
Heim >Backend-Entwicklung >Python-Tutorial >So verwenden Sie das Requests-Paket von Python, um eine simulierte Anmeldung zu implementieren
So verwenden Sie das Requests-Paket von Python, um eine simulierte Anmeldung zu implementieren

- 不言Original
- 2018-05-02 14:22:202991Durchsuche
In diesem Artikel wird hauptsächlich die Verwendung des Requests-Pakets von Python zum Simulieren der Anmeldung ausführlich vorgestellt. Es hat einen gewissen Referenzwert.
Ich habe vor einiger Zeit gerne Python verwendet, um einige Seiten abzurufen. Spielen Sie, aber im Grunde verwenden sie get, um einige Seiten anzufordern und sie dann durch reguläre Regeln zu filtern.
Ich habe es heute ausprobiert und die Anmeldung auf meiner persönlichen Website simuliert. Auch die Entdeckung ist relativ einfach. Das Lesen dieses Artikels erfordert ein gewisses Verständnis des http-Protokolls und der http-Sitzungen.
Hinweis: Da es sich bei der simulierten Anmeldung um meine persönliche Website handelt, verwaltet der folgende Code die persönliche Website und das Kontokennwort.
Website-Analyse
Der wesentliche erste Schritt für Crawler ist die Analyse der Zielwebsite. Hier nutzen wir zur Analyse die Entwicklertools von Google Chrome.
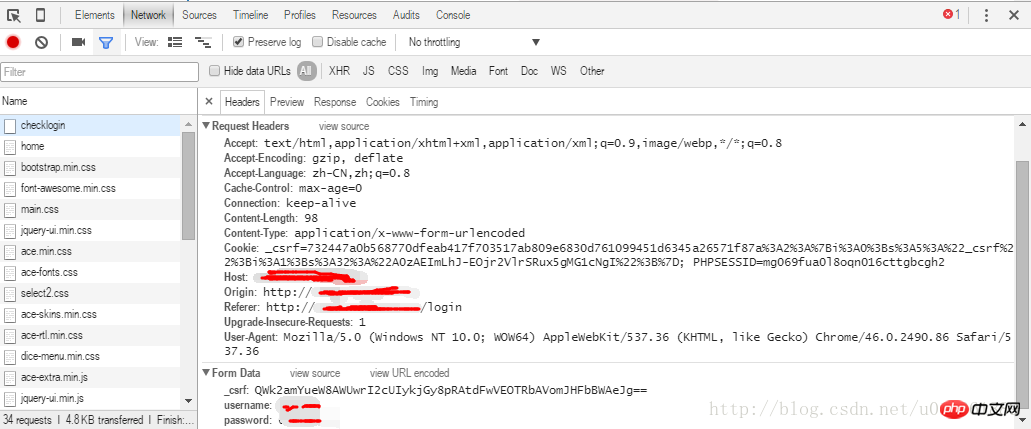
Über Login abrufen und eine solche Anfrage sehen.
Der obere Teil ist der Anforderungsheader und der untere Teil sind die von der Anforderung übergebenen Parameter. Wie aus dem Bild ersichtlich ist, übermittelt die Seite drei Parameter über das Formular. Dies sind jeweils _csrf, usermane und password.
Das CSRF soll domänenübergreifende Skriptfälschungen verhindern. Das Prinzip ist sehr einfach, das heißt, für jede Anfrage generiert der Server einen verschlüsselten String. Platzieren Sie es in einem versteckten Eingabeformular. Wenn Sie eine weitere Anfrage stellen, übergeben Sie diese Zeichenfolge gemeinsam, um zu überprüfen, ob es sich um eine Anfrage desselben Benutzers handelt.
Unsere Codelogik ist also da. Fordern Sie zunächst eine Anmeldeseite an. Analysieren Sie dann die Seite und rufen Sie die CSRF-Zeichenfolge ab. Abschließend werden diese Zeichenfolge und das Kontokennwort zur Anmeldung an den Server übergeben.
Erster Code
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import requests
import re
# 头部信息
headers = {
'Host':"localhost",
'Accept-Language':"zh-CN,zh;q=0.8",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Connection':"keep-alive",
'Referer':"http://localhost/login",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"
}
# 登陆方法
def login(url,csrf):
data = {
"_csrf" : csrf,
"username": "xiedj",
"password": "***"
}
response = requests.post(url, data=data, headers=headers)
return response.content
# 第一次访问获取csrf值
def get_login_web(url):
page = requests.get('http://localhost/login')
reg = r'<meta name="csrf-token" content="(.+)">'
csrf = re.findall(reg,page.content)[0]
login_page = login(url,csrf)
print login_page
if __name__ == "__main__":
url = "http://localhost/login/checklogin"
get_login_web(url)
Der Code scheint kein Problem zu haben. Bei der Ausführung ist jedoch ein Fehler aufgetreten. Nach der Überprüfung liegt der Grund für den Fehler darin, dass die CSRF-Überprüfung fehlgeschlagen ist!
Nachdem ich wiederholt bestätigt hatte, dass die erhaltene CSRF-Datei und die für die Anmeldung angeforderte CSRF-Zeichenfolge in Ordnung waren, fiel mir eine Frage ein.
Wenn Sie die Fehlerursache immer noch nicht kennen, können Sie hier innehalten und über ein Problem nachdenken. „Woher weiß der Server, dass die erste Anfrage zum Abrufen der CSRF und die zweite Post-Login-Anfrage vom selben Benutzer stammen?“
An diesem Punkt sollte klar sein, ob Sie sich erfolgreich anmelden möchten. Sie müssen herausfinden, wie Sie den Dienst davon überzeugen können, dass beide Anforderungen vom selben Benutzer stammen. Sie müssen hier eine HTTP-Sitzung verwenden (wenn Sie nicht sicher sind, können Sie Baidu selbst verwenden, hier ist eine kurze Einführung).
Das http-Protokoll ist ein zustandsloses Protokoll. Um dieses Zustandslose zustandsbehaftet zu machen, wurden Sitzungen eingeführt. Um es einfach auszudrücken: Zeichnen Sie diesen Status während der Sitzung auf. Wenn ein Benutzer zum ersten Mal einen Webdienst anfordert, generiert der Server eine Sitzung, um die Informationen des Benutzers zu speichern. Gleichzeitig wird bei der Rückkehr zum Nutzer die Session-ID in Cookies gespeichert. Wenn der Benutzer erneut eine Anfrage stellt, bringt der Browser dieses Cookie mit. Daher kann der Server erkennen, ob mehrere Anfragen für denselben Benutzer gelten.
Daher muss unser Code diese Sitzungs-ID erhalten, wenn er die erste Anfrage stellt. Übergeben Sie diese Sitzungs-ID zusammen mit der zweiten Anfrage. Das Tolle an Anfragen ist, dass Sie dieses Sitzungsobjekt mit einer einfachen request.Session() verwenden können.
Zweiter Code
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import requests
import re
# 头部信息
headers = {
'Host':"localhost",
'Accept-Language':"zh-CN,zh;q=0.8",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Connection':"keep-alive",
'Referer':"http://localhost/login",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"
}
# 登陆方法
def login(url,csrf,r_session):
data = {
"_csrf" : csrf,
"username": "xiedj",
"password": "***"
}
response = r_session.post(url, data=data, headers=headers)
return response.content
# 第一次访问获取csrf值
def get_login_web(url):
r_session = requests.Session()
page = r_session.get('http://localhost/login')
reg = r'<meta name="csrf-token" content="(.+)">'
csrf = re.findall(reg,page.content)[0]
login_page = login(url,csrf,r_session)
print login_page
if __name__ == "__main__":
url = "http://localhost/login/checklogin"
get_login_web(url)
Seite nach Anmeldung erfolgreich abgerufen
Sie können dem Code entnehmen, dass nach dem Starten des Sitzungsobjekts durch „requests.Session()“ die zweite Anforderung automatisch die letzte Sitzungs-ID zusammen weitergibt.
Verwandte Empfehlungen:
So verwenden Sie Python zum Exportieren von Excel-Diagrammen und zum Exportieren als Bilder
Analysieren Sie die Öffnungsfunktion mit Python Gründe für den Fehler No Such File or DIr
Das obige ist der detaillierte Inhalt vonSo verwenden Sie das Requests-Paket von Python, um eine simulierte Anmeldung zu implementieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!