



文本嵌入(word embedding)是自然语言处理(NLP)领域的基础技术,它能够将文本映射到语义空间,并转化为稠密的矢量表示。这种方法已经被广泛应用于各种NLP任务,包括信息检索(IR)、问答、文本相似度计算和推荐系统等。通过文本嵌入,我们可以更好地理解文本的含义和关系,从而提高NLP任务的效果。
在信息检索(IR)领域,第一阶段的检索通常使用文本嵌入进行相似度计算。它通过在大规模语料库中召回一个小的候选文件集,然后进行细粒度的计算。基于嵌入的检索也是检索增强生成(RAG)的重要组成部分。它使得大型语言模型(LLM)能够访问动态的外部知识,而无需修改模型参数。这样一来,IR系统可以更好地利用文本嵌入和外部知识,提高检索效果。
早期的文本嵌入学习方法如word2vec和GloVe虽然被广泛应用,但它们的静态特性限制了对自然语言中丰富上下文信息的捕捉能力。然而,随着预训练语言模型的兴起,一些新方法如Sentence-BERT和SimCSE通过微调BERT来学习文本嵌入,在自然语言推理(NLI)数据集上取得了显著的进展。这些方法利用BERT的上下文感知能力,能够更好地理解文本的语义和语境,从而提高了文本嵌入的质量和表达能力。通过预训练和微调的结合,这些方法能够从大规模的语料库中学习到更丰富的语义信息,为自然语言处理
为了提高文本嵌入性能和鲁棒性,先进的方法如E5和BGE采用了多阶段训练。它们首先对数十亿个弱监督文本对进行预训练,然后再在几个标注数据集上进行微调。这种策略能够有效地提升文本嵌入的表现。
现有的多阶段方法仍然存在两个缺陷:
1. 构造一个复杂的多阶段训练pipeline,需要大量的工程工作来管理大量的相关性数据对(relevance pairs)。
2. 微调依赖于人工收集的数据集,而这些数据集往往受到任务多样性和语言覆盖范围的限制。
大部分方法使用BERT式编码器,忽略了更好的LLM和相关技术的训练进展。
微软的研究团队最近提出了一种简单而高效的文本嵌入训练方法,以克服之前方法存在的一些缺陷。这种方法不需要复杂的管道设计或人工构建的数据集,而是利用LLM来合成多样化的文本数据。通过这种方法,他们能够为近100种语言的数十万文本嵌入任务生成高质量的文本嵌入,而整个训练过程不到1000步。

论文链接:https://arxiv.org/abs/2401.00368
具体来说,研究人员使用两步提示策略,首先提示LLM头脑风暴候选任务池,然后提示LLM从池中生成给定任务的数据。
为了覆盖不同的应用场景,研究人员为每个任务类型设计了多个提示模板,并将不同模板生成的数据进行联合收割机组合,以提高多样性。
实验结果证明,当「仅对合成数据」进行微调时,Mistral-7B在BEIR和MTEB基准上获得了非常有竞争力的性能;当同时加入合成和标注数据进行微调时,即可实现sota性能。
用大模型提升文本嵌入
1. 合成数据生成
利用GPT-4等最先进的大型语言模型(LLM)来合成数据越来越受到重视,可以增强模型在多任务和多语言上的能力多样性,进而可以训练出更健壮的文本嵌入,在各种下游任务(如语义检索、文本相似度计算、聚类)中都能表现良好。
为了生成多样化的合成数据,研究人员提出了一个简单的分类法,先将嵌入任务分类,然后再对每类任务使用不同的提示模板。
非对称任务(Asymmetric Tasks)
包括查询(query)和文档在语义上相关但彼此不互为改写(paraphrase)的任务。
根据查询和文档的长度,研究人员进一步将非对称任务分为四个子类别:短-长匹配(短查询和长文档,商业搜索引擎中的典型场景),长-短匹配,短-短匹配和长-长匹配。
对于每个子类别,研究人员设计了一个两步提示模板,首先提示LLM头脑风暴的任务列表,然后生成一个具体的例子的任务定义的条件;从GPT-4的输出大多连贯一致,质量很高。

在初步实验中,研究人员还尝试使用单个提示生成任务定义和查询文档对,但数据多样性不如上述的两步方法。
对称任务
主要包括具有相似语义但不同表面形式的查询和文档。
文中研究了两个应用场景:单语种(monolingual)语义文本相似性(STS)和双文本检索,并且为每个场景设计了两个不同的提示模板,根据其特定目标进行定制,由于任务的定义比较简单,所以头脑风暴步骤可以省略。
为了进一步提高提示词的多样性,提高合成数据的多样性,研究人员在每个提示板中加入了几个占位符,在运行时随机采样,例如「{query_length}」代表从集合「{少于5个单词,5-10个单词,至少10个单词}」中采样的。
为了生成多语言数据,研究人员从XLM-R的语言列表中采样「{language}」的值,给予高资源语言更多的权重;任何不符合预定义JSON格式的生成数据都将在解析过程中被丢弃;还会根据精确的字符串匹配删除重复项。
2. 训练
给定一个相关的查询-文档对,先使用原始查询q+来生成一个新的指令q_inst,其中「{task_definition}」是嵌入任务的一句话描述的占位符。

对于生成的合成数据,使用头脑风暴步骤的输出;对于其他数据集,例如MS-MARCO,研究人员手动创建任务定义并将其应用于数据集中的所有查询,不修改文件端的任何指令前缀。
通过这种方式,可以预先构建文档索引,并且可以通过仅更改查询端来自定义要执行的任务。
给定一个预训练的LLM,将一个[EOS]标记附加到查询和文档的末尾,然后馈送到LLM中,通过获取最后一层[EOS]向量来获得查询和文档嵌入。
然后采用标准的InfoNCE loss对批内negatives和hard negatives进行损失计算。
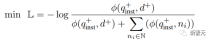
其中ℕ表示所有negatives的集合, 用来计算查询和文档之间的匹配分数,t是一个温度超参数,在实验中固定为0.02
用来计算查询和文档之间的匹配分数,t是一个温度超参数,在实验中固定为0.02

实验结果
合成数据统计
研究人员使用Azure OpenAI服务生成了500k个样本,包含150k条独特指令,其中25%由GPT-3.5-Turbo生成,剩余由GPT-4生成,总共消耗了1.8亿个token。
主要语言是英语,一共覆盖93种语言;对于75种低资源语言,平均每种语言约有1k个样本。
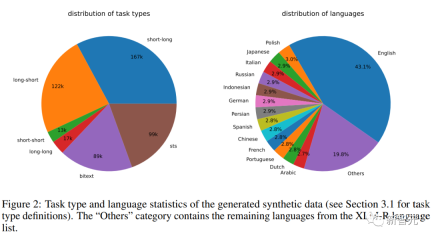
在数据质量方面,研究人员发现GPT-3.5-Turbo的部分输出没有严格遵循提示模板中规定的准则,但尽管如此,总体质量仍然是可以接受的,初步实验也证明了采用这一数据子集的好处。
模型微调和评估
研究人员对预训练Mistral-7B使用上述损失微调1个epoch,遵循RankLLaMA的训练方法,并使用秩为16的LoRA。
为了进一步降低GPU内存需求,采用梯度检查点、混合精度训练和DeepSpeed ZeRO-3等技术。
在训练数据方面,同时使用了生成的合成数据和13个公共数据集,采样后产生了约180万个示例。
为了与之前的一些工作进行公平比较,研究人员还报告了当唯一的标注监督是MS-MARCO篇章排序数据集时的结果,还在MTEB基准上对模型进行了评估。
主要结果
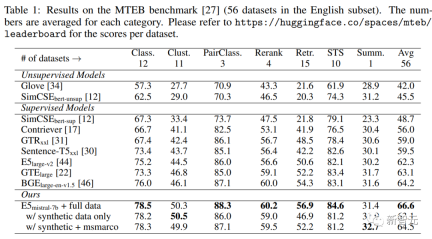
下表中可以看到,文中得到的模型「E5mistral-7B + full data」在MTEB基准测试中获得了最高的平均分,比之前最先进的模型高出2.4分。
在「w/ synthetic data only」设置中,没有使用标注数据进行训练,但性能仍然很有竞争力。
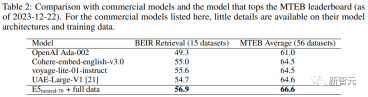
研究人员还对几种商业文本嵌入模型进行了比较,但由于这些模型缺乏透明度和文档,因此无法进行公平的比较。
不过,在BEIR基准上的检索性能对比结果中可以看到,训练得到的模型在很大程度上优于当前的商业模型。
多语言检索
为了评估模型的多语言能力,研究人员在MIRACL数据集上进行了评估,包含18种语言的人工标注查询和相关性判断。
结果显示,该模型在高资源语言上超过了mE5-large,尤其是在英语上,性能表现更出色;不过对于低资源语言来说,该模型与mE5-base相比仍不理想。
研究人员将此归因于Mistral-7B主要在英语数据上进行了预训练,预测多语言模型可以用该方法来弥补这一差距。
以上是无需人工标注!LLM加持文本嵌入学习:轻松支持100种语言,适配数十万下游任务的详细内容。更多信息请关注PHP中文网其他相关文章!

 Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM处理文档不再只是在您的AI项目中打开文件,而是将混乱变成清晰度。诸如PDF,PowerPoints和Word之类的文档以各种形状和大小淹没了我们的工作流程。检索结构化
 如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM
如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM利用Google的代理开发套件(ADK)的力量创建具有现实世界功能的智能代理!该教程通过使用ADK来构建对话代理,并支持Gemini和GPT等各种语言模型。 w
 在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM
在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM摘要: 小型语言模型 (SLM) 专为效率而设计。在资源匮乏、实时性和隐私敏感的环境中,它们比大型语言模型 (LLM) 更胜一筹。 最适合专注型任务,尤其是在领域特异性、控制性和可解释性比通用知识或创造力更重要的情况下。 SLM 并非 LLMs 的替代品,但在精度、速度和成本效益至关重要时,它们是理想之选。 技术帮助我们用更少的资源取得更多成就。它一直是推动者,而非驱动者。从蒸汽机时代到互联网泡沫时期,技术的威力在于它帮助我们解决问题的程度。人工智能 (AI) 以及最近的生成式 AI 也不例
 如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM
如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM利用Google双子座的力量用于计算机视觉:综合指南 领先的AI聊天机器人Google Gemini扩展了其功能,超越了对话,以涵盖强大的计算机视觉功能。 本指南详细说明了如何利用
 Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM2025年的AI景观正在充满活力,而Google的Gemini 2.0 Flash和Openai的O4-Mini的到来。 这些尖端的车型分开了几周,具有可比的高级功能和令人印象深刻的基准分数。这个深入的比较
 如何使用OpenAI GPT-Image-1 API生成和编辑图像Apr 27, 2025 am 09:16 AM
如何使用OpenAI GPT-Image-1 API生成和编辑图像Apr 27, 2025 am 09:16 AMOpenai的最新多模式模型GPT-Image-1彻底改变了Chatgpt和API的形象生成。 本文探讨了其功能,用法和应用程序。 目录 了解gpt-image-1 gpt-image-1的关键功能
 如何使用清洁行执行数据预处理? - 分析VidhyaApr 27, 2025 am 09:15 AM
如何使用清洁行执行数据预处理? - 分析VidhyaApr 27, 2025 am 09:15 AM数据预处理对于成功的机器学习至关重要,但是实际数据集通常包含错误。清洁行提供了一种有效的解决方案,它使用其Python软件包来实施自信的学习算法。 它自动检测和
 AI技能差距正在减慢供应链Apr 26, 2025 am 11:13 AM
AI技能差距正在减慢供应链Apr 26, 2025 am 11:13 AM经常使用“ AI-Ready劳动力”一词,但是在供应链行业中确实意味着什么? 供应链管理协会(ASCM)首席执行官安倍·埃什肯纳齐(Abe Eshkenazi)表示,它表示能够评论家的专业人员


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

