
贾强槐:蚂蚁大规模知识图谱构建及其应用

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-09-10 15:05:081424浏览

一、图谱概览
首先介绍知识图谱的一些基础概念。
1、什么是知识图谱
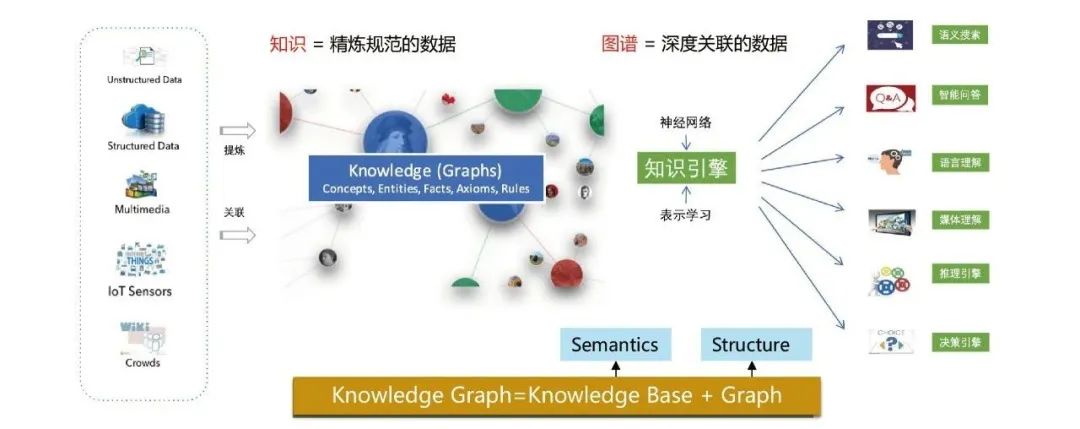
知识图谱旨在利用图结构建模、识别和推断事物之间的复杂关联关系和沉淀领域知识,是实现认知智能的重要基石, 已经被广泛应用于搜索引擎、智能问答、语言语义理解、大数据决策分析等众多领域。
知识图谱同时建模了数据之间的语义关系和结构关系,结合深度学习技术可以把这两者关系更好得融合和表征。
2、为什么要建知识图谱
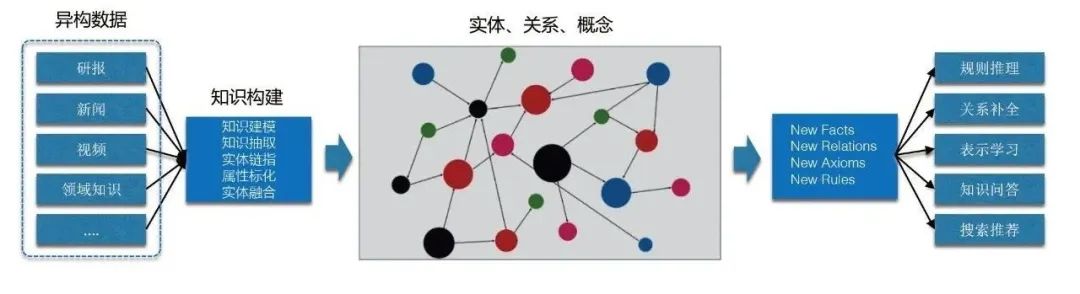
我们要建设知识图谱主要是从如下两点出发考虑:一方面是蚂蚁本身的数据来源背景特点,另一方面是知识图谱能带来的好处。
[1] 数据来源本身是多元和异构的,缺乏一套统一的知识理解体系。
[2] 知识图谱能够带来多个好处,包括:
- 语义标准化:利用图谱构建技术提升实体、关系、概念等的标准化和归一化水平。
- 领域知识沉淀:基于语义、图结构实现知识表示和互联,从而积累丰富的领域知识。
- 知识复用:构建高质量的蚂蚁知识图谱,通过融合、链接等服务多下游,为业务降本提效。
- 知识推理发现:基于图谱推理技术发现更多长尾知识,服务风控、信贷、理赔、商家运营、营销推荐等场景。
3、如何构建知识图谱的概览
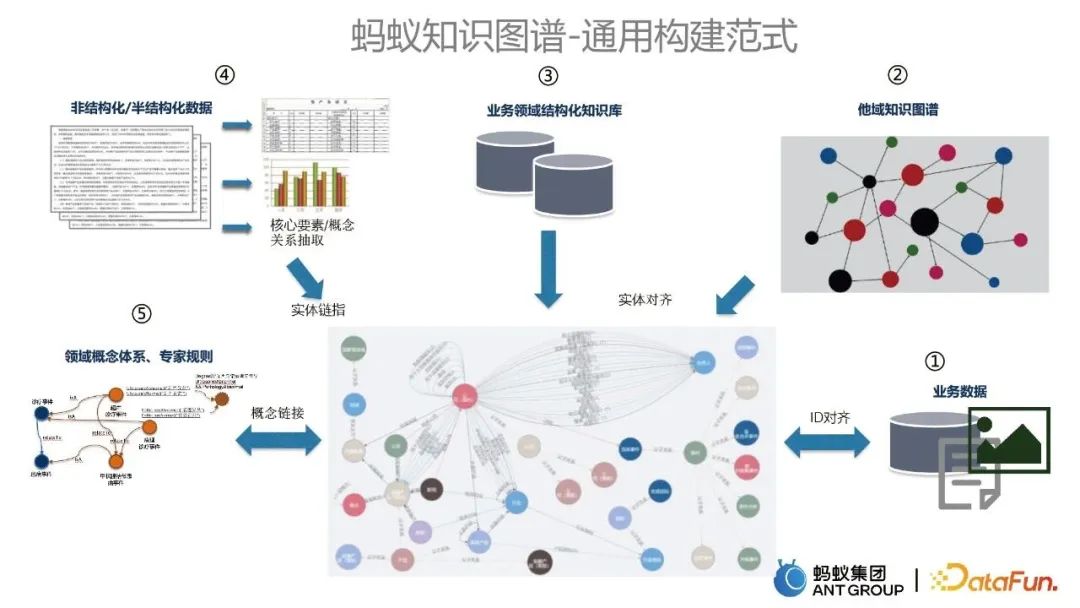
在构建各类业务知识图谱的过程中,我们沉淀出了一套蚂蚁知识图谱的通用构建范式,主要分为如下五个部分:
- 从业务数据出发,作为图谱冷启动的重要数据来源。
- 他域的知识图谱同现有图谱进行融合,通过实体对齐的技术来实现。
- 业务领域结构化的知识库同现有的知识图谱的进行融合,也是通过实体对齐的技术实现。
- 非结构和半结构化的数据,例如文本会对其进行信息抽取,通过实体链指技术实现对现有图谱进行更新。
- 领域概念体系和专家规则的融入,将相关概念、规则与现有知识图谱进行链接。
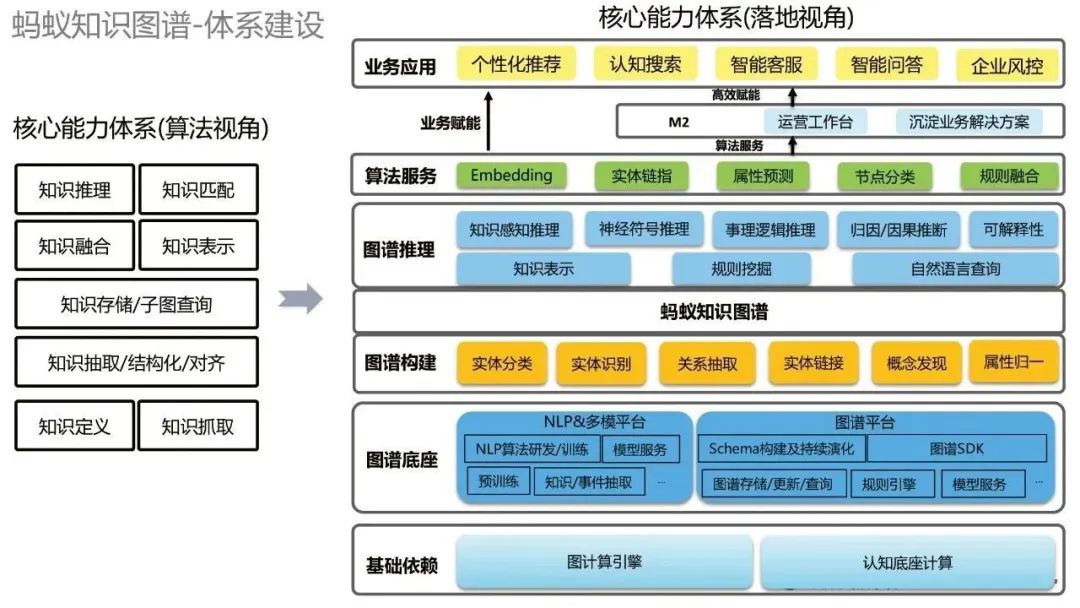
有了通用的构建范式后,就需要进行体系化的建设。从两个视角来看蚂蚁知识图谱的体系化建设。首先是从算法视角来看,有各种算法能力,比如知识推理、知识匹配等等。从落地视角来看,自下而上,最下面的基础依赖包括图计算引擎和认知底座计算;其上是图谱底座,包括NLP&多模平台以及图谱平台;往上是各种图谱构建技术,基于此我们就可以构建蚂蚁知识图谱;在知识图谱的基础上,我们可以做一些图谱推理;再往上,我们提供一些通用的算法能力;最上面是业务应用。
二、图谱建设
接下来分享蚂蚁集团建设知识图谱的一些核心能力,包括图谱构建、图谱融合、图谱认知三个方面。
1、图谱构建
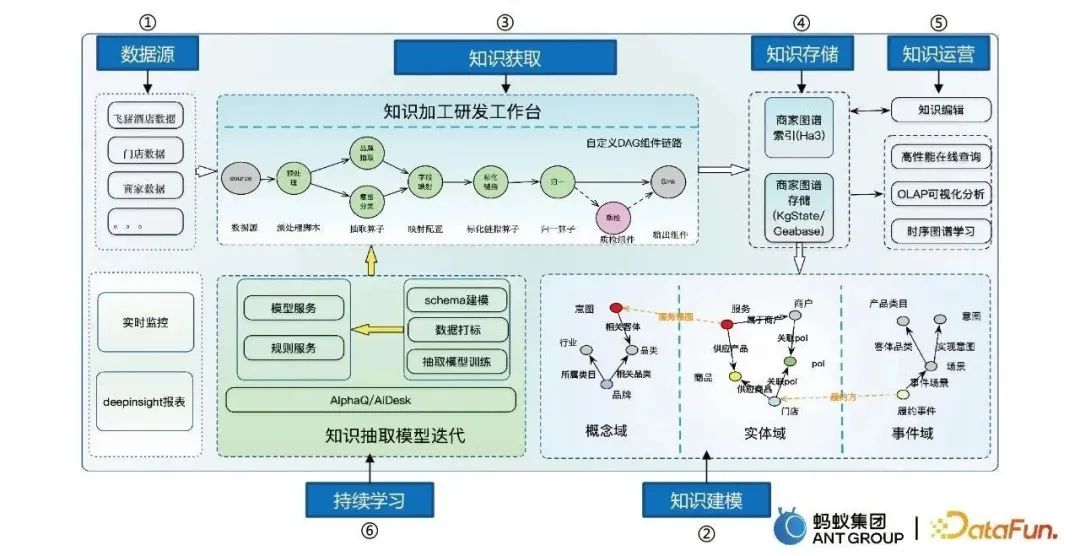
图谱构建的流程主要包括六步:
- 数据源,获取多元数据。
- 知识建模,将海量数据转化成结构化的数据,从概念、实体和事件三个域来建模。
- 知识获取,搭建了知识加工研发平台。
- 知识存储,包括Ha3存储和图存储等。
- 知识运营,包括知识编辑、在线查询、抽取等。
- 持续学习,让模型自动地进行迭代学习。
构建过程中的三个经验与技巧
融合专家知识的实体分类
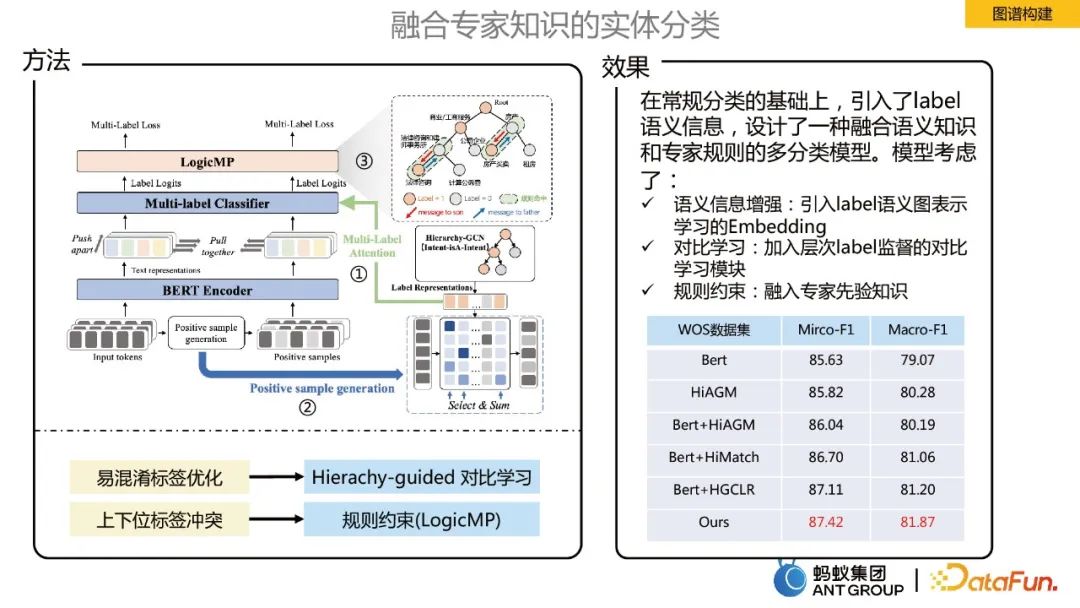
在构建知识图谱中,需要对输入的实体进行分类,在蚂蚁场景下是一个大规模多标签分类的任务。为了融合专家知识来进行实体分类,主要做如下三点优化:
- 语义信息增强:引入label语义图表示学习的Embedding。
- 对比学习:加入层次label监督的对比。
- 逻辑规则约束:融入专家先验知识。
领域词表注入的实体识别
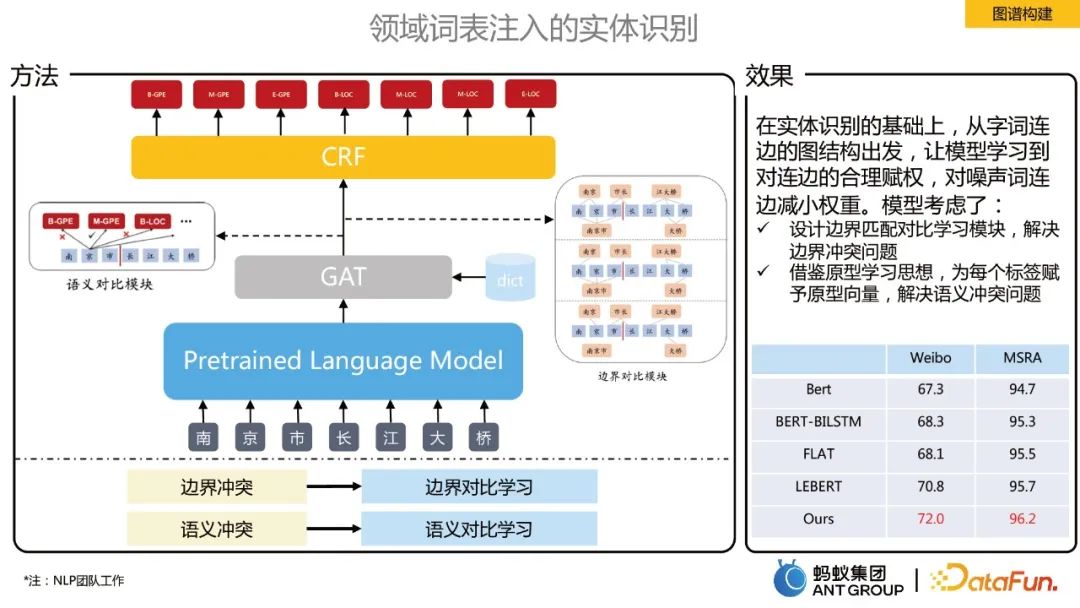
在实体识别的基础上,从字词连边的图结构出发,让模型学习到对连边的合理赋权,对噪声词连边减小权重。提出了边界对比学习和语义对比学习两个模块:
- 边界对比学习,用来解决边界冲突问题。在词表注入之后,构建一个全连接图,用GAT来学习每个token的表征,边界分类正确的部分构建一个正例的图,错误的部分构建负例的图,通过对比让模型学到每个token的边界信息。
- 语义对比学习,用来解决语义冲突问题。借鉴了原型学习思想,把label的语义的表征加进来,强化每个token与label语义之间的关联关系。
逻辑规则约束的小样本关系抽取
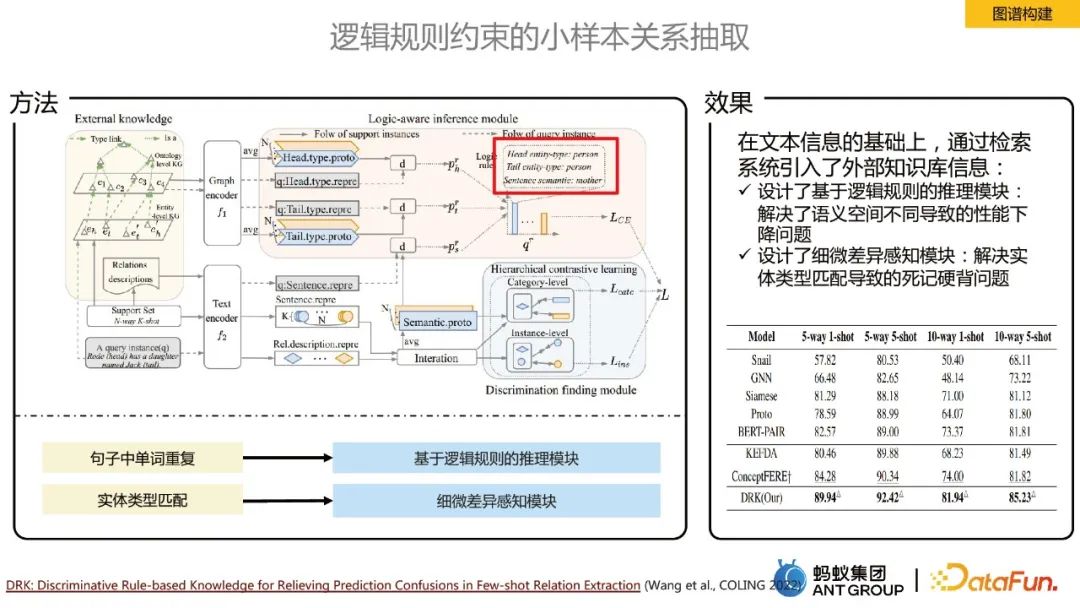
在领域问题上我们的标注样本很少,会面临few-shot或zero-shot的场景,在这种情况下进行关系抽取的核心思想就是引入外部知识库,为了解决语义空间不同导致的性能下降问题,设计了基于逻辑规则的推理模块;为了解决实体类型匹配导致的死记硬背问题,设计了细微差异感知模块。
2、图谱融合
图谱融合是指不同业务领域下图谱之间的信息融合。
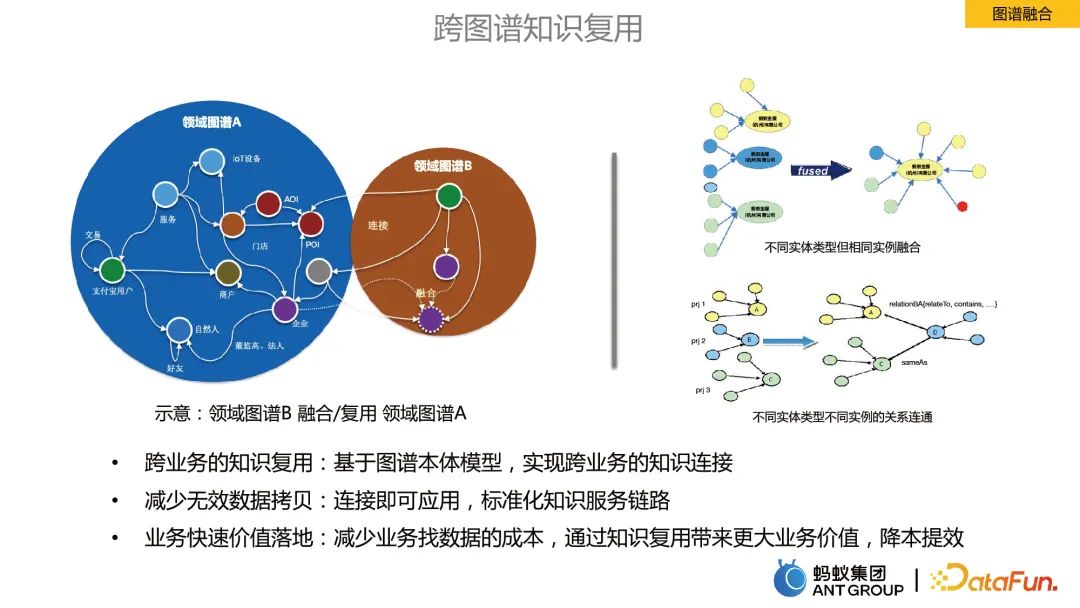
图谱融合的好处:
- 跨业务的知识复用:基于图谱本体模型,实现跨业务的知识连接。
- 减少无效数据拷贝:连接即可应用,标准化知识服务链路。
- 业务快速价值落地:减少业务找数据的成本,通过知识复用带来更大业务价值,降本提效。
图谱融合中的实体对齐
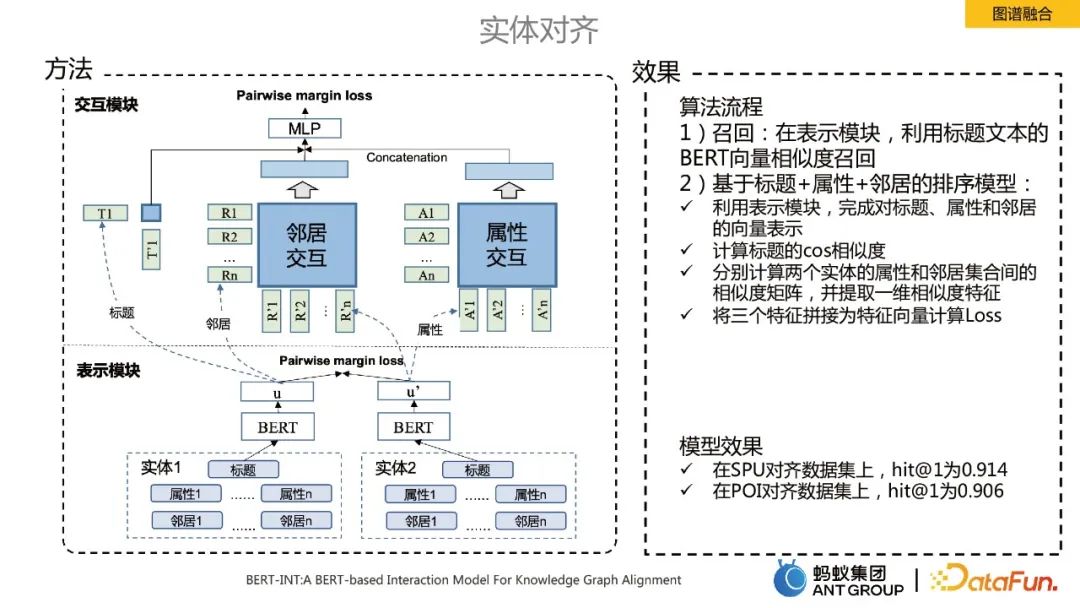
知识图谱融合过程中一个核心技术点就是实体对齐,这里我们采用了SOTA算法BERT-INT,主要包括两个模块,一个是表示模块,另一个是交互模块。
算法的实现流程主要包括召回和排序:
召回:在表示模块,利用标题文本的 BERT向量相似度召回。
基于标题+属性+邻居的排序模型:ü 利用表示模块,完成对标题、属性和邻居的向量表示:
- 计算标题的cos相似度。
- 分别计算两个实体的属性和邻居集合间的相似度矩阵,并提取一维相似度特征。
- 将三个特征拼接为特征向量计算Loss。
3、图谱认知
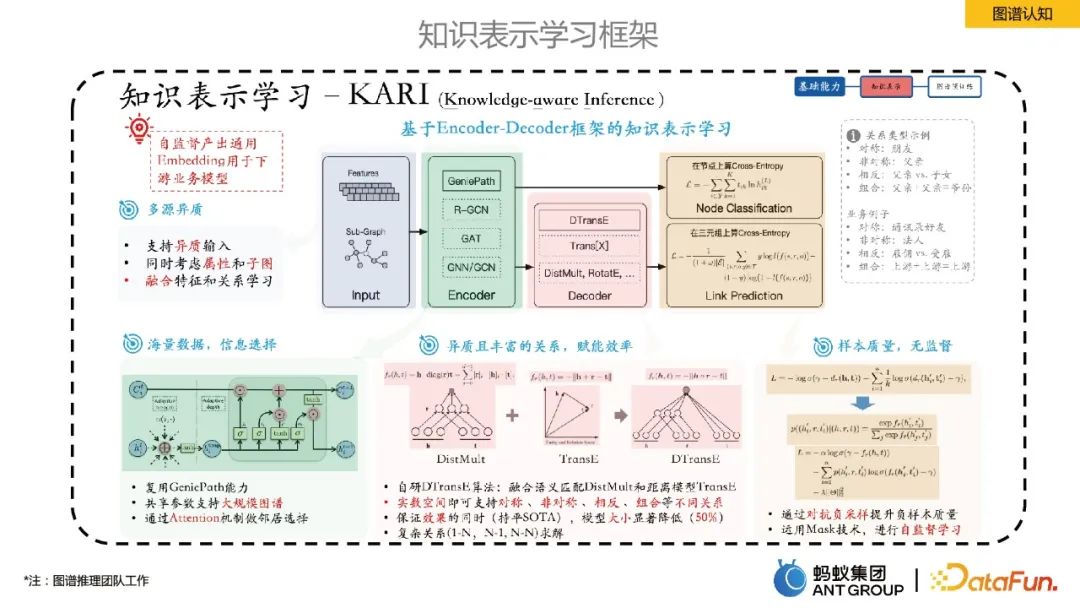
这一部分,主要介绍一下蚂蚁内部的知识表示学习框架。
蚂蚁提出了一个基于Encoder-Decoder框架的知识表示学习。其中Encoder是一些图神经的学习方法,Decoder是一些知识表示的学习,比如链接预测。这套表示学习框架可以自监督产出通用的实体/关系Embedding,有几个好处:1)Embedding Size远小于原始特征空间,降低了存储成本;2)低维向量更稠密,有效缓解数据稀疏问题;3)同一向量空间学习,对多源异质数据的融合更自然;4)Embedding具有一定的普适性,方便下游业务使用。
三、图谱应用
接下来分享几个在蚂蚁集团中知识图谱的典型应用案例。
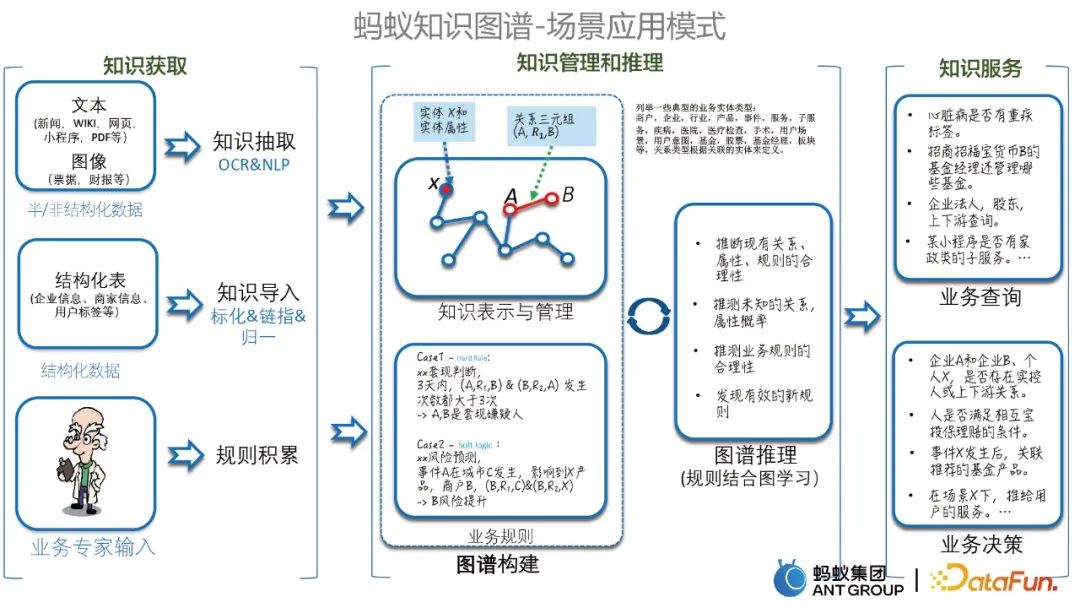
1、图谱的场景应用模式
在介绍具体案例前,先来介绍一下蚂蚁知识图谱场景应用的几种模式,主要包括知识获取、知识管理和推理,以及知识服务。如下图所示。
2、一些典型的案例
案例1:基于知识图谱的结构化匹配召回
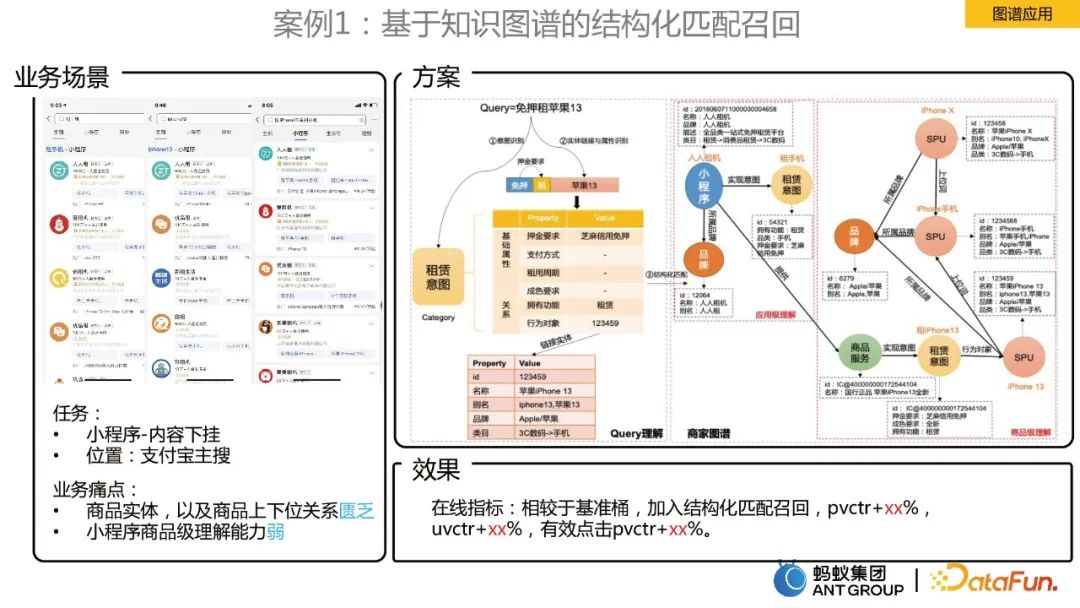
业务场景是支付宝主搜里面的小程序的内容下挂,要解决的业务痛点是:
- 商品实体,以及商品上下位关系匮乏。
- 小程序商品级理解能力弱。
解决方案是,构建了商家知识图谱。结合商家图谱的商品关系,实现对用户query商品级别的结构化理解。
案例2:用户意图实时预测在推荐系统应用
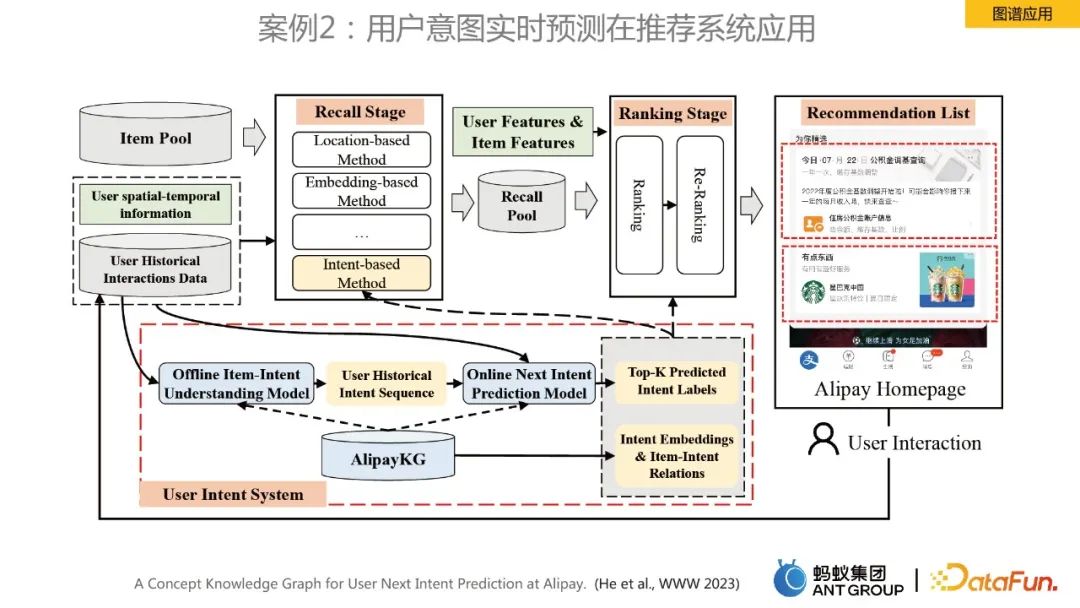
这一案例是针对首页推荐进行用户意图实时预测,构建了AlipayKG,框架如上图所示。相关工作也发表在顶会www 2023上,可以参考论文做更进一步的理解。
案例3:融合知识表征的营销券推荐
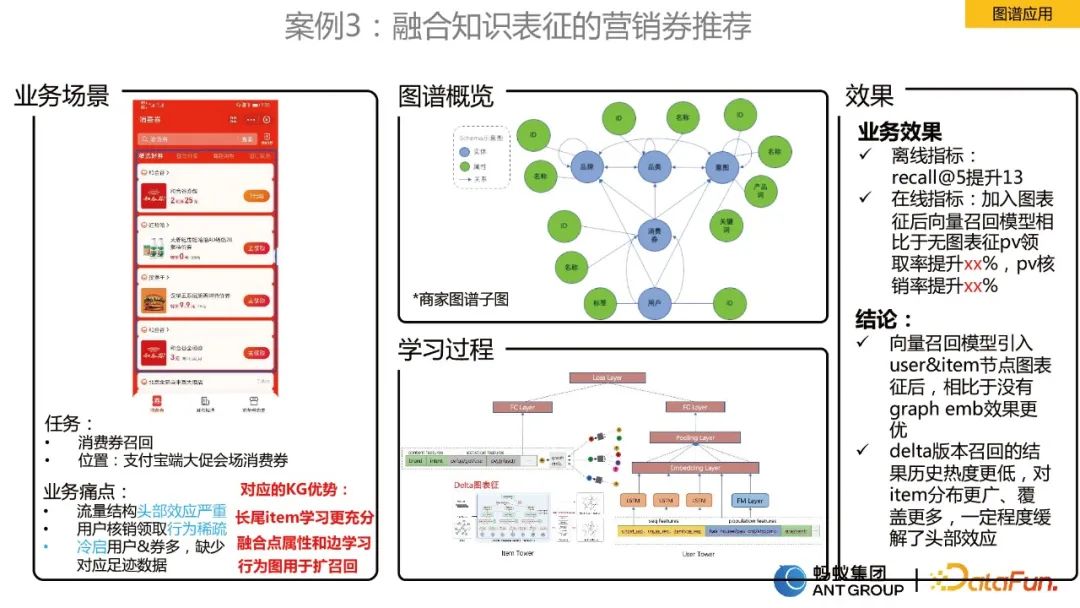
这个场景是消费券推荐的一个场景,业务面临的痛点为:
- 头部效应严重。
- 用户核销领取行为稀疏。
- 冷启动用户和券很多,缺少对应的足迹数据。
为了解决上述问题,我们设计了融合动态图表征的深度向量召回算法。因为我们发现用户消费券的行为是有周期性的,静态的单条边是无法建模这种周期性行为的。为此我们首先构建了动态图,接着采用团队自研的动态图算法来学习Embedding表征,得到表征之后再放到双塔模型中去,进行向量召回。
案例4:基于诊疗事件的智能理赔专家规则推理
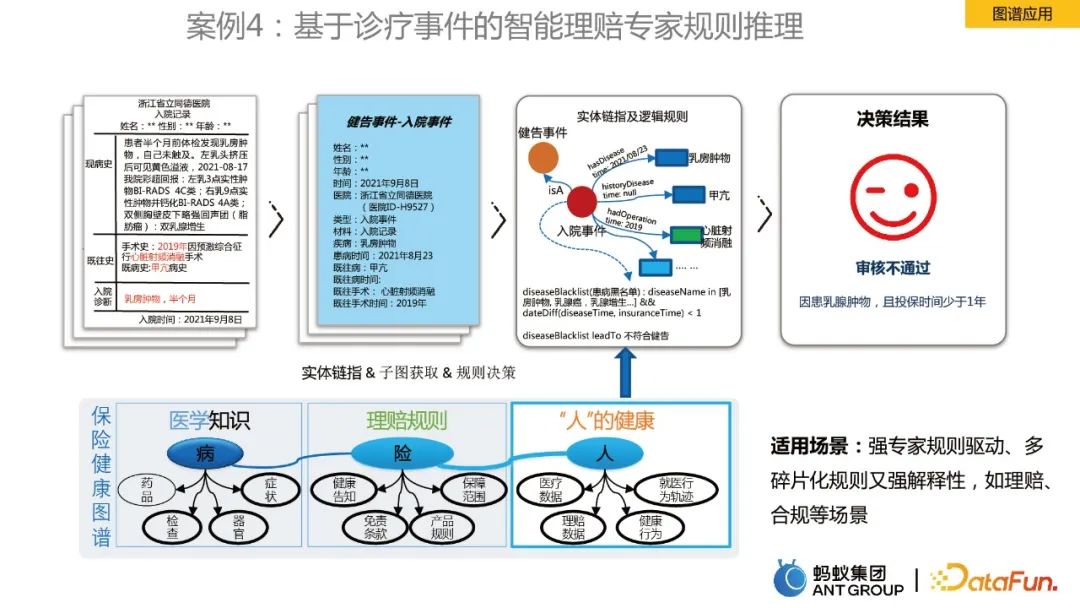
最后一个案例是关于图谱规则推理。以医疗保险健康图谱为例,包括医学知识、理赔规则、“人”的健康的信息,进行实体链指,再加上逻辑规则,来作为决策的依据。通过图谱实现了专家理赔效率的提升。
四、图谱与大模型
最后简单探讨一下在当前大模型快速发展的背景下知识图谱的机遇。
1、知识图谱与大模型的关系
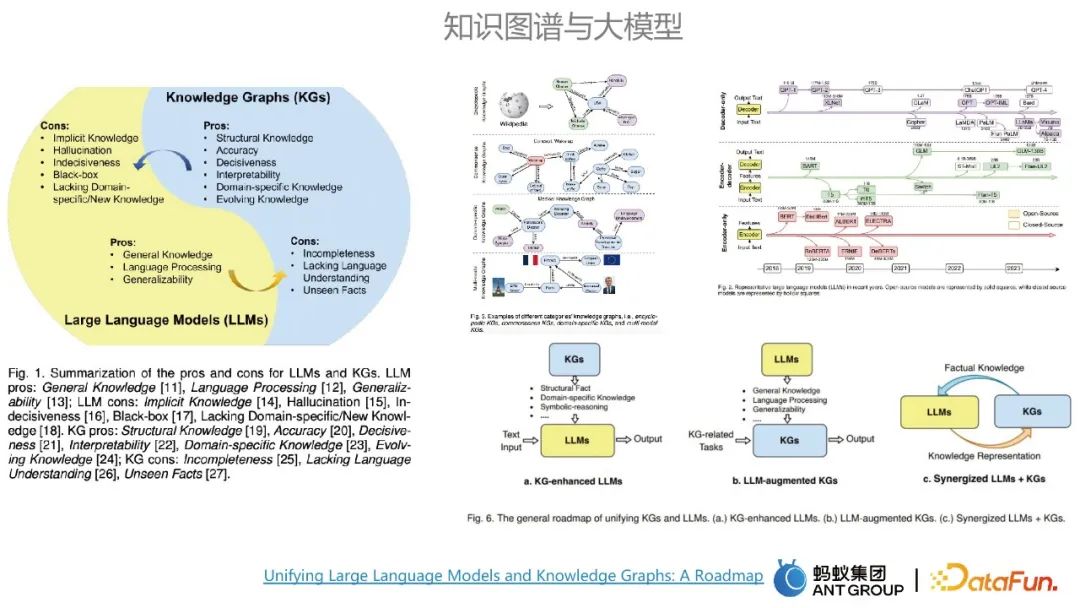
知识图谱与大模型各有优缺点,大模型的主要有通用知识建模和普适性等优点,而大模型的缺点正好是知识图谱的优点所能弥补的。图谱的优点包括准确性很高、可解释性强等。大模型和知识图谱是能够相互影响的。
图谱和大模型的融合通常存在三种路线,一种是利用知识图谱来增强大模型;第二种是利用大模型来增强知识图谱;第三种是大模型和知识图谱协同并进,优势互补,大模型可以认为是一种参数化的知识库,知识图谱可以认为是一种显示化的知识库。
2、大模型与知识图谱相应用的案例
大模型应用于知识图谱构建
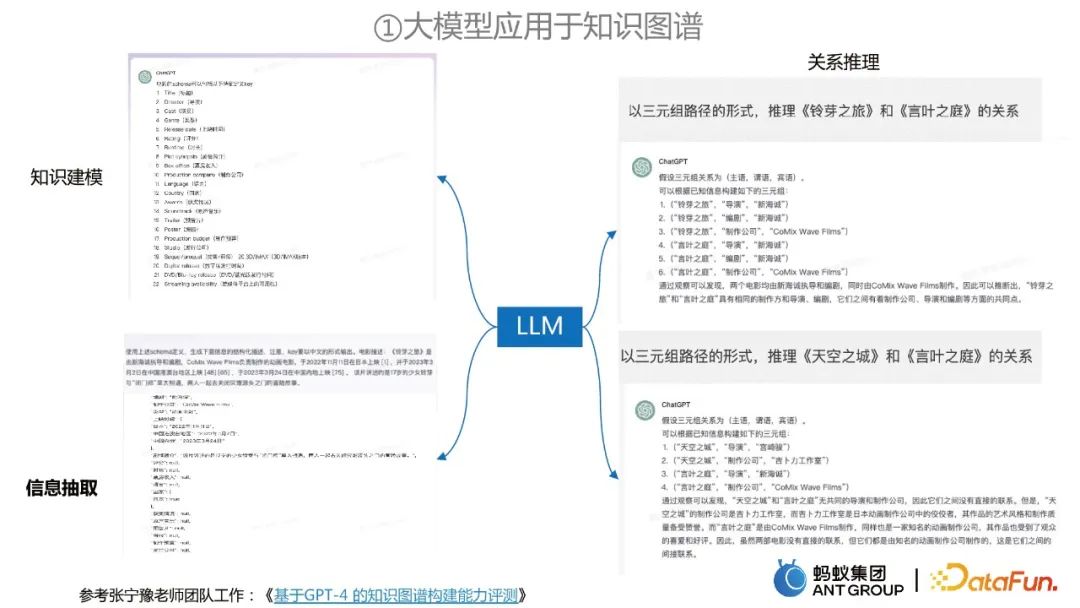
在知识图谱构建的过程中,可以利用大模型来进行信息抽取、知识建模和关系推理。
如何利用大模型来应用于知识图谱的信息抽取

达摩院的这个工作将信息抽取问题分解成了两个阶段:
- 在第一阶段,我们想要找到文本中存在的实体、关系或者事件类型,以减小搜索空间和计算复杂度。
- 在第二阶段,我们根据前面抽取的类型和给定的对应列表,进一步抽取出相关信息。
将知识图谱应用于大模型
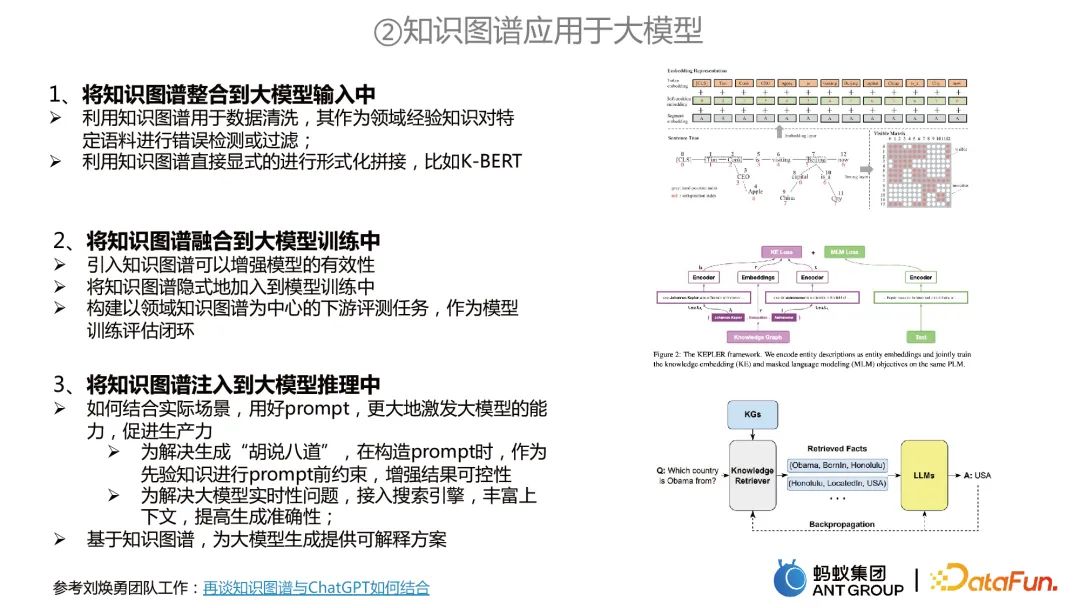
将知识图谱应用于大模型主要包括三个方面:
将知识图谱整合到大模型输入中。可以利用知识图谱来进行数据清洗,或利用知识图谱直接显式地进行形式化拼接。
将知识图谱融合到大模型训练中。比如同时进行两个任务的训练,知识图谱可以做知识表示的任务,大模型做MLM的预训练,两者联合建模。
将知识图谱注入到大模型推理中。首先可以解决大模型的两个问题,一是将知识图谱作为先验约束,来避免大模型“胡说八道”;第二就是解决大模型时效性问题。另一方面,基于知识图谱,可以为大模型生成提供可解释方案。
知识增强的问答系统
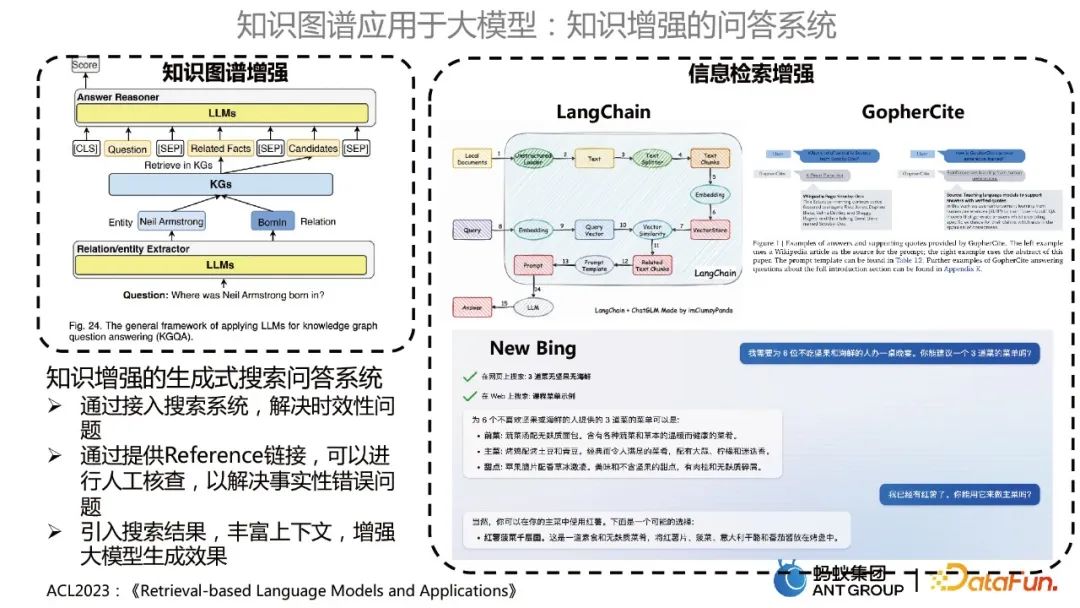
主要包括两类,一块是知识图谱增强的问答系统,即用大模型来优化KBQA的模式;另一个是信息检索增强,类似LangChain、GopherCite、New Bing等用大模型来做知识库问答的形式。
知识增强的生成式搜索问答系统,有如下优势:
- 通过接入搜索系统,解决时效性问题。
- 通过提供Reference链接,可以进行人工核查,以解决事实性错误问题。
- 引入搜索结果,丰富上下文,增强大模型生成效果。
3、总结与展望

知识图谱与大模型如何更好地交互协同共进,包括如下三个方向:
- 推进知识图谱和大模型在NLP、问答系统等领域的深入应用。
- 使用知识图谱进行大模型的幻觉检测和去毒。
- 结合知识图谱的领域大模型研发。
以上是贾强槐:蚂蚁大规模知识图谱构建及其应用的详细内容。更多信息请关注PHP中文网其他相关文章!