
Heim >Technologie-Peripheriegeräte >KI >Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-17 22:02:051222Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois at Urbana-Champaign (UIUC), darunter: Steven Xia , ein Doktorand im vierten Jahr, dessen Forschungsrichtung die automatische Codereparatur auf der Grundlage großer KI-Modelle ist; Deng Yinlin, ein Doktorand im vierten Jahr, dessen Forschungsrichtung die Codegenerierung auf der Grundlage großer KI-Modelle ist; , ist derzeit Student im dritten Jahr an der UIUC. Lehrer Zhang Lingming ist derzeit außerordentlicher Professor am Fachbereich Informatik der UIUC und beschäftigt sich hauptsächlich mit der Forschung im Zusammenhang mit Softwareentwicklung, maschinellem Lernen und großen Codemodellen.
Weitere Informationen finden Sie auf der persönlichen Homepage von Lehrer Zhang: https://lingming.cs.illinois.edu/
Da Devin (der erste vollautomatische KI-Softwareentwickler) es vorgeschlagen hat, KI für die Softwareentwicklung Das Design von Agenten ist in den Mittelpunkt der Forschung gerückt. Immer mehr agentenbasierte automatische KI-Softwareentwickler haben eine gute Leistung im SWE-Bench-Datensatz erzielt und viele echte GitHub-Probleme automatisch behoben.
Ein komplexes Agentensystem bringt jedoch zusätzlichen Aufwand und Unsicherheit mit sich. Müssen wir wirklich einen so komplexen Agenten verwenden, um GitHub-Probleme zu lösen? Kann eine agentenfreie Lösung annähernd an ihre Leistung herankommen?
Ausgehend von diesen beiden Problemen schlug das Team um Lehrer Zhang Lingming von der University of Illinois at Urbana-Champaign (UIUC) OpenAutoCoder-Agentless vor, eine einfache, effiziente und vollständig Open-Source-Lösung ohne Agenten, die ein echtes GitHub-Problem lösen kann für nur 0,34 $. Agentless hat in nur wenigen Tagen mehr als 300 GitHub-Stars auf GitHub angezogen und es in die Top 3 der wöchentlichen Liste der heißesten ML-Artikel von DAIR.AI geschafft.

Papier: AGENTLESS: Demystifying LLM-based Software Engineering Agents
Papieradresse: https://huggingface.co/papers/2407.01489
Open-Source-Code: https://github. com /OpenAutoCoder/Agentless
AWS-Forschungswissenschaftler Leo Boytsov sagte: „Das Agentless-Framework übertraf alle Open-Source-Agent-Lösungen und erreichte fast das Spitzenniveau von SWE Bench Lite (27 %). Darüber hinaus besiegte es es deutlich niedriger.“ Kosten: Alle Open-Source-Lösungen verwenden einen hierarchischen Abfrageansatz (indem LLM aufgefordert wird, Dateien, Klassen, Funktionen usw. zu finden), ermöglichen es LLM jedoch nicht, Planungsentscheidungen zu treffen Problemlösung bei der Softwareentwicklung, die einen einfachen zweiphasigen Ansatz verwendet, um Fehler in Ihrer Codebasis zu lokalisieren und zu beheben. In der Lokalisierungsphase verwendet Agentless einen hierarchischen Ansatz, um schrittweise auf verdächtige Dateien, Klassen/Funktionen und bestimmte Bearbeitungsorte einzugrenzen. Für Korrekturen wird ein einfaches Diff-Format (referenziert vom Open-Source-Tool Aider) verwendet, um mehrere Kandidaten-Patches zu generieren und diese zu filtern und zu sortieren.

Die Forscher verglichen Agentless mit bestehenden KI-Softwareagenten, einschließlich hochmoderner Open-Source- und kommerzieller/Closed-Source-Projekte. Überraschenderweise kann Agentless alle vorhandenen Open-Source-Software-Agenten zu geringeren Kosten übertreffen! Agentless löste 27,33 % der Probleme, den höchsten Wert unter den Open-Source-Lösungen, und löste es für durchschnittlich 0,29 US-Dollar pro Problem und etwa 0,34 US-Dollar im Durchschnitt für alle Probleme (sowohl lösbar als auch ungelöst).

Darüber hinaus hat Agentless das Potenzial, sich zu verbessern. Agentless kann 41 % der Probleme lösen, wenn alle generierten Patches berücksichtigt werden, eine Obergrenze, die auf erhebliches Verbesserungspotenzial in den Phasen der Patch-Sortierung und -Auswahl hinweist. Darüber hinaus ist Agentless in der Lage, einige einzigartige Probleme zu lösen, die selbst das beste kommerzielle Tool (Alibaba Lingma Agent) nicht lösen kann, was darauf hindeutet, dass es als Ergänzung zu bestehenden Tools verwendet werden kann.
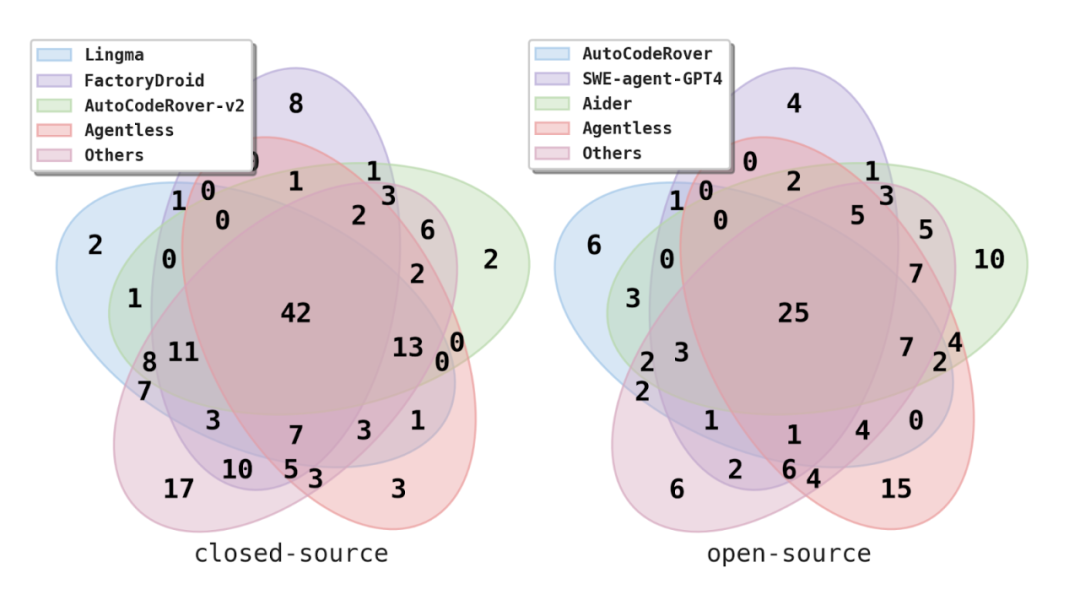
Analyse des SWE-bench Lite-Datensatzes
Die Forscher führten auch eine manuelle Inspektion und detaillierte Analyse des SWE-bench Lite-Datensatzes durch.
Die Studie ergab, dass 4,3 % der Probleme im SWE-bench Lite-Datensatz vollständige Antworten direkt in der Problembeschreibung lieferten, also dem richtigen Fix-Patch. Während die anderen 10 % der Fragen die genauen Schritte zur richtigen Lösung beschreiben. Dies deutet darauf hin, dass einige Probleme in SWE-bench Lite möglicherweise einfacher zu lösen sind.
Darüber hinaus stellte das Forschungsteam fest, dass 4,3 % der Probleme von Benutzern vorgeschlagene Lösungen oder Schritte in der Problembeschreibung enthielten, diese Lösungen jedoch nicht mit den tatsächlichen Patches der Entwickler übereinstimmten. Dies offenbart weiter ein potenzielles Problem mit diesem Benchmark, da diese irreführenden Lösungen dazu führen könnten, dass das KI-Tool falsche Lösungen generiert, indem es einfach der Problembeschreibung folgt.
In Bezug auf die Qualität der Problembeschreibung stellten die Forscher fest, dass die meisten Aufgaben in SWE-bench Lite zwar ausreichende Informationen enthalten und viele Aufgaben auch Fehlerbeispiele zur Reproduktion von Fehlern bereitstellen, bei 9,3 % der Probleme jedoch immer noch nicht genügend Informationen enthalten sind. Sie müssen beispielsweise eine neue Funktion implementieren oder eine Fehlermeldung hinzufügen, aber der spezifische Funktionsname oder die spezifische Fehlermeldungszeichenfolge ist in der Problembeschreibung nicht angegeben. Dies bedeutet, dass der Test fehlschlägt, selbst wenn die zugrunde liegende Funktionalität korrekt implementiert ist, wenn der Funktionsname oder die Fehlermeldungszeichenfolge nicht genau übereinstimmen.

Forscher der Princeton University und einer der Autoren von SWE-Bench, Ofir Press, bestätigten ihre Ergebnisse: „Agentless hat eine gute manuelle Analyse von SWE-Bench Lite durchgeführt. Sie glauben, dass die Theorie zu Lite die höchste Punktzahl hat.“ Ich denke, die tatsächliche Obergrenze liegt möglicherweise niedriger (ca. 80 %). Bei einigen Fragen sind die Informationen zu streng Problemteilmenge
 Um diese Probleme anzugehen, schlugen die Forscher eine strenge Problemteilmenge SWE-Bench Lite-S (mit 252 Fragen) vor. Insbesondere wurden Probleme, die genaue Patches oder irreführende Lösungen enthielten oder in der Problembeschreibung keine ausreichenden Informationen enthielten, von der SWE-Bench Lite (mit 300 Problemen) ausgeschlossen. Dadurch werden unangemessene Fragen beseitigt und der Schwierigkeitsgrad des Benchmarks standardisiert. Im Vergleich zum ursprünglichen SWE-bench Lite spiegelt der gefilterte Benchmark die wahren Fähigkeiten automatisierter Softwareentwicklungstools genauer wider.
Um diese Probleme anzugehen, schlugen die Forscher eine strenge Problemteilmenge SWE-Bench Lite-S (mit 252 Fragen) vor. Insbesondere wurden Probleme, die genaue Patches oder irreführende Lösungen enthielten oder in der Problembeschreibung keine ausreichenden Informationen enthielten, von der SWE-Bench Lite (mit 300 Problemen) ausgeschlossen. Dadurch werden unangemessene Fragen beseitigt und der Schwierigkeitsgrad des Benchmarks standardisiert. Im Vergleich zum ursprünglichen SWE-bench Lite spiegelt der gefilterte Benchmark die wahren Fähigkeiten automatisierter Softwareentwicklungstools genauer wider.
Fazit
Obwohl die agentenbasierte Softwareentwicklung sehr vielversprechend ist, glauben die Autoren, dass es für die Technologie- und Forschungsgemeinschaft an der Zeit ist, innezuhalten und über ihre wichtigsten Design- und Bewertungsmethoden nachzudenken, anstatt überstürzt weitere Agenten freizugeben. Forscher hoffen, dass Agentless dazu beitragen kann, die Grundlagen und Richtung von Agenten in der zukünftigen Softwareentwicklung neu zu bestimmen.
Das obige ist der detaillierte Inhalt vonDie agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr