


在自然语言处理中,有很多信息其实是重复的。
如果能将提示词进行有效地压缩,某种程度上也相当于扩大了模型支持上下文的长度。
现有的信息熵方法是通过删除某些词或短语来减少这种冗余。
然而,基于信息熵的计算仅涵盖了文本的单向上下文,可能会忽略压缩所需的关键信息;而且,信息熵的计算方式并非完全符合压缩提示词的实际目的。
为了迎接这些挑战,清华大学和微软的研究人员共同提出了一项全新的数据处理流程,名为LLMLingua-2。其旨在从大型语言模型(LLM)中提取知识,通过压缩提示词实现信息的精炼,同时确保关键信息不会丢失。

项目在GitHub上已经斩获3.1k星
结果显示,LLMLingua-2可以将文本长度大幅缩减至最初的20%,有效减少了处理时间和成本。
此外,与前一版本LLMLingua以及其他类似技术相比,LLMLingua 2的处理速度提高了3到6倍。

论文地址:https://arxiv.org/abs/2403.12968
在这个过程中,原始文本首先被输入模型。
模型会评估每个词的重要性,决定是保留还是删除,同时也会考虑到词语之间的关系。
最终,模型会选择那些评分最高的词汇组成一个更简短的提示词。

团队在包括MeetingBank、LongBench、ZeroScrolls、GSM8K和BBH在内的多个数据集上测试了LLMLingua-2模型。
尽管这个模型体积不大,但它在基准测试中取得了显著的性能提升,并且证明了其在不同的大语言模型(从GPT-3.5到Mistral-7B)和语种(从英语到中文)上具有出色的泛化能力。
系统提示:
作为一名杰出的语言学家,你擅长将较长的文段压缩成简短的表达方式,方法是去除那些不重要的词汇,同时尽可能多地保留信息。
用户提示:
请将给定的文本压缩成简短的表达形式,使得你(GPT-4)能够尽可能准确地还原原文。不同于常规的文本压缩,我需要你遵循以下五个条件:
1. 只移除那些不重要的词汇。
2. 保持原始词汇的顺序不变。
3. 保持原始词汇不变。
4. 不使用任何缩写或表情符号。
5. 不添加任何新的词汇或符号。
请尽可能地压缩原文,同时保留尽可能多的信息。如果你明白了,请对以下文本进行压缩:{待压缩文本}
压缩后的文本是:[...]
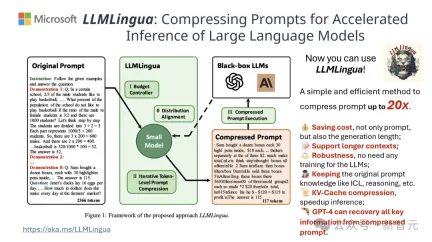
结果显示,在问答、摘要撰写和逻辑推理等多种语言任务中,LLMLingua-2都显著优于原有的LLMLingua模型和其他选择性上下文策略。
值得一提的是,这种压缩方法对于不同的大语言模型(从GPT-3.5到Mistral-7B)和不同的语言(从英语到中文)同样有效。
而且,只需两行代码,就可以实现LLMLingua-2的部署。
目前,该模型已经被集成到了广泛使用的RAG框架LangChain和LlamaIndex当中。
实现方法
为了克服现有基于信息熵的文本压缩方法所面临的问题,LLMLingua-2采取了一种创新的数据提炼策略。
这一策略通过从GPT-4这样的大语言模型中抽取精华信息,实现了在不损失关键内容和避免添加错误信息的前提下,对文本进行高效压缩。
提示设计
要想充分利用GPT-4的文本压缩潜力,关键在于如何设定精确的压缩指令。
也就是在压缩文本时,指导GPT-4仅移除那些在原始文本中不那么重要的词汇,同时避免在此过程中引入任何新的词汇。
这样做的目的是为了确保压缩后的文本尽可能地保持原文的真实性和完整性。

标注与筛选
研究人员利用了从GPT-4等大语言模型中提炼出的知识,开发了一种新颖的数据标注算法。
这个算法能够对原文中的每一个词汇进行标注,明确指出在压缩过程中哪些词汇是必须保留的。
为了保证所构建数据集的高质量,他们还设计了两种质量监控机制,专门用来识别并排除那些品质不佳的数据样本。

压缩器
最后,研究人员将文本压缩的问题转化为了一个对每个词汇(Token)进行分类的任务,并采用了强大的Transformer作为特征提取器。
这个工具能够理解文本的前后关系,从而精确地抓取对于文本压缩至关重要的信息。
通过在精心构建的数据集上进行训练,研究人员的模型能够根据每个词汇的重要性,计算出一个概率值来决定这个词汇是应该被保留在最终的压缩文本中,还是应该被舍弃。

性能评估
研究人员在一系列任务上测试了LLMLingua-2的性能,这些任务包括上下文学习、文本摘要、对话生成、多文档和单文档问答、代码生成以及合成任务,既包括了域内的数据集也包括了域外的数据集。
测试结果显示,研究人员的方法在保持高性能的同时,减少了最小的性能损失,并且在任务不特定的文本压缩方法中表现突出。
- 域内测试(MeetingBank)
研究人员将LLMLingua-2在MeetingBank测试集上的表现与其他强大的基线方法进行了对比。
尽管他们的模型规模远小于基线中使用的LLaMa-2-7B,但在问答和文本摘要任务上,研究人员的方法不仅大幅提升了性能,而且与原始文本提示的表现相差无几。

- 域外测试(LongBench、GSM8K和BBH)
考虑到研究人员的模型仅在MeetingBank的会议记录数据上进行了训练,研究人员进一步探索了其在长文本、逻辑推理和上下文学习等不同场景下的泛化能力。
值得一提的是,尽管LLMLingua-2只在一个数据集上训练,但在域外的测试中,它的表现不仅与当前最先进的任务不特定压缩方法相媲美,甚至在某些情况下还有过之而无不及。

即使是研究人员的较小模型(BERT-base大小),也能达到与原始提示相当的性能,在某些情况下甚至略高于原始提示。
虽然研究人员的方法取得了可喜的成果,但与其他任务感知压缩方法(如Longbench上的LongLLMlingua)相比,研究人员的方法还存在不足。
研究人员将这种性能差距归因于它们从问题中获取的额外信息。不过,研究人员的模型具有与任务无关的特点,因此在不同场景中部署时,它是一种具有良好通用性的高效选择。
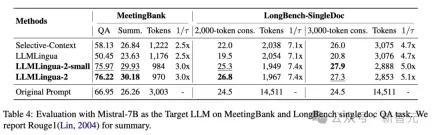
上表4列出了使用Mistral-7Bv0.1 4作为目标LLM的不同方法的结果。
与其他基线方法相比,研究人员的方法在性能上有明显的提升,展示了其在目标LLM上良好的泛化能力。
值得注意的是,LLMLingua-2的性能甚至优于原始提示。
研究人员推测,Mistral-7B在管理长上下文方面的能力可能不如GPT-3.5-Turbo。
研究人员的方法通过提供信息密度更高的短提示,有效提高了 Mistral7B 的最终推理性能。
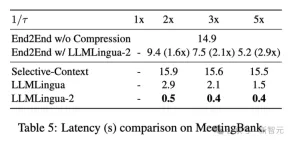
上表5显示了不同系统在不同压缩比的V100-32G GPU上的延迟。
结果表明,与其他压缩方法相比,LLMLingua2的计算开销要小得多,可以实现1.6倍到2.9倍的端到端速度提升。
此外,研究人员的方法还能将GPU内存成本降低8倍,从而降低对硬件资源的需求。
上下文意识观察 研究人员观察到,随着压缩率的增加,LLMLingua-2可以有效地保持与完整上下文相关的信息量最大的单词。
这要归功于双向上下文感知特征提取器的采用,以及明确朝着及时压缩目标进行优化的策略。

研究人员观察到,随着压缩率的增加,LLMLingua-2可以有效地保持与完整上下文相关的信息量最大的单词。
这要归功于双向上下文感知特征提取器的采用,以及明确朝着及时压缩目标进行优化的策略。

最后研究人员让GPT-4 从 LLMLingua-2压缩提示中重构原始提示音。
结果表明,GPT-4可以有效地重建原始提示,这表明在LLMLingua-2压缩过程中并没有丢失基本信息。
以上是清华微软开源全新提示词压缩工具,长度骤降80%!GitHub怒砍3.1K星的详细内容。更多信息请关注PHP中文网其他相关文章!

 让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM
让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM科学家已经广泛研究了人类和更简单的神经网络(如秀丽隐杆线虫中的神经网络),以了解其功能。 但是,出现了一个关键问题:我们如何使自己的神经网络与新颖的AI一起有效地工作
 新的Google泄漏揭示了双子AI的订阅更改Apr 27, 2025 am 11:08 AM
新的Google泄漏揭示了双子AI的订阅更改Apr 27, 2025 am 11:08 AMGoogle的双子座高级:新的订阅层即将到来 目前,访问Gemini Advanced需要$ 19.99/月Google One AI高级计划。 但是,Android Authority报告暗示了即将发生的变化。 最新的Google P中的代码
 数据分析加速度如何求解AI的隐藏瓶颈Apr 27, 2025 am 11:07 AM
数据分析加速度如何求解AI的隐藏瓶颈Apr 27, 2025 am 11:07 AM尽管围绕高级AI功能炒作,但企业AI部署中潜伏的巨大挑战:数据处理瓶颈。首席执行官庆祝AI的进步时,工程师努力应对缓慢的查询时间,管道超载,一个
 Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM处理文档不再只是在您的AI项目中打开文件,而是将混乱变成清晰度。诸如PDF,PowerPoints和Word之类的文档以各种形状和大小淹没了我们的工作流程。检索结构化
 如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM
如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM利用Google的代理开发套件(ADK)的力量创建具有现实世界功能的智能代理!该教程通过使用ADK来构建对话代理,并支持Gemini和GPT等各种语言模型。 w
 在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM
在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM摘要: 小型语言模型 (SLM) 专为效率而设计。在资源匮乏、实时性和隐私敏感的环境中,它们比大型语言模型 (LLM) 更胜一筹。 最适合专注型任务,尤其是在领域特异性、控制性和可解释性比通用知识或创造力更重要的情况下。 SLM 并非 LLMs 的替代品,但在精度、速度和成本效益至关重要时,它们是理想之选。 技术帮助我们用更少的资源取得更多成就。它一直是推动者,而非驱动者。从蒸汽机时代到互联网泡沫时期,技术的威力在于它帮助我们解决问题的程度。人工智能 (AI) 以及最近的生成式 AI 也不例
 如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM
如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM利用Google双子座的力量用于计算机视觉:综合指南 领先的AI聊天机器人Google Gemini扩展了其功能,超越了对话,以涵盖强大的计算机视觉功能。 本指南详细说明了如何利用
 Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM2025年的AI景观正在充满活力,而Google的Gemini 2.0 Flash和Openai的O4-Mini的到来。 这些尖端的车型分开了几周,具有可比的高级功能和令人印象深刻的基准分数。这个深入的比较


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3汉化版
中文版,非常好用

