Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der Hauptautor dieses Artikels ist Huang Yichong. Huang Yichong ist Doktorand am Social Computing and Information Retrieval Research Center des Harbin Institute of Technology und Praktikant am Pengcheng Laboratory. Er studiert bei Professor Qin Bing und Professor Feng Xiaocheng. Zu den Forschungsrichtungen gehören das Lernen großer Sprachmodelle und mehrsprachige große Modelle. Verwandte Artikel wurden auf den führenden Konferenzen zur Verarbeitung natürlicher Sprache (ACL, EMNLP und COLING) veröffentlicht. Da große Sprachmodelle eine erstaunliche Sprachintelligenz aufweisen, haben große KI-Unternehmen ihre eigenen großen Modelle auf den Markt gebracht. Diese großen Modelle haben in der Regel ihre eigenen Stärken in verschiedenen Bereichen und Aufgaben. Wie man sie integrieren kann, um ihr komplementäres Potenzial auszuschöpfen, ist zu einem Grenzthema in der KI-Forschung geworden. Kürzlich haben Forscher des Harbin Institute of Technology und des Pengcheng Laboratory das „trainingsfreie heterogene große Modell integrierte Lernrahmenwerk“ DeePEn vorgeschlagen. Im Gegensatz zu früheren Methoden, die externe Module trainieren, um von mehreren Modellen generierte Antworten zu filtern und zu fusionieren, fusioniert DeePEn die Wahrscheinlichkeitsverteilungen mehrerer Modellausgaben während des Decodierungsprozesses und bestimmt gemeinsam das Ausgabetoken jedes Schritts. Im Vergleich dazu kann diese Methode nicht nur schnell auf jede Modellkombination angewendet werden, sondern ermöglicht den integrierten Modellen auch den Zugriff auf die internen Darstellungen (Wahrscheinlichkeitsverteilungen) des jeweils anderen, was eine tiefere Modellzusammenarbeit ermöglicht. Die Ergebnisse zeigen, dass DeePEn bei mehreren öffentlichen Datensätzen erhebliche Verbesserungen erzielen kann, wodurch die Leistungsgrenzen großer Modelle effektiv erweitert werden: 
Das aktuelle Papier und der Code wurden veröffentlicht:
- Papiertitel: Ensemble Learning for Heterogeneous LargeLanguage Models with Deep Parallel Collaboration
- Papieradresse: https://arxiv.org/abs/2404.12715
- Codeadresse: https://github.com/OrangeInSouth/DeePEn
Einführung in die MethodeDie Kernschwierigkeit der Integration heterogener großer Modelle besteht darin, das Vokabularunterschiedsproblem zwischen Modellen zu lösen. Zu diesem Zweck erstellt DeePEn einen einheitlichen relativen Repräsentationsraum, der aus gemeinsamen Token zwischen mehreren Modellvokabularen besteht, die auf der relativen Repräsentationstheorie basieren. In der Dekodierungsphase ordnet DeePEn die von verschiedenen großen Modellen ausgegebenen Wahrscheinlichkeitsverteilungen diesem Raum zur Fusion zu. Im gesamten Prozess ist kein Parametertraining erforderlich. Das Bild unten zeigt die Methode von DeePEn. Bei N-Modellen für Ensembles erstellt DeePEn zunächst deren Transformationsmatrizen (d. h. relative Darstellungsmatrizen) und bildet Wahrscheinlichkeitsverteilungen aus mehreren heterogenen absoluten Räumen in einen einheitlichen relativen Raum ab. Bei jedem Dekodierungsschritt führen alle Modelle Vorwärtsberechnungen durch und geben N Wahrscheinlichkeitsverteilungen aus. Diese Verteilungen werden in den relativen Raum abgebildet und aggregiert. Schließlich werden die Aggregationsergebnisse zurück in den absoluten Raum eines Modells (des Mastermodells) transformiert, um den nächsten Token zu bestimmen.
Abbildung 1: Schematische Darstellung. Unter diesen wird die relative Darstellungstransformationsmatrix durch Berechnen der Wörterinbettungsähnlichkeit zwischen jedem Token im Vokabular und dem zwischen den Modellen gemeinsam genutzten Ankertoken erhalten. Konstruieren Sie eine relative Darstellungstransformation Gegebene N Modelle, die integriert werden sollen, findet DeePEn zunächst den Schnittpunkt aller Modellvokabulare, d bulary , Und extrahieren Sie eine Teilmenge A⊆C oder verwenden Sie alle gemeinsamen Wörter als Ankerwortsatz A=C. Für jedes Modell berechnet DeePEn die Einbettungsähnlichkeit zwischen jedem Token im Vokabular und dem Ankertoken, um eine relative Darstellungsmatrix zu erhalten. Um schließlich das Problem der relativen Repräsentationsverschlechterung von Ausreißerwörtern zu überwinden, führt der Autor des Artikels eine Zeilennormalisierung der relativen Repräsentationsmatrix durch und führt eine Softmax-Operation für jede Zeile der Matrix durch, um die normalisierte relative Repräsentationsmatrix zu erhalten. Relative Darstellungsfusion Sobald das Modell die Wahrscheinlichkeitsverteilung ausgibt, verwendet DeePEn die normalisierte relative Darstellungsmatrix, um in eine relative Darstellung umzuwandeln:
そしてすべての相対表現の加重平均を実行して、集約された相対表現を取得します: ここで、 はモデル のコラボレーション重みです。著者らは、協調的な重み値を決定する 2 つの方法を試しました: (1) すべてのモデルに同じ重みを使用する DeePEn-Avg、(2) 検証セットのパフォーマンスに基づいて各モデルの重みを比例的に設定する DeePEn-Adapt。
集約された相対表現に基づいて次のトークンを決定するために、DeePEn はそれを相対空間からメイン モデル (開発セットで最もパフォーマンスの高いモデル) の絶対空間に変換します。 )。この逆変換を達成するために、DeePEn は検索ベースの戦略を採用して、その相対表現が集約された相対表現と同じである絶対表現を見つけます:
ここで、はモデル の絶対空間を表し、距離間の相対的な損失関数 (KL 発散) の尺度です。 DeePEn は、絶対表現 に対する損失関数 の勾配を利用して検索プロセスをガイドし、繰り返し検索を実行します。具体的には、DeePEn は検索の開始点 をマスター モデルの元の絶対表現に初期化し、それを更新します:
Wobei η ein Hyperparameter ist, der als relative Ensemble-Lernrate bezeichnet wird, und T die Anzahl der Suchiterationsschritte ist. Verwenden Sie abschließend die aktualisierte absolute Darstellung , um im nächsten Schritt den auszugebenden Token zu bestimmen.
Tabelle 1: Hauptexperimentergebnisse. Der erste Teil ist die Leistung eines einzelnen Modells, der zweite Teil ist das Ensemble-Lernen der Top-2-Modelle für jeden Datensatz und der dritte Teil ist die Integration der Top-4-Modelle. Durch Experimente kam der Autor der Arbeit zu folgenden Schlussfolgerungen: (1) Große Modelle haben ihre eigenen Stärken bei verschiedenen Aufgaben. Wie in Tabelle 1 gezeigt, gibt es erhebliche Unterschiede in der Leistung verschiedener großer Modelle bei unterschiedlichen Datensätzen. Beispielsweise erzielte LLaMA2-13B die höchsten Ergebnisse bei den TriviaQA- und NQ-Datensätzen, landete jedoch bei den anderen vier Aufgaben nicht unter den ersten vier. (2) Distribution Fusion hat bei verschiedenen Datensätzen konsistente Verbesserungen erzielt. Wie in Tabelle 1 gezeigt, erzielten DeePEn-Avg und DeePEn-Adapt Leistungsverbesserungen bei allen Datensätzen. Auf GSM8K wurde in Kombination mit Voting eine Leistungsverbesserung von +11,35 erreicht. Tabelle 2: Ensemble-Lernleistung bei unterschiedlicher Anzahl von Modellen.
Mit zunehmender Anzahl integrierter Modelle nimmt die Integrationsleistung zunächst zu und dann ab
. Der Autor fügt die Modelle entsprechend der Modellleistung in der Reihenfolge von hoch nach niedrig zum Ensemble hinzu und beobachtet dann die Leistungsänderungen. Wie in Tabelle 2 gezeigt, nimmt die Integrationsleistung bei der kontinuierlichen Einführung von Modellen mit schlechter Leistung zunächst zu und dann ab.
Tabelle 3: Ensemble-Lernen zwischen großen Modellen und Übersetzungsexpertenmodelle für den mehrsprachigen maschinellen Übersetzungsdatensatz Flores.
Integrieren Sie große Modelle und Expertenmodelle, um die Leistung bestimmter Aufgaben effektiv zu verbessern
. Die Autoren integrierten auch das große Modell LLaMA2-13B und das mehrsprachige Übersetzungsmodell NLLB für maschinelle Übersetzungsaufgaben. Wie in Tabelle 3 gezeigt, kann die Integration zwischen einem allgemeinen großen Modell und einem aufgabenspezifischen Expertenmodell die Leistung erheblich verbessern.
Es gibt einen endlosen Strom großer Models, aber es ist für ein Model schwierig, andere Models bei allen Aufgaben umfassend zu überwältigen. Daher ist die Frage, wie die komplementären Vorteile verschiedener Modelle genutzt werden können, zu einer wichtigen Forschungsrichtung geworden. Das in diesem Artikel vorgestellte DeePEn-Framework löst das Problem der Vokabularunterschiede zwischen verschiedenen großen Modellen bei der Verteilungsfusion ohne Parametertraining. Eine große Anzahl von Experimenten zeigt, dass DeePEn in Ensemble-Lernumgebungen mit unterschiedlichen Aufgaben, unterschiedlichen Modellnummern und unterschiedlichen Modellarchitekturen stabile Leistungsverbesserungen erzielt hat. Das obige ist der detaillierte Inhalt vonLLama+Mistral+…+Yi=? Das trainingsfreie heterogene große Modell integrierte Lernframework DeePEn ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn






 , Und extrahieren Sie eine Teilmenge A⊆C oder verwenden Sie alle gemeinsamen Wörter als Ankerwortsatz A=C.
, Und extrahieren Sie eine Teilmenge A⊆C oder verwenden Sie alle gemeinsamen Wörter als Ankerwortsatz A=C.  berechnet DeePEn die Einbettungsähnlichkeit zwischen jedem Token im Vokabular und dem Ankertoken, um eine relative Darstellungsmatrix
berechnet DeePEn die Einbettungsähnlichkeit zwischen jedem Token im Vokabular und dem Ankertoken, um eine relative Darstellungsmatrix 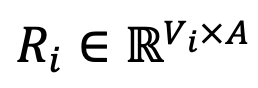 zu erhalten. Um schließlich das Problem der relativen Repräsentationsverschlechterung von Ausreißerwörtern zu überwinden, führt der Autor des Artikels eine Zeilennormalisierung der relativen Repräsentationsmatrix durch und führt eine Softmax-Operation für jede Zeile der Matrix durch, um die normalisierte relative Repräsentationsmatrix
zu erhalten. Um schließlich das Problem der relativen Repräsentationsverschlechterung von Ausreißerwörtern zu überwinden, führt der Autor des Artikels eine Zeilennormalisierung der relativen Repräsentationsmatrix durch und führt eine Softmax-Operation für jede Zeile der Matrix durch, um die normalisierte relative Repräsentationsmatrix 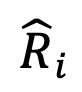 zu erhalten.
zu erhalten.  die Wahrscheinlichkeitsverteilung
die Wahrscheinlichkeitsverteilung  ausgibt, verwendet DeePEn die normalisierte relative Darstellungsmatrix, um
ausgibt, verwendet DeePEn die normalisierte relative Darstellungsmatrix, um  in eine relative Darstellung
in eine relative Darstellung  umzuwandeln:
umzuwandeln: 
 ここで、
ここで、 はモデル
はモデル 
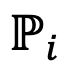 はモデル
はモデル 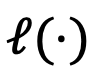 距離間の相対的な損失関数 (KL 発散) の尺度です。
距離間の相対的な損失関数 (KL 発散) の尺度です。  に対する損失関数
に対する損失関数 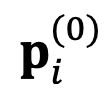 をマスター モデルの元の絶対表現に初期化し、それを更新します:
をマスター モデルの元の絶対表現に初期化し、それを更新します: 
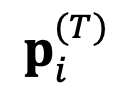 , um im nächsten Schritt den auszugebenden Token zu bestimmen.
, um im nächsten Schritt den auszugebenden Token zu bestimmen. 

