
Heim >Datenbank >MySQL-Tutorial >Verstehen Sie die Paging-Abfrage, nachdem zig Milliarden Daten in Tabellen unterteilt wurden
Verstehen Sie die Paging-Abfrage, nachdem zig Milliarden Daten in Tabellen unterteilt wurden

- coldplay.xixinach vorne
- 2020-11-09 17:24:033085Durchsuche
Die Spalte
MySQL-Video-Tutorial stellt die Paging-Abfrage von zig Milliarden Daten vor.

Wenn die Geschäftsgröße beispielsweise eine bestimmte Größenordnung erreicht, beträgt das tägliche Bestellvolumen von Taobao mehr als 50 Millionen Bestellungen und das tägliche Bestellvolumen von Meituan mehr als 30 Millionen Bestellungen. Wenn die Datenbank einem massiven Datendruck ausgesetzt ist, sind Unterdatenbank- und Tabellenunteroperationen erforderlich. Nachdem die Datenbank in Tabellen unterteilt wurde, können einige reguläre Abfragen Probleme verursachen. Am häufigsten sind Paging-Abfragen. Im Allgemeinen nennen wir die Felder von Sharding-Tabellen Shardingkey. Die Bestelltabelle verwendet beispielsweise die Benutzer-ID als Shardingkey. Wie führt man also Paging durch, wenn die Abfragebedingung keine Benutzer-ID enthält? Wie können beispielsweise mehr mehrdimensionale Abfragen abgefragt werden, wenn kein Sharding-Schlüssel vorhanden ist?
Einzigartiger Primärschlüssel
Im Allgemeinen werden die Primärschlüssel unserer Datenbank automatisch erhöht, sodass das Problem eines Primärschlüsselkonflikts nach der Aufteilung der Tabelle ein unvermeidbares Problem ist. Der einfachste Weg besteht darin, ein eindeutiges Geschäftsfeld als einzigen Primärschlüssel zu verwenden Schlüssel, z. B. order Die Bestellnummer der Tabelle muss global eindeutig sein.
Es gibt viele gängige verteilte Methoden zum Generieren eindeutiger IDs. Die häufigsten sind Snowflake, Didi Tinyid und Meituan Leaf. Am Beispiel des Snowflake-Algorithmus kann eine Millisekunde 4194304mehrere IDs generieren.
Das erste wird nicht verwendet, der Standardwert ist 0, 41-Bit-Zeitstempelauf Millisekunden genau, kann 69 Jahre aufnehmen, 10-stellige Arbeitsmaschinen-IDDie oberen 5 Ziffern sind die Rechenzentrums-ID, die niedrigen 5 Ziffern Ist die Knoten-ID, 12-stellige Seriennummer Jeder Knoten akkumuliert jede Millisekunde, und die Gesamtzahl kann 2^12 4096 IDs erreichen.

Tabelle aufteilen
Der erste Schritt besteht darin, sicherzustellen, dass die Bestellnummer nach der Aufteilung der Tabelle eindeutig ist. Betrachten Sie nun das Problem der Aufteilung der Tabelle. Berücksichtigen Sie zunächst die Größe der Untertabelle basierend auf ihrem eigenen Geschäftsvolumen und Inkrement.
Zum Beispiel beträgt unser tägliches Bestellvolumen jetzt 100.000 Bestellungen, und es wird geschätzt, dass es in einem Jahr 1 Million Bestellungen pro Tag erreichen wird. Je nach Geschäftsmerkmalen unterstützen wir im Allgemeinen die Abfrage von Bestellungen innerhalb eines halben Jahres und Bestellungen, die darüber hinausgehen ein halbes Jahr müssen archiviert werden.
Ausgehend von der Größenordnung von 1 Million Bestellungen pro Tag für ein halbes Jahr und ohne separate Tabellen wird unser Bestellvolumen also 1 Million erreichen. Sie können die Zeit, die für die Beförderung von RT benötigt wird, einfach nicht akzeptieren. Erfahrungsgemäß besteht kein Druck auf die Datenbank, wenn die Anzahl einer einzelnen Tabelle im Millionenbereich liegt, es reicht also aus, sie in 256 Tabellen aufzuteilen, 180 Millionen/256 ≈ 700.000 kann es auch in 512 Tabellen aufteilen. Denken Sie dann darüber nach: Wenn das Geschäftsvolumen um das Zehnfache auf 10 Millionen Bestellungen pro Tag steigt, ist die Untertabelle 1024 die geeignetere Wahl.
Nach der Aufteilung von Tabellen und der Archivierung von Daten über mehr als ein halbes Jahr reichen 700.000 Daten in einer einzigen Tabelle aus, um die meisten Szenarien zu bewältigen. Als nächstes wird die Bestellnummer gehasht und dann das Modulo von 256 verwendet, um zu bestimmen, auf welche Tabelle sie fällt.
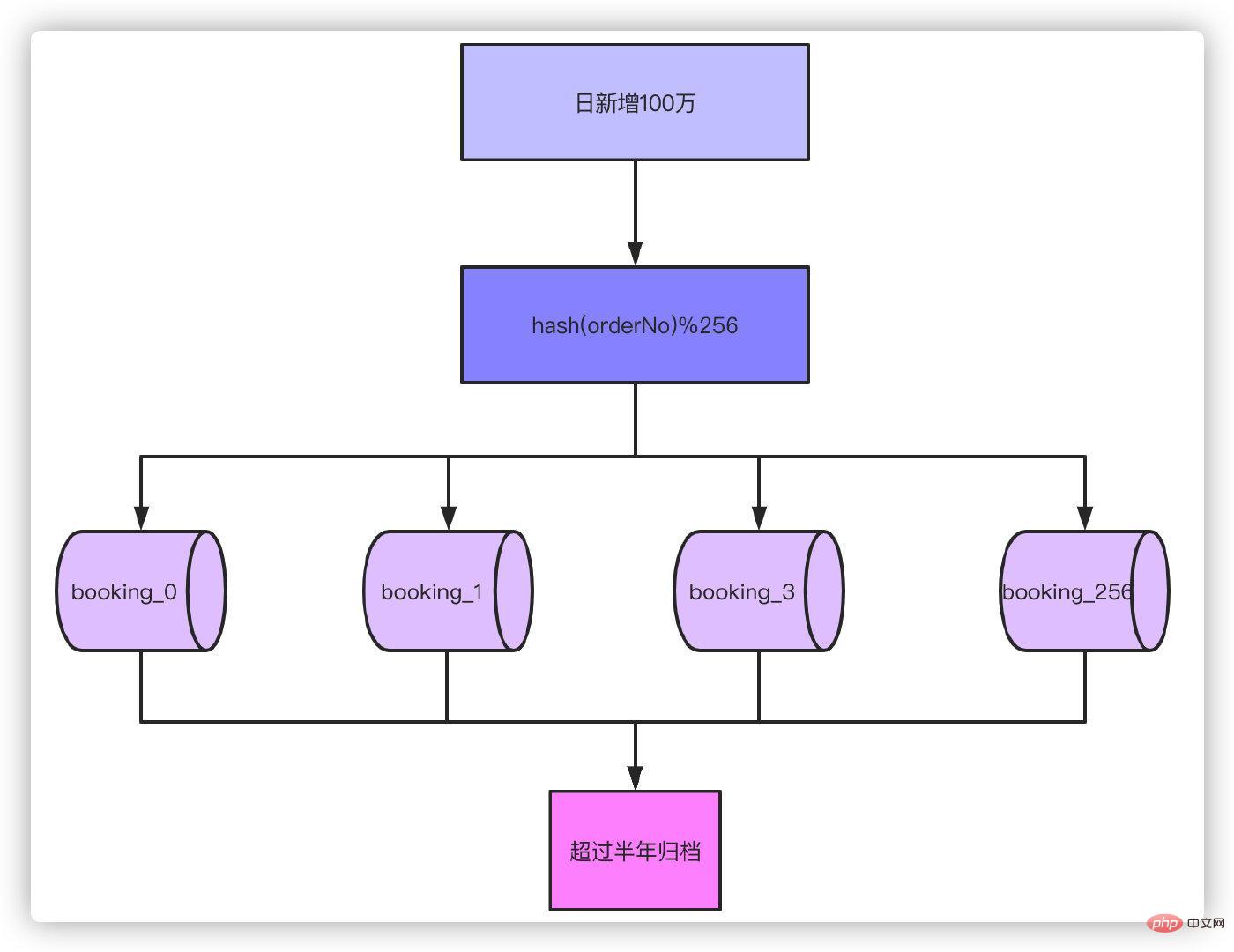
Da der einzige Primärschlüssel auf der Bestellnummer basiert, können die Abfragen, die Sie in der Vergangenheit basierend auf der Primärschlüssel-ID geschrieben haben, nicht verwendet werden. Dies erfordert die Änderung einiger historischer Abfragefunktionen. Aber das ist kein Problem, oder? Ändern Sie es einfach, um anhand der Bestellnummer zu überprüfen. Nichts davon ist ein Problem, das Problem ist das, was unser Titel sagt.
C-seitige Abfrage
Nachdem wir lange geredet haben, sind wir endlich zum Punkt gekommen. Wie können wir also die Probleme der Abfrage und Paging-Abfrage nach der Tabellenpartitionierung lösen?
Lassen Sie uns zunächst über die Abfrage mit dem Sharding-Schlüssel sprechen. Unabhängig davon, was Sie tun, können Sie die spezifische Tabelle für die Abfrage direkt finden.
Wenn es sich nicht um den Sharding-Schlüssel handelt und im obigen Beispiel die Bestellnummer als Sharding-Schlüssel verwendet wird, werden APPs und kleine Programme im Allgemeinen über die Benutzer-ID abgefragt. Was sollen wir also mit dem über die Bestellnummer durchgeführten Sharding tun? ? Die Bestelltabellen vieler Unternehmen verwenden direkt die Benutzer-ID als Sharding-Schlüssel, was sehr einfach ist und direkt überprüft werden kann. Was tun also mit der Bestellnummer? Eine sehr einfache Möglichkeit besteht darin, das Benutzer-ID-Attribut zur Bestellnummer hinzuzufügen. Um ein sehr einfaches Beispiel zu nennen: Sie denken, Sie können den ursprünglichen 41-stelligen Zeitstempel nicht verbrauchen. Die Regel zur Generierung der Bestellnummer enthält die Benutzer-ID Der ID-Hash in der Bestellnummer wird verwendet, sodass der Abfrageeffekt unabhängig von der Bestellnummer oder der Benutzer-ID gleich ist.
Natürlich ist diese Methode nur ein Beispiel. Die spezifischen Regeln zur Generierung von Bestellnummern, wie viele Ziffern und welche Faktoren enthalten sind, hängen von Ihrem eigenen Unternehmen und dem Implementierungsmechanismus ab.

Okay, unabhängig davon, ob Sie die Bestellnummer oder die Benutzer-ID als Sharding-Schlüssel verwenden, können Sie das Problem lösen, indem Sie die beiden oben genannten Methoden befolgen. Dann stellt sich noch eine Frage: Was soll ich tun, wenn es sich weder um eine Bestellnummer noch um eine Benutzer-ID-Abfrage handelt? Das intuitivste Beispiel ist die Abfrage von der Händlerseite oder dem Backend. Die Händlerseite verwendet die ID des Händlers oder Verkäufers als Abfragebedingung. Die Abfragebedingungen im Backend können komplizierter sein, wie einige Backend-Abfragebedingungen, auf die ich gestoßen bin. Es könnten Dutzende davon sein. Wie kann man das überprüfen? ? ? Keine Sorge, lassen Sie uns die komplexen Abfragen auf der B-Seite und im Backend getrennt besprechen.
In Wirklichkeit kommt der größte Teil des echten Datenverkehrs von der C-Seite der Benutzerseite, sodass das Problem im Wesentlichen auf der Benutzerseite gelöst ist. Dieses Problem ist größtenteils gelöst, und der verbleibende Abfrageverkehr kommt von der Händler-Verkäufer-Seite. Seite B-Seite und das Back-End-Support-Betriebsgeschäft werden nicht sehr groß sein, und dieses Problem wird leicht zu lösen sein.
Abfrage auf der anderen Seite
Es gibt zwei Möglichkeiten, die Nicht-Shardingkey-Abfrage auf der B-Seite zu lösen.
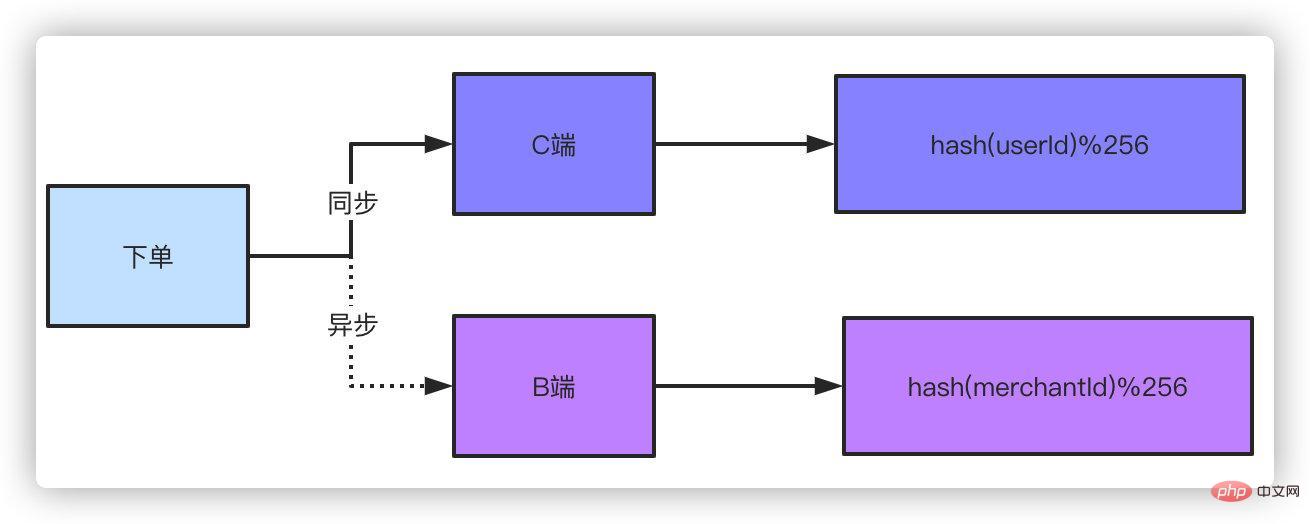
Doppeltes Schreiben bedeutet, dass die Bestelldaten in zwei Kopien gespeichert werden. Für die C-Seite können Sie die Bestellnummer oder die Benutzer-ID als Sharding verwenden Verwenden Sie für die B-Seite einfach die ID des Händlers als Shardingkey. Einige Klassenkameraden werden fragen: Hat es keinen Einfluss auf die Leistung, wenn Sie doppelt schreiben? Da eine leichte Verzögerung für die B-Seite akzeptabel ist, kann eine asynchrone Methode verwendet werden, um die Bestellung für die B-Seite aufzugeben. Denken Sie darüber nach: Wenn Sie nach Taobao gehen, um etwas zu kaufen und eine Bestellung aufzugeben, spielt es dann eine Rolle, wenn der Verkäufer den Erhalt der Bestellnachricht um ein oder zwei Sekunden verzögert? Hat es große Auswirkungen auf den von Ihnen bestellten Imbiss-Händler, wenn die Bestellung ein oder zwei Sekunden zu spät ankommt?
Offline-Data-Warehouse oder ES-Abfrage. Nachdem die Bestelldaten in die Datenbank eingefügt wurden, synchronisieren Sie die Daten mit dem Data-Warehouse oder ES. Die von ihnen unterstützten Größenordnungen sind für diese Abfragebedingung einfach. Bei dieser Methode gibt es definitiv eine leichte Verzögerung, aber diese kontrollierbare Verzögerung ist akzeptabel.
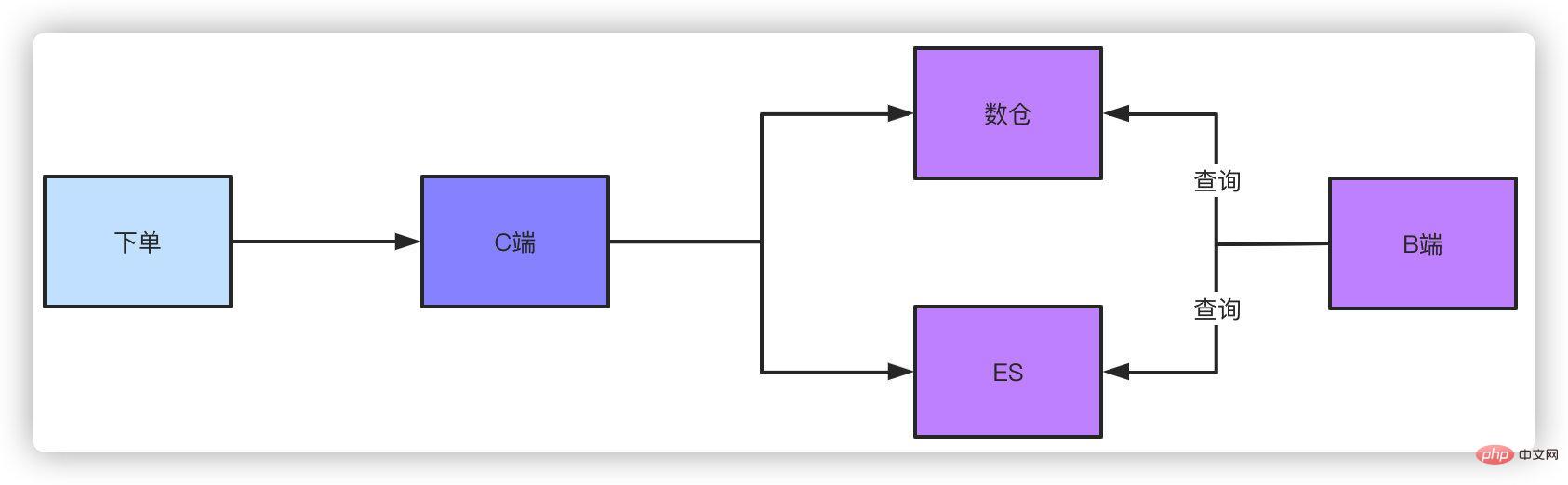 Für Abfragen im Management-Backend, z. B. Vorgänge, Geschäfte und Produkte, die Daten sehen müssen, sind natürlich komplexe Abfragebedingungen erforderlich, die auch über ES oder Data Warehouse erfolgen können. Wenn Sie diese Lösung nicht verwenden und eine Paging-Abfrage ohne Shardingkey durchführen, Bruder, können Sie nur die gesamte Tabelle scannen, um die aggregierten Daten abzufragen, und dann das Paging manuell durchführen, aber die auf diese Weise gefundenen Ergebnisse sind begrenzt.
Für Abfragen im Management-Backend, z. B. Vorgänge, Geschäfte und Produkte, die Daten sehen müssen, sind natürlich komplexe Abfragebedingungen erforderlich, die auch über ES oder Data Warehouse erfolgen können. Wenn Sie diese Lösung nicht verwenden und eine Paging-Abfrage ohne Shardingkey durchführen, Bruder, können Sie nur die gesamte Tabelle scannen, um die aggregierten Daten abzufragen, und dann das Paging manuell durchführen, aber die auf diese Weise gefundenen Ergebnisse sind begrenzt.
Wenn Sie beispielsweise 256 Shards haben und bei der Abfrage alle Shards zyklisch scannen, 20 Daten von jedem Shard abrufen und schließlich die Daten aggregieren und manuell paginieren, ist es definitiv unmöglich, die gesamte Menge zu finden Daten.
Zusammenfassung
Das Abfrageproblem nach der Aufteilung von Unterdatenbanken und Tabellen ist tatsächlich bekannt, aber ich glaube, dass das Geschäft der meisten Studenten möglicherweise nicht diese Größenordnung erreicht Mai Sie steckten alle in der Konzeptionsphase fest, und als ich im Interview danach gefragt wurde, war ich ratlos, weil ich nicht wusste, was ich tun sollte, weil ich keine Erfahrung hatte.
Die Unterdatenbank und die Tabelle werden zunächst anhand des bestehenden Geschäftsvolumens und des zukünftigen Zuwachses beurteilt. Beispielsweise verfügt Pinduoduo, das ein tägliches Auftragsvolumen von 50 Millionen hat, über Daten von mehreren zehn Milliarden in einem halben Jahr hat eine Punktzahl von 4096. Die Tabelle ist richtig, aber der tatsächliche Vorgang ist derselbe. Für Ihr Unternehmen ist es nicht erforderlich, ihn in 4096 aufzuteilen. Treffen Sie eine vernünftige Auswahl basierend auf dem Unternehmen.
Wir können Abfragen auf Basis von Shardingkey problemlos lösen, indem wir doppelte Daten, Data Warehouse und ES-Lösungen löschen. Wenn die Datenmenge nach der Aufteilung sehr gering ist, erstellen Sie natürlich einen Index. Das Scannen der gesamten Tabelle zur Abfrage ist eigentlich kein Problem.
Verwandte kostenlose Lernempfehlungen:
Das obige ist der detaillierte Inhalt vonVerstehen Sie die Paging-Abfrage, nachdem zig Milliarden Daten in Tabellen unterteilt wurden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!