
Heim >Technologie-Peripheriegeräte >KI >„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.

- PHPzOriginal
- 2024-07-26 17:38:031117Durchsuche
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Gewährleistung der Produktqualität, sondern auch der Kern der Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können.
Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „Defect Spectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „Defektspektrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben), die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien) und alle Arten von Fehlern Bereitstellung detaillierter Beschriftungen auf Pixelebene. Darüber hinaus liefert der Datensatz auch eine detaillierte sprachliche Beschreibung für jede Fehlerprobe. Der spezifische Anmerkungsvergleich ist in Abbildung 1 dargestellt.

Abbildung 1: Im Vergleich zu anderen industriellen Datensätzen weist Defect Spectrum eine höhere Genauigkeit und umfassendere Anmerkungen auf
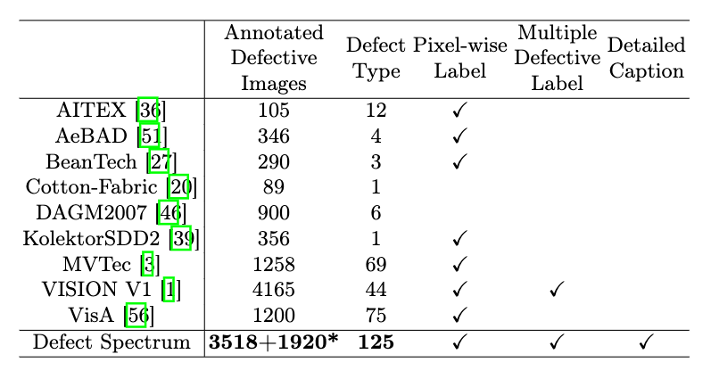
Tabelle 1: Vergleich der Menge und Art von Defect Spectrum und anderen vorhandenen Datensätzen
"Defect Spectrum". „ stellt einen revolutionären Ansatz vor – „DefectGen“ – basierend auf modernsten Diffusionsmodellen. Durch die Verwendung einer sehr kleinen Menge industrieller Fehlerdaten zur Generierung von Bildern und Fehlerkennzeichnungen auf Pixelebene verbessert diese Methode die Leistung industrieller Fehlererkennungsmodelle erheblich und wird auf mehreren Industriestandard-Datensätzen (wie MVTec AD, VISION, DAGM2007 usw.) implementiert Baumwollstoff) Ein beispielloser Leistungsdurchbruch.
Diese bahnbrechende Forschung verbessert nicht nur die Genauigkeit der Fehlererkennung erheblich, sondern eröffnet auch neue Möglichkeiten für die Anwendung von KI in komplexen Industrieumgebungen. Der Code und die Modelle des Projekts sind vollständig Open Source.

- Papier: Fehlerspektrum: Ein granularer Blick auf groß angelegte Fehlerdatensätze mit reichhaltiger Semantik
- Papierlink:https://www.php.cn/link/136aa7fe7fd745073fec3fb4ef67e3b9
- Projektlink: https : //envision-research.github.io/Defect_Spectrum/
- Github Repo: https://github.com/EnVision-Research/Defect_Spectrum
- Dataset Repo: https://huggingface.co/datasets/DefectSpectrum/Defect_Spectrum
Durchbrechen Sie die herkömmlichen Einschränkungen bei der Fehlererkennung und nähern Sie sich der tatsächlichen Produktion an . Die Fabrik muss die Rentabilität sicherstellen und gleichzeitig fehlerhafte Teile kontrollieren, wie in Abbildung 2 dargestellt. Allerdings mangelt es den bestehenden Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind. Wenn beispielsweise auf der Oberfläche einer Metallplatte ein großer Bereich der Farbe abblättert, wird dies der Fall sein, obwohl der Fehlerbereich groß ist haben keinen funktionellen Einfluss auf die Metallplatte. Wahrscheinlich nur sehr gering. Wenn es jedoch einen kleinen Riss in der Metallplatte gibt, obwohl dieser Riss so klein wie ein Haar ist, kann er dazu führen, dass die Metallplatte unter Druck sofort bricht, was ihre Leistung erheblich beeinträchtigt und sogar ernsthafte Sicherheitsrisiken mit sich bringt.
Angenommen, die Reißverschlusszähne eines Kleidungsstücks sind falsch ausgerichtet. Auch wenn dieser Defekt nicht groß oder gar nicht leicht zu erkennen erscheint, beeinträchtigt er ernsthaft die Funktion des Kleidungsstücks und führt dazu, dass der Reißverschluss nicht richtig funktioniert . Verbraucher mussten es zur Reparatur ins Werk zurückschicken. Tritt der Fehler jedoch im Stoff des Kleidungsstücks auf, beispielsweise ein leichtes Verhaken oder ein leichter Farbunterschied, müssen Größe und Auswirkungen sorgfältig abgewogen werden. Kleinere Stofffehler können innerhalb akzeptabler Grenzen klassifiziert werden, sodass diese Produkte über verschiedene Vertriebsstrategien verkauft werden können, beispielsweise durch den Verkauf zu ermäßigten Preisen, wodurch das Produkt im Umlauf bleibt, ohne die allgemeinen Qualitätsstandards zu beeinträchtigen.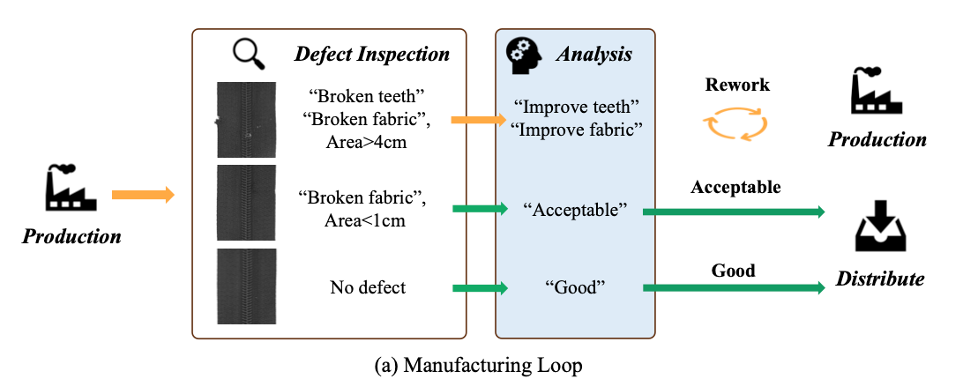 Dahinter verbirgt sich der Datensatz „Defect Spectrum“ wie ein allmächtiger Detektiv mit Einblick in alles. Es deckt nicht nur ein breites Spektrum an Industriefehlertypen ab, sondern bietet auch detaillierte und ausführliche Beschreibungen für jeden Fehler. Mit diesem leistungsstarken Tool kann das Fehlererkennungssystem verschiedene Fehler genauer identifizieren und klassifizieren, ohne dass Details verloren gehen.
Dahinter verbirgt sich der Datensatz „Defect Spectrum“ wie ein allmächtiger Detektiv mit Einblick in alles. Es deckt nicht nur ein breites Spektrum an Industriefehlertypen ab, sondern bietet auch detaillierte und ausführliche Beschreibungen für jeden Fehler. Mit diesem leistungsstarken Tool kann das Fehlererkennungssystem verschiedene Fehler genauer identifizieren und klassifizieren, ohne dass Details verloren gehen.
Stellen Sie sich vor, dass das Inspektionssystem in der tatsächlichen Produktionslinie mithilfe des Datensatzes „Fehlerspektrum“ diesen entscheidenden Fehler schnell identifizieren, ihn sofort kennzeichnen und zur Reparatur an das Werk zurücksenden kann. Gleichzeitig kann das System bei geringfügigen Mängeln oder Farbunterschieden im Stoff anhand der detaillierten Kennzeichnung des Mangels beurteilen, ob dieser im akzeptablen Bereich liegt, und entscheiden, ob der Stoff zu einem reduzierten Preis verkauft werden soll. Diese flexible Verarbeitungsmethode verbessert nicht nur die Produktqualität, sondern sorgt auch für Produktionseffizienz und Kostenkontrolle.
Obwohl herkömmliche Datensätze wie MVTEC und AeBAD Annotationen auf Pixelebene bereitstellen, sind sie oft auf binäre Masken beschränkt und können Fehlertypen und -orte nicht im Detail unterscheiden. Der „Defect Spectrum“-Datensatz bewertet und verfeinert bestehende Fehleranmerkungen durch die Zusammenarbeit mit vier großen Benchmarks der Branche. So werden beispielsweise feine Kratzer und Dellen präziser konturiert und übersehene Mängel mit fachkundiger Unterstützung ausgefüllt, sodass eine umfassende und genaue Anmerkung gewährleistet ist.
Innovatives Fehlergenerierungsmodell „Defect-Gen“
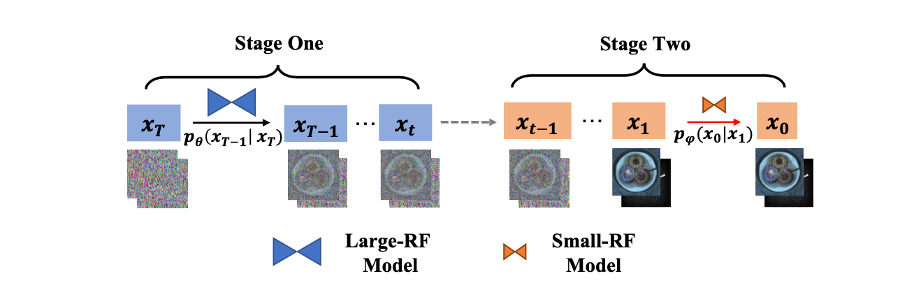
Abbildung 3: Schematische Darstellung des zweistufigen Generierungsprozesses von Defect-Gen
Angesichts des Problems unzureichender Fehlerproben im aktuellen Datensatz, Wir haben „Defect-Gen“ vorgeschlagen, einen zweistufigen Diffusionsgenerator. Dieser Generator verbessert die Vielfalt und Qualität von Bildern mit einer begrenzten Anzahl von Proben durch zwei Schlüsselmethoden: erstens durch die Verwendung von Patch-Level-Modellierung und zweitens durch die Begrenzung des Empfangsfeldes.
Herkömmliche Diffusionsmodelle neigen zur Überanpassung, wenn nur wenige Trainingsbeispiele vorhanden sind. Den generierten Ergebnissen mangelt es an Diversität und sie erinnern sich oft nur an die Trainingsbeispiele. Unser Modell reduziert dieses Überanpassungsphänomen effektiv, indem es die Datendimension reduziert und die Stichprobengröße erhöht.
Um die Mängel der Patch-Level-Modellierung bei der Darstellung der gesamten Bildstruktur auszugleichen, schlagen wir einen zweistufigen Diffusionsprozess vor. Verwenden Sie zunächst ein großes Empfangsfeldmodell, um die geometrische Struktur in frühen Schritten zu erfassen, und wechseln Sie dann zu einem kleinen Empfangsfeldmodell, um in nachfolgenden Schritten lokale Patches zu generieren. Dadurch wird die Vielfalt der erzeugten Bilder bei gleichbleibender Bildqualität deutlich verbessert. Durch die Anpassung der Zugangspunkte und Empfangsfelder beider Modelle erreicht unser Modell eine gute Balance zwischen Treue und Vielfalt.
Durch „Defect-Gen“ stellen wir umfangreichere und vielfältigere Trainingsbeispiele für die industrielle Fehlererkennung bereit und fördern so die Entwicklung automatisierter Inspektionstechnologie.
Umfassende Bewertung und zukünftige Forschungsrichtungen einige Fehlererkennungsnetzwerke im Defect Spectrum-Datensatz
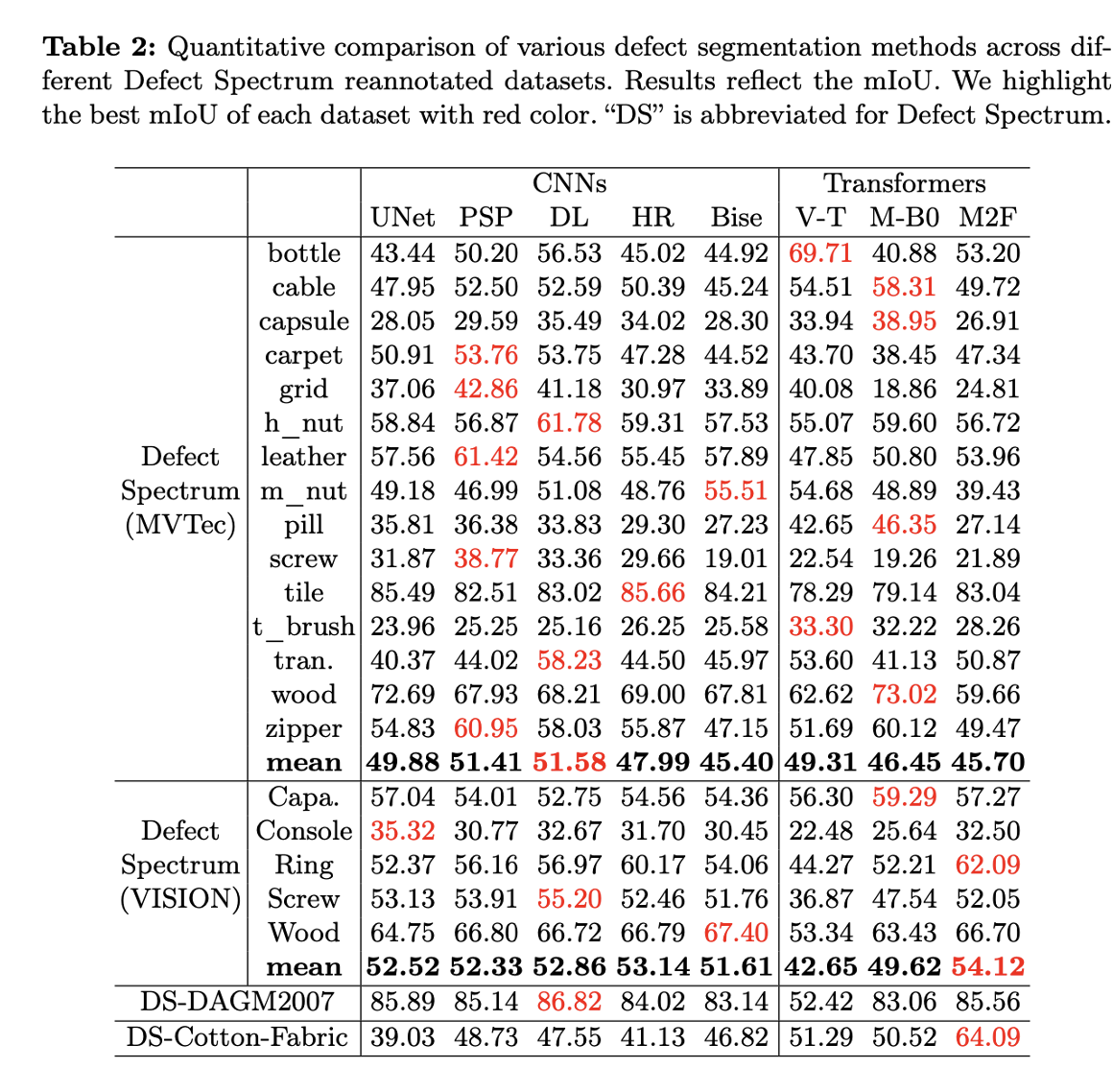 Tabelle 3: Tatsächliche Bewertungskriterien für den Defect Spectrum-Datensatz Tabelle 4: Hervorragende Leistung von Defect Spectrum bei der tatsächlichen Bewertung
Tabelle 3: Tatsächliche Bewertungskriterien für den Defect Spectrum-Datensatz Tabelle 4: Hervorragende Leistung von Defect Spectrum bei der tatsächlichen Bewertung
Unsere Bewertung der Defect Spectrum-Daten Der Satz wurde umfassend ausgewertet und kommentiert, wie in Tabelle 3 dargestellt. Dieses Experiment bestätigte die Anwendbarkeit und Überlegenheit des Fehlerspektrums bei verschiedenen Herausforderungen der industriellen Fehlererkennung. Tabelle 4 zeigt, dass das auf unserem Datensatz trainierte Modell im Vergleich zum Originaldatensatz die Rückrufrate um 10,74 % erhöhte und die Falsch-Positiv-Rate um 33,1 % reduzierte. Darüber hinaus bietet der Erstellungs- und Bewertungsprozess des Datensatzes nicht nur eine solide Forschungsgrundlage, sondern auch eine Plattform für Forscher in Industrie und Wissenschaft, um fortschrittliche Modelle für die komplexen Anforderungen der industriellen Fehlererkennung zu bewerten und zu entwickeln. 

Wir haben den Defect Spectrum-Datensatz und den DefectGen-Fehlergenerator veröffentlicht, die die hohe Genauigkeit und umfassende Fehlersemantik bieten, die für die tatsächliche industrielle Inspektion erforderlich sind, und das Problem lösen, dass das Modell Fehlerkategorien oder -orte nicht identifizieren kann .
Wir haben eine umfassende Bewertung des Fehlerspektrum-Datensatzes durchgeführt und seine Anwendbarkeit und Überlegenheit bei verschiedenen industriellen Fehlererkennungsherausforderungen überprüft. Im Vergleich zum Originaldatensatz hat sich das auf unserem Datensatz trainierte Modell verbessert. Die Rückrufrate beträgt 10,74 %, was die Falschmeldung reduziert Positive Rate um 33,1 %. Referenz:
1. Bai, H., Mou, S., Likhomanenko, T., Cinbis, R.G., Tuzel, O., Huang, P., Shan, J., Shi, J., Cao, M.: Sehdatensätze: Ein Maßstab für Visionbasierte Industrieinspektion. arXiv-Vorabdruck arXiv:2306.07890 (2023)
2. Silvestre-Blanes, J., Albero-Albero, T., Miralles, I., Pérez-Llorens, R., Moreno, J.: Eine öffentliche Stoffdatenbank für Methoden und Ergebnisse zur Fehlererkennung. Autex Research Journal19(4), 363–374 (2019). https://doi.org/doi:10.2478/aut-2019-0035,https://doi.org/10.2478/aut-2019-0035
3. Zhang, Z., Zhao, Z., Zhang, X., Sun, C., Chen, X.: Industrielle Anomalieerkennung mit Domänenverschiebung: Ein realer Datensatz und maskierte Multiskalen-Rekonstruktion. arXiv-Vorabdruck arXiv:2304.02216 (2023)
4. Mishra, P., Verk, R., Fornasier, D., Piciarelli, C., Foresti, G.L.: VT-ADL: Ein Vision-Transformator-Netzwerk zur Erkennung und Lokalisierung von Bildanomalien. In: 30. IEEE/IES International Symposium on Industrial Electronics (ISIE) (Juni 2021)
5. Incorporated, C.: Standard-Textilfehler-Glossar (2023), URL: https : / / www . Cottoninc. com / Qualität – Produkte / Textil – Ressourcen / Stoff – Defekt – Glossar
6. Wieler, M., Hahn, T.: Schwach überwachtes Lernen für die industrielle optische Inspektion. In: DAGM-Symposium in. Bd. 6 (2007)
7. Tabernik, D., Šela, S., Skvarč, J., Skočaj, D.: Segmentierungsbasierter Deep-Learning-Ansatz zur Erkennung von Oberflächenfehlern. Journal of Intelligent Manufacturing31(3), 759–776 (2020)
8. Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad – ein umfassender realer Datensatz für die unbeaufsichtigte Anomalieerkennung. In: Tagungsband der IEEE/CVF-Konferenz zu Computer Vision und Mustererkennung. S. 9592–9600 (2019)
9. Zou, Y., Jeong, J., Pemula, L., Zhang, D., Dabeer, O.: Spot-the-Difference Self-Supervised Pre-Training for Anomaly Detection and Segmentation (2022)
Das obige ist der detaillierte Inhalt von„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr