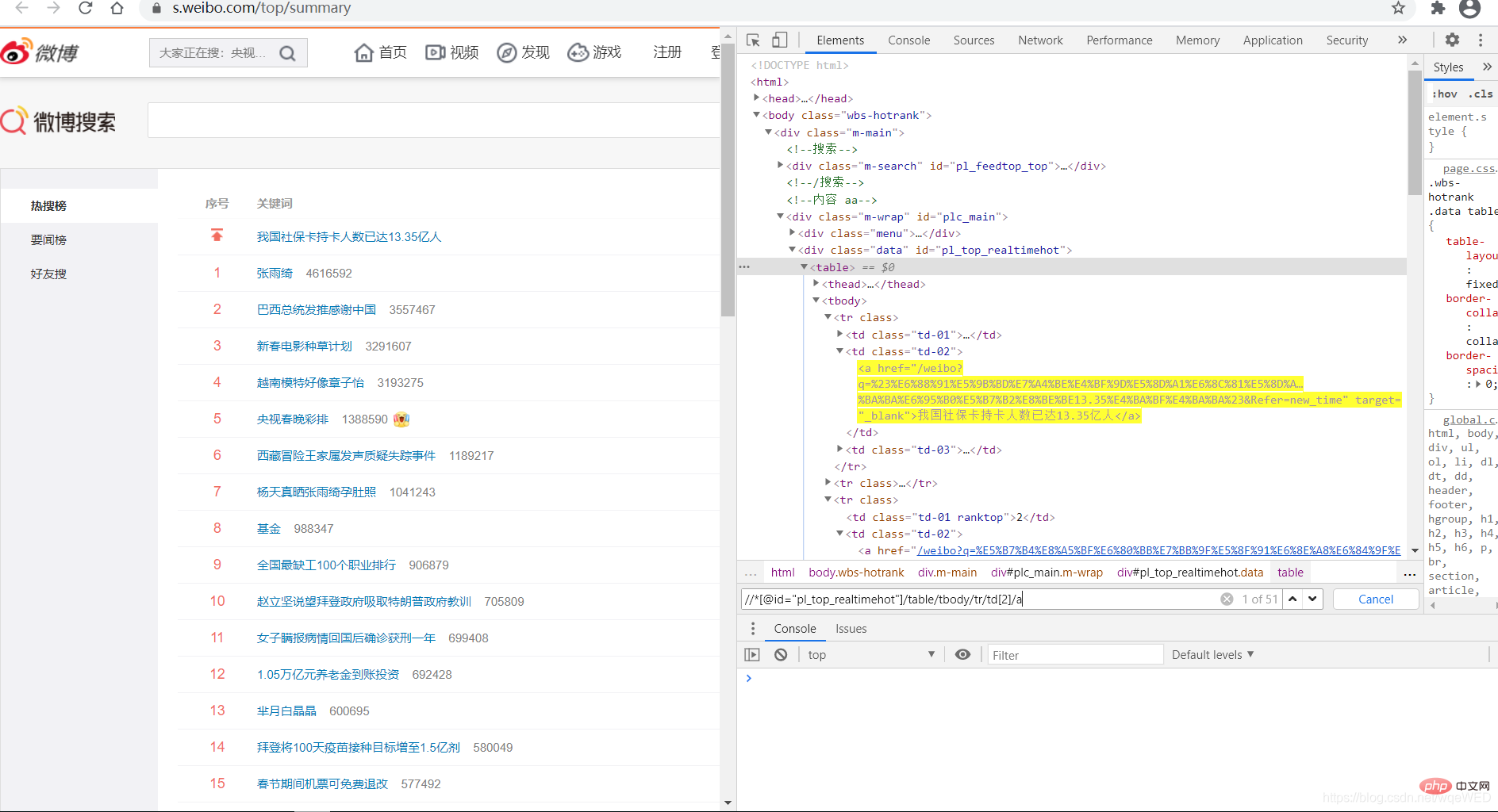
Wir sehen, dass mit xpath 51 Datenelemente abgerufen werden können, das sind die Hot-Suchen, aus denen wir den Link- und Titelinhalt abrufen können
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据
context = [i.text for i in c] # 得到标题内容
links = [i.get_attribute('href') for i in c] # 得到link
Dann verwenden wir die Zip-Funktion, um Datum und Kontext zusammenzuführen , und Links Die Zip-Funktion kombiniert mehrere Listen zu einer Liste und führt die Daten der geteilten Liste nach Index zu einem Tupel zusammen, wodurch Pandas-Objekte erzeugt werden können.
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])Das Datum kann über das Zeitmodul abgerufen werden
Zweitens: Verknüpfen der Datenbank
Das ist sehr einfach
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
Gesamtcodefrom selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
def get_data():
url = r"https://s.weibo.com/top/summary" # 微博的地址
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
browser = Chrome(options=option)
browser.get(url)
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
context = [i.text for i in all]
links = [i.get_attribute('href') for i in all]
date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime())
dates = []
for i in range(len(context)):
dates.append(date)
# print(len(dates),len(context),dates,context)
dc = zip(dates, context, links)
pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
# pdf.to_sql(name=in, con=enging, if_exists="append")
return pdf
def w_mysql(pdf):
try:
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
except:
print('出错了')
if __name__ == '__main__':
xx = get_data()
w_mysql(xx)Ich hoffe, es kann allen helfen, lasst uns Fortschritte machen und gemeinsam wachsen !
Verwandte kostenlose Lernempfehlungen:
Python-Tutorial
(Video)
Das obige ist der detaillierte Inhalt vonPython realisiert das Crawlen von Weibo-Hot-Suchen und das Speichern dieser in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Führen Sie die Schritte zum Erstellen einer Python + Selenium-Automatisierungsumgebung aus
- Codebeispiele für Python und Selenium zur Verarbeitung von Browserfenstern
- Web-Automatisierungstests (1) Problemsatz für die Selenium 3-Nutzungsserie
- Webautomatisiertes Testen (3) Selenium+beatuifulsoup
- Selenium+PhantomJs analysiert und rendert grundlegende Operationen von Js