



译者 | 朱先忠
审校 | 孙淑娟
传统的球面CNN无法扩展到高分辨率分类任务。在本文中,我们介绍了球面散射层(spherical scattering layers)——一种新型的球面层,它可以降低输入数据的维数,同时保留相关信息,同时还具有旋转等变的特性。
散射网络通过使用小波分析中预定义的卷积滤波器进行工作,而不是从头开始学习卷积滤波器。由于散射层的权重是专门设计的而不是通过学习得到的,因此散射层可以用作一次性预处理步骤,从而降低输入数据的分辨率。我们以往的经验表明,配备初始散射层的球面CNN可以扩展到数千万像素的分辨率,这一壮举以前在传统球面CNN层中是难以实现的。
传统球面深度学习方法需要计算
球面CNN(文献1,2,3)对于解决机器学习中的多种不同类型的问题都非常有用,因为这其中许多问题的数据源不能自然地在平面上表示(有关这方面的入门性介绍,请参阅我们的前一篇文章,地址是:https://towardsdatascience.com/geometric-deep-learning-for-spherical-data-55612742d05f)。
球面CNN的一个关键特性是,它们与球面数据的旋转是等变的(在本文中,我们重点讨论旋转等变方法)。实际上,这意味着球面CNN具有令人印象深刻的泛化特性,允许它们执行诸如分类3D对象网格之类的操作,而不管它们是如何旋转的(以及它们在训练期间是否看到网格的不同旋转)。
我们在最近发布的文章中描述了Kagenova团队为提高球面CNN的计算效率而开发的一系列进展成果(参考地址:https://towardsdatascience.com/efficient-generalized-spherical-cnns-1493426362ca)。我们所采用的方法——高效的广义球面CNN——既保留了传统球面CNN的等方差特性,同时又使得计算效率更高(文献1)。然而,尽管在计算效率方面取得了这些进步,球面CNN仍然局限于相对低分辨率的数据。这意味着,球面CNN目前还不能应用于通常涉及更高分辨率数据的激动人心的应用场景中,例如宇宙学数据分析和虚拟现实的360度计算机视觉等领域。在最近发布的一篇文章中,我们介绍了球面散射层网络,以便灵活调整高效的通用球面CNN来提高分辨率(文献4),在本文中我们将对该内容进行一下回顾。
支持高分辨率输入数据的混合方法
在开发高效的通用球面CNN(文献1)时,我们发现了一种非常有效的构建球面CNN架构的混合方法。混合球面CNN可以在同一网络中使用不同风格的球面CNN层,允许开发人员在不同处理阶段获得不同类型层的好处。
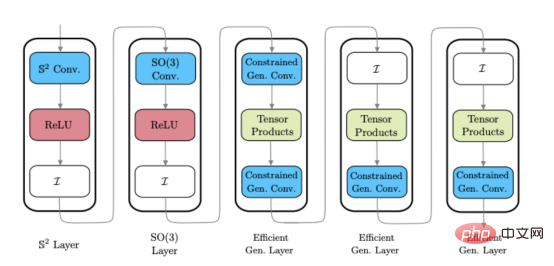
上图展示了混合球面CNN架构示例图(请注意:这些层不是单一的,而是一些不同风格的球面CNN层)。
球面上的散射网络继续采用这种混合方法,并引入了一种新的球面CNN层,可以插入现有的球面架构中。为了将高效的通用球面CNN扩展到更高维度,这一新层需要具备如下特征:
- 计算支持下的可扩展性
- 将信息混合到低频,以允许后续层以低分辨率运行
- 旋转等变
- 提供稳定和局部不变的表示(即提供有效的表示空间)
我们确定散射网络层具有满足所有上面列举的这些特征的潜力。
球面上的散射网络
由Mallat(文献5)在欧几里德环境中首次提出的散射网络可以被视为具有固定卷积滤波器的CNN,这些滤波器是从小波分析中导出的。散射网络已被证明对传统(欧氏)计算机视觉非常有用,尤其是在数据有限的情况下——而在这种情况下学习卷积滤波器是比较困难的。接下来,我们简要讨论一下散射网络层的内部工作原理、它们如何满足上一节中定义的要求以及如何开发它们用于球面数据分析。
散射层内的数据处理由三个基本操作执行。第一个构建块是固定小波卷积,它类似于欧氏CNN中使用的正常学习卷积。在小波卷积之后,散射网络对结果表示应用模数非线性方法。最后,散射利用了一个缩放函数,该函数执行了一种局部平均算法,与普通CNN中的池化层有一些相似之处。重复应用这三个构建块就会将输入数据分散到计算树中,并在不同的处理阶段将结果表示(类似于CNN频道)从树中提取出来。这些操作的简略示意图如下所示。
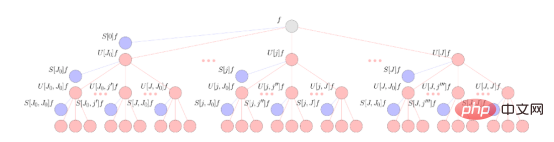
该图示意了球面信号f的球面散射网络。信号通过级联球面小波变换传播,并结合用红色节点表示的绝对值激活函数。散射网络的输出是通过将这些信号投影到球面小波缩放函数上得到的,从而得到用蓝色节点表示的散射系数。
从传统的深度学习观点来看,分散网络的操作似乎有些模糊。然而,所描述的每种计算操作都有一个特定的目的——旨在利用小波分析的可靠的理论结果。
散射网络中的小波卷积是经过仔细推导的,以便从输入数据中提取相关信息。例如,对于自然图像,小波被定义为专门提取与高频的边缘和低频的物体普通形状相关的信息。因此,在平面设置中,散射网络滤波器可能与传统的CNN滤波器有一些相似之处。这同样适用于球面设置,我们使用尺度离散小波(scale-discretised wavelets,详见文献4)。
由于小波滤波器是固定的,初始散射层只需要应用一次,而不需要在整个训练过程中重复应用(如传统CNN中的初始层)。这使得散射网络在计算上具有可扩展性,满足上面特征1的要求。此外,散射层降低了其输入数据的维数,这意味着在训练下游CNN层时,只需要使用有限的存储空间来缓存散射表示。
小波卷积后面采用的是模数非线性方法。首先,这给神经网络层注入了非线性特征。其次,模数运算将输入信号中的高频信息混合到低频数据中,满足上面的要求2。下图显示了模数非线性计算前后数据的小波表示的频率分布情况。
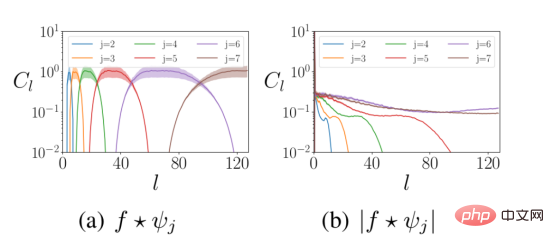
上图展示了模运算前后不同球面频率l处小波系数的分布。输入信号中的能量从高频(左侧面板)移动到低频(右侧面板)。其中,f是输入信号,Ψ代表缩放j的小波。
应用模数计算后,将得到的信号投影到缩放函数上。缩放函数从表示结果中提取低频信息,类似于传统CNN中的池化函数操作。
我们对球面散射网络的理论上的等方差特性进行了经验测试。测试是通过旋转信号并将其通过散射网络馈送,然后将得到的结果表示与输入数据通过散射网络后再进行旋转计算的结果表示进行比较。由下表中的数据可以证明给定深度的等方差误差较低,因此满足上述要求3(通常在实践中,一个路径深度不会超过两个路径的深度,因为大多数信号能量已经被捕获)。
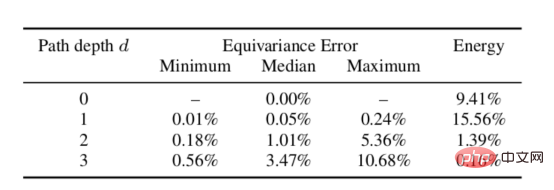
不同深度球面散射网络的旋转等方差误差
最后,从理论上证明了欧氏散射网络对小的微分或畸变是稳定的(文献5)。目前,这个结果已经推广到紧致黎曼流形上的散射网络(文献6),特别是球面环境(文献4)。在实践中,对差异形态的稳定性意味着,如果对输入进行轻微更改,散射网络计算的表示不会有显著差异(关于稳定性在几何深度学习中的作用的讨论,请参阅我们之前的帖子,地址是https://towardsdatascience.com/a-brief-introduction-to-geometric-deep-learning-dae114923ddb)。因此,散射网络提供了一个表现良好的表示空间,在该空间上可以有效地进行随后的学习,满足上述第4项要求。
可缩放和旋转等变的球面CNN
考虑到引入的散射层满足我们所有想要的特性,接下来我们准备将它们集成到我们的混合球面CNN中。如前所述,散射层可以作为初始预处理步骤固定到现有架构上,以减小后续球面层处理的表示的大小。
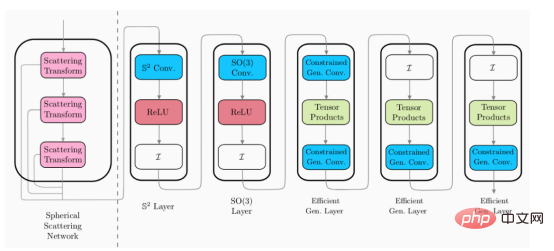
在上图中,散射层模块(虚线左侧)是一个设计层。这意味着,它不需要训练,而其余层(虚线右侧)是可训练的。因此,这意味着散射层可以作为一次性预处理步骤应用,以降低输入数据的维数。
由于散射网络具有给定输入的固定表示,因此散射网络层可以在训练开始时应用于整个数据集一次,并缓存生成的低维表示以训练后续层。幸运的是,散射表示具有降低的维度,这意味着存储它们所需的磁盘空间相对较低。由于存在这个新的球面散射层,所以可以把高效的广义球面CNN扩展到高分辨率分类问题领域。
宇宙微波背景各向异性的分类
物质在整个宇宙中是如何分布的?这是宇宙学家的一个基本研究问题,对我们宇宙的起源和演化的理论模型具有重大意义。宇宙微波背景辐射(CMB)——来自大爆炸的残余能量——描绘了宇宙中物质的分布。宇宙学家在天球上观察CMB,这需要能够在天球内进行宇宙学分析的计算方法。
宇宙学家对分析宇宙微波背景的方法非常感兴趣,因为这些方法能够检测宇宙微波背景在整个空间的分布中的非高斯性,这对早期宇宙理论具有重要意义。这种分析方法还需要能够扩展到天文分辨率。我们通过将CMB模拟分为高斯或非高斯,分辨率为L=1024,证明了我们的散射网络能够满足这些要求。散射网络成功地将这些模拟分类,准确度为95.3%,比低分辨率传统球面CNN的53.1%要好得多。
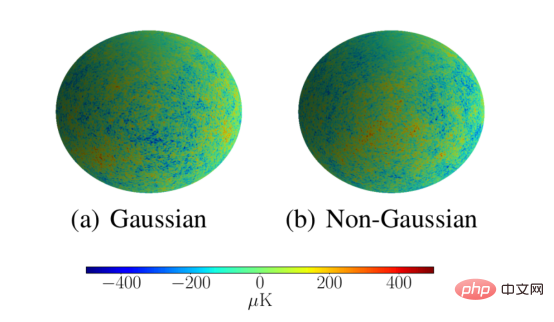
上图给出高斯和非高斯类CMB的高分辨率模拟示例,用于评估球面散射网络扩展到高分辨率的能力。
总结
在本文中,我们探讨了球面散射层能够压缩其输入表示的维度,同时还保留下游任务的重要信息。我们已经证明,这使得散射层对于高分辨率的球面分类任务非常有用。这为以前难以解决的例如宇宙学数据分析和高分辨率360图像/视频分类等潜在应用打开了大门。然而,许多例如分割或深度估计这样的需要密集预测的计算机视觉问题都需要高维输出和高维输入。最后,如何开发可控制的既可以增加输出表示维度同时又能够保持等方差的球面CNN层,这是Kagenova开发人员当前研究的主题。这些内容将在下一篇文章中进行介绍。
参考文献
[1]Cobb, Wallis, Mavor-Parker, Marignier, Price, d’Avezac, McEwen, Efficient Generalised Spherical CNNs, ICLR (2021), arXiv:2010.11661
[2] Cohen, Geiger, Koehler, Welling, Spherical CNNs, ICLR (2018), arXiv:1801.10130
[3] Esteves, Allen-Blanchette, Makadia, Daniilidis, Learning SO(3) Equivariant Representations with Spherical CNNs, ECCV (2018), arXiv:1711.06721
[4] McEwen, Jason, Wallis, Christopher and Mavor-Parker, Augustine N., Scattering Networks on the Sphere for Scalable and Rotationally Equivariant Spherical CNNs, ICLR (2022), arXiv:2102.02828
[5] Bruna, Joan, and Stéphane Mallat, Invariant scattering convolution networks, IEEE Transaction on Pattern Analysis and Machine Intelligence (2013)
[6] Perlmutter, Michael, et al., Geometric wavelet scattering networks on compact Riemannian manifolds, Mathematical and Scientific Machine Learning. PMLR (2020), arXiv:1905.10448
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Scaling Spherical Deep Learning to High-Resolution Input Data,作者:Jason McEwen,Augustine Mavor-Parker
以上是将球面深度学习扩展到高分辨率输入数据的详细内容。更多信息请关注PHP中文网其他相关文章!

 人工智能(AI)、机器学习(ML)和深度学习(DL):有什么区别?Apr 12, 2023 pm 01:25 PM
人工智能(AI)、机器学习(ML)和深度学习(DL):有什么区别?Apr 12, 2023 pm 01:25 PM人工智能Artificial Intelligence(AI)、机器学习Machine Learning(ML)和深度学习Deep Learning(DL)通常可以互换使用。但是,它们并不完全相同。人工智能是最广泛的概念,它赋予机器模仿人类行为的能力。机器学习是将人工智能应用到系统或机器中,帮助其自我学习和不断改进。最后,深度学习使用复杂的算法和深度神经网络来重复训练特定的模型或模式。让我们看看每个术语的演变和历程,以更好地理解人工智能、机器学习和深度学习实际指的是什么。人工智能自过去 70 多
 深度学习GPU选购指南:哪款显卡配得上我的炼丹炉?Apr 12, 2023 pm 04:31 PM
深度学习GPU选购指南:哪款显卡配得上我的炼丹炉?Apr 12, 2023 pm 04:31 PM众所周知,在处理深度学习和神经网络任务时,最好使用GPU而不是CPU来处理,因为在神经网络方面,即使是一个比较低端的GPU,性能也会胜过CPU。深度学习是一个对计算有着大量需求的领域,从一定程度上来说,GPU的选择将从根本上决定深度学习的体验。但问题来了,如何选购合适的GPU也是件头疼烧脑的事。怎么避免踩雷,如何做出性价比高的选择?曾经拿到过斯坦福、UCL、CMU、NYU、UW 博士 offer、目前在华盛顿大学读博的知名评测博主Tim Dettmers就针对深度学习领域需要怎样的GPU,结合自
 字节跳动模型大规模部署实战Apr 12, 2023 pm 08:31 PM
字节跳动模型大规模部署实战Apr 12, 2023 pm 08:31 PM一. 背景介绍在字节跳动,基于深度学习的应用遍地开花,工程师关注模型效果的同时也需要关注线上服务一致性和性能,早期这通常需要算法专家和工程专家分工合作并紧密配合来完成,这种模式存在比较高的 diff 排查验证等成本。随着 PyTorch/TensorFlow 框架的流行,深度学习模型训练和在线推理完成了统一,开发者仅需要关注具体算法逻辑,调用框架的 Python API 完成训练验证过程即可,之后模型可以很方便的序列化导出,并由统一的高性能 C++ 引擎完成推理工作。提升了开发者训练到部署的体验
 基于深度学习的Deepfake检测综述Apr 12, 2023 pm 06:04 PM
基于深度学习的Deepfake检测综述Apr 12, 2023 pm 06:04 PM深度学习 (DL) 已成为计算机科学中最具影响力的领域之一,直接影响着当今人类生活和社会。与历史上所有其他技术创新一样,深度学习也被用于一些违法的行为。Deepfakes 就是这样一种深度学习应用,在过去的几年里已经进行了数百项研究,发明和优化各种使用 AI 的 Deepfake 检测,本文主要就是讨论如何对 Deepfake 进行检测。为了应对Deepfake,已经开发出了深度学习方法以及机器学习(非深度学习)方法来检测 。深度学习模型需要考虑大量参数,因此需要大量数据来训练此类模型。这正是
 聊聊实时通信中的AI降噪技术Apr 12, 2023 pm 01:07 PM
聊聊实时通信中的AI降噪技术Apr 12, 2023 pm 01:07 PMPart 01 概述 在实时音视频通信场景,麦克风采集用户语音的同时会采集大量环境噪声,传统降噪算法仅对平稳噪声(如电扇风声、白噪声、电路底噪等)有一定效果,对非平稳的瞬态噪声(如餐厅嘈杂噪声、地铁环境噪声、家庭厨房噪声等)降噪效果较差,严重影响用户的通话体验。针对泛家庭、办公等复杂场景中的上百种非平稳噪声问题,融合通信系统部生态赋能团队自主研发基于GRU模型的AI音频降噪技术,并通过算法和工程优化,将降噪模型尺寸从2.4MB压缩至82KB,运行内存降低约65%;计算复杂度从约186Mflop
 地址标准化服务AI深度学习模型推理优化实践Apr 11, 2023 pm 07:28 PM
地址标准化服务AI深度学习模型推理优化实践Apr 11, 2023 pm 07:28 PM导读深度学习已在面向自然语言处理等领域的实际业务场景中广泛落地,对它的推理性能优化成为了部署环节中重要的一环。推理性能的提升:一方面,可以充分发挥部署硬件的能力,降低用户响应时间,同时节省成本;另一方面,可以在保持响应时间不变的前提下,使用结构更为复杂的深度学习模型,进而提升业务精度指标。本文针对地址标准化服务中的深度学习模型开展了推理性能优化工作。通过高性能算子、量化、编译优化等优化手段,在精度指标不降低的前提下,AI模型的模型端到端推理速度最高可获得了4.11倍的提升。1. 模型推理性能优化
 深度学习撞墙?LeCun与Marcus到底谁捅了马蜂窝Apr 09, 2023 am 09:41 AM
深度学习撞墙?LeCun与Marcus到底谁捅了马蜂窝Apr 09, 2023 am 09:41 AM今天的主角,是一对AI界相爱相杀的老冤家:Yann LeCun和Gary Marcus在正式讲述这一次的「新仇」之前,我们先来回顾一下,两位大神的「旧恨」。LeCun与Marcus之争Facebook首席人工智能科学家和纽约大学教授,2018年图灵奖(Turing Award)得主杨立昆(Yann LeCun)在NOEMA杂志发表文章,回应此前Gary Marcus对AI与深度学习的评论。此前,Marcus在杂志Nautilus中发文,称深度学习已经「无法前进」Marcus此人,属于是看热闹的不
 英伟达首席科学家:深度学习硬件的过去、现在和未来Apr 12, 2023 pm 03:07 PM
英伟达首席科学家:深度学习硬件的过去、现在和未来Apr 12, 2023 pm 03:07 PM过去十年是深度学习的“黄金十年”,它彻底改变了人类的工作和娱乐方式,并且广泛应用到医疗、教育、产品设计等各行各业,而这一切离不开计算硬件的进步,特别是GPU的革新。 深度学习技术的成功实现取决于三大要素:第一是算法。20世纪80年代甚至更早就提出了大多数深度学习算法如深度神经网络、卷积神经网络、反向传播算法和随机梯度下降等。 第二是数据集。训练神经网络的数据集必须足够大,才能使神经网络的性能优于其他技术。直至21世纪初,诸如Pascal和ImageNet等大数据集才得以现世。 第三是硬件。只有


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3 Linux新版
SublimeText3 Linux最新版

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

