
Heim >Technologie-Peripheriegeräte >KI >1 hervorragend, 5 mündlich! Ist die ACL von ByteDance dieses Jahr so heftig? Kommen Sie und chatten Sie im Live-Übertragungsraum!
1 hervorragend, 5 mündlich! Ist die ACL von ByteDance dieses Jahr so heftig? Kommen Sie und chatten Sie im Live-Übertragungsraum!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-15 16:32:32826Durchsuche
Der Fokus akademischer Kreise liegt diese Woche zweifellos auf dem ACL 2024 Summit in Bangkok, Thailand. Diese Veranstaltung zog viele herausragende Forscher aus der ganzen Welt an, die zusammenkamen, um die neuesten akademischen Ergebnisse zu diskutieren und auszutauschen.
Offizielle Daten zeigen, dass die diesjährige ACL fast 5.000 Papiereinreichungen erhalten hat, von denen 940 von der Hauptkonferenz angenommen wurden und 168 Arbeiten für den mündlichen Bericht (mündlich) der Konferenz ausgewählt wurden. Die Annahmequote liegt unter 3,4 %. Darunter hat ByteDance insgesamt 5 Ergebnisse und Oral wurde ausgewählt.
In der Paper Awards-Sitzung am Nachmittag des 14. August wurde ByteDances Errungenschaft „G-DIG: Towards Gradient-based DIverse and high-quality Instruction Data Selection for Machine Translation“ vom Veranstalter offiziell als Outstanding Paper bekannt gegeben ( 1/ 35).现 ACL 2024 vor Ort Fotos
 Zurück zu ACL 2021, Byte Beating hat die einzigen besten Arbeiten mit Lorbeer gewonnen. Es ist das zweite Mal, dass das chinesische Wissenschaftlerteam zum zweiten Mal seit der Gründung von ACL ausgewählt wurde. Hauptpreis!
Zurück zu ACL 2021, Byte Beating hat die einzigen besten Arbeiten mit Lorbeer gewonnen. Es ist das zweite Mal, dass das chinesische Wissenschaftlerteam zum zweiten Mal seit der Gründung von ACL ausgewählt wurde. Hauptpreis!
Um eine ausführliche Diskussion über die neuesten Forschungsergebnisse dieses Jahres zu führen, haben wir speziell die wichtigsten Mitarbeiter des ByteDance-Artikels zur Interpretation und zum Austausch eingeladen. Nächsten Dienstag, 20. August, von 19:00-21:00 Uhr, wird die „ByteDance ACL 2024 Cutting-edge Paper Sharing Session“ online übertragen!
Wang Mingxuan, Leiter des Doubao-Sprachmodell-Forschungsteams, wird mit vielen ByteDance-Forschern
Huang Zhichao, Zheng Zaixiang, Li Chaowei, Zhang Xinbo und dem mysteriösen Gast von Outstanding Paperzusammenarbeiten, um einige der aufregenden Ergebnisse zu teilen und Forschungsrichtungen von ACL. Es umfasst die Verarbeitung natürlicher Sprache, Sprachverarbeitung, multimodales Lernen, das Denken großer Modelle und andere Bereiche. Vereinbaren Sie gerne einen Termin! ?? ech Discretization Device
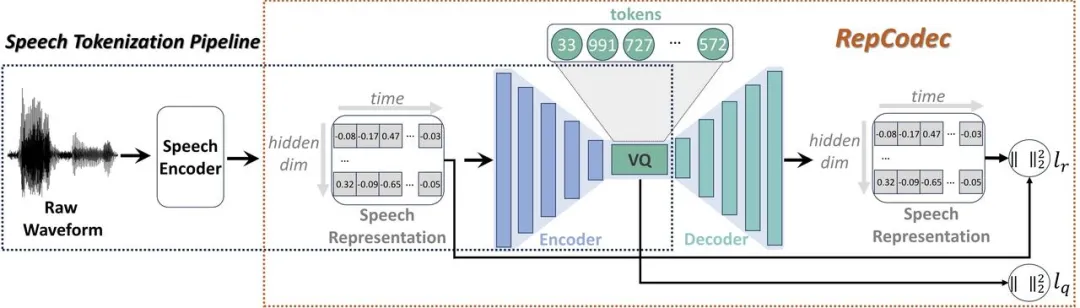
Papieradresse: https:// arxiv.org/pdf/2309.00169Angesichts der jüngsten rasanten Entwicklung großer Sprachmodelle (LLMs) spielt die diskrete Sprachtokenisierung eine wichtige Rolle bei der Injektion von Sprache in LLMs. Diese Diskretisierung führt jedoch zu einem Informationsverlust und beeinträchtigt somit die Gesamtleistung. Um die Leistung dieser diskreten Sprachtokens zu verbessern, schlagen wir RepCodec vor, einen neuartigen Sprachdarstellungscodec für die semantische Sprachdiskretisierung.
🔜 wie HuBERT oder data2vec. Der Sprachkodierer, der Codec-Kodierer und das VQ-Codebuch bilden zusammen einen Prozess, der Sprachwellenformen in semantische Token umwandelt. Umfangreiche Experimente zeigen, dass RepCodec aufgrund seiner verbesserten Informationsspeicherfähigkeiten die weit verbreitete K-Means-Clustering-Methode beim Sprachverständnis und der Sprachgenerierung deutlich übertrifft. Darüber hinaus bleibt dieser Vorteil bei einer Vielzahl von Sprachcodierern und Sprachen bestehen, was die Robustheit von RepCodec bestätigt. Dieser Ansatz kann die groß angelegte Sprachmodellforschung in der Sprachverarbeitung erleichtern. 
Während der. diff usionsmodell generiert Mit kontinuierlichen Signalen wie Bildern und Audio wurden große Erfolge erzielt, es bestehen jedoch weiterhin Schwierigkeiten beim Erlernen diskreter Sequenzdaten wie natürlicher Sprache. Obwohl eine neuere Reihe von Textdiffusionsmodellen diese Herausforderung der Diskretion umgehen, indem sie diskrete Zustände in einen latenten Zustandsraum mit kontinuierlichen Zuständen einbetten, ist ihre Generierungsqualität immer noch unbefriedigend. Um dies zu verstehen, analysieren wir zunächst den Trainingsprozess von Sequenzgenerierungsmodellen basierend auf Diffusionsmodellen und identifizieren drei schwerwiegende Probleme damit: (1) Lernfehler; (3) Vernachlässigung des Bedingungssignals; Wir glauben, dass diese Probleme auf die Unvollkommenheit der Diskretion im Einbettungsraum zurückzuführen sind, wo das Ausmaß des Rauschens eine entscheidende Rolle spielt. In dieser Arbeit schlagen wir DINOISER vor, das Diffusionsmodelle für die Sequenzgenerierung durch Manipulation von Rauschen verbessert. Wir bestimmen adaptiv den Bereich der abgetasteten Rauschskala während der Trainingsphase in einer von der optimalen Übertragung inspirierten Weise und ermutigen das Modell während der Inferenzphase, das bedingte Signal durch Verstärkung der Rauschskala besser auszunutzen. Experimente zeigen, dass DINOISER auf der Grundlage der vorgeschlagenen effektiven Trainings- und Inferenzstrategie die Basislinie früherer Diffusionssequenz-Generierungsmodelle bei mehreren bedingten Sequenzmodellierungs-Benchmarks übertrifft. Weitere Analysen bestätigten auch, dass DINOISER bedingte Signale besser zur Steuerung seines Generierungsprozesses nutzen kann. Beschleunigen Sie das Training der visuellen bedingten Sprachgenerierung durch Reduzierung der Redundanz Papieradresse: https://arxiv.org/pdf/2310.03291
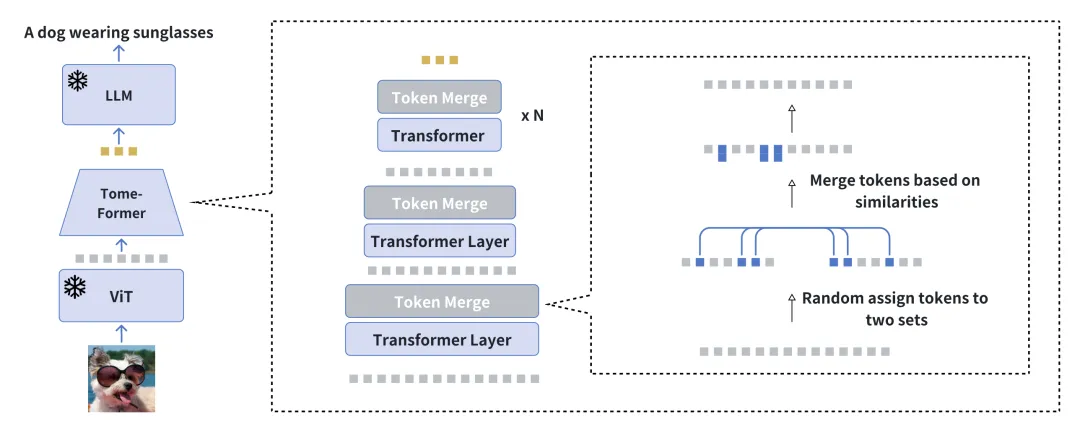
Wir stellen EVLGen vor, ein Tool für A vereinfacht Framework, das für das Vortraining visuell bedingter Sprachgenerierungsmodelle mit hohem Rechenaufwand entwickelt wurde und eingefrorene vorab trainierte große Sprachmodelle (LLMs) nutzt.
Der herkömmliche Ansatz beim Visual Language Pretraining (VLP) umfasst normalerweise einen zweistufigen Optimierungsprozess: Eine erste ressourcenintensive Phase widmet sich den allgemeinen Lernschwerpunkten der Visual Language Representation beim Extrahieren und Integrieren relevanter visueller Merkmale. Darauf folgt eine Nachbereitungsphase, in der die durchgängige Abstimmung zwischen visuellen und sprachlichen Modalitäten im Vordergrund steht. Unser neuartiges einstufiges Einzelverlust-Framework umgeht die rechenintensive erste Trainingsphase, indem ähnliche visuelle Orientierungspunkte während des Trainings schrittweise zusammengeführt werden, und vermeidet gleichzeitig die Modellunannehmlichkeiten, die durch das einstufige Training von BLIP-2-Modellen verursacht werden. Der schrittweise Zusammenführungsprozess komprimiert visuelle Informationen effektiv und behält gleichzeitig den semantischen Reichtum bei, wodurch eine schnelle Konvergenz erreicht wird, ohne die Leistung zu beeinträchtigen.
Experimentelle Ergebnisse zeigen, dass unsere Methode das Training visueller Sprachmodelle um das Fünffache beschleunigt, ohne nennenswerte Auswirkungen auf die Gesamtleistung. Darüber hinaus schließt unser Modell die Leistungslücke zu aktuellen visuellen Sprachmodellen deutlich, indem es nur 1/10 der Daten verwendet. Abschließend zeigen wir, wie unser Bild-Text-Modell über ein neuartiges, zeitlich beschriftetes Kontextmodul mit weicher Aufmerksamkeit nahtlos an videokonditionierte Sprachgenerierungsaufgaben angepasst werden kann.
StreamVoice: Streambare kontextsensitive Sprachmodellierung für Zero-Shot-Sprachkonvertierung in Echtzeit
Papieradresse: https://arxiv.org/pdf/2401.11053
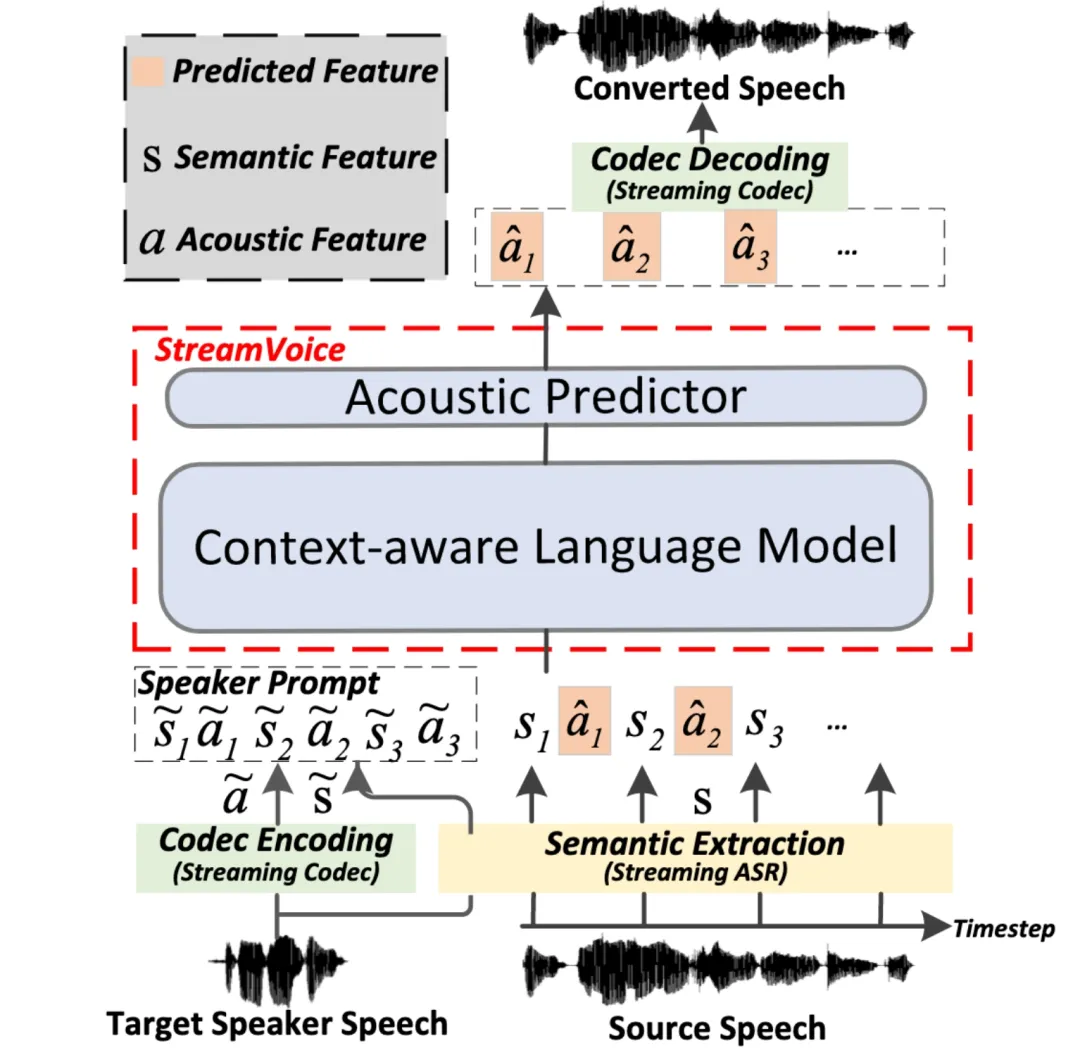
Streaming Streaming Die Zero-Shot-Sprachkonvertierung bezieht sich auf die Fähigkeit, eingegebene Sprache in Echtzeit in die Sprache eines beliebigen Sprechers umzuwandeln. Sie erfordert nur einen Satz der Stimme des Sprechers als Referenz und erfordert keine zusätzlichen Modellaktualisierungen. Bestehende Methoden zur Sprachkonvertierung ohne Abtastung sind in der Regel für Offline-Systeme konzipiert und können die Streaming-Fähigkeitsanforderungen von Echtzeit-Sprachkonvertierungsanwendungen nur schwer erfüllen. Neuere Methoden, die auf dem Sprachmodell (LM) basieren, haben eine hervorragende Leistung bei der Zero-Shot-Sprachgenerierung (einschließlich Konvertierung) gezeigt, erfordern jedoch die Verarbeitung ganzer Sätze und sind auf Offline-Szenarien beschränkt. oice In dieser Arbeit schlagen wir StreamVoice vor, ein neues Zero-Shot-Sprachkonvertierungsmodell basierend auf Streaming LM, um eine Echtzeitkonvertierung für beliebige Sprecher und Eingabesprache zu erreichen. Um Streaming-Fähigkeiten zu erreichen, verwendet StreamVoice insbesondere ein kontextbewusstes, vollständig kausales LM sowie einen zeitunabhängigen akustischen Prädiktor, während der Wechsel semantischer und akustischer Merkmale in einem autoregressiven Prozess die Abhängigkeit von der vollständigen Quellsprache beseitigt.
Um den durch unvollständigen Kontext in Streaming-Szenarien verursachten Leistungsabfall zu beheben, werden zwei Strategien verwendet, um das Kontextbewusstsein von LM für die Zukunft und Geschichte zu verbessern: 1) lehrergeführte Kontextvorausschau, durch lehrergeführte Kontextvoraussicht Das Modell fasst die zusammen aktuelle und zukünftige genaue Semantik, um das Modell bei der Vorhersage des fehlenden Kontexts zu unterstützen. 2) Die semantische Maskierungsstrategie ermutigt das Modell, eine akustische Vorhersage aus zuvor beschädigten semantischen Eingaben zu erzielen und die Lernfähigkeit des historischen Kontexts zu verbessern. Experimente zeigen, dass StreamVoice über Streaming-Konvertierungsfunktionen verfügt und gleichzeitig eine Zero-Shot-Leistung erreicht, die der von Nicht-Streaming-VC-Systemen nahekommt.
G-DIG: Engagiert für eine auf Gradienten basierende maschinelle Übersetzungsvielfalt und eine qualitativ hochwertige Auswahl von Befehlsdaten Papieradresse: https://arxiv.org/pdf/2405.12915
Groß Sprachmodelle (LLMs) haben in allgemeinen Szenarien außergewöhnliche Fähigkeiten bewiesen. Durch die Feinabstimmung der Anweisungen können sie bei einer Vielzahl von Aufgaben auf Augenhöhe mit Menschen arbeiten. Die Vielfalt und Qualität der Unterrichtsdaten bleiben jedoch zwei große Herausforderungen für die Feinabstimmung des Unterrichts. Zu diesem Zweck schlagen wir einen neuartigen, auf Gradienten basierenden Ansatz vor, um automatisch hochwertige und vielfältige Daten zur Feinabstimmung von Anweisungen für die maschinelle Übersetzung auszuwählen. Unsere wichtigste Innovation liegt in der Analyse, wie sich einzelne Trainingsbeispiele während des Trainings auf das Modell auswirken.
der Einflussfunktion und eines kleinen hochwertigen Seed-Datensatzes. Um die Vielfalt der Trainingsdaten zu erhöhen, maximieren wir außerdem die Vielfalt ihres Einflusses auf das Modell, indem wir ihre Gradienten gruppieren und erneut abtasten. Umfangreiche Experimente zu WMT22- und FLORES-Übersetzungsaufgaben belegen die Überlegenheit unserer Methode, und eine eingehende Analyse bestätigt ihre Wirksamkeit und Allgemeingültigkeit weiter.
GroundingGPT: Sprachverbessert Multimodales ErdungsmodellPapieradresse: https://arxiv.org/pdf/2401.06071
Um dieses Problem zu lösen und die Vielseitigkeit großer multimodaler Modelle für ein breiteres Aufgabenspektrum zu verbessern, schlagen wir GroundingGPT vor, ein multimodales Modell, das unterschiedliche granulare Verständnisse von Bildern, Videos und Audios erreichen kann. Neben der Erfassung globaler Informationen eignet sich unser vorgeschlagenes Modell auch gut für die Bewältigung von Aufgaben, die ein verfeinertes Verständnis erfordern, beispielsweise die Fähigkeit des Modells, bestimmte Regionen in einem Bild oder bestimmte Momente in einem Video zu lokalisieren. Um dieses Ziel zu erreichen, haben wir einen vielfältigen Datensatzkonstruktionsprozess entwickelt, um einen multimodalen und multigranularen Trainingsdatensatz zu erstellen. Experimente mit mehreren öffentlichen Benchmarks zeigen die Vielseitigkeit und Wirksamkeit unseres Modells.
ReFT: Inferenz basierend auf Verstärkungsfeinabstimmung Papieradresse: https://arxiv.org/pdf/2401.08967
Vergleich zwischen SFT und ReFT hinsichtlich der Präsenz von CoT-Alternativen
Um diese Herausforderung zu lösen, schlagen wir am Beispiel mathematischer Probleme eine einfache und effektive Methode namens Reinforced Fine-Tuning (ReFT) vor, um die Generalisierungsfähigkeit von LLMs während der Inferenz zu verbessern. ReFT verwendet zunächst SFT zum Aufwärmen des Modells und verwendet dann zur Optimierung Online-Verstärkungslernen (insbesondere den PPO-Algorithmus in dieser Arbeit), das automatisch eine große Anzahl von Argumentationspfaden für ein bestimmtes Problem abtastet und Belohnungen basierend auf den tatsächlichen Antworten erhält weitere Feinabstimmung des Modells.
Umfangreiche Experimente mit GSM8K-, MathQA- und SVAMP-Datensätzen zeigen, dass ReFT SFT deutlich übertrifft und die Modellleistung durch die Kombination von Strategien wie Mehrheitsabstimmung und Neuordnung weiter verbessert werden kann. Es ist erwähnenswert, dass ReFT hier nur auf demselben Trainingsproblem wie SFT beruht und nicht auf zusätzlichen oder erweiterten Trainingsproblemen beruht. Dies zeigt, dass ReFT über eine überlegene Generalisierungsfähigkeit verfügt. Ich freue mich auf Ihre interaktiven Fragen
Live-Übertragungszeit: 20. August 2024 (Dienstag) 19:00–21:00 Uhr Live-Übertragungsplattform: WeChat-Videokonto [Doubao Big Model Team], Xiao Red Book Number [Doubao-Forscher]
Sie können gerne den Fragebogen ausfüllen und uns Ihre Fragen zum ACL 2024-Papier mitteilen und online mit mehreren Forschern chatten! Das Beanbao-Modellteam wird weiterhin heiß rekrutiert. Klicken Sie bitte auf diesen Link, um mehr über Teamrekrutierungsinformationen zu erfahren.

Während der. diff usionsmodell generiert Mit kontinuierlichen Signalen wie Bildern und Audio wurden große Erfolge erzielt, es bestehen jedoch weiterhin Schwierigkeiten beim Erlernen diskreter Sequenzdaten wie natürlicher Sprache. Obwohl eine neuere Reihe von Textdiffusionsmodellen diese Herausforderung der Diskretion umgehen, indem sie diskrete Zustände in einen latenten Zustandsraum mit kontinuierlichen Zuständen einbetten, ist ihre Generierungsqualität immer noch unbefriedigend. Um dies zu verstehen, analysieren wir zunächst den Trainingsprozess von Sequenzgenerierungsmodellen basierend auf Diffusionsmodellen und identifizieren drei schwerwiegende Probleme damit: (1) Lernfehler; (3) Vernachlässigung des Bedingungssignals; Wir glauben, dass diese Probleme auf die Unvollkommenheit der Diskretion im Einbettungsraum zurückzuführen sind, wo das Ausmaß des Rauschens eine entscheidende Rolle spielt. In dieser Arbeit schlagen wir DINOISER vor, das Diffusionsmodelle für die Sequenzgenerierung durch Manipulation von Rauschen verbessert. Wir bestimmen adaptiv den Bereich der abgetasteten Rauschskala während der Trainingsphase in einer von der optimalen Übertragung inspirierten Weise und ermutigen das Modell während der Inferenzphase, das bedingte Signal durch Verstärkung der Rauschskala besser auszunutzen. Experimente zeigen, dass DINOISER auf der Grundlage der vorgeschlagenen effektiven Trainings- und Inferenzstrategie die Basislinie früherer Diffusionssequenz-Generierungsmodelle bei mehreren bedingten Sequenzmodellierungs-Benchmarks übertrifft. Weitere Analysen bestätigten auch, dass DINOISER bedingte Signale besser zur Steuerung seines Generierungsprozesses nutzen kann.Beschleunigen Sie das Training der visuellen bedingten Sprachgenerierung durch Reduzierung der Redundanz Papieradresse: https://arxiv.org/pdf/2310.03291 Wir stellen EVLGen vor, ein Tool für A vereinfacht Framework, das für das Vortraining visuell bedingter Sprachgenerierungsmodelle mit hohem Rechenaufwand entwickelt wurde und eingefrorene vorab trainierte große Sprachmodelle (LLMs) nutzt. Der herkömmliche Ansatz beim Visual Language Pretraining (VLP) umfasst normalerweise einen zweistufigen Optimierungsprozess: Eine erste ressourcenintensive Phase widmet sich den allgemeinen Lernschwerpunkten der Visual Language Representation beim Extrahieren und Integrieren relevanter visueller Merkmale. Darauf folgt eine Nachbereitungsphase, in der die durchgängige Abstimmung zwischen visuellen und sprachlichen Modalitäten im Vordergrund steht. Unser neuartiges einstufiges Einzelverlust-Framework umgeht die rechenintensive erste Trainingsphase, indem ähnliche visuelle Orientierungspunkte während des Trainings schrittweise zusammengeführt werden, und vermeidet gleichzeitig die Modellunannehmlichkeiten, die durch das einstufige Training von BLIP-2-Modellen verursacht werden. Der schrittweise Zusammenführungsprozess komprimiert visuelle Informationen effektiv und behält gleichzeitig den semantischen Reichtum bei, wodurch eine schnelle Konvergenz erreicht wird, ohne die Leistung zu beeinträchtigen. Experimentelle Ergebnisse zeigen, dass unsere Methode das Training visueller Sprachmodelle um das Fünffache beschleunigt, ohne nennenswerte Auswirkungen auf die Gesamtleistung. Darüber hinaus schließt unser Modell die Leistungslücke zu aktuellen visuellen Sprachmodellen deutlich, indem es nur 1/10 der Daten verwendet. Abschließend zeigen wir, wie unser Bild-Text-Modell über ein neuartiges, zeitlich beschriftetes Kontextmodul mit weicher Aufmerksamkeit nahtlos an videokonditionierte Sprachgenerierungsaufgaben angepasst werden kann.
StreamVoice: Streambare kontextsensitive Sprachmodellierung für Zero-Shot-Sprachkonvertierung in Echtzeit
Papieradresse: https://arxiv.org/pdf/2401.11053
Streaming Streaming Die Zero-Shot-Sprachkonvertierung bezieht sich auf die Fähigkeit, eingegebene Sprache in Echtzeit in die Sprache eines beliebigen Sprechers umzuwandeln. Sie erfordert nur einen Satz der Stimme des Sprechers als Referenz und erfordert keine zusätzlichen Modellaktualisierungen. Bestehende Methoden zur Sprachkonvertierung ohne Abtastung sind in der Regel für Offline-Systeme konzipiert und können die Streaming-Fähigkeitsanforderungen von Echtzeit-Sprachkonvertierungsanwendungen nur schwer erfüllen. Neuere Methoden, die auf dem Sprachmodell (LM) basieren, haben eine hervorragende Leistung bei der Zero-Shot-Sprachgenerierung (einschließlich Konvertierung) gezeigt, erfordern jedoch die Verarbeitung ganzer Sätze und sind auf Offline-Szenarien beschränkt. In dieser Arbeit schlagen wir StreamVoice vor, ein neues Zero-Shot-Sprachkonvertierungsmodell basierend auf Streaming LM, um eine Echtzeitkonvertierung für beliebige Sprecher und Eingabesprache zu erreichen. Um Streaming-Fähigkeiten zu erreichen, verwendet StreamVoice insbesondere ein kontextbewusstes, vollständig kausales LM sowie einen zeitunabhängigen akustischen Prädiktor, während der Wechsel semantischer und akustischer Merkmale in einem autoregressiven Prozess die Abhängigkeit von der vollständigen Quellsprache beseitigt.
Um den durch unvollständigen Kontext in Streaming-Szenarien verursachten Leistungsabfall zu beheben, werden zwei Strategien verwendet, um das Kontextbewusstsein von LM für die Zukunft und Geschichte zu verbessern: 1) lehrergeführte Kontextvorausschau, durch lehrergeführte Kontextvoraussicht Das Modell fasst die zusammen aktuelle und zukünftige genaue Semantik, um das Modell bei der Vorhersage des fehlenden Kontexts zu unterstützen. 2) Die semantische Maskierungsstrategie ermutigt das Modell, eine akustische Vorhersage aus zuvor beschädigten semantischen Eingaben zu erzielen und die Lernfähigkeit des historischen Kontexts zu verbessern. Experimente zeigen, dass StreamVoice über Streaming-Konvertierungsfunktionen verfügt und gleichzeitig eine Zero-Shot-Leistung erreicht, die der von Nicht-Streaming-VC-Systemen nahekommt.
G-DIG: Engagiert für eine auf Gradienten basierende maschinelle Übersetzungsvielfalt und eine qualitativ hochwertige Auswahl von Befehlsdaten Papieradresse: https://arxiv.org/pdf/2405.12915 Groß Sprachmodelle (LLMs) haben in allgemeinen Szenarien außergewöhnliche Fähigkeiten bewiesen. Durch die Feinabstimmung der Anweisungen können sie bei einer Vielzahl von Aufgaben auf Augenhöhe mit Menschen arbeiten. Die Vielfalt und Qualität der Unterrichtsdaten bleiben jedoch zwei große Herausforderungen für die Feinabstimmung des Unterrichts. Zu diesem Zweck schlagen wir einen neuartigen, auf Gradienten basierenden Ansatz vor, um automatisch hochwertige und vielfältige Daten zur Feinabstimmung von Anweisungen für die maschinelle Übersetzung auszuwählen. Unsere wichtigste Innovation liegt in der Analyse, wie sich einzelne Trainingsbeispiele während des Trainings auf das Modell auswirken.
der Einflussfunktion und eines kleinen hochwertigen Seed-Datensatzes. Um die Vielfalt der Trainingsdaten zu erhöhen, maximieren wir außerdem die Vielfalt ihres Einflusses auf das Modell, indem wir ihre Gradienten gruppieren und erneut abtasten. Umfangreiche Experimente zu WMT22- und FLORES-Übersetzungsaufgaben belegen die Überlegenheit unserer Methode, und eine eingehende Analyse bestätigt ihre Wirksamkeit und Allgemeingültigkeit weiter.
Um dieses Problem zu lösen und die Vielseitigkeit großer multimodaler Modelle für ein breiteres Aufgabenspektrum zu verbessern, schlagen wir GroundingGPT vor, ein multimodales Modell, das unterschiedliche granulare Verständnisse von Bildern, Videos und Audios erreichen kann. Neben der Erfassung globaler Informationen eignet sich unser vorgeschlagenes Modell auch gut für die Bewältigung von Aufgaben, die ein verfeinertes Verständnis erfordern, beispielsweise die Fähigkeit des Modells, bestimmte Regionen in einem Bild oder bestimmte Momente in einem Video zu lokalisieren. Um dieses Ziel zu erreichen, haben wir einen vielfältigen Datensatzkonstruktionsprozess entwickelt, um einen multimodalen und multigranularen Trainingsdatensatz zu erstellen. Experimente mit mehreren öffentlichen Benchmarks zeigen die Vielseitigkeit und Wirksamkeit unseres Modells.GroundingGPT: Sprachverbessert Multimodale große Sprache Das Modell zeigt hervorragende Leistungen bei verschiedenen Aufgaben in unterschiedlichen Modalitäten. Bei früheren Modellen liegt der Schwerpunkt jedoch hauptsächlich auf der Erfassung globaler Informationen über multimodale Eingaben. Daher mangelt es diesen Modellen an der Fähigkeit, die Details in den Eingabedaten effektiv zu verstehen, und sie sind bei Aufgaben, die gleichzeitig ein detailliertes Verständnis der Eingabe erfordern, schlecht dieser Modelle leiden unter schwerwiegenden Halluzinationsproblemen, was ihre weitverbreitete Verwendung einschränkt. Multimodales ErdungsmodellPapieradresse: https://arxiv.org/pdf/2401.06071
ReFT: Inferenz basierend auf Verstärkungsfeinabstimmung Eine gemeinsame Verstärkung für große Sprachmodelle (LLMs) Inferenz Der leistungsfähige Ansatz ist die überwachte Feinabstimmung (Supervised Fine-Tuning, SFT) mithilfe von Chain of Thought (CoT) annotierten Daten. Diese Methode weist jedoch keine ausreichend starke Generalisierungsfähigkeit auf, da das Training nur auf den gegebenen CoT-Daten basiert. Insbesondere in Datensätzen, die sich auf mathematische Probleme beziehen, gibt es normalerweise nur einen kommentierten Argumentationspfad für jedes Problem in den Trainingsdaten. Wenn der Algorithmus mehrere gekennzeichnete Argumentationspfade für ein Problem lernen kann, verfügt er über stärkere Generalisierungsfähigkeiten. Papieradresse: https://arxiv.org/pdf/2401.08967 Vergleich zwischen SFT und ReFT hinsichtlich der Präsenz von CoT-Alternativen
Um diese Herausforderung zu lösen, schlagen wir am Beispiel mathematischer Probleme eine einfache und effektive Methode namens Reinforced Fine-Tuning (ReFT) vor, um die Generalisierungsfähigkeit von LLMs während der Inferenz zu verbessern. ReFT verwendet zunächst SFT zum Aufwärmen des Modells und verwendet dann zur Optimierung Online-Verstärkungslernen (insbesondere den PPO-Algorithmus in dieser Arbeit), das automatisch eine große Anzahl von Argumentationspfaden für ein bestimmtes Problem abtastet und Belohnungen basierend auf den tatsächlichen Antworten erhält weitere Feinabstimmung des Modells. Umfangreiche Experimente mit GSM8K-, MathQA- und SVAMP-Datensätzen zeigen, dass ReFT SFT deutlich übertrifft und die Modellleistung durch die Kombination von Strategien wie Mehrheitsabstimmung und Neuordnung weiter verbessert werden kann. Es ist erwähnenswert, dass ReFT hier nur auf demselben Trainingsproblem wie SFT beruht und nicht auf zusätzlichen oder erweiterten Trainingsproblemen beruht. Dies zeigt, dass ReFT über eine überlegene Generalisierungsfähigkeit verfügt. Ich freue mich auf Ihre interaktiven Fragen
Live-Übertragungszeit: 20. August 2024 (Dienstag) 19:00–21:00 Uhr Live-Übertragungsplattform: WeChat-Videokonto [Doubao Big Model Team], Xiao Red Book Number [Doubao-Forscher] Sie können gerne den Fragebogen ausfüllen und uns Ihre Fragen zum ACL 2024-Papier mitteilen und online mit mehreren Forschern chatten! Das Beanbao-Modellteam wird weiterhin heiß rekrutiert. Klicken Sie bitte auf diesen Link, um mehr über Teamrekrutierungsinformationen zu erfahren.


 oice
oice




Das obige ist der detaillierte Inhalt von1 hervorragend, 5 mündlich! Ist die ACL von ByteDance dieses Jahr so heftig? Kommen Sie und chatten Sie im Live-Übertragungsraum!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr