
Heim >Technologie-Peripheriegeräte >KI >LLMs für die Codierung im Jahr 2024: Preis, Leistung und der Kampf um das Beste
LLMs für die Codierung im Jahr 2024: Preis, Leistung und der Kampf um das Beste

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2025-02-26 00:46:10391Durchsuche
Die sich schnell entwickelnde Landschaft großer Sprachmodelle (LLMs) für die Codierung bietet Entwicklern eine Fülle von Auswahlmöglichkeiten. Diese Analyse vergleicht Top-LLMs, die über öffentliche APIs zugänglich sind und sich auf ihre kodierenden Fähigkeiten konzentrieren, gemessen an Benchmarks wie ELO-Scores von Humaneval und realer Welt. Unabhängig davon, ob Sie persönliche Projekte erstellen oder KI in Ihren Workflow integrieren, ist es entscheidend für die fundierte Entscheidungsfindung, die Stärken und Schwächen dieser Modelle zu verstehen.
Die Herausforderungen des LLM -Vergleichs:
direkter Vergleich ist aufgrund häufiger Modellaktualisierungen (selbst kleinere Auswirkungen auf die Leistung), die inhärente Stochastizität von LLMs, die zu inkonsistenten Ergebnissen und potenzielle Verzerrungen bei der Konstruktion und Berichterstattung von Benchmarks führt. Diese Analyse stellt einen Best-Effort-Vergleich dar, der auf aktuell verfügbaren Daten basiert.
Bewertungsmetriken: Humaner- und ELO -Scores:
Diese Analyse verwendet zwei Schlüsselmetriken:
- Humaneropfer: Ein Benchmark -Bewertungscode -Korrektheit und -Funktionalität basierend auf bestimmten Anforderungen. Es misst den Code-Abschluss und die Fähigkeiten zur Problemlösung.
- ELO-Scores (Chatbot Arena-nur Codierung): Abgeleitet von Kopf-an-Kopf-LLM-Vergleiche, die von Menschen beurteilt wurden. Höhere ELO -Werte weisen auf eine überlegene relative Leistung hin. Eine Differenz von 100 Punkten deutet auf eine Gewinnrate von ~ 64% für das höher bewertete Modell hin.
Leistungsübersicht:

OpenAIS -Modelle übertreffen sowohl die Humaner- als auch die ELO -Rangliste und zeigen überlegene Codierungsfunktionen. Das Modell o1-mini übertrifft das größere O1 -Modell in beiden Metriken überraschend. Die besten Modelle anderer Unternehmen zeigen eine vergleichbare Leistung, obwohl sie OpenAI zurückblicken.

Benchmark vs. reale Leistungsdiskrepanzen:

Eine signifikante Missverhältnis zwischen Humaner- und ELO -Ergebnissen. Einige Modelle, wie Mistrals Mistral Large , können mit Humaner besser als in der realen Verwendung (potenzielle Überanpassung), während andere wie Googles Gemini 1.5 Pro den entgegengesetzten Trend zeigen (Googles
Gemini 1.5 Pro Unterschätzung in Benchmarks). Dies unterstreicht die Grenzen, die sich ausschließlich auf Benchmarks verlassen. Alibaba- und Mistral -Modelle überwachen häufig Benchmarks, während die Modelle von Google aufgrund ihrer Schwerpunkte auf faire Bewertung unterschätzt werden. Meta-Modelle zeigen ein konsistentes Gleichgewicht zwischen Benchmark und realer Leistung. 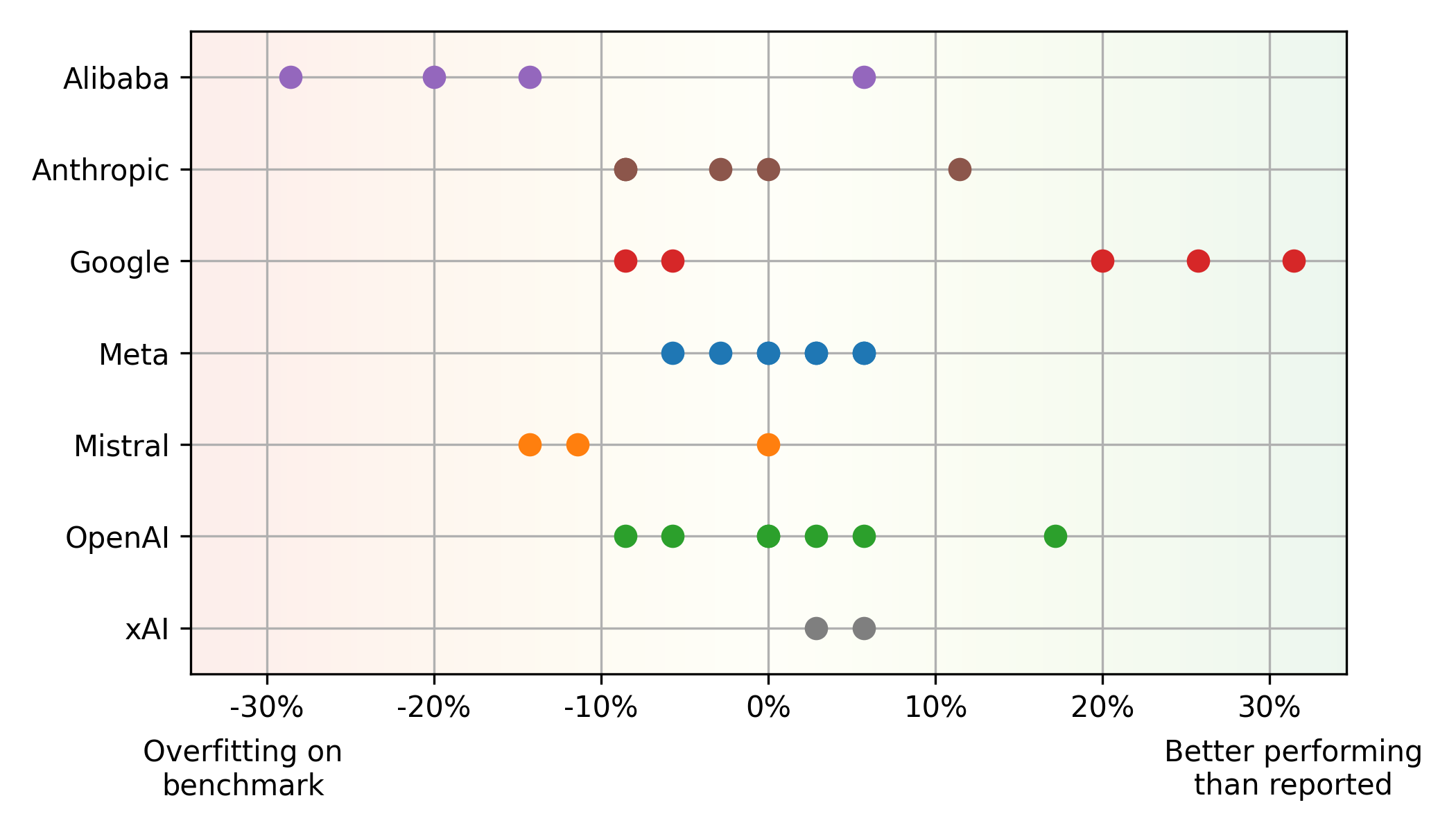
Ausgleich von Leistung und Preis:


Die Modelle von Pareto Front (optimaler Leistung und Preis) verfügt hauptsächlich um OpenAI- (hohe Leistung) und Google (Value for Money). Die Open-Source-Lama-Modelle von Meta, die auf dem Durchschnitt der Cloud-Anbieter basiert, zeigen ebenfalls einen Wettbewerbswert.
Zusätzliche Erkenntnisse:



llms verbessern die Leistung und die Kostenverringerung konsequent. Proprietäre Modelle behalten die Dominanz bei, obwohl Open-Source-Modelle aufholen. Auch kleinere Aktualisierungen beeinflussen die Leistung und/oder die Preisgestaltung erheblich.
Schlussfolgerung:
Die Codierungs -LLM -Landschaft ist dynamisch. Entwickler sollten die neuesten Modelle regelmäßig bewerten, unter Berücksichtigung von Leistung und Kosten. Das Verständnis der Grenzen von Benchmarks und der Priorisierung verschiedener Bewertungsmetriken ist entscheidend, um fundierte Entscheidungen zu treffen. Diese Analyse liefert eine Momentaufnahme des aktuellen Zustands, und eine kontinuierliche Überwachung ist wichtig, um in diesem sich schnell entwickelnden Bereich voranzukommen.
Das obige ist der detaillierte Inhalt vonLLMs für die Codierung im Jahr 2024: Preis, Leistung und der Kampf um das Beste. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr