



提升大型语言模型的推理能力是当前研究的最重要方向之一,在这类任务中,近期发布的很多小模型看起来表现不错,并且能够很好地应对这类任务。例如微软的Phi-3、Mistral 8x22B等模型。
研究人员们指出,当前大模型研究领域存在一个关键问题:很多研究未能准确地对现有LLM的能力进行基准测试。这提示我们需要花更多的时间来评估和测试当前LLM的能力水平。


这是因为目前的大多数研究都采用GSM8k、MATH、MBPP、HumanEval、SWEBench等测试集作为基准。由于模型是基于互联网抓取的大量数据集进行训练的,训练数据集可能包含了与基准测试中的问题高度相似的样本。
这种污染可能导致模型的推理能力被错误评估 —— 它们可能仅仅是在训练过程中蒙到题了,正好背出了正确答案。
刚刚,Scale AI 的一篇论文对当前最热门的大模型进行了深度调查,包括 OpenAI 的 GPT-4、Gemini、Claude、Mistral、Llama、Phi、Abdin 等系列下参数量不同的模型。
测试结果证实了一个广泛的疑虑:许多模型受到了基准数据的污染。

论文标题:A Careful Examination of Large Language Model Performance on Grade School Arithmetic
论文链接:https://arxiv.org/pdf/2405.00332
为了避免数据污染问题,来自 Scale AI 的研究者们未使用任何 LLM 或其他合成数据来源,完全依靠人工注释创建了 GSM1k 数据集。与 GSM8k 相似,GSM1k 内含有 1250 道小学级数学题。为了保证基准测试公平,研究者们尽力确保了 GSM1k 在难度分布上与 GSM8k 是相似的。在 GSM1k 上,研究者对一系列领先的开源和闭源大型语言模型进行了基准测试,结果发现表现最差的模型在 GSM1k 上的性能比在 GSM8k 上低 13%。
尤其是以量小质优闻名的 Mistral 和 Phi 模型系列,根据 GSM1k 的测试结果显示,几乎其中的所有版本都显示出了过拟合的一致证据。
通过进一步分析发现,模型生成 GSM8k 样本的概率与其在 GSM8k 和 GSM1k 之间的表现差距之间存在正相关关系(相关系数 r^2 = 0.32)。这强烈表明,过拟合的主要原因是模型部分背出了 GSM8k 中的样本。不过,Gemini、GPT、Claude 以及 Llama2 系列过显示出的拟合迹象非常少。此外,包括最过拟合的模型在内,所有模型仍能够成功地泛化到新的小学数学问题,虽然有时的成功率低于其基准数据所示。

Scale AI 目前不打算公开发布 GSM1k,以防未来发生类似的数据污染问题。他们计划定期对所有主要的开源和闭源 LLM 持续进行评估,还将开源评估代码,以便后续研究复现论文中的结果。
GSM1k 数据集
GSM1k 内包含 1250 道小学数学题。这些问题只需基本的数学推理即可解决。Scale AI 向每位人工注释者展示 3 个 GSM8k 的样本问题,并要求他们提出难度相似的新问题,得到了 GSM1k 数据集。研究者们要求人工注释者们不使用任何高级数学概念,只能使用基本算术(加法、减法、乘法和除法)来出题。与 GSM8k 一样,所有题的解都是正整数。在构建 GSM1k 数据集的过程中,也没有使用任何语言模型。
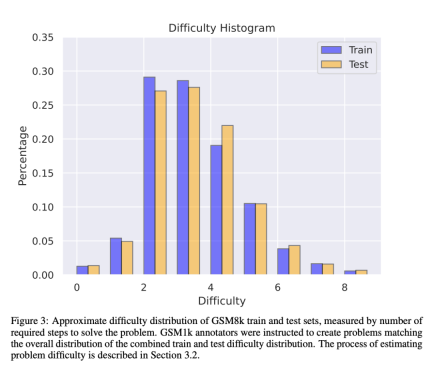
为了避免 GSM1k 数据集的数据污染问题,Scale AI 目前不会公开发布该数据集,但将开源 GSM1k 评估框架,该框架基于 EleutherAI 的 LM Evaluation Harness。
但 Scale AI 承诺,在以下两个条件中先达成某一项后,将在 MIT 许可证下发布完整的 GSM1k 数据集:(1) 有三个基于不同预训练基础模型谱系的开源模型在 GSM1k 上达到 95% 的准确率;(2) 至 2025 年底。届时,小学数学很可能不再足以作为评估 LLM 性能的有效基准。
为了评估专有模型,研究者将通过 API 的方式发布数据集。之所以采取这种发布方式,是论文作者们认为,LLM 供应商通常不会使用 API 数据点来训练模型模型。尽管如此,如果 GSM1k 数据通过 API 泄露了,论文作者还保留了未出现在最终 GSM1k 数据集中的数据点,这些备用数据点将在以上条件达成时随 GSM1k 一并发布。
他们希望未来的基准测试发布时也能遵循类似的模式 —— 先不公开发布,预先承诺在未来某个日期或满足某个条件时发布,以防被操纵。
此外,尽管 Scale AI 尽力确保了 GSM8k 和 GSM1k 之间在最大程度上一致。但 GSM8k 的测试集已经公开发布并广泛地用于模型测试,因此 GSM1k 和 GSM8k 仅是在理想情况下的近似。以下评估结果是 GSM8k 和 GSM1k 的分布并非完全相同的情况下得出的。
评估结果
为了对模型进行评估,研究者使用了 EleutherAI 的 LM Evaluation Harness 分支,并使用了默认设置。GSM8k 和 GSM1k 问题的运行 prompt 相同,都是从 GSM8k 训练集中随机抽取 5 个样本,这也是该领域的标准配置(完整的 prompt 信息见附录 B)。
所有开源模型都在温度为 0 时进行评估,以保证可重复性。LM 评估工具包提取响应中的最后一个数字答案,并将其与正确答案进行比较。因此,以与样本不符的格式生成「正确」答案的模型响应将被标记为不正确。
对于开源模型,如果模型与库兼容,会使用 vLLM 来加速模型推断,否则默认使用标准 HuggingFace 库进行推理。闭源模型通过 LiteLLM 库进行查询,该库统一了所有已评估专有模型的 API 调用格式。所有 API 模型结果均来自 2024 年 4 月 16 日至 4 月 28 日期间的查询,并使用默认设置。
在评估的模型方面,研究者是根据受欢迎程度选择的,此外还评估了几个在 OpenLLMLeaderboard 上排名靠前但鲜为人知的模型。
有趣的是,研究者在这个过程中发现了古德哈特定律(Goodhart's law)的证据:许多模型在 GSM1k 上的表现比 GSM8k 差很多,这表明它们主要是在迎合 GSM8k 基准,而不是在真正提高模型推理能力。所有模型的性能见下图附录 D。
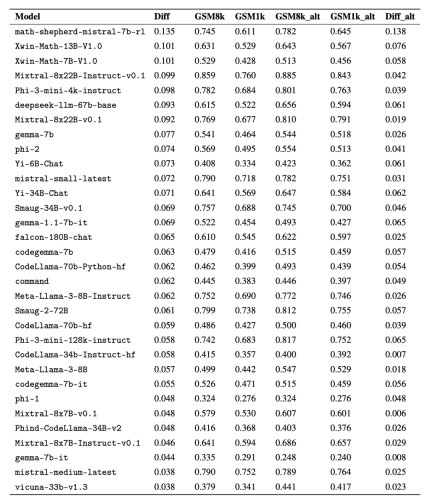

为了进行公平对比,研究者按照模型在 GSM8k 上的表现对它们进行了划分,并与其他表现类似的模型进行了对比(图 5、图 6、图 7)。
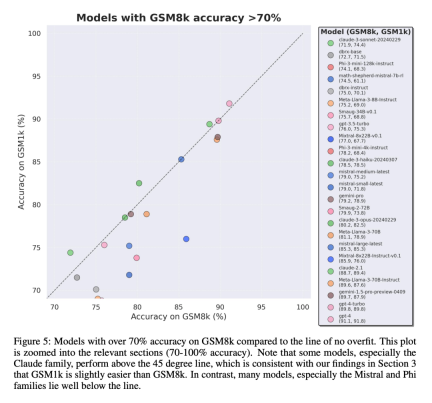


得出了哪些结论?
尽管研究者提供了多个模型的客观评估结果,但同时表示,解释评估结果就像对梦境的解释一样,往往是一项非常主观的工作。在论文的最后一部分,他们以更主观的方式阐述了上述评估的四个启示:
结论 1: 一些模型系列是系统性过拟合
虽然通常很难从单一数据点或模型版本中得出结论,但检查模型系列并观察过拟合模式,可以做出更明确的陈述。一些模型系列,包括 Phi 和 Mistral,几乎每一个模型版本和规模都显示出在 GSM8k 上比 GSM1k 表现更强的系统趋势。还有其他模型系列,如 Yi、Xwin、Gemma 和 CodeLlama 也在较小程度上显示出这种模式。
结论 2: 其他模型,尤其是前沿模型,没有表现出过拟合的迹象
许多模型在所有性能区域都显示出很小的过拟合迹象,特别是包括专有 Mistral Large 在内的所有前沿或接近前沿的模型,在 GSM8k 和 GSM1k 上的表现似乎相似。对此,研究者提出了两个可能的假设:1)前沿模型具有足够先进的推理能力,因此即使它们的训练集中已经出现过 GSM8k 问题,它们也能泛化到新的问题上;2)前沿模型的构建者可能对数据污染更为谨慎。
虽然不能查看每个模型的训练集,也无法确定这些假设,但支持前者的一个证据是,Mistral Large 是 Mistral 系列中唯一没有过拟合迹象的模型。Mistral 只确保其最大模型不受数据污染的假设似乎不太可能,因此研究者倾向于足够强大的 LLM 也会在训练过程中学习基本的推理能力。如果一个模型学会了足够强的推理能力来解决给定难度的问题,那么即使 GSM8k 出现在其训练集中,它也能够泛化到新的问题上。
结论 3: 过拟合的模型仍然具有推理能力
很多研究者对模型过拟合的一种担心是,模型无法进行推理,而只是记忆训练数据中的答案,但本论文的结果并不支持这一假设。模型过拟合的事实并不意味着它的推理能力很差,而仅仅意味着它没有基准所显示的那么好。事实上,研究者发现许多过拟合模型仍然能够推理和解决新问题。例如,Phi-3 在 GSM8k 和 GSM1k 之间的准确率几乎下降了 10%,但它仍能正确解决 68% 以上的 GSM1k 问题 —— 这些问题肯定没有出现在它的训练分布中。这一表现与 dbrx-instruct 等更大型的模型相似,而后者包含的参数数量几乎是它们的 35 倍。同样地,即使考虑到过度拟合的因素,Mistral 模型仍然是最强的开源模型之一。这为本文结论提供了更多证据,即足够强大的模型可以学习基本推理,即使基准数据意外泄漏到训练分布中,大多数过拟合模型也可能出现这种情况。
结论 4: 数据污染可能不是过拟合的完整解释
一个先验的、自然的假设是,造成过拟合的主要原因是数据污染,例如,在创建模型的预训练或指令微调部分,测试集被泄露了。以往的研究表明,模型会对其在训练过程中见过的数据赋予更高的对数似然性(Carlini et al. [2023])。研究者通过测量模型从 GSM8k 测试集中生成样本的概率,并将其与 GSM8k 和 GSM1k 相比的过拟合程度进行比较,来验证数据污染是造成过拟合的原因这一假设。
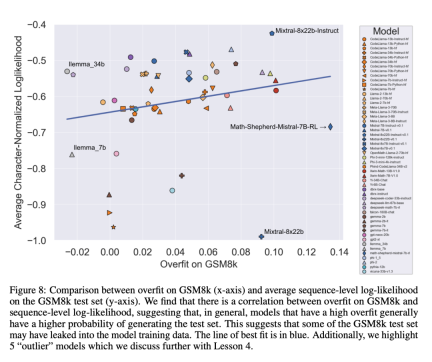
研究者表示,数据污染可能并不是全部原因。他们通过几个异常值观察到了这一点。仔细研究这些异常值可以发现,每个字符对数似然值最低的模型(Mixtral-8x22b)和每个字符对数似然值最高的模型(Mixtral-8x22b-Instruct)不仅是同一模型的变体,而且具有相似的过拟合程度。更有趣的是,过拟合程度最高的模型(Math-Shepherd-Mistral-7B-RL (Yu et al. [2023]))的每个字符对数似然值相对较低(Math Shepherd 使用合成数据在流程级数据上训练奖励模型)。
因此,研究者假设奖励建模过程可能泄露了有关 GSM8k 的正确推理链的信息,即使这些问题本身从未出现在数据集中。最后他们发现, Llema 模型具有高对数似然和最小过拟合。由于这些模型是开源的,其训练数据也是已知的,因此正如 Llema 论文中所述,训练语料库中出现了几个 GSM8k 问题实例。不过,作者发现这几个实例并没有导致严重的过拟合。这些异常值的存在表明,GSM8k 上的过拟合并非纯粹是由于数据污染造成的,而可能是通过其他间接方式造成的,例如模型构建者收集了与基准性质相似的数据作为训练数据,或者根据基准上的表现选择最终模型检查点,即使模型本身可能在训练的任何时候都没有看到过 GSM8k 数据集。反之亦然:少量的数据污染并不一定会导致过拟合。
更多研究细节,可参考原论文。
以上是终于有人调查了小模型过拟合:三分之二都有数据污染,微软Phi-3、Mixtral 8x22B被点名的详细内容。更多信息请关注PHP中文网其他相关文章!

 人工智能可以帮助我们实现工作与生活的平衡吗? - 分析VidhyaApr 18, 2025 am 09:27 AM
人工智能可以帮助我们实现工作与生活的平衡吗? - 分析VidhyaApr 18, 2025 am 09:27 AM介绍 Joanna Maciejewska最近在X上分享了一个有见地的观察结果: AI推动最大的挑战? 这是错误的。我希望AI处理洗衣和菜肴,以便我可以专注于艺术和写作,而不是相反。 - 乔安娜·马
 Llama 3.1的工具呼叫指南Apr 18, 2025 am 09:26 AM
Llama 3.1的工具呼叫指南Apr 18, 2025 am 09:26 AMMeta的Llama 3.1:深入研究开源LLM功能 Meta继续以开源大语模型(LLM)领导该指控。 骆驼一家从骆驼变成骆驼2,骆驼3和现在的骆驼3.1,表明了对
 什么是SPC图表? - 分析VidhyaApr 18, 2025 am 09:24 AM
什么是SPC图表? - 分析VidhyaApr 18, 2025 am 09:24 AM介绍 统计过程控制(SPC)图表是质量管理中的重要工具,使组织能够监视,控制和改善其流程。 通过应用统计方法,SPC图在视觉上表示数据变化
 前30个MySQL面试问题 - 分析VidhyaApr 18, 2025 am 09:23 AM
前30个MySQL面试问题 - 分析VidhyaApr 18, 2025 am 09:23 AM本指南通过涵盖了跨越初学者,中级和高级级别的30个问题,为您的MySQL面试提供了更大的准备。 MySQL是数据管理和分析中的重要工具,通过理论概念和实际查询示例探讨了
 非关系数据库和关系数据库Apr 18, 2025 am 09:22 AM
非关系数据库和关系数据库Apr 18, 2025 am 09:22 AM选择正确的数据库:关系与非关系 想象一下管理繁华的咖啡馆:无数的订单,波动的库存水平和苛刻的客户。 有效的工具对于成功至关重要。 同样,处理大数据集需要C
 2025年的前6个人形机器人 - 分析VidhyaApr 18, 2025 am 09:16 AM
2025年的前6个人形机器人 - 分析VidhyaApr 18, 2025 am 09:16 AM人形机器人:一瞥未来 几个世纪以来,人形机器人的概念(从复杂的发条机制到复杂的AI驱动创造物)捕捉了我们的想象力。 早期示例,例如雅克·德·沃卡森(Jacques de Vaucanson)的技工
 SQL中的concat是什么? - 分析VidhyaApr 18, 2025 am 09:10 AM
SQL中的concat是什么? - 分析VidhyaApr 18, 2025 am 09:10 AMSQL的Concat函数:综合的字符串串联指南 结构化查询语言(SQL)cont函数是将两个或多个字符串组合到单个统一的字符串中的首选工具。这对于数据格式和MA是无价的
 前13位印度Genai领导人将于2025年跟随Apr 18, 2025 am 09:09 AM
前13位印度Genai领导人将于2025年跟随Apr 18, 2025 am 09:09 AM印度的前13名生成AI领导者:塑造AI的未来 在政府的支持以及众多企业和初创企业的贡献的推动下,印度迅速发展的生物AI(Genai)部门正在经历爆炸性的增长。 本文sp


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

Dreamweaver CS6
视觉化网页开发工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

