



强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体会因为采取行动导致预期结果而获得奖励或受到惩罚。随着时间的推移,代理会学会采取行动,以使得其预期回报最大化
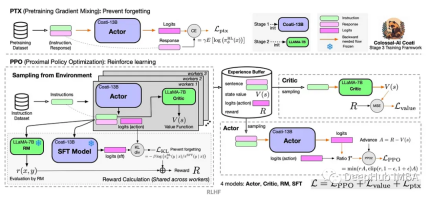
RL代理通常使用马尔可夫决策过程(MDP)进行训练,MDP是为顺序决策问题建模的数学框架。MDP由四个部分组成:
- 状态:环境的可能状态的集合。
- 动作:代理可以采取的一组动作。
- 转换函数:在给定当前状态和动作的情况下,预测转换到新状态的概率的函数。
- 奖励函数:为每次转换分配奖励给代理的函数。
代理的目标是学习策略函数,将状态映射到动作。通过策略函数来最大化代理随着时间的预期回报。
Deep Q-learning是一种使用深度神经网络学习策略函数的强化学习算法。深度神经网络以当前状态作为输入,并输出一个值向量,其中每个值代表一个可能的动作。然后代理根据具有最高值的操作进行采取
Deep Q-learning是一种基于值的强化学习算法,这意味着它学习每个状态-动作对的值。状态-动作对的值是agent在该状态下采取该动作所获得的预期奖励。
Actor-Critic是一种结合了基于值和基于策略的RL算法。有两个组成部分:
Actor:参与者负责选择操作。
Critic:负责评价Actor的行为。
演员和评论家同时接受培训。演员接受培训以最大化预期奖励,评论家接受培训以准确预测每个状态-动作对的预期奖励
Actor-Critic算法相对于其他强化学习算法有几个优点。首先,它更加稳定,这意味着在训练过程中不太可能出现偏差。其次,它更加高效,这意味着它可以更快地学习。第三,它具有更好的可扩展性,可以应用于具有大型状态和操作空间的问题
下面的表格总结了Deep Q-learning和Actor-Critic之间的主要区别:

Actor-Critic (A2C)的优势
演员-评论家是一种受欢迎的强化学习体系结构,它结合了基于策略和基于价值的方法。它有许多优点,使其成为解决各种强化学习任务的强有力的选择:
1、低方差
相较于传统的策略梯度方法,A2C 在训练过程中通常具有较低的方差。这是因为 A2C 同时使用了策略梯度和值函数,在梯度的计算中利用值函数来降低方差。低方差表示训练过程更加稳定,能够更快地收敛到更优的策略
2、更快的学习速度
由于低方差的特性,A2C 通常能够以更快的速度学习到一个良好的策略。这对于那些需要进行大量模拟的任务来说尤为重要,因为较快的学习速度可以节省宝贵的时间和计算资源。
3、结合策略和值函数
A2C 的一个显著特点是它同时学习策略和值函数。这种结合使得代理能够更好地理解环境和动作的关联,从而更好地指导策略改进。值函数的存在还有助于减小策略优化中的误差,提高训练的效率。
4、支持连续和离散动作空间
A2C 可以适应不同类型的动作空间,包括连续和离散动作,而且非常通用。这就使得 A2C 成为一个广泛适用的强化学习算法,可以应用于各种任务,从机器人控制到游戏玩法优化
5、并行训练
A2C 可以轻松地并行化,充分利用多核处理器和分布式计算资源。这意味着可以在更短的时间内收集更多的经验数据,从而提高训练效率。
尽管Actor-Critic方法具有一些优势,但是它们也面临着一些挑战,比如超参数调优和训练中的潜在不稳定性。然而,通过适当的调整以及经验回放和目标网络等技术,这些挑战可以在很大程度上得到缓解,使得Actor-Critic成为强化学习中有价值的方法
panda-gym
panda-gym 基于 PyBullet 引擎开发,围绕 panda 机械臂封装了 reach、push、slide、pick&place、stack、flip 等 6 个任务,主要也是受 OpenAI Fetch 启发。
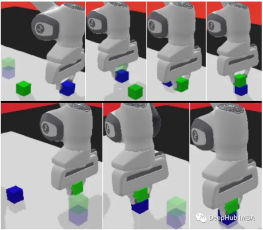
我们将使用panda-gym作为示例来展示下面的代码
1、安装库
首先,我们需要初始化强化学习环境的代码:
!apt-get install -y \libgl1-mesa-dev \libgl1-mesa-glx \libglew-dev \xvfb \libosmesa6-dev \software-properties-common \patchelf !pip install \free-mujoco-py \pytorch-lightning \optuna \pyvirtualdisplay \PyOpenGL \PyOpenGL-accelerate\stable-baselines3[extra] \gymnasium \huggingface_sb3 \huggingface_hub \ panda_gym
2、导入库
import os import gymnasium as gym import panda_gym from huggingface_sb3 import load_from_hub, package_to_hub from stable_baselines3 import A2C from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize from stable_baselines3.common.env_util import make_vec_env
3、创建运行环境
env_id = "PandaReachDense-v3" # Create the env env = gym.make(env_id) # Get the state space and action space s_size = env.observation_space.shape a_size = env.action_space print("\n _____ACTION SPACE_____ \n") print("The Action Space is: ", a_size) print("Action Space Sample", env.action_space.sample()) # Take a random action
4、观察和奖励的规范化
强化学习优化的一个好方法是对输入特征进行归一化。我们通过包装器计算输入特征的运行平均值和标准偏差。同时还通过添加norm_reward = True来规范化奖励
env = make_vec_env(env_id, n_envs=4) env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5、创建A2C模型
我们使用Stable-Baselines3团队训练过的官方代理
model = A2C(policy = "MultiInputPolicy",env = env,verbose=1)
6、训练A2C
model.learn(1_000_000) # Save the model and VecNormalize statistics when saving the agent model.save("a2c-PandaReachDense-v3") env.save("vec_normalize.pkl")
7、评估代理
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize # Load the saved statistics eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")]) eval_env = VecNormalize.load("vec_normalize.pkl", eval_env) # We need to override the render_mode eval_env.render_mode = "rgb_array" # do not update them at test time eval_env.training = False # reward normalization is not needed at test time eval_env.norm_reward = False # Load the agent model = A2C.load("a2c-PandaReachDense-v3") mean_reward, std_reward = evaluate_policy(model, eval_env) print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
总结
在“panda-gym”将Panda机械臂和GYM环境有效的结合使得我们可以轻松的在本地进行机械臂的强化学习,
Actor-Critic架构中代理会学会在每个时间步骤中进行渐进式改进,这与稀疏的奖励函数形成对比(在稀疏的奖励函数中结果是二元的),这使得Actor-Critic方法特别适合于此类任务。
通过无缝结合策略学习和值估计,机器人代理能够熟练地操纵机械臂末端执行器,准确到达指定的目标位置。这不仅为机器人控制等任务提供了实用的解决方案,还具有改变各种需要敏捷和明智决策的领域的潜力
以上是使用Panda-Gym的机器臂模拟实现Deep Q-learning强化学习的详细内容。更多信息请关注PHP中文网其他相关文章!


 软AI的兴起及其对当今企业的意义Apr 15, 2025 am 11:36 AM
软AI的兴起及其对当今企业的意义Apr 15, 2025 am 11:36 AM软AI(被定义为AI系统,旨在使用近似推理,模式识别和灵活的决策执行特定的狭窄任务 - 试图通过拥抱歧义来模仿类似人类的思维。 但是这对业务意味着什么
 为AI前沿的不断发展的安全框架Apr 15, 2025 am 11:34 AM
为AI前沿的不断发展的安全框架Apr 15, 2025 am 11:34 AM答案很明确 - 只是云计算需要向云本地安全工具转变,AI需要专门为AI独特需求而设计的新型安全解决方案。 云计算和安全课程的兴起 在
 生成AI的3种方法放大了企业家:当心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3种方法放大了企业家:当心平均值!Apr 15, 2025 am 11:33 AM企业家,并使用AI和Generative AI来改善其业务。同时,重要的是要记住生成的AI,就像所有技术一样,都是一个放大器 - 使得伟大和平庸,更糟。严格的2024研究O
 Andrew Ng的新简短课程Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程Apr 15, 2025 am 11:32 AM解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 大语言模型(LLM)中的幻觉是不可避免的吗?Apr 15, 2025 am 11:31 AM
大语言模型(LLM)中的幻觉是不可避免的吗?Apr 15, 2025 am 11:31 AM大型语言模型(LLM)和不可避免的幻觉问题 您可能使用了诸如Chatgpt,Claude和Gemini之类的AI模型。 这些都是大型语言模型(LLM)的示例,在大规模文本数据集上训练的功能强大的AI系统
 60%的问题 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的问题 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根据行业和搜索类型,AI概述可能导致有机交通下降15-64%。这种根本性的变化导致营销人员重新考虑其在数字可见性方面的整个策略。 新的
 麻省理工学院媒体实验室将人类蓬勃发展成为AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工学院媒体实验室将人类蓬勃发展成为AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大学(Elon University)想象的数字未来中心的最新报告对近300名全球技术专家进行了调查。由此产生的报告“ 2035年成为人类”,得出的结论是,大多数人担心AI系统加深的采用


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

Atom编辑器mac版下载
最流行的的开源编辑器

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

