
Heim >Technologie-Peripheriegeräte >KI >Die Mathematik hinter dem Kontextlernen
Die Mathematik hinter dem Kontextlernen

- 王林Original
- 2025-02-26 00:03:10644Durchsuche
In-Context Learning (ICL), ein wichtiges Merkmal der modernen Großsprachenmodelle (LLMs), ermöglicht Transformatoren, sich anhand von Beispielen innerhalb der Eingabeaufforderung anzupassen. Nur wenige Schüsse, die mehrere Aufgabenbei Beispiele verwenden, zeigt effektiv das gewünschte Verhalten. Aber wie erreichen Transformatoren diese Anpassung? Dieser Artikel untersucht potenzielle Mechanismen hinter ICL.

Der Kern von ICL ist: Geben Sie beispiele Paare ((x, y)) auf, können Aufmerksamkeitsmechanismen einen Algorithmus lernen, um neue Abfragen (x) ihren Ausgängen (y) zuzuordnen?
Softmax -Aufmerksamkeit und nächste Nachbarsuchung
Die Softmax -Aufmerksamkeitsformel lautet:
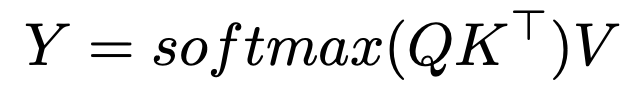
Einführung eines inversen Temperaturparameters, c
, verändert die Aufmerksamkeitszuweisung:
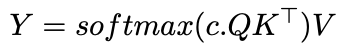
als c nähert sich unendlich, die Aufmerksamkeit wird zu einem HOT-Vektor, der sich ausschließlich auf den ähnlichsten Token konzentriert-effektiv eine nächste Nachbar-Suche. Mit endlicher c
ähnelt die Aufmerksamkeit dem Gaußschen Kernelglättung. Dies deutet darauf hin, dass ICL möglicherweise einen nächsten Nachbaralgorithmus für Eingabe-Output-Paare implementiert.Implikationen und weitere Forschung
Verständnis, wie Transformatoren Algorithmen lernen (wie der nächste Nachbarn), öffnet Türen für Automl. Hollmann et al. Demonstriertes Training eines Transformators auf synthetischen Datensätzen, um die gesamte Automl -Pipeline zu erlernen, die optimale Modelle und Hyperparameter aus neuen Daten in einem einzigen Pass vorherzusagen.
Die 2022 -Forschung von
Anthropic legt "Induktionsköpfe" als Mechanismus vor. Diese Paare von Aufmerksamkeitsköpfen kopieren und vollständige Muster; Zum Beispiel geben sie "... a, b ... a" voraus, "B" basierend auf früheren Kontext.Neuere Studien (Garg et al. 2022, Oswald et al. 2023) verbinden die ICL der Transformatoren mit Gradientenabstieg. Lineare Aufmerksamkeit, die Softmax -Operation weglassen:
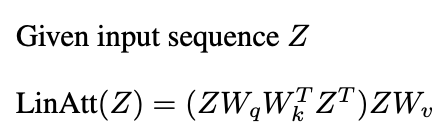
ähnelt vorkonditionierter Gradientenabfälle (PGD):
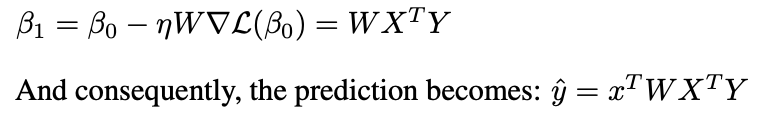
Eine Schicht der linearen Aufmerksamkeit führt einen PGD -Schritt aus.
Schlussfolgerung
Aufmerksamkeitsmechanismen können Lernalgorithmen implementieren und ICL ermöglichen, indem sie aus Demonstrationspaaren lernen. Während das Zusammenspiel mehrerer Aufmerksamkeitsschichten und MLPs komplex ist, wirft die Forschung auf die ICL -Mechanik auf. Dieser Artikel bietet einen hochrangigen Überblick über diese Erkenntnisse.
Weiteres Lesen:
- In-Kontext-Lern- und Induktionsköpfe
- Was können Transformatoren in Kontexten lernen? Eine Fallstudie von einfachen Funktionsklassen
- Transformatoren lernen in Kontext durch Gradientenabstieg
- Transformatoren lernen, vorkonditionierte Gradientenabstiegungen für das Lernen in Kontext zu implementieren
Bestätigung
Dieser Artikel ist vom Herbst 2024 Graduiertenkurs an der Universität von Michigan inspiriert. Fehler sind ausschließlich die des Autors.
Das obige ist der detaillierte Inhalt vonDie Mathematik hinter dem Kontextlernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr