
一篇文章把 Go 中的内存分配扒得干干净净
- Go语言进阶学习转载
- 2023-07-25 13:57:091304浏览
今天给大家盘一盘 Go 中关于内存管理比较常问几个知识点。
# 1. 分配内存三大组件
Go 分配内存的过程,主要由三大组件所管理,级别从上到下分别是:
mheap
Go 在程序启动时,首先会向操作系统申请一大块内存,并交由mheap结构全局管理。
具体怎么管理呢?mheap 会将这一大块内存,切分成不同规格的小内存块,我们称之为 mspan,根据规格大小不同,mspan 大概有 70类左右,划分得可谓是非常的精细,足以满足各种对象内存的分配。
那么这些 mspan 大大小小的规格,杂乱在一起,肯定很难管理对吧?
因此就有了 mcentral 这下一级组件
mcentral
启动一个 Go 程序,会初始化很多的 mcentral ,每个 mcentral 只负责管理一种特定规格的 mspan。
相当于 mcentral 实现了在 mheap 的基础上对 mspan 的精细化管理。
但是 mcentral 在 Go 程序中是全局可见的,因此如果每次协程来 mcentral 申请内存的时候,都需要加锁。
可以预想,如果每个协程都来 mcentral 申请内存,那频繁的加锁释放锁开销是非常大的。
因此需要有一个 mcentral 的二级代理来缓冲这种压力
mcache
在一个 Go 程序里,每个线程M会绑定给一个处理器P,在单一粒度的时间里只能做多处理运行一个goroutine,每个P都会绑定一个叫 mcache 的本地缓存。
当需要进行内存分配时,当前运行的goroutine会从mcache中查找可用的mspan。从本地mcache里分配内存时不需要加锁,这种分配策略效率更高。
mspan 供应链
mcache 的 mspan 数量并不总是充足的,当供不应求的时候,mcache 会从 mcentral 再次申请更多的 mspan,同样的,如果 mcentral 的 mspan 数量也不够的话,mcentral 也会向它的上级 mheap 申请 mspan。再极端一点,如果 mheap 里的 mspan 也无法满足程序的内存申请,那该怎么办?
那就没办法啦,mheap 只能厚着脸皮跟操作系统这个老大哥申请了。
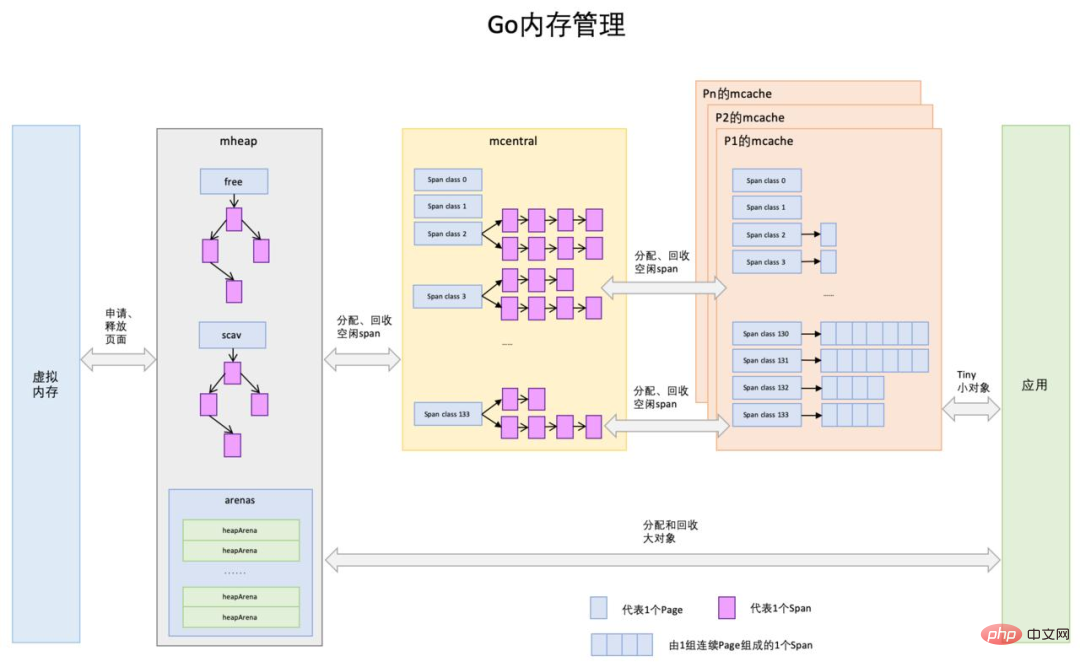
以上的供应流程,只适用于内存块小于 64KB 的场景,原因在于Go 没法使用工作线程的本地缓存mcache和全局中心缓存 mcentral 上管理超过 64KB 的内存分配,所以对于那些超过 64KB 的内存申请,会直接从堆上(mheap)上分配对应的数量的内存页(每页大小是 8KB)给程序。
# 2. 什么是堆内存和栈内存?
根据内存管理(分配和回收)方式的不同,可以将内存分为 堆内存 和 栈内存。
那么他们有什么区别呢?
堆内存:由内存分配器和垃圾收集器负责回收
栈内存:由编译器自动进行分配和释放
一个程序运行过程中,也许会有多个栈内存,但肯定只会有一个堆内存。
每个栈内存都是由线程或者协程独立占有,因此从栈中分配内存不需要加锁,并且栈内存在函数结束后会自动回收,性能相对堆内存好要高。
而堆内存呢?由于多个线程或者协程都有可能同时从堆中申请内存,因此在堆中申请内存需要加锁,避免造成冲突,并且堆内存在函数结束后,需要 GC (垃圾回收)的介入参与,如果有大量的 GC 操作,将会吏程序性能下降得历害。
# 3. 逃逸分析的必要性
由此可以看出,为了提高程序的性能,应当尽量减少内存在堆上分配,这样就能减少 GC 的压力。
在判断一个变量是在堆上分配内存还是在栈上分配内存,虽然已经有前人已经总结了一些规律,但依靠程序员能够在编码的时候时刻去注意这个问题,对程序员的要求相当之高。
好在 Go 的编译器,也开放了逃逸分析的功能,使用逃逸分析,可以直接检测出你程序员所有分配在堆上的变量(这种现象,即是逃逸)。
方法是执行如下命令
go build -gcflags '-m -l' demo.go # 或者再加个 -m 查看更详细信息 go build -gcflags '-m -m -l' demo.go
# 内存分配位置的规律
如果逃逸分析工具,其实人工也可以判断到底有哪些变量是分配在堆上的。
那么这些规律是什么呢?
经过总结,主要有如下四种情况
根据变量的使用范围
根据变量类型是否确定
根据变量的占用大小
根据变量长度是否确定
接下来我们一个一个分析验证
根据变量的使用范围
当你进行编译的时候,编译器会做逃逸分析(escape analysis),当发现一个变量的使用范围仅在函数中,那么可以在栈上为它分配内存。
比如下边这个例子
func foo() int {
v := 1024
return v
}
func main() {
m := foo()
fmt.Println(m)
}我们可以通过 go build -gcflags '-m -l' demo.go 来查看逃逸分析的结果,其中 -m 是打印逃逸分析的信息,-l 则是禁止内联优化。
从分析的结果我们并没有看到任何关于 v 变量的逃逸说明,说明其并没有逃逸,它是分配在栈上的。
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: m escapes to heap
而如果该变量还需要在函数范围之外使用,如果还在栈上分配,那么当函数返回的时候,该变量指向的内存空间就会被回收,程序势必会报错,因此对于这种变量只能在堆上分配。
比如下边这个例子,返回的是指针
func foo() *int {
v := 1024
return &v
}
func main() {
m := foo()
fmt.Println(*m) // 1024
}从逃逸分析的结果中可以看到 moved to heap: v ,v 变量是从堆上分配的内存,和上面的场景有着明显的区别。
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: v ./demo.go:12:13: ... argument does not escape ./demo.go:12:14: *m escapes to heap
除了返回指针之外,还有其他的几种情况也可归为一类:
第一种情况:返回任意引用型的变量:Slice 和 Map
func foo() []int {
a := []int{1,2,3}
return a
}
func main() {
b := foo()
fmt.Println(b)
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:12: []int literal escapes to heap ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: b escapes to heap
第二种情况:在闭包函数中使用外部变量
func Increase() func() int {
n := 0
return func() int {
n++
return n
}
}
func main() {
in := Increase()
fmt.Println(in()) // 1
fmt.Println(in()) // 2
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: n ./demo.go:7:9: func literal escapes to heap ./demo.go:15:13: ... argument does not escape ./demo.go:15:16: in() escapes to heap
根据变量类型是否确定
在上边例子中,也许你发现了,所有编译输出的最后一行中都是 m escapes to heap 。
奇怪了,为什么 m 会逃逸到堆上?
其实就是因为我们调用了 fmt.Println() 函数,它的定义如下
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}可见其接收的参数类型是 interface{} ,对于这种编译期不能确定其参数的具体类型,编译器会将其分配于堆上。
根据变量的占用大小
最开始的时候,就介绍到,以 64KB 为分界线,我们将内存块分为 小内存块 和 大内存块。
小内存块走常规的 mspan 供应链申请,而大内存块则需要直接向 mheap,在堆区申请。
以下的例子来说明
func foo() {
nums1 := make([]int, 8191) // < 64KB
for i := 0; i < 8191; i++ {
nums1[i] = i
}
}
func bar() {
nums2 := make([]int, 8192) // = 64KB
for i := 0; i < 8192; i++ {
nums2[i] = i
}
}给 -gcflags 多加个 -m 可以看到更详细的逃逸分析的结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:5:15: make([]int, 8191) does not escape ./demo.go:12:15: make([]int, 8192) escapes to heap
那为什么是 64 KB 呢?
我只能说是试出来的 (8191刚好不逃逸,8192刚好逃逸),网上有很多文章千篇一律的说和 ulimit -a 中的 stack size 有关,但经过了解这个值表示的是系统栈的最大限制是 8192 KB,刚好是 8M。
$ ulimit -a -t: cpu time (seconds) unlimited -f: file size (blocks) unlimited -d: data seg size (kbytes) unlimited -s: stack size (kbytes) 8192
我个人实在无法理解这个 8192 (8M) 和 64 KB 是如何对应上的,如果有朋友知道,还请指教一下。
根据变量长度是否确定
由于逃逸分析是在编译期就运行的,而不是在运行时运行的。因此避免有一些不定长的变量可能会很大,而在栈上分配内存失败,Go 会选择把这些变量统一在堆上申请内存,这是一种可以理解的保险的做法。
func foo() {
length := 10
arr := make([]int, 0 ,length) // 由于容量是变量,因此不确定,因此在堆上申请
}
func bar() {
arr := make([]int, 0 ,10) // 由于容量是常量,因此是确定的,因此在栈上申请
}以上是一篇文章把 Go 中的内存分配扒得干干净净的详细内容。更多信息请关注PHP中文网其他相关文章!