



自注意力机制是一种被广泛应用于自然语言处理和计算机视觉等领域的神经网络模型。它通过对输入序列的不同位置进行加权聚合,从而捕捉序列中的重要信息。这种机制能够在不同位置上自动学习到的权重,使模型能够更好地理解输入序列的上下文关系。相比传统的注意力机制,自注意力机制能够更好地处理长序列和全局依赖关系。 而随机采样则是一种从概率分布中随机选择样本的方法。在生成序列数据或进行模型的蒙特卡罗近似推断时,随机采样是一种常用的技术。通过随机采样,我们可以从给定的概率分布中生成样本,从而得到多样化的结果。在模型的蒙特卡罗近似推断中,随机采样可以用于从后验分布
在人工智能模型的训练和泛化中,自注意力机制和随机采样具有不同的优势和应用场景。自注意力机制能够帮助模型捕捉长距离的依赖关系,提高其泛化能力。而随机采样则可以用于增强模型的多样性和创造力。将二者相互结合,可以在提高模型性能的同时保持模型的多样性和泛化能力。
首先,自注意力机制在处理序列数据时具有重要作用,可以帮助模型更好地捕捉序列之间的依赖关系。在自然语言处理领域,自注意力机制已经被广泛应用于语言模型、机器翻译、文本分类等任务中,取得了显著的效果。自注意力机制的关键特点是能够对输入序列的不同位置进行加权聚合,以更加关注重要的信息。这种机制使得模型能够更好地处理长序列数据,从而提高模型的训练和泛化性能。通过对输入序列的自我关注,模型能够根据不同位置上的重要性权重,灵活地调整对不同部分的关注程度,从而更好地理解和表示序列中的信息。这种能力对于处理自然语言文本等具有长序列的数据非常重要,因为长序列往往包含了更多的上下文信息和依赖关系。自注意力机制的引入使得模型能够更好地捕捉这些关系,从而提高了模型的表达能力和性能。总之,自注意力机制是一种强大的工具,能够在序列数据处理任务中帮助模型更好地捕捉序列之间的依赖关系,提高模型的训练和泛化
同时,随机采样可以帮助模型在训练过程中避免过拟合问题,并提高模型的泛化性能。在深度学习中,通常使用随机梯度下降(SGD)等优化算法进行模型训练。然而,在训练过程中,模型可能会过度拟合训练数据,导致在测试数据上的性能表现不佳。为了避免这种情况,可以使用随机采样来打破模型的确定性,增加模型的鲁棒性。例如,对于文本生成任务,可以通过使用随机采样来生成多个不同的文本样本,从而增加模型对不同语言风格和表达方式的适应能力。此外,随机采样还可以用于模型的蒙特卡罗近似推断,例如在贝叶斯神经网络中进行模型不确定性的估计。
在实际应用中,自注意力机制和随机采样可以相互结合,以进一步提高模型的性能。例如,在语言模型中,可以使用自注意力机制来捕捉文本的上下文信息,并利用随机采样生成多个文本样本,以增加模型的鲁棒性和泛化能力。此外,还可以运用基于自注意力机制和随机采样的生成对抗网络(GAN)来生成更逼真的图像和文本数据。这种结合能够有效地提升模型的表现,并在各种任务中发挥重要作用。
以下是一个例子,演示如何使用自注意力机制和随机采样改善机器翻译模型的性能:
1.准备数据集:准备机器翻译的数据集,包括源语言和目标语言的句子对。可以使用公开数据集,如WMT等。
2.构建模型:构建一个基于自注意力机制的神经机器翻译模型。该模型应该包括编码器和解码器,其中编码器使用自注意力机制对源语言句子进行编码,解码器使用自注意力机制和随机采样来生成目标语言句子。
3.训练模型:使用训练数据集对模型进行训练,使用随机梯度下降(SGD)等优化算法优化模型参数。训练过程中,可以使用自注意力机制来捕捉源语言句子的上下文信息,并使用随机采样来生成多个目标语言句子,从而增加模型的鲁棒性和泛化能力。
4.测试模型:使用测试数据集对模型进行测试,评估模型的翻译质量和性能。可以使用自注意力机制和随机采样来生成多个不同的目标语言句子,从而提高模型的准确性和可靠性。
5.优化模型:根据测试结果对模型进行优化和调整,以提高模型的性能和泛化能力。可以增加模型的深度和宽度,或者使用更加复杂的自注意力机制和随机采样策略来进一步改进模型。
总之,自注意力机制和随机采样是两种在人工智能模型训练和泛化中非常有用的技术。它们可以相互结合,以进一步提高模型的性能和鲁棒性,对于各种任务都有广泛的应用价值。
以上是自注意力机制如何使用随机采样来提升人工智能模型的训练和泛化能力?的详细内容。更多信息请关注PHP中文网其他相关文章!

 LLM路由:策略,技术和Python实施Apr 14, 2025 am 11:14 AM
LLM路由:策略,技术和Python实施Apr 14, 2025 am 11:14 AM大型语言模型(LLM)路由:通过智能任务分配优化性能 LLM的快速发展的景观呈现出各种各样的模型,每个模型都具有独特的优势和劣势。 有些在创意内容gen上表现出色
 更新授权以维护能源网格Apr 14, 2025 am 11:13 AM
更新授权以维护能源网格Apr 14, 2025 am 11:13 AM三个主要地区构成了美国的能源电网:德克萨斯州的互连系统,西部的互连,该系统跨越了太平洋到落基山的国家,而东部相互联系则为山区以东。
 超越骆驼戏:大型语言模型的4个新基准Apr 14, 2025 am 11:09 AM
超越骆驼戏:大型语言模型的4个新基准Apr 14, 2025 am 11:09 AM陷入困境的基准:骆驼案例研究 2025年4月上旬,梅塔(Meta)揭开了Llama 4套件的模特套件,具有令人印象深刻的性能指标,使他们对GPT-4O和Claude 3.5 Sonnet等竞争对手有利地定位。伦斯的中心
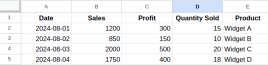 Excel中的数据格式是什么? - 分析VidhyaApr 14, 2025 am 11:05 AM
Excel中的数据格式是什么? - 分析VidhyaApr 14, 2025 am 11:05 AM介绍 在Excel中有效地处理数据对于分析师来说可能具有挑战性。鉴于关键的业务决策取决于准确的报告,因此格式化错误可能会导致重大问题。本文将帮助您
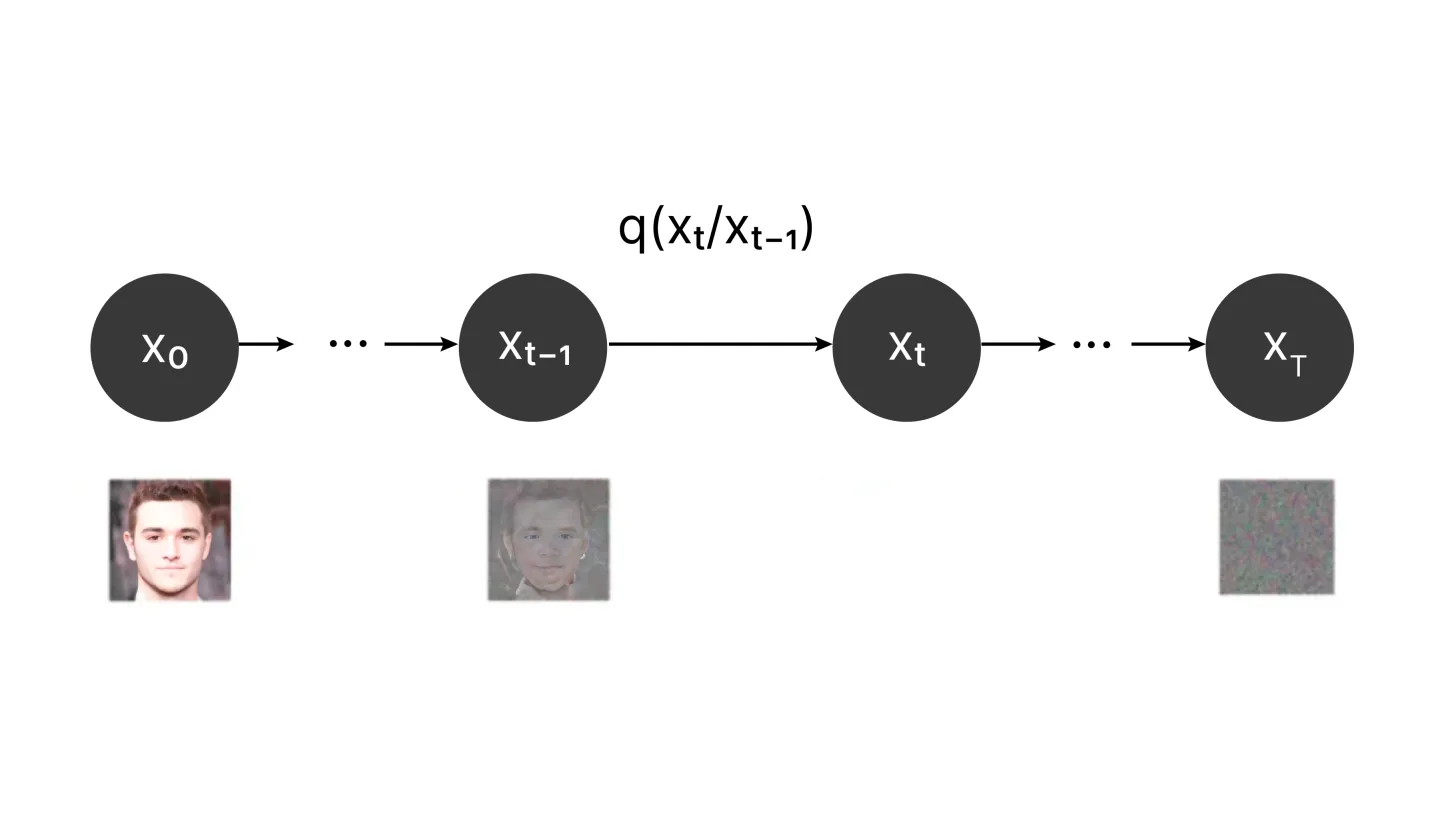 什么是扩散模型?Apr 14, 2025 am 11:00 AM
什么是扩散模型?Apr 14, 2025 am 11:00 AM潜入扩散模型的世界:综合指南 想象一下,在页面上观看墨水,其颜色巧妙地扩散到了迷人的图案。这种自然扩散过程,其中颗粒从高浓度向低浓度移动
 AI中的启发式功能是什么? - 分析VidhyaApr 14, 2025 am 10:51 AM
AI中的启发式功能是什么? - 分析VidhyaApr 14, 2025 am 10:51 AM介绍 想象一下,浏览复杂的迷宫 - 您的目标是尽快逃脱。 存在几条路径?现在,图片有一张图的地图,该地图突出显示有希望的路线和死胡同。这就是人造中启发式功能的本质
 回溯算法的综合指南Apr 14, 2025 am 10:45 AM
回溯算法的综合指南Apr 14, 2025 am 10:45 AM介绍 回溯算法是一种有力的解决问题的技术,可以逐步构建候选解决方案。 这是计算机科学中广泛使用的方法,在丢弃任何Potenti之前,系统地探索了所有可能的途径
 5个免费学习统计信息的最佳YouTube频道Apr 14, 2025 am 10:38 AM
5个免费学习统计信息的最佳YouTube频道Apr 14, 2025 am 10:38 AM介绍 统计数据是一项至关重要的技能,适用于学术界。无论您是追求数据科学,进行研究还是简单地管理个人信息,对统计的掌握都是必不可少的。 互联网,尤其是距离


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

Dreamweaver CS6
视觉化网页开发工具

WebStorm Mac版
好用的JavaScript开发工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

禅工作室 13.0.1
功能强大的PHP集成开发环境

