



在最新的人工智能领域动态中,人工生成的提示(prompt)质量对大语言模型(LLM)的响应精度有着决定性影响。OpenAI 提出的建议指出,精确、详细且具体的问题对于这些大语言模型的表现至关重要。然而,普通用户是否能够确保他们的问题对于 LLM 来说足够清晰明了?
需要重新写的内容是:值得注意的是,人类在某些情境下的自然理解能力与机器的解读存在明显差异。例如,“偶数月” 这一概念,在人类看来很明显指的是二月、四月等月份,而GPT-4却可能将其误解为天数为偶数的月份。这不仅揭示了人工智能在理解日常语境上的局限性,也促使我们反思如何更有效地与这些大型语言模型进行交流。随着人工智能技术的不断进步,如何弥合人类与机器在语言理解方面的鸿沟,是一个未来研究的重要课题
关于此事,加利福尼亚大学洛杉矶分校(UCLA)的顾全全教授领导的通用人工智能实验室发布了一份研究报告,提出了一种创新的解决方案,针对大语言模型(如 GPT-4)在问题理解上的歧义问题。这项研究是由邓依荷、张蔚桐和陈子翔博士生完成的
- 论文地址:https://arxiv.org/pdf/2311.04205.pdf
- 项目地址: https://uclaml.github.io/Rephrase-and-Respond
重写后的中文内容为:该方案的核心是让大型语言模型对提出的问题进行复述和扩写,以提高回答的准确性。研究发现,经过GPT-4重新表述的问题变得更加详细,问题格式也更清晰。这种复述和扩写的方法显著提高了模型的回答准确率。实验表明,一个经过良好复述的问题使得回答的准确率从原来的50%提高到接近100%。这一性能提升不仅展示了大型语言模型自我改进的潜力,也为人工智能如何更有效地处理和理解人类语言提供了新的视角
方法
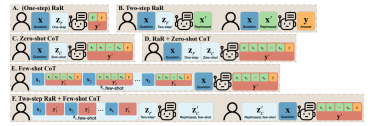
基于以上的发现,研究者提出了一个简单但效果显著的提示词 (prompt):“Rephrase and expand the question, and respond”(简称为 RaR)。这一提示词直接提高了 LLM 回答问题的质量,展示了在问题处理上的一个重要提升。

研究团队还提出了 RaR 的一种变体,称为 “Two-step RaR”,以充分利用像 GPT-4 这样的大模型复述问题的能力。这种方法遵循两个步骤:首先,针对给定的问题,使用一个专门的 Rephrasing LLM 生成一个复述问题;其次,将原始问题和复述后的问题结合起来,用于提示一个 Responding LLM 进行回答。

结果
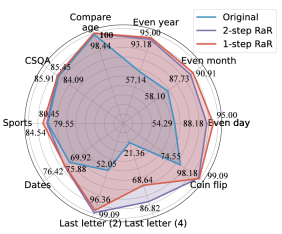
研究人员进行了不同任务的实验,结果表明,无论是单步 RaR 还是两步 RaR,都能有效地提高 GPT4 的回答准确率。值得注意的是,RaR 在原本对 GPT-4 极具挑战性的任务上展现出了显著的改进效果,甚至在某些情况下准确率接近 100%。研究团队总结了以下两点关键结论:
1. 复述并扩写(RaR)提供了一种即插即用的黑箱式提示方法,能够有效地提高 LLM 在各种任务上的性能。
2. 在评估 LLM 在问答(QA)任务上的表现时,检查问题的质量至关重要。

研究人员采用了Two-step RaR方法进行研究,以探究GPT-4、GPT-3.5和Vicuna-13b-v.15等不同模型的表现。实验结果表明,对于那些具备更复杂架构和更强大处理能力的模型,例如GPT-4,RaR方法可以显着提升其处理问题的准确性和效率。而对于较为简单的模型,例如Vicuna,尽管改进幅度较小,但仍然表明了RaR策略的有效性。基于此,研究人员进一步检查了不同模型复述后问题的质量。对于较小模型的复述问题,有时可能会扰乱问题的意图。而像GPT-4这样的高级模型提供的复述问题与人类的意图相符,并且可以增强其他模型的回答效果

这一发现揭示了一个重要的现象:不同等级的语言模型复述的问题在质量和效果上存在差异。特别是像 GPT-4 这样的高级模型,它复述的问题不仅能够为自身提供更清晰的问题理解,还能够作为一种有效的输入,提高其他较小模型的性能。
与思维链(CoT)的区别
为了理解RaR 与思维链(CoT)之间的区别,研究人员提出了它们的数学表述,并阐明了RaR 在数学上与CoT 的不同之处,以及它们如何可以轻松结合。
在深入探讨如何增强模型推理能力之前,这项研究指出应该提高问题的质量,以确保能正确评估模型的推理能力。例如,“硬币翻转”问题,人们发现GPT-4将“翻转(flip)”理解为随机抛掷的动作,与人类的意图不同。即使使用“让我们逐步思考”来引导模型进行推理,这种误解仍会在推理过程中存在。只有在澄清问题之后,大型语言模型才会回答预期的问题

进一步的,研究人员注意到,除了问题文本之外,用于few-shot CoT 的问答示例也是由人类编写的。这就引发了一个问题:当这些人工构造的示例存在缺陷时,大语言模型(LLM)会作出怎样的反应?该研究提供了一个很有意思的例子,并发现不良的 few-shot CoT 示例可能会对 LLM 产生负面影响。以 “末尾字母连接” 任务为例,先前使用的问题示例在提高模型性能方面显示出了积极效果。然而,当提示逻辑发生变化,比如从找到末尾字母变成找到首位字母,GPT-4 却给出了错误的答案。这一现象突显了模型对人工示例的敏感性。

研究人员发现,使用RaR,GPT-4 可以修正给定示例中的逻辑缺陷,从而提高few-shot CoT 的质量和稳健性
结论
人类和大型语言模型(LLM)之间的交流可能存在误解:人类看似清晰的问题,可能会被大型语言模型理解成其他问题。 UCLA研究团队提出了RaR这一新颖方法,该方法促使LLM先复述并澄清问题,然后再回答,从而解决了这个问题
RaR 的有效性已经通过在多个基准数据集上进行的实验评估得到证实。进一步的分析结果显示,通过复述问题可以提升问题质量,而这种提升效果可以在不同的模型之间转移
对于未来的展望来说,预计类似于RaR 这样的方法将不断完善,同时与CoT 等其他方法的整合将为人类和大型语言模型之间的互动提供更准确、更有效的方式,最终拓展AI 解释和推理能力的边界
以上是让大型AI模型自主提问:GPT-4打破与人类对话的障碍,展现更高水平的表现的详细内容。更多信息请关注PHP中文网其他相关文章!

 拥抱面部是否7B型号奥林匹克赛车击败克劳德3.7?Apr 23, 2025 am 11:49 AM
拥抱面部是否7B型号奥林匹克赛车击败克劳德3.7?Apr 23, 2025 am 11:49 AM拥抱Face的OlympicCoder-7B:强大的开源代码推理模型 开发以代码为中心的语言模型的竞赛正在加剧,拥抱面孔与强大的竞争者一起参加了比赛:OlympicCoder-7B,一种产品
 4个新的双子座功能您可以错过Apr 23, 2025 am 11:48 AM
4个新的双子座功能您可以错过Apr 23, 2025 am 11:48 AM你们当中有多少人希望AI可以做更多的事情,而不仅仅是回答问题?我知道我有,最近,我对它的变化感到惊讶。 AI聊天机器人不仅要聊天,还关心创建,研究
 Camunda为经纪人AI编排编写了新的分数Apr 23, 2025 am 11:46 AM
Camunda为经纪人AI编排编写了新的分数Apr 23, 2025 am 11:46 AM随着智能AI开始融入企业软件平台和应用程序的各个层面(我们必须强调的是,既有强大的核心工具,也有一些不太可靠的模拟工具),我们需要一套新的基础设施能力来管理这些智能体。 总部位于德国柏林的流程编排公司Camunda认为,它可以帮助智能AI发挥其应有的作用,并与新的数字工作场所中的准确业务目标和规则保持一致。该公司目前提供智能编排功能,旨在帮助组织建模、部署和管理AI智能体。 从实际的软件工程角度来看,这意味着什么? 确定性与非确定性流程的融合 该公司表示,关键在于允许用户(通常是数据科学家、软件
 策划的企业AI体验是否有价值?Apr 23, 2025 am 11:45 AM
策划的企业AI体验是否有价值?Apr 23, 2025 am 11:45 AM参加Google Cloud Next '25,我渴望看到Google如何区分其AI产品。 有关代理空间(此处讨论)和客户体验套件(此处讨论)的最新公告很有希望,强调了商业价值
 如何为抹布找到最佳的多语言嵌入模型?Apr 23, 2025 am 11:44 AM
如何为抹布找到最佳的多语言嵌入模型?Apr 23, 2025 am 11:44 AM为您的检索增强发电(RAG)系统选择最佳的多语言嵌入模型 在当今的相互联系的世界中,建立有效的多语言AI系统至关重要。 强大的多语言嵌入模型对于RE至关重要
 麝香:奥斯汀的机器人需要每10,000英里进行干预Apr 23, 2025 am 11:42 AM
麝香:奥斯汀的机器人需要每10,000英里进行干预Apr 23, 2025 am 11:42 AM特斯拉的Austin Robotaxi发射:仔细观察Musk的主张 埃隆·马斯克(Elon Musk)最近宣布,特斯拉即将在德克萨斯州奥斯汀推出的Robotaxi发射,最初出于安全原因部署了一支小型10-20辆汽车,并有快速扩张的计划。 h
 AI震惊的枢轴:从工作工具到数字治疗师和生活教练Apr 23, 2025 am 11:41 AM
AI震惊的枢轴:从工作工具到数字治疗师和生活教练Apr 23, 2025 am 11:41 AM人工智能的应用方式可能出乎意料。最初,我们很多人可能认为它主要用于代劳创意和技术任务,例如编写代码和创作内容。 然而,哈佛商业评论最近报道的一项调查表明情况并非如此。大多数用户寻求人工智能的并非是代劳工作,而是支持、组织,甚至是友谊! 报告称,人工智能应用案例的首位是治疗和陪伴。这表明其全天候可用性以及提供匿名、诚实建议和反馈的能力非常有价值。 另一方面,营销任务(例如撰写博客、创建社交媒体帖子或广告文案)在流行用途列表中的排名要低得多。 这是为什么呢?让我们看看研究结果及其对我们人类如何继续将



热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

WebStorm Mac版
好用的JavaScript开发工具

