
Vorstellung der MySQL-Lösung zur Optimierung großer Tabellen

- coldplay.xixinach vorne
- 2021-01-28 09:28:001766Durchsuche

Kostenlose Lernempfehlung: MySQL-Datenbank (Video)
Hintergrund
Alibaba Cloud RDS FÜR MySQL (MySQL Version 5. 7) Datenbank-Geschäftstabellen werden jeden Monat hinzugefügt Da die Datenmenge weiterhin zunimmt, kommt es in unserem Unternehmen zu langsamen Abfragen in großen Tabellen. In Spitzenzeiten dauern langsame Abfragen in der Hauptgeschäftstabelle Dutzende von Sekunden, was erhebliche Auswirkungen auf das Geschäft hat Überblick über die Lösung
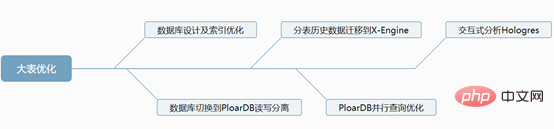 1. Datenbankdesign und Indexoptimierung
1. Datenbankdesign und Indexoptimierung
Die MySQL-Datenbank selbst ist sehr flexibel, was zu einer unzureichenden Leistung führt und stark von den Tabellendesignfunktionen und Indexoptimierungsfunktionen des Entwicklers abhängig ist. Hier sind einige Optimierungsvorschläge
Konvertieren Sie den Zeittyp in das Zeitstempelformat, verwenden Sie den Typ int zum Speichern und Erstellen des Index, um die Abfrageeffizienz zu erhöhen
- Es wird empfohlen, dass die Felddefinition nicht null ist. Ein Nullwert ist schwierig für die Abfrageoptimierung und nimmt zusätzlichen Indexplatz ein
- Verwenden Sie den Typ TINYINT anstelle der Aufzählung ENUM.
- Das Speichern präziser Gleitkommazahlen muss durch DECIMAL FLOAT und DOUBLE ersetzt werden.
- Die Feldlänge richtet sich ausschließlich nach den Geschäftsanforderungen. Stellen Sie sie nicht zu groß ein. Versuchen Sie, TEXT nicht zu verwenden Wenn Sie es verwenden müssen, wird empfohlen, die selten verwendeten großen Felder in andere Tabellen aufzuteilen. MySQL hat Einschränkungen hinsichtlich der Länge der Indexfelder. Ja, die Länge jeder Indexspalte der Innodb-Engine ist auf 767 Bytes begrenzt Standardmäßig darf die Summe der Längen aller Indexspalten nicht größer als 3072 Byte sein (ein einzelner MySQL 8.0-Index kann 1024 Zeichen erstellen).
- Für große Tabellen gelten DDL-Anforderungen. Bitte wenden Sie sich an den DBA
- Wie der Name schon sagt, bedeutet dies die Priorität ganz links. Bei der Erstellung eines kombinierten Index wird die am häufigsten verwendete Spalte in der Where-Klausel ganz links platziert. Ein sehr wichtiges Thema in einem zusammengesetzten Index ist die Reihenfolge der Spalten. Wenn beispielsweise die beiden Felder c1 und c2 nach „wo“ verwendet werden, ist die Reihenfolge des Index (c1, c2) oder (c2, c1). Der richtige Ansatz ist: Je kleiner der Wert, desto höher ist er. Wenn beispielsweise 95 % der Werte in einer Spalte nicht wiederholt werden, kann diese Spalte im Allgemeinen an den Anfang gestellt werden. a, b, c)
- wobei a=3 verwendet wird, wird nur a
- wobei a=3 und b=5 a,b verwendet
- wobei a=3 und b=5 und c=4 a,b,c verwendet werden
- wobei a= 3 und b wie 'xx%' und c= 7 Die Verwendung von a, b
- entspricht tatsächlich der Erstellung mehrerer Indizes: key(a), key(a,b), key(a,b,c)
- 2. Stellen Sie die Datenbank auf die Lese-/Schreibtrennung von PloarDB um.
- PolarDB ist eine von Alibaba Cloud selbst entwickelte relationale Cloud-Datenbank. Sie ist zu 100 % kompatibel mit MySQL und verfügt über eine Speicherkapazität von bis zu 100 TB Die Datenbank kann auf bis zu 16 Knoten erweitert werden. Sie eignet sich für verschiedene Datenbankanwendungsszenarien von Unternehmen. PolarDB verwendet eine Architektur, die Speicher und Datenverarbeitung trennt und eine Kopie der Daten gemeinsam nutzt und Konfigurations-Upgrades und -Downgrades auf Minutenebene, Fehlerwiederherstellung auf zweiter Ebene, globale Datenkonsistenz sowie kostenlose Datensicherungs- und Notfallwiederherstellungsdienste bietet.
- Cluster-Architektur, Trennung von Rechenleistung und Speicherung PolarDB verwendet eine Multi-Knoten-Cluster-Architektur. Es gibt einen Writer-Knoten (Master-Knoten) und mehrere Reader-Knoten (schreibgeschützte Knoten) im Cluster System (PolarFileSystem) Gemeinsamer zugrunde liegender Speicher (PolarStore)
- Trennung von Lesen und Schreiben
- Wenn eine Anwendung eine Clusteradresse verwendet, stellt PolarDB externe Dienste über die interne Proxy-Schicht (Proxy) bereit. Die Anforderungen der Anwendung durchlaufen zunächst den Proxy, bevor sie auf die zugreifen Datenbankknoten. Die Proxy-Schicht kann nicht nur Sicherheitsauthentifizierung und -schutz durchführen, sondern auch SQL analysieren, Schreibvorgänge (z. B. Transaktionen, UPDATE, INSERT, DELETE, DDL usw.) an den Masterknoten senden und Lesevorgänge (z. B. SELECT) gleichmäßig verteilen ) an mehrere Knoten Leseknoten realisieren eine automatische Lese- und Schreibtrennung. Für Anwendungen ist es so einfach wie die Verwendung eines einzigen Datenbankpunkts.
In gemischten Offline-Szenarien: Verschiedene Dienste verwenden unterschiedliche Verbindungsadressen und verwenden unterschiedliche Datenknoten, um gegenseitige Beeinflussung zu vermeiden
PloarDB 8-Core 32G 2 EinheitenDie geteilte Geschäftstabelle speichert 3 Monate an Daten (dies basiert auf den Unternehmensanforderungen) und historische Daten werden monatlich in historische Datenbank-X-Engine-Speicher-Engine-Tabellen aufgeteilt. Warum sollten wir uns für X-Engine-Speicher-Engine-Tabellen entscheiden? sind seine Vorteile?
- Kostenersparnis, die Speicherkosten von X-Engine sind etwa halb so hoch wie die von InnoDB
- X-Engine Tiered Storage verbessert QPS, übernimmt eine hierarchische Speicherstruktur, speichert Hot- und Cold-Daten auf verschiedenen Ebenen und Standardmäßig wird der Grad kalter Daten komprimiert.
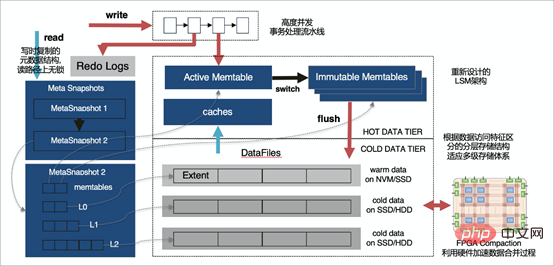
Die X-Engine-Speicher-Engine ist nicht nur nahtlos mit MySQL kompatibel (dank der MySQL Pluginable Storage Engine-Funktion), sondern X-Engine verwendet auch eine mehrschichtige Speicherarchitektur. Da das Ziel darin besteht, umfangreiche Datenmengen zu speichern, eine hohe Fähigkeit zur gleichzeitigen Transaktionsverarbeitung bereitzustellen und die Speicherkosten zu senken, sind in den meisten Szenarien mit großem Datenvolumen die Möglichkeiten für den Datenzugriff ungleichmäßig, und häufig abgerufene Hot-Daten sind tatsächlich dafür verantwortlich Sehr selten unterteilt X-Engine die Daten entsprechend der Häufigkeit des Datenzugriffs in mehrere Ebenen, entwirft die entsprechende Speicherstruktur und schreibt sie auf das entsprechende Speichergerät
- X- Die Engine verwendet LSM-Tree, dient als architektonische Grundlage für hierarchischen Speicher und wurde neu gestaltet:
- Die Hot-Data-Schicht und Datenaktualisierungen nutzen Speicherspeicher und verbessern die Transaktionsverarbeitungsleistung durch In-Memory-Datenbanktechnologie (Lock-Free-Indexstruktur/Anhängen). nur).
- Der Pipeline-Transaktionsverarbeitungsmechanismus parallelisiert mehrere Phasen der Transaktionsverarbeitung und verbessert so den Durchsatz erheblich.
- Daten mit geringer Zugriffshäufigkeit werden nach und nach eliminiert oder in der persistenten Speicherschicht zusammengeführt und zur Speicherung mit mehrschichtigen Speichergeräten (NVM/SSD/HDD) kombiniert.
- Am Komprimierungsprozess wurden viele Optimierungen vorgenommen, die große Auswirkungen auf die Leistung haben:
- Teilen Sie die Datenspeichergranularität auf, nutzen Sie die Eigenschaften relativ konzentrierter Datenaktualisierungs-Hotspots und verwenden Sie Daten bei der Zusammenführung so weit wie möglich wieder Verfahren.
- Kontrollieren Sie die Form von LSM genau, reduzieren Sie die E/A- und Rechenkosten und verringern Sie effektiv die Platzvergrößerung während des Fusionsprozesses.
- Verwendet außerdem detailliertere Zugriffskontroll- und Caching-Mechanismen, um die Leseleistung zu optimieren.
4. Parallele Abfrage der Alibaba Cloud PloarDB MySQL8.0-Version
Nach der Aufteilung der Tabellen ist unser Datenvolumen immer noch sehr groß, was unser langsames Abfrageproblem nicht vollständig löst, sondern nur die Größe verringert unserer Geschäftstabellen Für diesen Teil der langsamen Abfrage müssen wir die parallele Abfrageoptimierung von PolarDB verwenden.
PolarDB MySQL 8.0 startet das parallele Abfrage-Framework automatisch gestartet, wodurch die Abfrage zeitaufwändig wird.
In der Speicherschicht werden die Daten in mehrere Threads fragmentiert und die Ergebnispipeline wird im Hauptthread zusammengefasst Einfache Zusammenführung und Rückgabe an den Benutzer, um die Abfrageeffizienz zu verbessern.
Parallel Query nutzt die Parallelverarbeitungsfähigkeiten von Multi-Core-CPUs. Am Beispiel der 8-Core-32-GB-Konfiguration sieht das schematische Diagramm wie folgt aus.
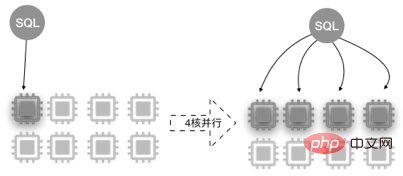
Parallele Abfragen eignen sich für die meisten SELECT-Anweisungen, z. B. große Tabellenabfragen, Verknüpfungsabfragen mit mehreren Tabellen und Abfragen mit großer Berechnungslast. Bei sehr kurzen Abfragen ist der Effekt weniger spürbar.
Parallele Abfragenutzung: Sie können die Hint-Syntax verwenden, um eine einzelne Anweisung zu steuern. Wenn das System beispielsweise parallele Abfragen standardmäßig deaktiviert, Sie aber eine hochfrequente langsame SQL-Abfrage beschleunigen müssen, können Sie Hint zur Beschleunigung verwenden spezifisches SQL erstellen.
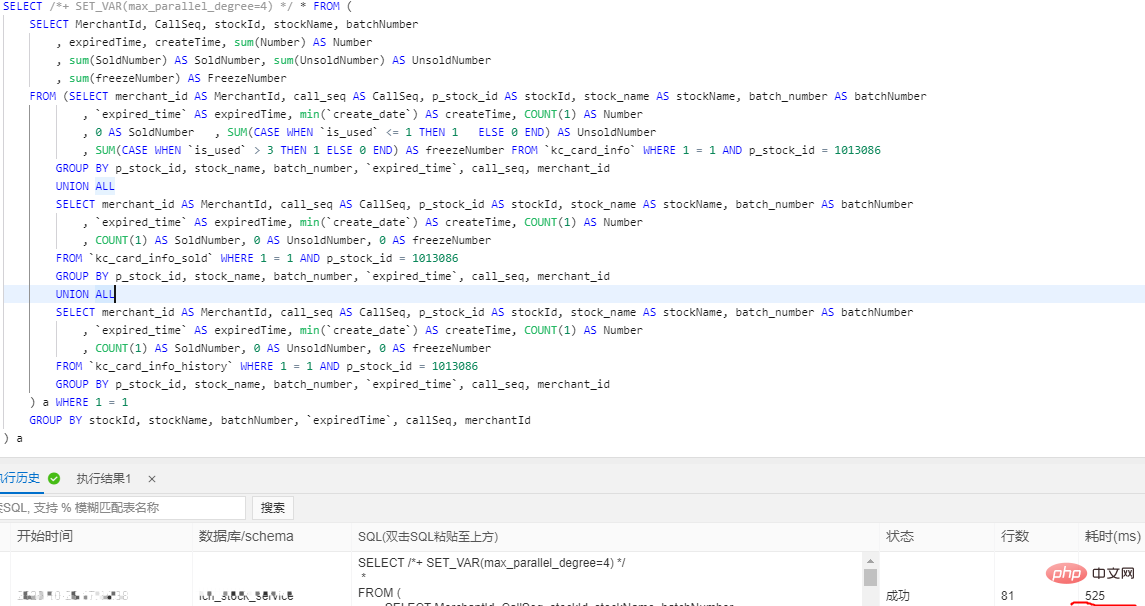
SELECT /+PARALLEL(x)/ … FROM …; – x >0
SELECT /*+ SET_VAR(max_parallel_degree=n) */ * FROM … // n > Bei der Konfiguration von 16 Kernen und 32G übersteigt das Datenvolumen einer einzelnen Tabelle 30 Millionen.
Vor dem Hinzufügen der parallelen Abfrage waren es 4326 ms und nach dem Hinzufügen waren es 525 ms. Die Leistung stieg um das 8,24-fache. 5 .Interaktive Analyse Hologre
Obwohl wir die Effizienz langsamer Abfragen in großen Tabellen mithilfe der parallelen Abfrageoptimierung verbessern, können wir einige spezifische Anforderungen für Echtzeitberichte und Echtzeit-Großbildschirme immer noch nicht erfüllen und können uns nur darauf verlassen Big Data, um sie zu verarbeiten. Hier empfehlen wir die interaktive Analyse Hologre von Alibaba Cloud ( https://help.aliyun.com/product/113622.html)
https://help.aliyun.com/product/113622.html)
6. Postscript
Die Optimierung von zig Millionen großen Tabellen basiert auf Geschäftsszenarien werden auf Kosten der Kosten optimiert. Eine horizontale Aufteilung und Erweiterung der Datenbank ist in vielen Fällen möglicherweise nicht gut Datenbankdesign, Indexoptimierung und Tabellenpartitionierungsstrategien sind Sobald dies erledigt ist, sollten Sie die geeignete Technologie auswählen, um es basierend auf den Geschäftsanforderungen zu implementieren.
Weitere verwandte kostenlose Lernempfehlungen: MySQL-Tutorial(Video)
Das obige ist der detaillierte Inhalt vonVorstellung der MySQL-Lösung zur Optimierung großer Tabellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!