
Heim >Datenbank >MySQL-Tutorial >Ein Artikel, der Ihnen hilft, die zugrunde liegenden Prinzipien von MYSQL zu verstehen
Ein Artikel, der Ihnen hilft, die zugrunde liegenden Prinzipien von MYSQL zu verstehen

- coldplay.xixinach vorne
- 2020-11-10 17:12:493590Durchsuche
In der Spalte „MySQL-Video-Tutorial“ werden die zugrunde liegenden Prinzipien vorgestellt.
MYSQL
Ein SQL-Ausführungsprozess Erster Blick auf eine SQL-Abfrage
Erster Blick auf eine SQL-Abfrage
(Hier ist die offizielle Dokumentation für jede Speicher-Engine MySQL-Speicher-Engine)
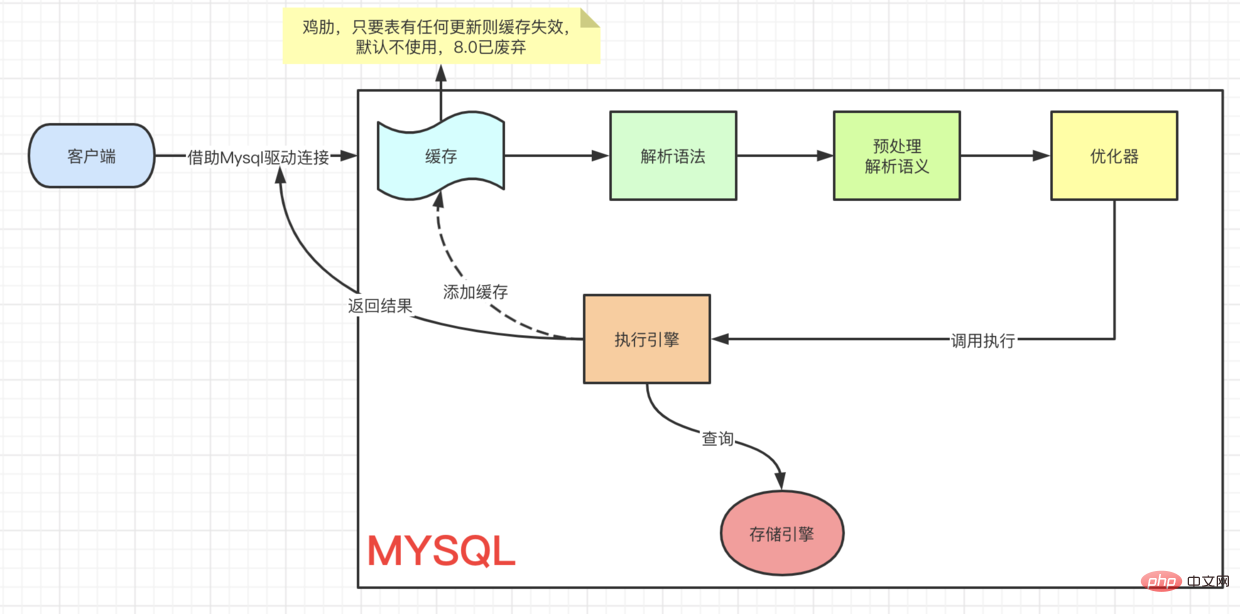 Eine aktualisierte SQL-Ausführung
Eine aktualisierte SQL-Ausführung
- Die Aktualisierung erfolgt über die
Innodb-Architektur
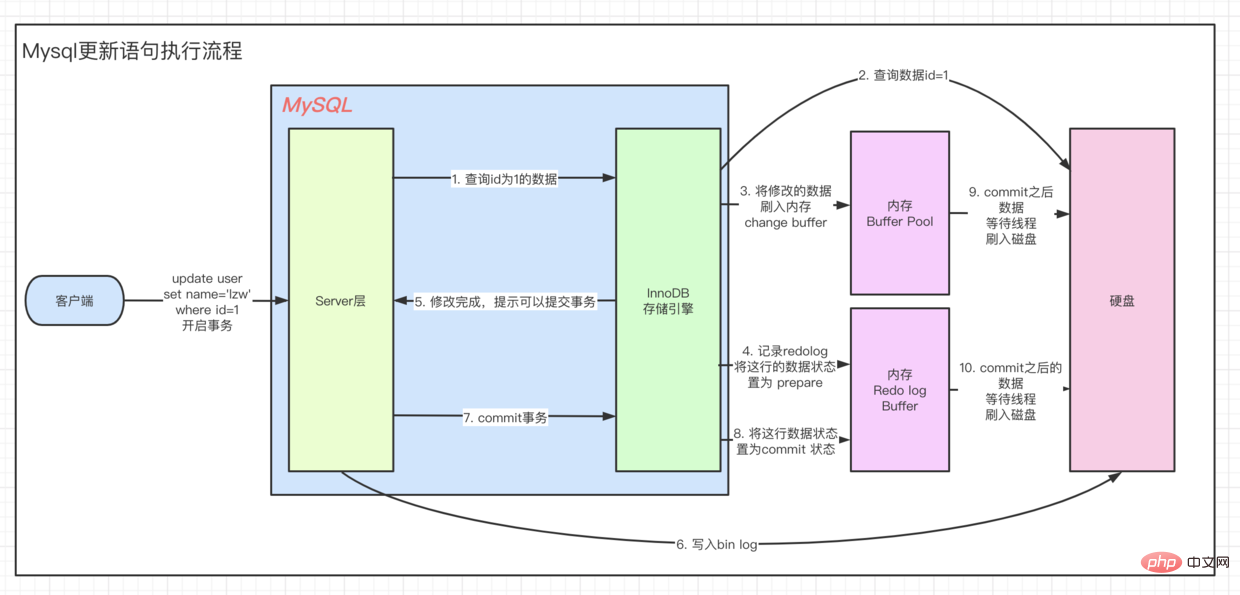
client=> ··· => Der Vorgang ist derselbe. Um den <code>UPDATE-Prozess zu verstehen, werfen wir zunächst einen Blick auf das Architekturmodell von Innodb. 
Interne Module客户端 => ··· => 执行引擎 是一样的流程,都要先查到这条数据,然后再去更新。要想理解 UPDATE 流程我们先来看看,Innodb的架构模型。Innodb 架构
上一张 MYSQL 官方InnoDB架构图:
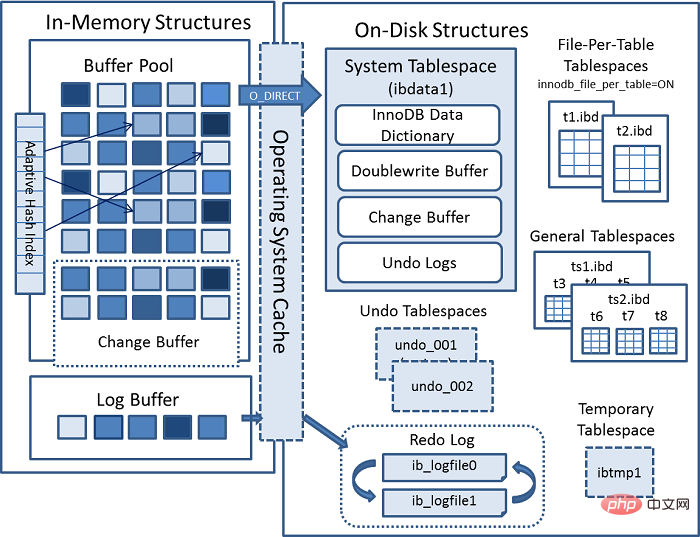
内部模块
连接器(JDBC、ODBC等) =>
[MYSQL 内部
[Connection Pool] (授权、线程复用、连接限制、内存检测等) => [SQL Interface] (DML、DDL、Views等) [Parser] (Query Translation、Object privilege) [Optimizer] (Access Paths、 统计分析) [Caches & Buffers] => [Pluggable Storage Engines]复制代码
]
=> [File]
内存结构
这里有个关键点,当我们去查询数据时候会先 拿着我们当前查询的 page 去 buffer pool 中查询 当前page是否在缓冲池中。如果在,则直接获取。
而如果是update操作时,则会直接修改 Buffer中的值。这个时候,buffer pool中的数据就和我们磁盘中实际存储的数据不一致了,称为脏页。每隔一段时间,Innodb存储引擎就会把脏页数据刷入磁盘。一般来说当更新一条数据,我们需要将数据给读取到buffer中修改,然后写回磁盘,完成一次 落盘IO 操作。
为了提高update的操作性能,Mysql在内存中做了优化,可以看到,在架构图的缓冲池中有一块区域叫做:change buffer。顾名思义,给change后的数据,做buffer的,当更新一个没有 unique index 的数据时,直接将修改的数据放到 change buffer,然后通过 merge 操作完成更新,从而减少了那一次 落盘的IO 操作。
- 我们上面说的有个条件:
没有唯一索引的数据更新时,为什么必须要没有唯一索引的数据更新时才能直接放入change buffer呢?如果是有唯一约束的字段,我们在更新数据后,可能更新的数据和已经存在的数据有重复,所以只能从磁盘中把所有数据读出来比对才能确定唯一性。 - 所以当我们的数据是
写多读少的时候,就可以通过 增加innodb_change_buffer_max_size来调整change buffer在buffer pool中所占的比例,默认25(即:25%)
问题又来了,merge是如何运作的
有四种情况:
- 有其他访问,访问到了当前页的数据,就会合并到磁盘
- 后台线程定时merge
- 系统正常shut down之前,merge一次
-
redo log写满的时候,merge到磁盘
一、redo log是什么
谈到redo,就要谈到innodb的 crash safe,使用 WAL 的方式实现(write Ahead Logging,在写之前先记录日志)
这样就可以在,当数据库崩溃的后,直接从 redo log中恢复数据,保证数据的正确性
redo log 默认存储在两个文件中 ib_logfile0 ib_logfile1,这两个文件都是固定大小的。为什么需要固定大小?
这是因为redo log的 顺序读取
rrreee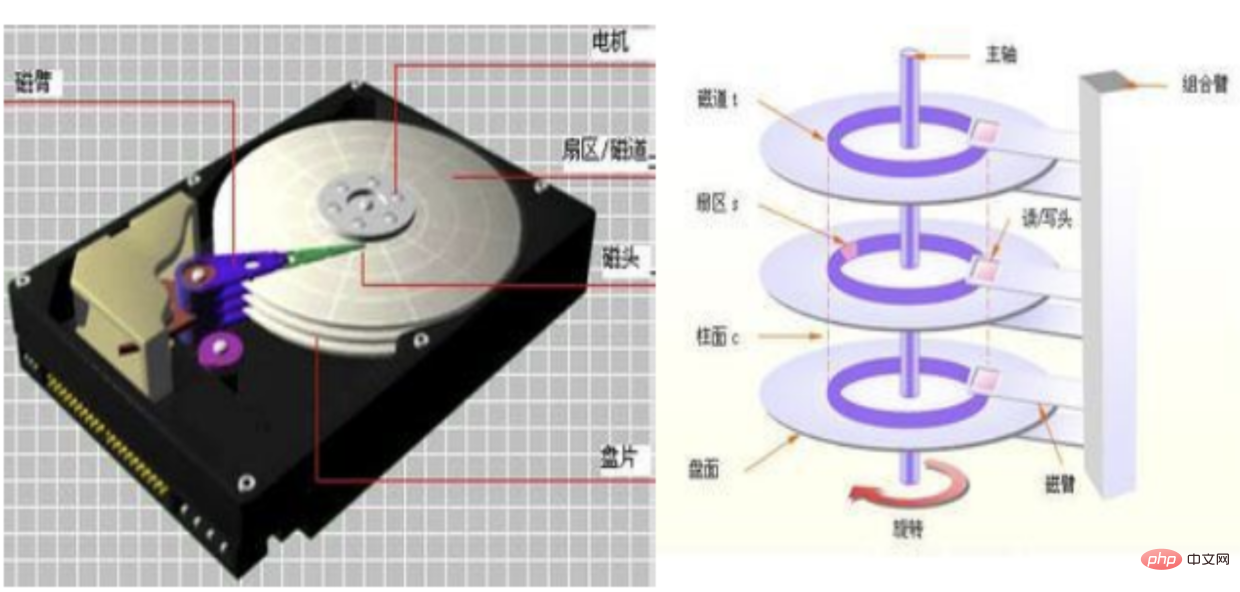 ]
]
=> [File]
Speicherstruktur
Hier gibt es einen wichtigen Punkt: Wenn wir Daten abfragen, nehmen wir zuerst die
Seite, die wir gerade abfragen, und gehen zum Pufferpool, um die aktuelle Seite abzufragen. code> Ob es sich im <code>Pufferpool befindet. Wenn ja, holen Sie es sich direkt. - Und wenn es sich um einen
Aktualisierungsvorganghandelt, wird der Wert imPufferdirekt geändert. Zu diesem Zeitpunkt sind die Daten imPufferpoolinkonsistentmit den tatsächlich auf unserer Festplatte gespeicherten Daten, was alsschmutzige Seitebezeichnet wird. Hin und wieder löscht die Innodb-Speicher-Engineverschmutzte Seitendatenauf die Festplatte. Im Allgemeinen müssen wir beim Aktualisieren eines Datenelements die Daten zur Änderung in denPuffereinlesen und sie dann zurück auf die Festplatte schreiben, um einendisk IO-Vorgang abzuschließen. - Um die Betriebsleistung von
updatezu verbessern, wurde MySQL im Speicher optimiert. Sie können sehen, dass es im Pufferpool vonArchitekturdiagrammeinen Bereich mit dem Namen gibt:Puffer ändern. Wie der Name schon sagt, erstellteinen Puffer für die geänderten Daten. Beim Aktualisieren von Daten ohneeindeutigen Indexwerden die geänderten Daten direkt imÄnderungspuffer abgelegt. code> code> und schließen Sie dann die Aktualisierung durch den <code>merge-Vorgang ab, wodurch der E/A-Vorgang desDisk-Drops reduziert wird. - Für das, was wir oben gesagt haben, gibt es eine Bedingung:
Wenn die Daten ohne eindeutigen Index aktualisiert werden, warum muss das so sein?Wenn die Daten ohne eindeutigen Index aktualisiert werdenbevor es direkt ineingefügt werden kann. Was ist mit dem Änderungspuffer? Wenn es sich um ein Feld miteindeutigen Einschränkungenhandelt, werden die aktualisierten Daten nach der Aktualisierung der Daten möglicherweise mit den vorhandenen Daten dupliziert, sodass wir nuralle Daten von der Festplatte lesen und vergleichen können um die Einzigartigkeit zu bestimmen.
Wenn unsere Daten also mehr geschrieben und weniger gelesen sind, können wir den Änderungspuffer im Puffer anpassen, indem wir den <code>innodb_change_buffer_max_size-Anteil erhöhen des Pools, der Standardwert ist 25 (also: 25%)
Die Frage ist wieder, wie funktioniert die Zusammenführung
🎜Es gibt vier Situationen: 🎜🎜🎜Bei einem anderen Zugriff werden die Daten der aktuellen Seite auf der Festplatte zusammengeführt🎜🎜Geplante Zusammenführung des Hintergrundthreads🎜🎜Bevor das System normal herunterfährt, einmal zusammenführen🎜🎜Redo-Protokoll schreiben Wenn es voll ist, auf Festplatte zusammenführen🎜🎜1. Was ist Redo-Log? Wenn wir über Redo sprechen, müssen wir über den absturzsicheren von innodb sprechen WAL-Implementierung (Ahead-Protokollierung schreiben, Protokoll vor dem Schreiben aufzeichnen)🎜🎜Auf diese Weise können die Daten bei einem Datenbankabsturz direkt aus Redo-Log wiederhergestellt werden, um die Richtigkeit der Daten sicherzustellen.🎜 🎜Redo-Log wird standardmäßig in zwei Dateien gespeichert: ib_logfile0 ib_logfile1, beide Dateien haben eine feste Größe. Warum benötigen Sie eine feste Größe? 🎜🎜Dies ist auf die Funktion sequentielles Lesen des Redo-Protokolls zurückzuführen, bei der es sich um einen kontinuierlichen Speicherplatz handeln muss🎜🎜2. Zufälliges Lesen und Schreiben sowie sequentielles Lesen und Schreiben🎜🎜 Siehe Bild 🎜🎜🎜 Im Allgemeinen sind unsere Daten auf der Festplatte verstreut: 🎜🎜Die Lese- und Schreibsequenz der mechanischen Festplatte ist: 🎜🎜🎜Suchen Sie die Spur🎜🎜Warten Sie darauf, in den entsprechenden Sektor zu wechseln🎜🎜Beginnen Sie mit dem Lesen und Schreiben 🎜🎜🎜 Festkörperlesen und -schreiben: 🎜
- Suchen Sie direkt den Flash-Speicherchip (aus diesem Grund ist Solid-State schneller als mechanisch)
- Beginnen Sie mit dem Lesen und Schreiben
Tatsächlich verwenden wir beim Speichern, egal ob mechanisch oder Solid-State, den Dateisystem und die Festplatte Sie interagieren miteinander, und es gibt zwei Möglichkeiten, mit ihnen umzugehen. Zufälliges Lesen und Schreiben und Sequentielles Lesen und Schreiben文件系统与磁盘打交道的,而他们打交道的方式就有两个。随机读写和顺序读写
- 随机读写存储的数据是分布在不同的
块(默认 1block=8扇区=4K) - 而顺序存储,顾名思义,数据是分布在
一串连续的块中,这样读取速度就大大提升了
三、回到我们架构图
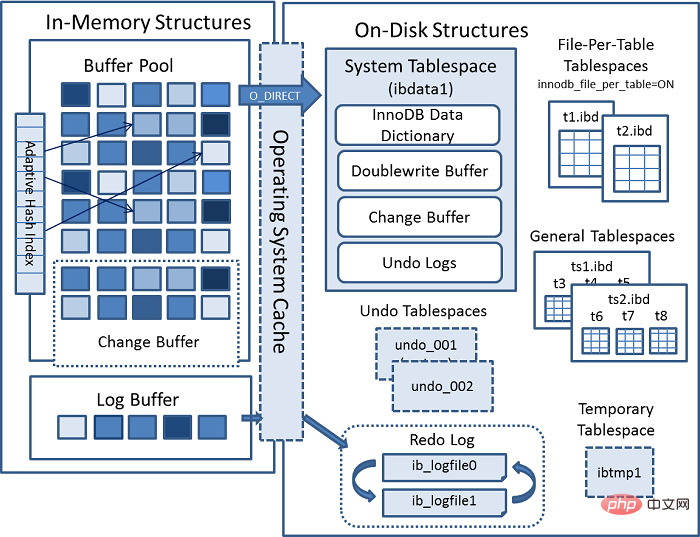
看到buffer pool中的Log Buffer,其就是用来写 redo log 之前存在的缓冲区
在这里,redo log具体的执行策略有三种:
- 不用写
Log Buffer,只需要每秒写redo log 磁盘数据一次,性能高,但会造成数据 1s 内的一致性问题。适用于强实时性,弱一致性,比如评论区评论 - 写
Log Buffer,同时写入磁盘,性能最差,一致性最高。 适用于弱实时性,强一致性,比如支付场景 - 写
Log Buffer,同时写到os buffer(其会每秒调用fsync将数据刷入磁盘),性能好,安全性也高。这个是实时性适中一致性适中的,比如订单类。
我们通过innodb_flush_log_at_trx_commit就可以设置执行策略。默认为 1
内存结构小结

- Buffer Pool 用于加速读
- Change Buffer 用于没有非唯一索引的加速写
- Log Buffer 用于加速redo log写
-
自适应Hash索引主要用于加快查询页。在查询时,Innodb通过监视索引搜索的机制来判断当前查询是否能走Hash索引。比如LIKE运算符和% 通配符就不能走。
硬盘结构
一、System Tablespace
存储在一个叫ibdata1的文件中,其中包含:
- InnoDB Data Dictionary,存储了元数据,比如表结构信息、索引等
- Doublewrite Buffer 当
Buffer Pool写入数据页时,不是直接写入到文件,而是先写入到这个区域。这样做的好处的是,一但操作系统,文件系统或者mysql挂掉,可以直接从这个Buffer中获取数据。 - Change Buffer 当Mysql shut down的时候,修改就会被存储在磁盘这里
- Undo Logs 记录事务修改操作
二、File-Per-Table Tablespaces
每一张表都有一张 .ibd 的文件,存储数据和索引。
- 有了
每表文件表空间可以使得ALTER TABLE与TRUNCATE TABLE性能得到很好的提升。比如ALTER TABLE,相较于对驻留在共享表空间中的表,在修改表时,会进行表复制操作,这可能会增加表空间占用的磁盘空间量。此类操作可能需要与表中的数据以及索引一样多的额外空间。该空间不会像每表文件表空间 - Die beim zufälligen Lesen und Schreiben gespeicherten Daten werden in verschiedenen
Blöckenverteilt (Standard 1block=). 8 Sektoren =4K) - Und sequentielle Speicherung, wie der Name schon sagt, die Daten werden in
einer Reihe aufeinanderfolgender Blöckeverteilt, sodass die Lesegeschwindigkeit erheblich verbessert wird
3. Zurück zu unserem Architekturdiagramm

Protokollpuffer im Pufferpool , und es wird verwendet, um den Puffer zu schreiben, der vor dem Redo-Log vorhanden war🎜🎜Hier gibt es drei spezifische Ausführungsstrategien für das Redo-Log:🎜- 🎜Keine Notwendigkeit,
- Die Speicherplatzauslastung ist gering und es kommt zu Fragmentierung, die sich auf die Leistung auswirkt, wenn
Tabelle löschen(es sei denn, Sie verwalten die Fragmentierung selbst) - 因为每个表分成各自的表文件,操作系统不能同时进行
fsync一次性刷入数据到文件中 - mysqld会持续保持每个表文件的
文件句柄, 以提供维持对文件的持续访问 - 通用表空间又叫
共享表空间,他可以存储多个表的数据 - 如果存储相同数量的表,消耗的存储比
每表表空间小 - 在MySQL 5.7.24中弃用了将表分区放置在常规表空间中的支持,并且在将来的MySQL版本中将不再支持。
- 提供修改操作的
原子性,即当修改到一半,出现异常,可以通过Undo 日志回滚。 - 它存储了,事务开始前的原始数据与这次的修改操作。
- Undo log 存在于回滚段(rollback segment)中,回滚段又存在
系统表空间``撤销表空间``临时表空间中,如架构图所示。 - 查询到我们要修改的那条数据,我们这里称做
origin,返给执行器 - 在执行器中,修改数据,称为
modification - 将
modification刷入内存,Buffer Pool的Change Buffer - 引擎层:记录undo log (实现事务原子性)
- 引擎层:记录redo log (崩溃恢复使用)
- 服务层:记录bin log(记录DDL)
- 返回更新成功结果
- 数据等待被工作线程刷入磁盘
- 这一个log和
innodb引擎没有多大关系,我们前面说的那两种日志,都在是innodb引擎层的。而Bin log是处于服务层的。所以他能被各个引擎所通用 - 他的主要作用是什么呢?首先,
Bin log是以事件的形式,记录了各个DDL DML语句,它是一种逻辑意义上的日志。 - 能够实现
主从复制,从服务器拿到主服务器的bin log日志,然后执行。 - 做
数据恢复,拿到某个时间段的日志,重新执行一遍。 - 默认的
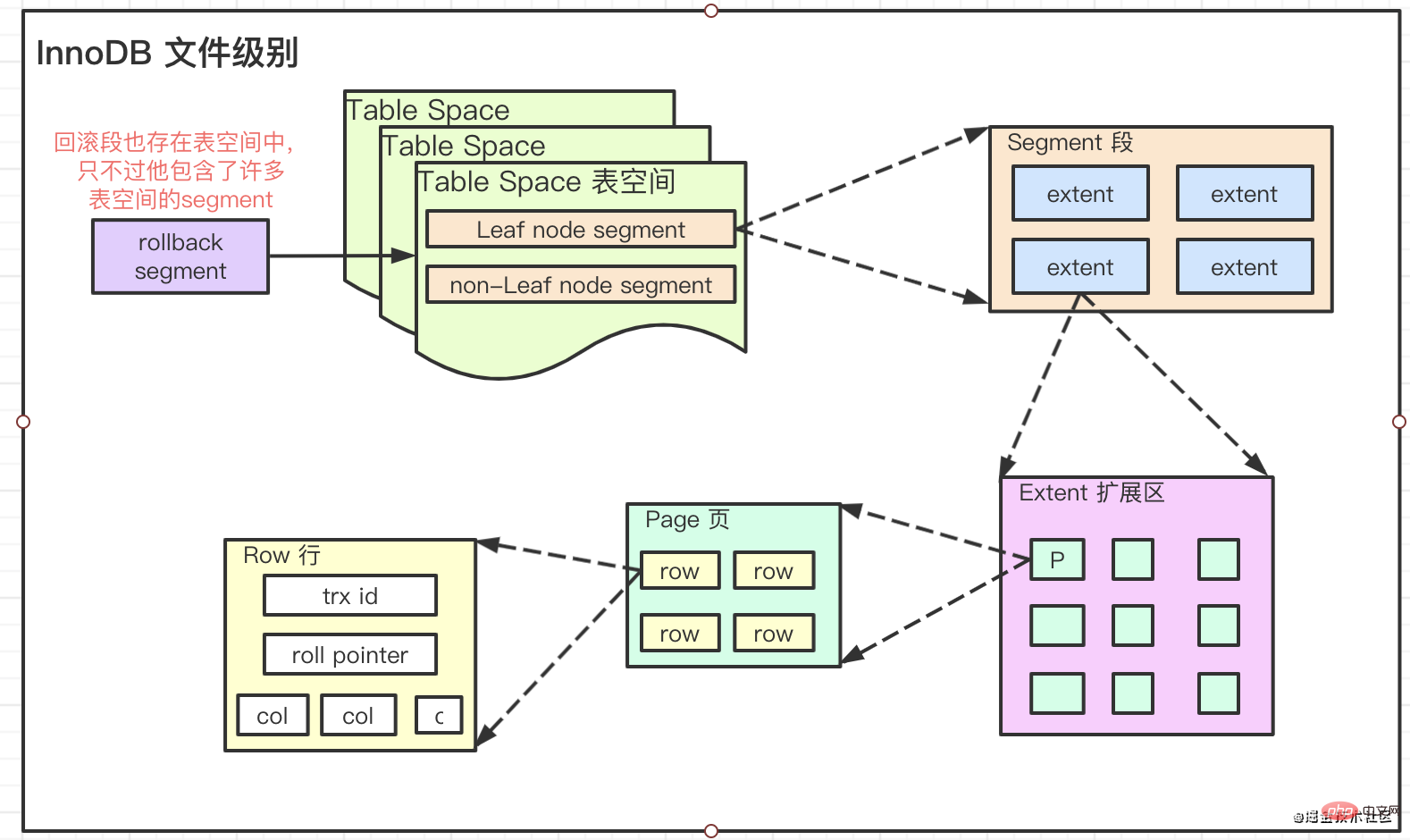
extent大小为1M即64个16KB的Page。平常我们文件系统所说的页大小是4KB,包含8个512Byte的扇区。
Log Buffer zu schreiben Code>, nur jede Die Redo-Log-Festplattendaten werden einmal pro Sekunde geschrieben, was eine hohe Leistung bietet, aber innerhalb von 1 Sekunde zu Datenkonsistenzproblemen führt. Anwendbar auf <code>starke Echtzeit, schwache Konsistenz, wie z. B. Kommentare im Kommentarbereich🎜🎜schreiben Sie Protokollpuffer und gleichzeitig schreiben Auf die Festplatte ist die Leistung am schlechtesten und die Konsistenz am höchsten. Anwendbar auf Schwache Echtzeit, Starke Konsistenz, wie z. B. Zahlungsszenario🎜🎜Schreiben Sie Protokollpuffer und schreiben Sie darauf Der OS-Puffer (der jede Sekunde fsync aufruft, um Daten auf die Festplatte zu übertragen) bietet eine gute Leistung und hohe Sicherheit. Dies ist moderate Echtzeit moderate Konsistenz, wie z. B. Auftragstyp. 🎜🎜🎜Wir können die Ausführungsrichtlinie über innodb_flush_log_at_trx_commit festlegen. Der Standardwert ist 1🎜Zusammenfassung der Speicherstruktur
🎜🎜🎜🎜Pufferpool für Beschleunigung Read🎜🎜Change Buffer wird verwendet, um das Schreiben ohne nicht eindeutige Indizes zu beschleunigen. 🎜🎜Log Buffer wird verwendet, um das Schreiben von Redo-Logs zu beschleunigen. 🎜🎜Adaptive Hash Index wird hauptsächlich verwendet, um die Abfrage von page . Bei der Abfrage bestimmt Innodb, ob die aktuelle Abfrage den <code>Hash-Index durchlaufen kann, indem es den Indexsuchmechanismus überwacht. Beispielsweise können der LIKE-Operator und das Platzhalterzeichen % nicht verwendet werden. 🎜🎜Festplattenstruktur
1. System Tablespace
🎜 wird in einer Datei namensibdata1-Datei, die Folgendes enthält: 🎜🎜🎜InnoDB Data Dictionary, das Metadaten wie Tabellenstrukturinformationen, Indizes usw. speichert. 🎜🎜Doublewrite Buffer Wenn <code>Buffer Pool die Datenseite schreibt , es wird nicht direkt in die Datei geschrieben, sondern zuerst in diesen Bereich geschrieben. Dies hat den Vorteil, dass die Daten direkt aus diesem Puffer abgerufen werden können, sobald das Betriebssystem, das Dateisystem oder MySQL hängt. 🎜🎜Puffer ändern Wenn MySQL heruntergefahren wird, werden die Änderungen auf der Festplatte gespeichert. 🎜🎜Rückgängig-Protokolle zeichnen Transaktionsänderungsvorgänge auf >🎜Jede Tabelle verfügt über eine .ibd-Datei zum Speichern von Daten und Indizes. 🎜🎜🎜Mit Datei-pro-Tabelle-Tablespace kann die Leistung von ALTER TABLE und TRUNCATE TABLE erheblich verbessert werden. Beispielsweise führt ALTER TABLE im Vergleich zu einer Tabelle in einem gemeinsam genutzten Tabellenbereich beim Ändern der Tabelle einen Tabellenkopiervorgang aus, der den Tabellenbereich vergrößern kann belegt. Die Größe des Speicherplatzes. Solche Vorgänge erfordern möglicherweise genauso viel zusätzlichen Speicherplatz wie die Daten in der Tabelle und den Indizes. Dieser Speicherplatz wird nicht wie Datei-pro-Tabelle-Tablespace an das Betriebssystem zurückgegeben. 🎜🎜Tablespace-Datendateien pro Tabelle können auf separaten Speichergeräten zur E/A-Optimierung, Speicherplatzverwaltung oder Sicherung erstellt werden. Dies bedeutet, dass Tabellendaten und -strukturen problemlos zwischen verschiedenen Datenbanken migriert werden können. 🎜🎜Wenn eine Datenbeschädigung auftritt, Sicherungen oder Binärprotokolle nicht verfügbar sind oder eine MySQL-Serverinstanz nicht neu gestartet werden kann, spart das Speichern von Tabellen in einer einzigen Tablespace-Datendatei Zeit und erhöht die Chance auf eine erfolgreiche Wiederherstellung. 🎜🎜🎜Natürlich gibt es Vor- und Nachteile:🎜Drop table的时候会影响性能(除非你自己管理了碎片)三、General Tablespaces
四、Temporary Tablespaces
存储在一个叫 ibtmp1 的文件中。正常情况下Mysql启动的时候会创建临时表空间,停止的时候会删除临时表空间。并且它能够自动扩容。
五、Undo Tablespaces
Redo Log
前面已经介绍过
总结一下,我们执行一句update SQL 会发生什么
Bin log
说了 Undo、Redo也顺便说一下Bin log.
跟随一条SQL语句完成全局预览后,我们来看看回过头来让SQL变得更加丰富,我们来添加一个索引试试
华丽的分割线
索引篇
要想彻底弄明白InnoDB中的索引是个什么东西,就必须要了解它的文件存储级别
Innodb中将文件存储分为了四个级别
Pages, Extents, Segments, and Tablespaces
它们的关系是:
存储结构 B树变体 B+树
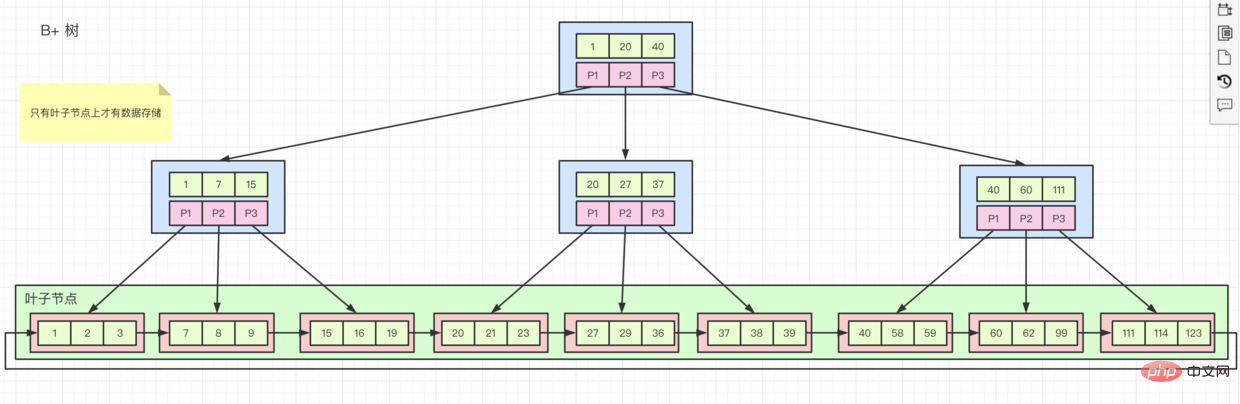
所以有时候,我们被要求主键为什么要是有序的原因就是,如果我们在一个有序的字段上,建立索引,然后插入数据。
在存储的时候,innodb就会按着顺序一个个存储到 页 上,存满一个页再去申请新的页,然后接着存。
但如果我们的字段是无序的,存储的位置就会在不同的页上。当我们的数据存储到一个已经被 存满的页上时,就会造成页分裂,从而形成碎片Da jede Tabelle in ihre eigene unterteilt ist Tabellendatei, das Betriebssystem kann nicht gleichzeitig fsync einmaliges Flushen von Daten in die Datei durchführen
Dateihandle von bei Jede Tabellendatei bietet kontinuierlichen Zugriff auf Dateien
Allgemeine Tablespaces
🎜🎜Allgemeine Tablespaces werden auch shared tablespaces. Es können Daten ausmehreren Tabellen gespeichert werden. 🎜Wenn die gleiche Anzahl von Tabellen gespeichert wird, ist der verbrauchte Speicher kleiner als tablespace pro Tabelle 4. Temporäre Tablespaces
werden in einer Datei namens ibtmp1 gespeichert. Unter normalen Umständen erstellt MySQL beim Start einen temporären Tabellenbereich und löscht den temporären Tabellenbereich beim Stoppen. Und es kann automatisch erweitert werden. 🎜
5. Tabellenbereiche rückgängig machen
🎜🎜 BietetAtomizität von Änderungsvorgängen, d. Sie können es über Rollback rückgängig machen protokollieren. 🎜Es speichert die Originaldaten vor Beginn der Transaktion und diesem Änderungsvorgang. 🎜Das Rückgängig-Protokoll existiert im Rollback-Segment und das Rollback-Segment existiert im Systemtabellenbereich „Rückgängig-Tabellenbereich“ temporärer Tabellenbereich , wie im Architekturdiagramm gezeigt. Redo Log
Wurde bereits eingeführt🎜
Zusammenfassend: Wir Was passiert, wenn eine Update-SQL-Anweisung ausgeführt wird
🎜🎜Die Daten, die wir ändern möchten, werden abgefragt, die wir hierorigin nennen, und an den Executor zurückgegeben🎜Im Executor Das Ändern von Daten wird als Änderung🎜Flash Änderung in den Speicher, Puffer ändern des Pufferpools 🎜Engine-Schicht: Rückgängig-Protokoll aufzeichnen (um Transaktionsatomizität zu erreichen) 🎜Engine-Schicht: Redo-Protokoll aufzeichnen (wird für die Wiederherstellung nach einem Absturz verwendet) 🎜Service-Schicht: Bin-Protokoll aufzeichnen (DDL aufzeichnen) li>🎜 li>🎜Das Erfolgsergebnis der Aktualisierung zurückgeben🎜Die Daten warten darauf, vom Arbeitsthread auf die Festplatte geleert zu werden🎜
Bin log
Ich habe Undo und Redo erwähnt und übrigens, Bin log.🎜 🎜🎜Dieses Protokoll hat wenig mit der innodb-Engine zu tun. Die beiden zuvor erwähnten Protokolle befinden sich beide auf der Ebene der innodb-Engine. Und Bin log befindet sich in der Serviceschicht. Es kann also von allen Motoren verwendet werden🎜Was ist seine Hauptfunktion? Zunächst zeichnet Bin log jede DDL DML-Anweisung in Form von Ereignissen auf. Es handelt sich im logischen Sinne um ein Protokoll. 🎜Es kann eine Master-Slave-Replikation realisieren und das <code>bin log-Protokoll des Master-Servers vom server. 🎜Führen Sie eine Datenwiederherstellung durch, rufen Sie die Protokolle eines bestimmten Zeitraums ab und führen Sie sie erneut aus.
Nachdem wir einer SQL-Anweisung gefolgt sind, um die globale Vorschau abzuschließen, blicken wir zurück und machen die SQL reicher. Fügen wir einen Indexhinzu >Probieren Sie es aus
Wunderschöne Trennlinie🎜
Indexartikel
Wenn Sie es gründlich verstehen wollenWas ist ein Index in InnoDB
? Sie müssen seineDateispeicherebene verstehen. 🎜
Innodb unterteilt die Dateispeicherung in vier Ebenen
Seiten, Extents, Segmente und Tablespaces🎜
Ihre Beziehung ist:🎜
 🎜
🎜
- 🎜defaultextent ist
1M, also 64 16KB Seite. Die Seitengröße, auf die sich unser Dateisystem normalerweise bezieht, beträgt 4 KB und enthält 8 Sektoren von 512 Byte. Speicherstruktur B-Baum Variante B+ Baum
🎜
Manchmal werden wir gefragt, warum der Primärschlüssel geordnet sein muss, weil wir einen Index für ein geordnetes Feld erstellen und dann Daten einfügen.
Beim Speichern speichert innodb sie nacheinander auf Seiten. Wenn eine Seite voll ist, wird sie für eine neue Seite angewendet und dann mit dem Speichern fortgefahren. 🎜
Wenn unsere Felder jedoch ungeordnet sind, befinden sich die Speicherorte auf verschiedenen Seiten. Wenn unsere Daten auf einer Seite gespeichert werden, die bereits voll ist, kommt es zu einer Seitenteilung, wodurch Fragmente entstehen . 🎜
Mehrere verschiedene Indexorganisationsformen
- Clustered-Index, wie im
B+tree-Diagramm oben gezeigt, werdenZeilendatenauf den untergeordneten Knoten gespeichert und derdes Index Wenn die Sortierreihenfolgemit derIndexschlüsselwertreihenfolgeübereinstimmt, handelt es sich um einenClustered-Index. Der Primärschlüsselindex ist ein Clustered-Index, alle anderen sindHilfsindizesB+树图所示,子节点上存储行数据,并且索引的排列的顺序和索引键值顺序一致的话就是聚簇索引。主键索引就是聚簇索引,除了主键索引,其他所以都是辅助索引 - 辅助索引,如果我们创建了一个
辅助索引,它的叶子节点上只存储自己的值和主键索引的值。这就意味着,如果我们通过辅助索引查询所有数据,就会先去查找辅助索引中的主键键值,然后再去主键索引里面,查到相关数据。这个过程称为回表 -
rowid如果没有主键索引怎么办呢?- 没有主键,但是有一个 Unique key 而且都不是 null的,则会根据这个 key来创建
聚簇索引。 - 那上面两种都没有呢,别担心,innodb自己维护了一个叫
rowid的东西,根据这个id来创建聚簇索引
- 没有主键,但是有一个 Unique key 而且都不是 null的,则会根据这个 key来创建
索引如何起作用
搞清楚什么是索引,结构是什么之后。 我们来看看,什么时候我们要用到索引,理解了这些能更好的帮助我们创建正确高效的索引
离散度低不建索引,也就是数据之间相差不大的就没必要建立索引。(因为建立索引,在查询的时候,innodb大多数据都是相同的,我走索引 和全表没什么差别就会直接
全表查询)。比如 性别字段。这样反而浪费了大量的存储空间。-
联合字段索引,比如
idx(name, class_name)- 当执行
select * from stu where class_name = xx and name = lzw查询时,也能走idx这个索引的,因为优化器将SQL优化为了name = lzw and class_name = xx - 当需要有
select ··· where name = lzw的时候,不需要创建一个单独的name索引,会直接走idx这个索引 -
覆盖索引。如果我们此次查询的所有数据全都包含在索引里面了,就不需要再回表去查询了。比如:select class_name from stu where name =lzw
- 当执行
-
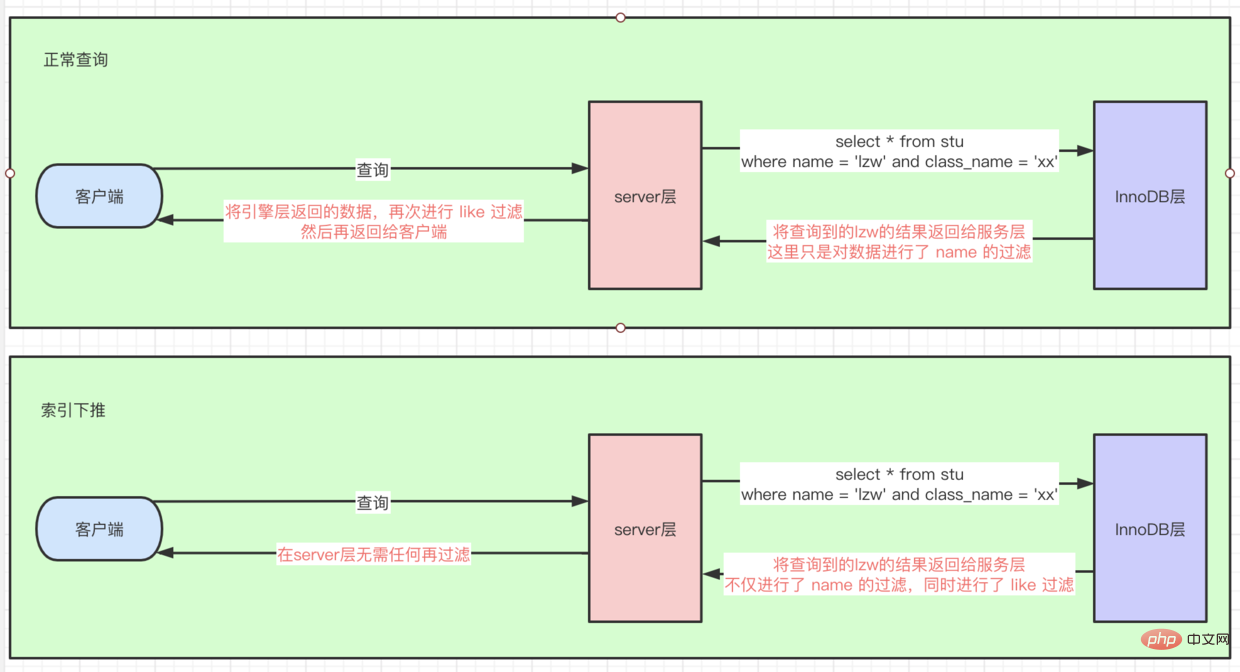
索引条件下推(index_condition_pushdown)
- 有这样一条SQL,
select * from stu where name = lzw and class_name like '%xx' - 如果没有
索引条件下推,因为后面是like '%xx'的查询条件,所以这里首先根据name走idx联合索引查询到几条数据后,再回表查询到全量row数据,然后在server层进行 like 过滤找到数据 - 如果有,则直接在
引擎层对like也进行过滤了,相当于把server层这个过滤操作下推到引擎层了。如图所示:
- 有这样一条SQL,
建立索引注意事项
- 在where、order、join的on 使用次数多的时候,加上索引
- 离散度高的字段才能建立索引
- 联合索引把离散度高的放前面(因为首先根据第一个字段匹配,能迅速定位数据位置。)
- 频繁更新的字段不能建索引(造成
页分裂,索引按顺序存储,如果存储页满了,再去插入就会造成页分裂) - 使用比如replace、sum、count等
函数的时候不会使用索引,所以没必要额外建 - 出现隐式转化的时候,比如字符串转int,也用不到索引
- 特别长的字段,可以截取前面几位创建索引(可以通过
select count(distinct left(name, 10))/count(*)来看离散度,决定到底提取前几位)
- tips: 执行一个SQL,不能确切说他是否能不能用到索引,毕竟这一切都是
优化器决定的。比如你使用了Cost Base OptimizerHilfsindizes. Wenn wir einen
Hilfsindex erstellen, ist sein Blatt Knoten speichern nur eigenen Wert und Wert des Primärschlüsselindex. Das heißt, wenn wir alle Daten über den Hilfsindex abfragen, suchen wir zuerst den Primärschlüsselwert im Hilfsindex und gehen dann zum Primärindex SchlüsselindexIm Inneren finden Sie relevante <code>Daten. Dieser Vorgang heißt table return
rowid Was tun, wenn kein Primärschlüsselindex vorhanden ist?
Es gibt keinen Primärschlüssel, aber einen eindeutigen Schlüssel, der nicht null ist. Dann wird ein Clustered-Index basierend auf diesem Schlüssel erstellt.
Wenn Sie über keines der oben genannten verfügen, machen Sie sich keine Sorgen, innodb verwaltet etwas namens
rowid und erstellt darauf basierend einen Clustered Indexdiese ID
Wie der Index funktioniert Nachdem ich herausgefunden habe, was ein Index ist und wie seine Struktur ist.
Werfen wir einen Blick darauf, wann wir Indizes verwenden müssen. Wenn wir diese verstehen, können wir korrekte und effiziente Indizes erstellen. Es besteht keine Notwendigkeit, Indizes zu erstellen, wenn die Streuung gering ist, das heißt, wenn die Daten nicht sehr unterschiedlich sind , es ist nicht erforderlich, einen Index zu erstellen. (Aufgrund der Indexerstellung sind die meisten Daten in InnoDB bei der Abfrage gleich. Wenn es keinen Unterschied zwischen dem Index und der gesamten Tabelle gibt, werde ich direkt die gesamte Tabelle abfragen). Zum Beispiel das Feld „Geschlecht“. Dadurch wird viel Speicherplatz verschwendet.
🎜🎜Gemeinsamer Feldindex, wie z. B. idx(name, class_name)🎜🎜🎜Bei der Ausführung von select * from stu where class_name = xx and name = lzw auch Abfrage Der Index idx kann verwendet werden, da der Optimierer SQL auf name = lzw und class_name = xx optimiert. 🎜🎜Wenn Sie benötigen, wählen Sie ··· wobei name = ist lzw, es ist nicht erforderlich, einen separaten name-Index zu erstellen, der idx-Index wird direkt verwendet🎜🎜abdeckender Index. Wenn alle Daten, die wir dieses Mal abfragen, alle im Index enthalten sind, besteht keine Notwendigkeit, zur Abfrage zur Tabelle zurückzukehren. Zum Beispiel: select class_name from stu where name =lzw🎜🎜🎜🎜index_condition_pushdown)🎜🎜🎜Es gibt so ein SQL, select * from stu where name = lzw und class_name wie '%xx'🎜🎜Wenn es keinen Indexbedingungs-Pushdown gibt, weil darauf die Abfragebedingung von wie '%xx' folgt, also hier ist der erste Verwenden Sie gemäß name den idx-Joint-Index, um mehrere Daten abzufragen, und kehren Sie dann zur Tabelle zurück, um Vollständige Zeilendaten. Führen Sie dann eine ähnliche Filterung auf der Serverebene durch, um die Daten zu finden. 🎜🎜Wenn vorhanden, filtern Sie diese direkt auf der Engine-Ebene , was dem Filtern der Serverebenecode> entspricht. Dieser Filtervorgang wird auf die Engine-Ebene verschoben. Wie im Bild gezeigt: 🎜🎜🎜 🎜
🎜Hinweise zur Indizierung
🎜🎜 Wenn „Where“, „Order“ und „Join“ häufig verwendet werden, können Felder mit einem hohen Streuungsgrad hinzugefügt werden, um einen Index zu erstellen. Der gemeinsame Index stellt die Felder mit einem hohen Streuungsgrad an die erste Stelle (weil Es wird zunächst anhand des ersten Felds abgeglichen, wodurch sich der Speicherort der Daten schnell ermitteln lässt ist voll, ein erneutes Einfügen führt zu Seitenteilungen) 🎜🎜Verwendung wie Indizes werden nicht verwendet, wenn Ersetzung, Summe, Anzahl und andereFunktionen verwendet werden, sodass keine zusätzlichen Funktionen erstellt werden müssen 🎜🎜 Wenn eine implizite Konvertierung erfolgt, z. B. die Konvertierung von Zeichenfolgen in int, sind keine Indizes erforderlich 🎜🎜Ein außergewöhnlich langes Feld, Sie können die ersten paar Ziffern abfangen, um einen Index zu erstellen (Sie können select count(distinct left(name, 10) verwenden ))/count(*), um die Streuung zu sehen und zu entscheiden, wie die ersten paar Ziffern extrahiert werden) 🎜- 🎜Tipps: Bei der Ausführung einer SQL kann nicht genau gesagt werden, ob sie verwendet werden kann Schließlich wird das alles vom
Optimierer entschieden. Wenn Sie beispielsweise den kostenbasierten Optimierer Cost Base Optimizer verwenden, verwenden Sie die Optimierung mit den niedrigsten Kosten. 🎜🎜🎜Nachdem wir den Index verstanden haben, können wir die Kopie von Lock Chapter öffnen. 🎜🎜Eine weitere wunderschöne Trennlinie.🎜🎜🎜Lock Chapter : 🎜- Atomizität (implementiert durch Rückgängig-Protokoll)
- Konsistenz
- Isolation
- Haltbarkeit (Absturzwiederherstellung, Redo-Protokoll + Doppelschreibimplementierung)
Lesekonsistenzprobleme sollten durch die Transaktionsisolationsstufe der Datenbank (SQL92-Standard) gelöst werden.
Prämisse in einer Transaktion:
- Dirty Read (Daten lesen, die andere nicht festgeschrieben haben, und dann hat jemand anderes sie zurückgesetzt)
- Nicht wiederholbares Lesen (die Daten zum ersten Mal lesen und dann jemand anderes geändert haben). die Festschreibung, und lesen Sie es erneut und lesen Sie die Daten, die andere festgeschrieben haben)
- Phantomlesung (Lesen Sie während der Bereichsabfrage die neu hinzugefügten Daten durch andere)
SQL92-Standardbestimmungen: (Die Parallelität nimmt von links nach rechts ab)

- Tipps: In Innodb kann der Phantom-Read von Repeatable Read nicht existieren, da er ihn selbst löst
LBCC (Lock Based Concurrency Control) Fügen Sie vor dem Lesen eine Sperre hinzu, dies kann jedoch zu Leistungsproblemen führen => Das Sperren beim Lesen verhindert das Lesen und Schreiben anderer Transaktionen. Ja, die Leistung ist gering.
MVCC (Multi Version Concurrency Control) zeichnet auf Der Snapshot wird beim Lesen angezeigt, und andere können den Snapshot lesen => Leistungsverbrauch und Speicherverbrauch
- Diese beiden Lösungen werden in Innodb zusammen verwendet. Hier ist eine kurze Erklärung der MVCC-Implementierung von
RR. Der Anfangswert der Rollback-ID in der Abbildung sollte nicht 0, sondern NULL sein. Der Einfachheit halber wird er als 0 -

RCs MVCC-Implementierung erstellt eine Version für mehrere Lesevorgänge derselben Transaktion und RR erstellt eine Version für alle Lesevorgänge derselben TransaktionRR 的 MVCC实现,图中 回滚id 初始值不应该为0而是NULL,这里为了方便写成0

-
RC的MVCC实现是对 同一个事务的多个读 创建一个版本而RR 是 同一个事务任何一条都创建一个版本
通过MVCC与LBCC的结合,InnoDB能解决对于不加锁条件下的 幻读的情况。而不必像 Serializable 一样,必须让事务串行进行,无任何并发。
下面我们来深入研究一下InnoDB锁是如何实现 RR 事务隔离级别的
锁深入 MVCC在Innodb的实现
一、Innodb 的锁
- Shared and Exclusive Locks 共享和排它锁 =>(S、X)
- Intention Locks 意向锁 => 这里指的是两把锁,其实就是
表级别的 共享和排它锁 => (IS、IX)
上面这四把锁是最基本锁的类型
- Record Locks 记录锁
- Gap Locks 间隙锁
- Next-key Locks 临锁
这三把锁,理解成对于上面四把锁实现的三种算法方式,我们这里暂且把它们称为:高阶锁
- Insert Intention Locks 插入锁
- AUTO-INC Locks 自增键锁
- Predicate Locks for Spatial Indexes 专用于给Spatial Indexes用的
上面三把是额外扩展的锁
二、读写锁深入解释
- 要使用共享锁,在语句后面加上
lock in share mode。排它锁默认Insert、Update、Delete会使用。显示使用在语句后加for update。 - 意向锁都是由数据库自己维护的。(主要作用是给表
打一个标记,记录这个表是否被锁住了) => 如果没有这个锁,别的事务想锁住这张表的时候,就要去全表扫描是否有锁,效率太低。所以才会有意向锁的存在。
补充:Mysql中锁,到底锁的是什么
锁的是索引,那么这个时候可能有人要问了:那如果我不创建索引呢?
索引的存在,我们上面讲过了,这里再回顾一下,有下面几种情况
- 你建了一个 Primary key, 就是聚集索引 (存储的是
完整的数据) - 没有主键,但是有一个 Unique key 而是都不是 null的,则会根据这个 key来创建
聚簇索引 - 那上面两种都没有呢,别担心,innodb自己维护了一个叫
rowid的东西,根据这个id来创建聚簇索引
所以一个表里面,必然会存在一个索引,所以锁当然总有索引拿来锁住了。
当要给一张你没有显示创建索引的表,进行加锁查询时,数据库其实是不知道到底要查哪些数据的,整张表可能都会用到。所以索性就锁整张表
LBCC kann InnoDB das Problem des Phantomlesens unter keine Sperrung-Bedingungen lösen. Anstatt wie Serialisierbar zu sein, muss die Transaktion seriell sein und ohne jegliche Parallelität durchgeführt werden. 🎜🎜Lassen Sie uns eine detaillierte Untersuchung darüber durchführen, wie InnoDB lock die Transaktionsisolationsstufe RR implementiert. 🎜Lock dringt tief in MVCC ein in der Innodb-Implementierung🎜1. Innodb-Sperren🎜🎜🎜Gemeinsame und exklusive Sperren => (S, X) 🎜🎜Intention-Sperren => hier Es bezieht sich auf zwei Sperren, bei denen es sich tatsächlich um gemeinsame und exklusive Sperren auf Tabellenebene => (IS, IX) handelt. 🎜🎜🎜Die oben genannten vier Sperren sind Die grundlegendsten Arten von Sperren🎜🎜Datensatzsperren Datensatzsperren🎜🎜Lückensperren Lückensperren🎜🎜Next-Key-Sperren Next-Key-Sperren🎜🎜🎜Diese drei Sperren werden als die oben genannten drei Algorithmusmethoden verstanden implementiert durch Four Locks werden hier vorübergehend genannt: High-order locks🎜🎜Intention Locks Insert locks🎜🎜 AUTO-INC Locks 🎜🎜 Prädikatsperren für räumliche Indizes 🎜🎜🎜Die oben genannten drei sind zusätzliche erweiterte Sperren🎜 2. Lesen und schreiben Ausführliche Erläuterung der Sperren🎜🎜🎜Um gemeinsame Sperren zu verwenden, fügen Sie im Freigabemodus sperren nach der Anweisung. Standardmäßig werden exklusive Sperren Einfügen, Aktualisieren, Löschen verwendet. Anzeige mit for update nach der Anweisung. 🎜🎜Absichtssperren werden von der Datenbank selbst verwaltet. (Die Hauptfunktion besteht darin, die Tabelle Ergänzung: Was ist die Sperre in MySQL?
🎜Die Sperre ist der Index, daher könnte sich zu diesem Zeitpunkt jemand fragen: Was ist, wenn ich keine erstelle? Index? Wollstoff? 🎜🎜Über die Existenz eines Index haben wir oben gesprochen. Sehen wir uns das hier an. Es gibt die folgenden Situationen: 🎜🎜🎜Sie haben einen Primärschlüssel erstellt, bei dem es sich um einen Clustered-Index handelt (der vollständige Datenspeichert). >) 🎜🎜Es gibt keinen Primärschlüssel, aber einen eindeutigen Schlüssel. Wenn keiner von beiden null ist, wird ein gruppierter Index basierend auf diesem Schlüssel erstellt. 🎜🎜Wenn keiner der oben genannten Schlüssel vorhanden ist, Keine Sorge, innodb verwaltet es selbst. Es gibt etwas namens rowid und ein clustered index wird basierend auf dieser ID erstellt 🎜🎜🎜Es muss also einen Index geben in einer Tabelle, also gibt es natürlich immer einen Index, der die Sperre übernimmt. Kommen Sie und sperren Sie sie. 🎜🎜Wenn Sie eine gesperrte Abfrage für eine Tabelle durchführen möchten, für die Sie nicht explizit einen Index erstellt haben, weiß die Datenbank tatsächlich nicht, welche Daten überprüft werden sollen Tabelle Kann verwendet werden. Also einfach die gesamte Tabelle sperren. 🎜- Wenn Sie beispielsweise eine Schreibsperre zum
Hilfsindex hinzufügen, wählen Sie * aus, wobei name = 'xxx' für die Aktualisierung und schließlich kehren Sie zur Tabelle zurück code>, um die Primärschlüsselinformationen zu überprüfen. Daher sperren wir zu diesem Zeitpunkt zusätzlich zum Sperren des <code>Hilfsindex auch den Primärschlüsselindex
3. Ausführliche Erklärung von Sperren höherer Ordnung
辅助索引加写锁,比如select * from where name = ’xxx‘ for update 最后要回表查主键上的信息,所以这个时候除了锁辅助索引还要锁主键索引三、高阶锁深入解释
首先上三个概念,有这么一组数据:主键是 1,3,6,9
在存储时候有如下:x 1 x 3 x x 6 x x x 9 x···
记录锁,锁的是每个记录,也就是 1,3,6,9
间隙锁,锁的是记录间隙,每个 x,(-∞,1), (1,3), (3,6), (6,9), (9,+∞)
临锁,锁的是 (-∞,1], (1,3], (3,6], (6,9], (9,+∞] 左开右闭的区间
首先这三种锁都是 排它锁, 并且 临键锁 = 记录锁 + 间隙锁
- 当
select * from xxx where id = 3 for update 时,产生记录锁
- 当
select * from xxx where id = 5 for update 时,产生间隙锁 => 锁住了(3,6),这里要格外注意一点:间隙锁之间是不冲突的。
- 当
select * from xxx where id = 5 for update 时,产生临键锁 => 锁住了(3,6], mysql默认使用临键锁,如果不满足 1 ,2 情况 则他的行锁的都是临键锁
- 回到开始的问题,在这里
Record Lock 行锁防止别的事务修改或删除,Gap Lock 间隙锁防止别的事务新增,Gap Lock 和 Record Lock结合形成的Next-Key锁共同解决RR级别在写数据时的幻读问题。
说到了锁那么必然逃不过要说一下死锁
发生死锁后的检查
-
show status like 'innodb_row_lock_%'
- Innodb_row_lock_current_waits 当前正在有多少等待锁
- Innodb_row_lock_time 一共等待了多少时间
- Innodb_row_lock_time_avg 平均等多少时间
- Innodb_row_lock_time_max 最大等多久
- Innodb_row_lock_waits 一共出现过多少次等待
-
select * from information_schema.INNODB_TRX 能查看到当前正在运行和被锁住的事务
-
show full processlist = select * from information_schema.processlist 能查询出是 哪个用户 在哪台机器host的哪个端口上 连接哪个数据库 执行什么指令 的 状态与时间
死锁预防
- 保证访问数据的顺序
- 避免where的时候不用索引(这样会锁表,不仅死锁更容易产生,而且性能更加低下)
- 一个非常大的事务,拆成多个小的事务
- 尽量使用等值查询(就算用范围查询也要限定一个区间,而不要只开不闭,比如 id > 1 就锁住后面所有)
优化篇
分库分表
动态选择数据源
Tabellenebene => (IS, IX) handelt. 🎜🎜🎜Die oben genannten vier Sperren sind Die grundlegendsten Arten von Sperren🎜- 🎜Datensatzsperren Datensatzsperren🎜🎜Lückensperren Lückensperren🎜🎜Next-Key-Sperren Next-Key-Sperren🎜🎜🎜Diese drei Sperren werden als die oben genannten drei Algorithmusmethoden verstanden implementiert durch
- Wenn Sie beispielsweise eine Schreibsperre zum
Hilfsindexhinzufügen,wählen Sie * aus, wobei name = 'xxx' für die Aktualisierungund schließlichkehren Sie zur Tabelle zurück code>, um die Primärschlüsselinformationen zu überprüfen. Daher sperren wir zu diesem Zeitpunkt zusätzlich zum Sperren des <code>Hilfsindexauch denPrimärschlüsselindex - 当
select * from xxx where id = 3 for update时,产生记录锁 - 当
select * from xxx where id = 5 for update时,产生间隙锁 => 锁住了(3,6),这里要格外注意一点:间隙锁之间是不冲突的。 - 当
select * from xxx where id = 5 for update时,产生临键锁 => 锁住了(3,6], mysql默认使用临键锁,如果不满足 1 ,2 情况 则他的行锁的都是临键锁
Four Locks werden hier vorübergehend genannt: High-order locks🎜- 🎜Intention Locks Insert locks🎜🎜 AUTO-INC Locks 🎜🎜 Prädikatsperren für räumliche Indizes 🎜🎜🎜Die oben genannten drei sind zusätzliche erweiterte Sperren🎜
2. Lesen und schreiben Ausführliche Erläuterung der Sperren🎜🎜🎜Um gemeinsame Sperren zu verwenden, fügen Sie im Freigabemodus sperren nach der Anweisung. Standardmäßig werden exklusive Sperren Einfügen, Aktualisieren, Löschen verwendet. Anzeige mit for update nach der Anweisung. 🎜🎜Absichtssperren werden von der Datenbank selbst verwaltet. (Die Hauptfunktion besteht darin, die Tabelle Ergänzung: Was ist die Sperre in MySQL?
🎜Die Sperre ist der Index, daher könnte sich zu diesem Zeitpunkt jemand fragen: Was ist, wenn ich keine erstelle? Index? Wollstoff? 🎜🎜Über die Existenz eines Index haben wir oben gesprochen. Sehen wir uns das hier an. Es gibt die folgenden Situationen: 🎜🎜🎜Sie haben einen Primärschlüssel erstellt, bei dem es sich um einen Clustered-Index handelt (der vollständige Datenspeichert). >) 🎜🎜Es gibt keinen Primärschlüssel, aber einen eindeutigen Schlüssel. Wenn keiner von beiden null ist, wird ein gruppierter Index basierend auf diesem Schlüssel erstellt. 🎜🎜Wenn keiner der oben genannten Schlüssel vorhanden ist, Keine Sorge, innodb verwaltet es selbst. Es gibt etwas namens rowid und ein clustered index wird basierend auf dieser ID erstellt 🎜🎜🎜Es muss also einen Index geben in einer Tabelle, also gibt es natürlich immer einen Index, der die Sperre übernimmt. Kommen Sie und sperren Sie sie. 🎜🎜Wenn Sie eine gesperrte Abfrage für eine Tabelle durchführen möchten, für die Sie nicht explizit einen Index erstellt haben, weiß die Datenbank tatsächlich nicht, welche Daten überprüft werden sollen Tabelle Kann verwendet werden. Also einfach die gesamte Tabelle sperren. 🎜
3. Ausführliche Erklärung von Sperren höherer Ordnung
辅助索引加写锁,比如select * from where name = ’xxx‘ for update 最后要回表查主键上的信息,所以这个时候除了锁辅助索引还要锁主键索引三、高阶锁深入解释
首先上三个概念,有这么一组数据:主键是 1,3,6,9 在存储时候有如下:x 1 x 3 x x 6 x x x 9 x···
记录锁,锁的是每个记录,也就是 1,3,6,9
间隙锁,锁的是记录间隙,每个 x,(-∞,1), (1,3), (3,6), (6,9), (9,+∞)
临锁,锁的是 (-∞,1], (1,3], (3,6], (6,9], (9,+∞] 左开右闭的区间
首先这三种锁都是 排它锁, 并且 临键锁 = 记录锁 + 间隙锁
- 回到开始的问题,在这里
Record Lock 行锁防止别的事务修改或删除,Gap Lock 间隙锁防止别的事务新增,Gap Lock 和 Record Lock结合形成的Next-Key锁共同解决RR级别在写数据时的幻读问题。
说到了锁那么必然逃不过要说一下死锁
发生死锁后的检查
-
show status like 'innodb_row_lock_%'- Innodb_row_lock_current_waits 当前正在有多少等待锁
- Innodb_row_lock_time 一共等待了多少时间
- Innodb_row_lock_time_avg 平均等多少时间
- Innodb_row_lock_time_max 最大等多久
- Innodb_row_lock_waits 一共出现过多少次等待
-
select * from information_schema.INNODB_TRX能查看到当前正在运行和被锁住的事务 -
show full processlist=select * from information_schema.processlist能查询出是哪个用户在哪台机器host的哪个端口上连接哪个数据库执行什么指令的状态与时间
死锁预防
- 保证访问数据的顺序
- 避免where的时候不用索引(这样会锁表,不仅死锁更容易产生,而且性能更加低下)
- 一个非常大的事务,拆成多个小的事务
- 尽量使用等值查询(就算用范围查询也要限定一个区间,而不要只开不闭,比如 id > 1 就锁住后面所有)
优化篇
分库分表
动态选择数据源
编码层 -- 实现 AbstracRoutingDataSource => 框架层 -- 实现 Mybatis Plugin => 驱动层 -- Sharding-JDBC(配置多个数据源,根据自定义实现的策略对数据进行分库分表存储)核心流程,SQL解析=>执行优化=>SQL数据库路由=>SQL改变(比如分表,改表名)=>SQL执行=>结果归并) => 代理层 -- Mycat(将所有与数据库的连接独立出来。全部由Mycat连接,其他服务访问Mycat获取数据) => 服务层 -- 特殊的SQL版本
MYSQL如何做优化
说到底我们学习这么多知识都是为了能更好使用MYSQL,那就让我们来实操一下,建立一个完整的优化体系
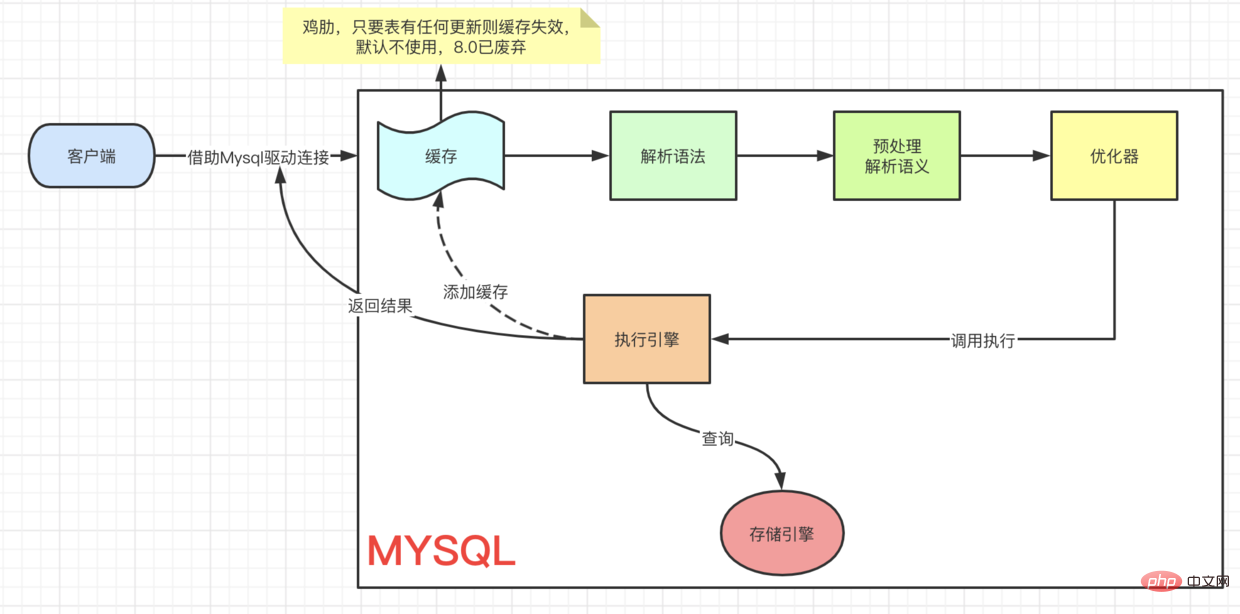
要想获得更好的查询性能,可以从这张查询执行过程入手
一、客户端连接池
添加连接池,避免每次都新建、销毁连接Lassen Sie uns zunächst über drei Konzepte sprechen. Es gibt einen solchen Datensatz: Der Primärschlüssel ist 1 , 3, 6, 9
Beim Speichern ist es wie folgt: x 1 x 3 x x 6 x x x 9 x...
Lückensperre, sperrt die Datensatzlücke, jedes x, (-∞,1), (1,3), (3,6), (6,9), (9,+∞ )
Beim Sperren sind die Sperren (-∞,1], (1,3], (3,6], (6,9], (9,+∞], die linksoffenen und rechtsgeschlossenen Intervalle
Zuallererst handelt es sich bei diesen drei Sperren um exklusive Sperren und temporäre Tastensperren = Datensatzsperren + Lückensperren
- 🎜Wenn
* aus xxx mit ID = 3 für die Aktualisierung ausgewählt wird , eine Datensatzsperre wird generiert🎜Wenn wähle * aus xxx, wobei die ID = 5 für die Aktualisierung ist, wird eine Lückensperre generiert => (3,6) ist gesperrt Besondere Aufmerksamkeit hier: Die Lückensperre Es gibt keinen Konflikt zwischen 🎜Wenn wähle * aus xxx, wobei die ID = 5 für die Aktualisierung ist, wird eine temporäre Tastensperre => , das standardmäßig von MySQL verwendet wird und die Bedingungen 1 und 2 nicht erfüllt sind, sind alle Zeilensperren temporäre Tastensperren Datensatzsperre ZeilensperreVerhindert das Ändern oder Löschen anderer Transaktionen, Gap Lock Lückensperre verhindert das Hinzufügen anderer Transaktionen, Gap Lock und Record Lock werden zu einem Formular kombiniert a Next-Key lockArbeiten Sie zusammen, um das Problem des Phantomlesens beim Schreiben von Daten auf RR-Ebene zu lösen Wenn es um Sperren geht, gibt es keinen Ausweg. Reden wir über Deadlock
Überprüfen Sie, nachdem ein Deadlock auftritt
- 🎜Status wie „innodb_row_lock_%“ anzeigen ninnodb_row_Lock_current_waits wartet derzeit auf Sperren 🎜innodb_row_lock_time, wie lange gewartet wurde 🎜innodb_row_lock_avg durchschnittliche Zeit 🎜innodb_ro Wie lang ist die maximale Wartezeit von w_lock_time_max 🎜innodb_row_lock_waits
select * from information_schema.INNODB_TRX kann die aktuell laufenden und gesperrten Transaktionen anzeigen 🎜vollständige Prozessliste anzeigen = select * from information_schema.processlist kann abfragen, welcher Benutzer sich an welchem Port auf welcher Maschine befindet host Welche Datenbank soll verbunden werden Welcher Befehl ausgeführt werden solls Status- und Zeit- 🎜Stellen Sie die Reihenfolge des Datenzugriffs sicher🎜Vermeiden Sie die Verwendung eines Index, wenn Sie angeben, wo (dies sperrt die Tabelle, nicht nur Deadlocks). tritt wahrscheinlicher auf, aber auch die Leistung ist geringer)🎜A Teilen Sie sehr große Transaktionen in mehrere kleine Transaktionen auf🎜 Versuchen Sie, eine entsprechende Abfrage zu verwenden (auch wenn Sie eine Bereichsabfrage verwenden, müssen Sie diese einschränken zu einem Intervall, anstatt es nur zu öffnen oder zu schließen, wenn id > 1, alle nachfolgenden sperren)
Optimierung
Unterdatenbank und Untertabelle
Dynamische Auswahl von Datenquellen
🎜Codierungsschicht – Implementierung von AbstractRoutingDataSource => Framework-Ebene – Implementierung des Mybatis-Plugins => Treiberschicht – Sharding-JDBC (mehrere Datenquellen konfigurieren, Daten in separaten Datenbanken und Tabellen gemäß benutzerdefinierten Implementierungsstrategien speichern), SQL-Analyse => SQL-Datenbank-Routing => Tabellen aufteilen und Tabellennamen ändern)=>SQL-Ausführung=>Ergebnisse zusammenführen) => Proxy-Schicht – Mycat (unabhängig von allen Verbindungen zur Datenbank. Alle Verbindungen werden von Mycat hergestellt und andere Dienste greifen auf Mycat zu, um Daten abzurufen) => Serviceschicht – spezielle SQL-Version🎜Wie man MYSQL optimiert
🎜Am Ende lernen wir so viel Wissen, um MYSQL besser nutzen zu können, also lasst uns üben es und etablieren Sie ein vollständiges Optimierungssystem. 🎜🎜 -11.png" data-width="800" data-height="600"/>🎜🎜Wenn Sie eine bessere Abfrageleistung erzielen möchten, können Sie diesemAbfrageausführungsprozessErste Schritte folgen🎜1. Client-Verbindungspool🎜Fügen Sie einen Verbindungspool hinzu, um zu vermeiden, dass jedes Mal Verbindungen erstellt und zerstört werden. Dann ist unser Verbindungspool nicht mehr vorhanden desto besser?
Interessierte Freunde können diesen Artikel lesen: Über die Poolgröße🎜🎜Ich fasse es grob zusammen:🎜- Unsere gleichzeitige Ausführung von SQL wird mit zunehmender Anzahl von Verbindungen nicht schneller. Warum? Wenn ich 10.000 Verbindungen gleichzeitig ausführen würde, wäre das nicht viel schneller als Ihre 10 Verbindungen? Die Antwort lautet: Nein, es ist nicht nur nicht schnell, sondern wird auch langsamer.
- Bei Computern wissen wir alle, dass nur
CPUtatsächlichThreadsausführen kann. Da das Betriebssystem dieTime-Slicing-Technologie verwendet, gehen wir davon aus, dass einCPU-Kernmehrere Threadsausführt.
CPU才能真正去执行线程。而操作系统因为用时间分片的技术,让我们以为一个CPU内核执行了多个线程。 - Bei Computern wissen wir alle, dass nur
- 但其实上一个
CPU在某个时间段只能执行一个线程,所以无论我们怎么增加并发,CPU还是只能在这个时间段里处理这么多数据。 - 那就算
CPU处理不了这么多数据,又怎么会变慢?因为时间分片,当多个线程看起来在"同时执行",其实他们之间的上下文切换十分耗时 - 所以,一旦线程的数量超过了CPU核心的数量,再增加线程数系统就只会更慢,而不是更快。
- 比如我们用的机械硬盘,我们要通过旋转,寻址到某个位置,再进行
I/O操作,这个时候,CPU就可以把时间,分片给其他线程,以提升处理效率和速度 - 所以,如果你用的是机械硬盘,我们通常可以多添加一些连接数,保持高并发
- 但如果你用的是 SSD 呢,因为
I/O等待时间非常短,所以我们就不能添加过多连接数
线程数 = ((核心数 * 2) + 有效磁盘数)。比如一台 i7 4core 1hard disk的机器,就是 4 * 2 + 1 = 9很多CPU计算和I/O的场景 比如:设置最大线程数等二、数据库整体设计方案
第三方缓存
如果并发非常大,就不能让他们全打到数据库上,在客户端连接数据库查询时,添加如Redis这种三方缓存
集群方式部署数据库
既然我们一个数据库承受不了巨大的并发,那为什么不多添加几台机器呢? 主从复制原理图
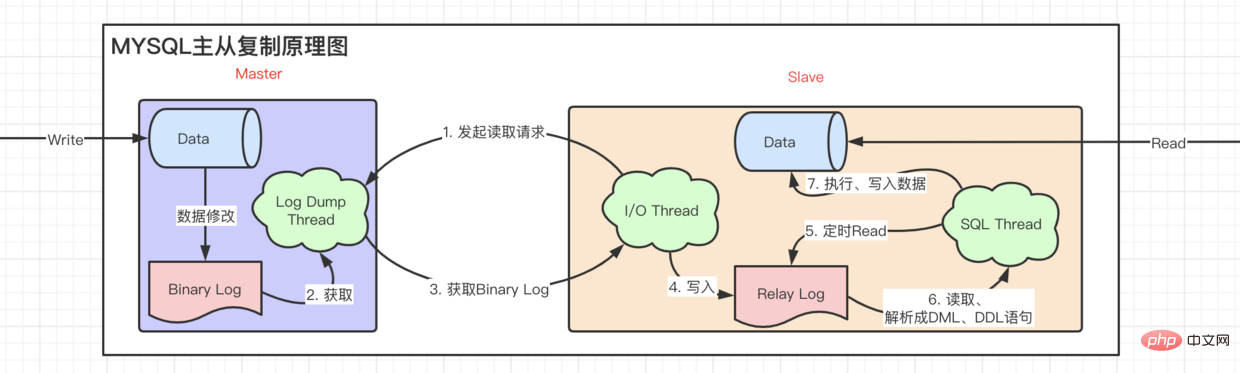
从图中我们不难看出、Mysql主从复制 读写分离 异步复制的特性。
- tips: 在把
Binary Log写入relay log之后,slave都会把最新读取到的Binary Log Position记录到master info上,下一次就直接从这个位置去取。
不同方式的主从复制
上面这种异步的主从复制,很明显的一个问题就是,更新不及时的问题。当写入一个数据后,马上有用户读取,读取的还是之前的数据,也就是存在着延时。
要解决延时的问题,就需要引入 事务
- 全同步复制,事务方式执行,主节点先写入,然后让所有slave写,必须要所有 从节点 把数据写完,才返回写成功,这样的话会大大影响写入的性能
- 半同步复制,只要有一个salve写入数据,就算成功。(如果需要半同步复制,主从节点都需要安装semisync_mater.so和 semisync_slave.so插件)
- GTID(global transaction identities)复制,主库并行复制的时候,从库也并行复制,解决主从同步复制延迟,实现自动的
failover动作,即主节点挂掉,选举从节点后,能快速自动避免数据丢失。
集群高可用方案
- 主从 HAPrxoy + keeplive
- NDB
- Glaera Cluster for MySQL
- MHA(Master-Mater replication manager for MySQL),MMM(MySQL Master High Available)
- MGR(MySQL Group Replication) => MySQL Cluster
分表
对数据进行分类划分,分成不同表,减少对单一表造成过多锁操作Aber tatsächlich kann die vorherige CPU nur einen Thread in einem bestimmten Zeitraum ausführen, also egal, wie wir uns steigern Parallelität, CPU kann in diesem Zeitraum immer noch nur eine bestimmte Menge Daten verarbeiten.
CPU dann langsamer werden, selbst wenn sie nicht so viele Daten verarbeiten kann? Aufgrund der Zeitaufteilung ist der Kontextwechsel zwischen ihnen tatsächlich sehr zeitaufwändig, wenn mehrere Threads scheinbar „gleichzeitig ausgeführt“ werden. code> li>🎜Sobald also die Anzahl der Threads die Anzahl der CPU-Kerne übersteigt, wird das System durch Erhöhen der Anzahl der Threads nur langsamer und nicht schneller. 🎜Natürlich ist dies nur der Hauptgrund. Die Festplatte wirkt sich auch auf die Geschwindigkeit aus und wirkt sich auch auf die Konfiguration unserer Verbindungsnummer aus. 🎜🎜Bei der von uns verwendeten mechanischen Festplatte müssen wir sie beispielsweise drehen, an einen bestimmten Ort adressieren und dann den I/O-Vorgang ausführen CPU kann Zeit sparen und auf andere Threads aufteilen, um die Verarbeitungseffizienz und -geschwindigkeit zu verbessern🎜Wenn Sie also eine mechanische Festplatte verwenden, können wir normalerweise weitere Verbindungen hinzufügen um eine hohe Parallelität aufrechtzuerhalten🎜Aber wenn Sie SSD verwenden, können wir nicht zu viele Verbindungen hinzufügen, da die I/O-Wartezeit sehr kurz ist li>🎜Bestanden Im Allgemeinen müssen Sie dieser Formel folgen: Anzahl der Threads = ((Anzahl der Kerne * 2) + Anzahl der effektiven Festplatten). Zum Beispiel ist eine i7 4core 1hard disk Maschine 4 * 2 + 1 = 9🎜Ich frage mich, ob Ihnen diese Formel bekannt ist. Sie gilt nicht nur für Datenbankverbindungen, sondern auch Anwendbar auf jedes Szenario mit viel CPU-Rechenleistung und E/A. Zum Beispiel: Festlegen der maximalen Anzahl von Threads usw.2. Gesamtentwurfsplan für die Datenbank
Drittanbieter-Cache
Wenn die Parallelität sehr groß ist, können wir nicht zulassen, dass alle davon betroffen sind Wenn der Client zur Abfrage eine Verbindung zur Datenbank herstellt, fügen Sie einen Drittanbieter-Cache hinzu, z. B. Redis🎜
Stellen Sie die Datenbank im Clustermodus bereit h4>
Da eine unserer Datenbanken einer großen Parallelität nicht standhalten kann, warum nicht noch ein paar weitere Maschinen hinzufügen? Master-Slave-Replikationsschema🎜
 🎜
🎜
Auf dem Bild können wir leicht erkennen, dass die MySQL-Master-Slave-Replikation Lese-Schreib-Trennungist > Asynchrone Replikation-Funktion. 🎜
- 🎜Tipps: Nachdem
Binary Log in Relay Log geschrieben wurde, schreibt Slave die zuletzt gelesene Binary Log Position code> wird in <code>master info aufgezeichnet und beim nächsten Mal direkt von dieser Position abgerufen.
Verschiedene Arten der Master-Slave-Replikation
Die obige asynchrone Master-Slave-Replikation ist sehr Ein offensichtliches Problem besteht darin, dass Updates nicht rechtzeitig erfolgen. Wenn ein Datenelement geschrieben und sofort von einem Benutzer gelesen wird, handelt es sich bei den gelesenen Daten immer noch um die vorherigen Daten, was bedeutet, dass es zu einer Verzögerung kommt.
Um das Verzögerungsproblem zu lösen, ist es notwendig, eine vollständig synchrone Replikation einzuführen, die zuerst im Transaktionsmodus ausgeführt wird und dann alle Slave-Knoten schreiben Beim Schreiben der Daten wird ein erfolgreicher Schreibvorgang zurückgegeben, was sich stark auf die Schreibleistung auswirkt.🎜Halbsynchrone Replikation gilt als erfolgreich, solange eine Salbe zum Schreiben von Daten vorhanden ist. (Wenn eine halbsynchrone Replikation erforderlich ist, müssen sowohl der Master- als auch der Slave-Knoten die Plug-Ins semisync_mater.so und semisync_slave.so installieren.) 🎜GTID-Replikation (Global Transaction Identities), wenn die Master-Bibliothek parallel repliziert Die Slave-Bibliothek repliziert auch parallel und löst so das Problem des Masters. Durch die synchrone Replikationsverzögerung wird eine automatische Failover-Aktion implementiert, d. h. wenn der Master-Knoten auflegt und der Slave-Knoten ausgewählt wird, werden Daten übertragen Verluste können schnell und automatisch vermieden werden.
Cluster-Hochverfügbarkeitslösung
🎜🎜Master-Slave HAProxoy + Keeplive🎜NDB🎜Glaera-Cluster für MySQL 🎜MHA (Master-Mater-Replikationsmanager für MySQL), MMM (MySQL Master High Available) 🎜MGR (MySQL Group Replication) => MySQL-ClusterTabellenaufteilung
Kategorisiert und unterteilt Daten in verschiedene Tabellen, um übermäßige Sperrvorgänge zu reduzieren, die sich auf die Leistung einer einzelnen Tabelle auswirken🎜
Tabellenstruktur
- Entwerfen Sie angemessene Feldtypen.
- Entwerfen Sie angemessene Feldlängen >long_query_time s SQL wird protokolliert.
Sie können
mysqldumpslow /var/lib/mysql/mysql-slow.logverwenden. Es gibt viele Plug-Ins, die eine elegantere Analyse ermöglichen, daher werde ich hier nicht auf Details eingehen.
SQL erklären und analysieren
Jedes SQL sollte nach dem Schreiben explain sein
1. Laufwerkstabelle – wie Missbrauch left/right join导致性能低下
- 使用
left/right join会直接指定驱动表,在MYSQL中,默认使用Nest loop join进行表关联(即通过驱动表的结果集作为循环基础数据,然后通过此集合中的每一条数据筛选下一个关联表的数据,最后合并结果,得出我们常说的临时表)。 - 如果
驱动表的数据是百万千万级别的,可想而知这联表查询得有多慢。但是反过来,如果以小表作为驱动表,借助千万级表的索引查询就能变得很快。 - 如果你不确定到底该用谁来作为
驱动表,那么请交给优化器来决定,比如:select xxx from table1, table2, table3 where ···,优化器会将查询记录行数少的表作为驱动表。 - 如果你就是想自己指定
驱动表,那么请拿好Explain武器,在Explain的结果中,第一个就是基础驱动表 - 排序。同样的,对不同
表排序也是有很大的性能差异,我们尽量对驱动表进行排序,而不要对临时表,也就是合并后的结果集进行排序。即执行计划中出现了using temporary,就需要进行优化。
2. 执行计划各参数含义
- select_type(查询的类型):
普通查询和复杂查询(联合查询、子查询等)-
SIMPLE,查询不包含子查询或者UNION -
PRIMARY,如果查询包含复杂查询的子结构,那么就需要用到主键查询 -
SUBQUERY,在select或者where中包含子查询 -
DERIVED,在from中包含子查询 -
UNION RESULT,从union表查询子查询
-
- table 使用到的表名
- type(访问类型),找到所需行的方式,从上往下,查询速度
越来越快-
const或者system常量级别的扫描,查询表最快的一种,system是const的一种特殊情况(表中只有一条数据) -
eq_ref唯一性索引扫描 -
ref非唯一性索引扫描 -
range索引的范围扫描,比如 between、等范围查询 -
index(index full)扫描全部索引树 -
ALL扫描全表 -
NULL,不需要访问表或者索引
-
- possible_keys,给出使用哪个索引能找到表中的记录。这里被列出的索引
不一定使用 - key:到底
哪一个索引被真正使用到了。如果没有则为NULL - key_len:使用的索引所占用的字节数
- ref:哪个字段或者常数和
索引(key)一起被使用 - rows:一共扫描了多少行
- filtered(百分比):有多少数据在server层还进行了过滤
- Extra:额外信息
-
only index信息只需要从索引中查出,可能用到了覆盖索引,查询非常快 -
using where如果查询没有使用索引,这里会在server层过滤再使用where来过滤结果集 -
impossible where啥也没查出来 -
using filesort,只要没有通过索引来排序,而是使用了其他排序的方式就是 filesort -
using temporary(需要通过临时表来对结果集进行暂时存储,然后再进行计算。)一般来说这种情况都是进行了DISTINCT、排序、分组 -
using index condition索引下推,上文讲过,就是把server层这个过滤操作下推到引擎层
-
四、存储引擎
- 当仅仅是
插入与查询比较多的时候,可以使用MyISAM存储引擎 - 当只是使用临时数据,可以使用
memory - 当
插入、更新、查询等并发数很多时,可以使用InnoDB
Zusammenfassung
Antwort MYSQL-Optimierung auf fünf Ebenen, von oben nach unten
- SQL und Index
- Speicher-Engine und Tabellenstruktur
- Datenbankarchitektur
- MySQL-Konfiguration
- Hardware und Betriebssystem
Darüber hinaus ist die Datenabfrage langsam, daher sollten wir die Datenbank nicht einfach blind „optimieren“, sondern sie auf der Ebene der Geschäftsanwendung analysieren. Zum Beispiel Daten zwischenspeichern, Anfragen einschränken usw.
Bis zum nächsten Artikel
Verwandte kostenlose Lernempfehlungen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonEin Artikel, der Ihnen hilft, die zugrunde liegenden Prinzipien von MYSQL zu verstehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!