



Stable Diffusion 3 的论文终于来了!
这个模型于两周前发布,采用了与 Sora 相同的 DiT(Diffusion Transformer)架构,一经发布就引起了不小的轰动。
与之前版本相比,Stable Diffusion 3 生成的图质量有了显着提升,现在支持多主题提示,并且文字书写效果也得到了改善,不再出现乱码情况。
Stability AI 指出,Stable Diffusion 3 是一个系列模型,其参数量从800M到8B不等。这一参数范围意味着该模型可以在许多便携设备上直接运行,从而显着降低了使用AI大型模型的门槛。
在最新发布的论文中,Stability AI 表示,在基于人类偏好的评估中,Stable Diffusion 3 优于当前最先进的文本到图像生成系统,如 DALL・E 3、Midjourney v6 和 Ideogram v1。不久之后,他们将公开该研究的实验数据、代码和模型权重。

在论文中,Stability AI 透露了关于 Stable Diffusion 3 的更多细节。

- 论文标题:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- 论文链接:https://stabilityai-public-packages.s3.us-west-2.amazonaws .com/Stable+Diffusion+3+Paper.pdf
架构细节
对于文本到图像的生成,Stable Diffusion 3 模型必须同时考虑文本和图像两种模式。因此,论文作者称这种新架构为 MMDiT,意指其处理多种模态的能力。与之前版本的 Stable Diffusion 一样,作者使用预训练模型来推导合适的文本和图像表征。具体来说,他们使用了三种不同的文本嵌入模型 —— 两种 CLIP 模型和 T5—— 来编码文本表征,并使用改进的自编码模型来编码图像 token。
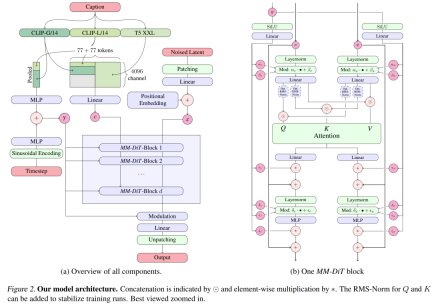
Stable Diffusion 3 模型架构。
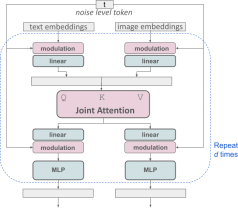
改进的多模态扩散 transformer:MMDiT 块。
SD3 架构基于 Sora 核心研发成员 William Peebles 和纽约大学计算机科学助理教授谢赛宁合作提出的 DiT。由于文本嵌入和图像嵌入在概念上有很大不同,因此 SD3 的作者对两种模态使用两套不同的权重。如上图所示,这相当于为每种模态设置了两个独立的transformer,但将两种模态的序列结合起来进行注意力运算,从而使两种表征都能在各自的空间内工作,同时也将另一种表征考虑在内。
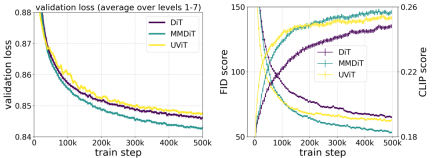
在训练过程中测量视觉保真度和文本对齐度时,作者提出的 MMDiT 架构优于 UViT 和 DiT 等成熟的文本到图像骨干。
通过这种方法,信息可以在图像和文本 token 之间流动,从而提高模型的整体理解能力,并改善所生成输出的文字排版。正如论文中所讨论的那样,这种架构也很容易扩展到视频等多种模式。

得益于 Stable Diffusion 3 改进的提示遵循能力,新模型有能力制作出聚焦于各种不同主题和质量的图像,同时还能高度灵活地处理图像本身的风格。

通过 re-weighting 改进 Rectified Flow
Stable Diffusion 3 采用 Rectified Flow(RF)公式,在训练过程中,数据和噪声以线性轨迹相连。这使得推理路径更加平直,从而减少了采样步骤。此外,作者还在训练过程中引入了一种新的轨迹采样计划。他们假设,轨迹的中间部分会带来更具挑战性的预测任务,因此该计划给予轨迹中间部分更多权重。他们使用多种数据集、指标和采样器设置进行比较,并将自己提出的方法与 LDM、EDM 和 ADM 等 60 种其他扩散轨迹进行了测试。结果表明,虽然以前的 RF 公式在少步采样情况下性能有所提高,但随着步数的增加,其相对性能会下降。相比之下,作者提出的重新加权 RF 变体能持续提高性能。
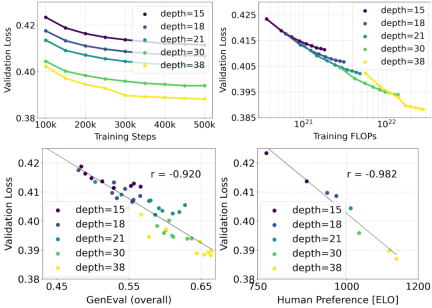
扩展 Rectified Flow Transformer 模型
作者利用重新加权的 Rectified Flow 公式和 MMDiT 骨干对文本到图像的合成进行了扩展(scaling)研究。他们训练的模型从带有 450M 个参数的 15 个块到带有 8B 个参数的 38 个块不等,并观察到验证损失随着模型大小和训练步骤的增加而平稳降低(上图的第一行)。为了检验这是否转化为对模型输出的有意义改进,作者还评估了自动图像对齐指标(GenEval)和人类偏好分数(ELO)(上图第二行)。结果表明,这些指标与验证损失之间存在很强的相关性,这表明后者可以很好地预测模型的整体性能。此外,scaling 趋势没有显示出饱和的迹象,这让作者对未来继续提高模型性能持乐观态度。
灵活的文本编码器
通过移除用于推理的内存密集型 4.7B 参数 T5 文本编码器,SD3 的内存需求可显著降低,而性能损失却很小。如图所示,移除该文本编码器不会影响视觉美感(不使用 T5 时的胜率为 50%),只会略微降低文本一致性(胜率为 46%)。不过,作者建议在生成书面文本时加入 T5,以充分发挥 SD3 的性能,因为他们观察到,如果不加入 T5,生成排版的性能下降幅度更大(胜率为 38%),如下图所示:

只有在呈现涉及许多细节或大量书面文本的非常复杂的提示时,移除 T5 进行推理才会导致性能显著下降。上图显示了每个示例的三个随机样本。
模型性能
作者将 Stable Diffusion 3 的输出图像与其他各种开源模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及闭源模型(如 DALL-E 3、Midjourney v6 和 Ideogram v1)进行了比较,以便根据人类反馈来评估性能。在这些测试中,人类评估员从每个模型中获得输出示例,并根据模型输出在多大程度上遵循所给提示的上下文(prompt following)、在多大程度上根据提示渲染文本(typography)以及哪幅图像具有更高的美学质量(visual aesthetics)来选择最佳结果。
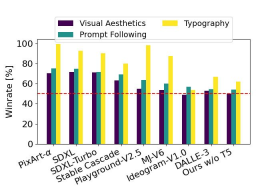
以 SD3 为基准,这个图表概述了它在基于人类对视觉美学、提示遵循和文字排版的评估中的胜率。
从测试结果来看,作者发现 Stable Diffusion 3 在上述所有方面都与当前最先进的文本到图像生成系统相当,甚至更胜一筹。
在消费级硬件上进行的早期未优化推理测试中,最大的 8B 参数 SD3 模型适合 RTX 4090 的 24GB VRAM,使用 50 个采样步骤生成分辨率为 1024x1024 的图像需要 34 秒。

此外,在最初发布时,Stable Diffusion 3 将有多种变体,从 800m 到 8B 参数模型不等,以进一步消除硬件障碍。


更多细节请参考原论文。
参考链接:https://stability.ai/news/stable-diffusion-3-research-paper
以上是Stable Diffusion 3论文终于发布,架构细节大揭秘,对复现Sora有帮助?的详细内容。更多信息请关注PHP中文网其他相关文章!

 10个生成AI编码扩展,在VS代码中,您必须探索Apr 13, 2025 am 01:14 AM
10个生成AI编码扩展,在VS代码中,您必须探索Apr 13, 2025 am 01:14 AM嘿,编码忍者!您当天计划哪些与编码有关的任务?在您进一步研究此博客之前,我希望您考虑所有与编码相关的困境,这是将其列出的。 完毕? - 让&#8217
 烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PM
烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PMAI增强食物准备 在新生的使用中,AI系统越来越多地用于食品制备中。 AI驱动的机器人在厨房中用于自动化食物准备任务,例如翻转汉堡,制作披萨或组装SA
 Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM
Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM介绍 了解Python功能中变量的名称空间,范围和行为对于有效编写和避免运行时错误或异常至关重要。在本文中,我们将研究各种ASP
 视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM
视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM介绍 想象一下,穿过美术馆,周围是生动的绘画和雕塑。现在,如果您可以向每一部分提出一个问题并获得有意义的答案,该怎么办?您可能会问:“您在讲什么故事?
 联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM
联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM继续使用产品节奏,本月,Mediatek发表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。这些产品填补了Mediatek业务中更传统的部分,其中包括智能手机的芯片
 本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM
本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:现在是星期一早上。作为AI驱动的招聘人员,您更聪明,而不是更努力。您在手机上登录公司的仪表板。它告诉您三个关键角色已被采购,审查和计划的FO
 生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM我猜你一定是。 我们似乎都知道,心理障碍包括各种chat不休,这些chat不休,这些chat不休,混合了各种心理术语,并且常常是难以理解的或完全荒谬的。您需要做的一切才能喷出fo
 原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM
原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM根据本周发表的一项新研究,只有在2022年制造的塑料中,只有9.5%的塑料是由回收材料制成的。同时,塑料在垃圾填埋场和生态系统中继续堆积。 但是有帮助。一支恩金团队


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver Mac版
视觉化网页开发工具

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

