



目前,构建通用人工智能(AGI)系统的方法,在帮助人们更好地解决现实问题的同时,也会带来一些意外的风险。
因此,在未来,人工智能的进一步发展可能会导致很多极端风险,如具有攻击性的网络能力或强大的操纵技能等等。
今天,Google DeepMind 联合剑桥大学、牛津大学等高校和 OpenAI、Anthropic等企业,以及 Alignment Research Center 等机构,在预印本网站 arXiv 上发表了题为“Model evaluation for extreme risks”的文章,提出了一个针对新型威胁评估通用模型的框架,并解释了为何模型评估对应对极端风险至关重要。
他们认为,开发者必须具备能够识别危险的能力(通过"危险能力评估"),以及模型应用其能力造成伤害的倾向(通过"对齐评估")。这些评估将对让决策者和其他利益相关方保持了解,并对模型的训练、部署和安全做出负责任的决策至关重要。

学术头条(ID:SciTouTiao)在不改变原文大意的情况下,做了简单的编译。内容如下:
为了负责任地推动人工智能前沿研究的进一步发展,我们必须尽早识别人工智能系统中的新能力和新风险。
人工智能研究人员已经使用一系列评估基准来识别人工智能系统中不希望出现的行为,如人工智能系统做出误导性的声明、有偏见的决定或重复有版权的内容。现在,随着人工智能社区建立和部署越来越强大的人工智能,我们必须扩大评估范围,包括对具有操纵、欺骗、网络攻击或其他危险能力的通用人工智能模型可能带来的极端风险的考虑。
我们与剑桥大学、牛津大学、多伦多大学、蒙特利尔大学、OpenAI、Anthropic、Alignment Research Center、Centre for Long-Term Resilience 和 Centre for the Governance of AI 合作,介绍了一个评估这些新威胁的框架。
模型安全评估,包括评估极端风险,将成为安全的人工智能开发和部署的重要组成部分。
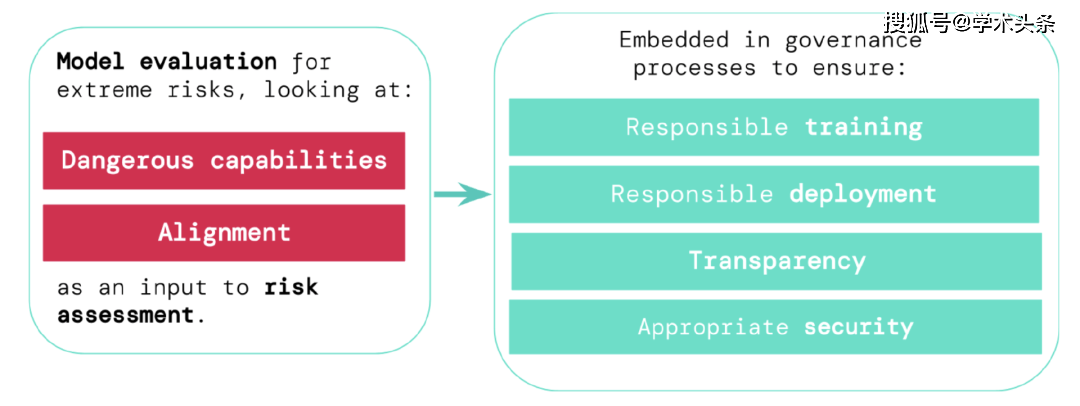
为了评估新型通用人工智能系统的极端风险,开发者需要对其危险能力和对齐水平进行评估。早期识别风险,可以使得在训练新的人工智能系统、部署这些人工智能系统、透明地描述它们的风险以及应用适当的网络安全标准时更加负责。
对极端风险进行评估
通用模型通常在训练中学习它们的能力和行为。然而,现有的指导学习过程的方法并不完善。例如,Google DeepMind 之前的研究已经探讨了人工智能系统如何学习追求人们不希望看到的目标,即使我们正确地奖励了它们的良好行为。
负责任的人工智能开发者必须更进一步,预测未来可能的发展和新的风险。随着持续进步,未来的通用模型可能会默认学习各种危险的能力。例如,未来的人工智能系统能够进行攻击性的网络活动,在对话中巧妙地欺骗人类,操纵人类进行有害的行为,设计或获取武器(如生物、化学武器),在云计算平台上微调和操作其他高风险的人工智能系统,或者协助人类完成任何这些任务,这都是可能的(尽管不确定)。
怀有不良意图的人可能会滥用这些模型的能力。这些人工智能模型由于与人类的价值观和道德不同而可能会采取有害行为,即使没有人有意这样做。
模型评估有助于我们提前识别这些风险。在我们的框架下,人工智能开发者将使用模型评估来揭开:
- 一个模型在多大程度上具有某些“危险的能力”,威胁安全,施加影响,或逃避监督。
- 模型在多大程度上容易使用其能力来造成伤害(即模型的对齐水平)。有必要确认模型即使在非常广泛的情况下也能按预期行事,并且在可能的情况下,应该检查模型的内部运作情况。
通过这些评估的结果,人工智能开发者可以了解是否存在可能导致极端风险的因素。最高风险的情况将涉及多种危险能力的组合。如下图:
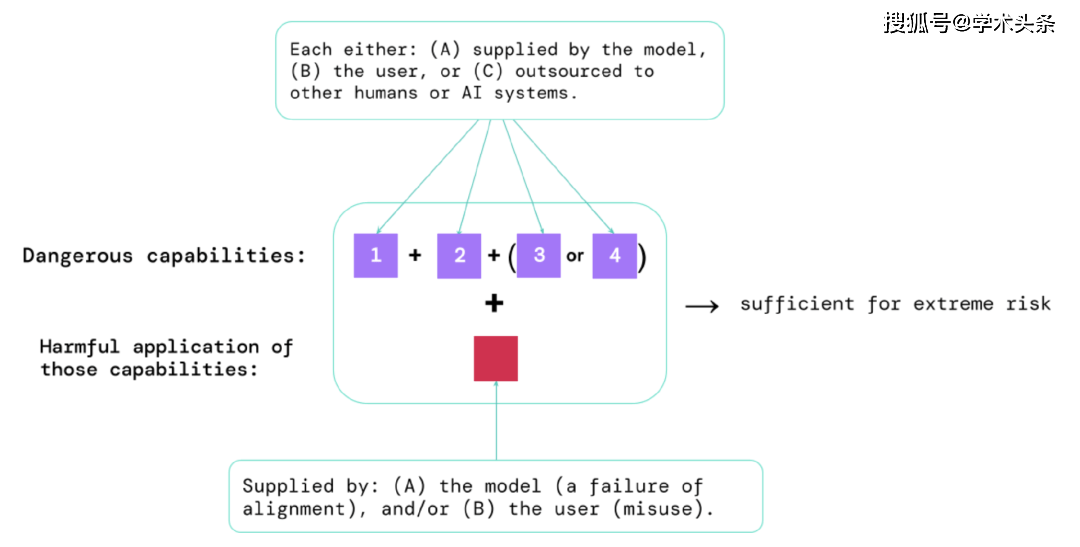
图|构成极端风险的要素:有时,特定的能力可能会被外包,可以是交给人类(例如用户或众包工作者)或其他AI系统。无论是出于滥用还是因为未能取得对齐,这些能力都必须用于造成伤害。
一个经验法则:如果一个人工智能系统具有足以造成极端伤害的能力特征,假设它被滥用或无法对齐,那么人工智能社区应将其视为“高度危险”。要在现实世界中部署这样的系统,人工智能开发者需要展现出异常高的安全标准。
模型评估是关键的治理基础设施
如果我们有更好的工具来识别哪些模型是有风险的,公司和监管机构就能更好地确保:
- 负责任的训练:负责任地决定是否以及如何训练一个显示出早期风险迹象的新模型。
- 负责任的部署:对是否、何时以及如何部署有潜在风险的模型做出负责任的决定。
- 透明度:向利益相关者报告有用的和可操作的信息,以帮助他们应对或减少潜在的风险。
- 适当的安全:强大的信息安全控制和系统适用于可能构成极端风险的模型。
我们已经制定了一个蓝图,说明了针对极端风险的模型评估应如何为训练和部署能力强大的通用模型的重要决策提供支持。开发者在整个过程中进行评估,并授权外部安全研究人员和模型审核员对模型进行结构化访问,以便他们进行额外的评估。评估结果可以在模型训练和部署之前提供风险评估的参考。
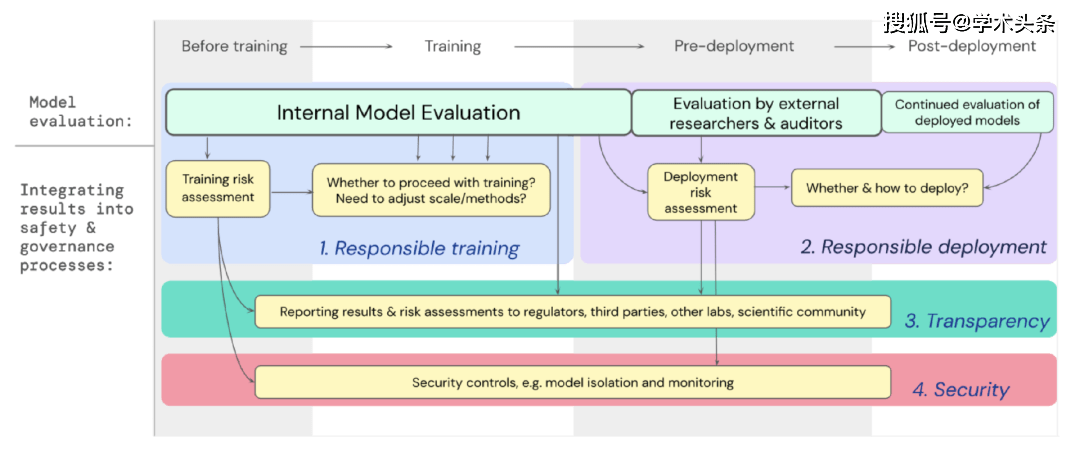
图|将针对极端风险的模型评估嵌入到整个模型训练和部署的重要决策过程中。
展望未来
在Google DeepMind和其他地方,对于极端风险的模型评估的重要初步工作已经开始进行。但要构建一个能够捕捉所有可能风险并有助于防范未来新出现的挑战的评估流程,我们需要更多的技术和机构方面的努力。
模型评估并不是万能的解决方案;有时,一些风险可能会逃脱我们的评估,因为它们过于依赖模型外部的因素,比如社会中复杂的社会、政治和经济力量。需要将模型评估与整个行业、政府和公众对安全的广泛关注以及其他风险评估工具相结合。
谷歌最近在其有关负责任人工智能的博客中提到,“个体实践、共享行业标准和合理的政府政策对于正确使用人工智能至关重要”。我们希望许多从事人工智能工作和受这项技术影响的行业能够共同努力,为安全开发和部署人工智能共同制定方法和标准,造福所有人。
我们相信,拥有跟踪模型中出现的风险属性的程序,以及对相关结果的充分回应,是作为一个负责任的开发者在人工智能前沿研究工作中的关键部分。
以上是Google DeepMind、OpenAI等联合发文:AI大模型的极端风险,如何评估?的详细内容。更多信息请关注PHP中文网其他相关文章!

 是什么使Phi 3.5 SLM成为生成AI的游戏改变者?Apr 14, 2025 am 09:13 AM
是什么使Phi 3.5 SLM成为生成AI的游戏改变者?Apr 14, 2025 am 09:13 AMMicrosoft揭幕了PHI-3.5:一个高效且强大的小语言模型的家族 Microsoft的最新一代小语言模型(SLM),PHI-3.5家族,拥有各种基准的卓越性能,包括理性
 Python功能和Lambdas的指南 - 分析VidhyaApr 14, 2025 am 09:12 AM
Python功能和Lambdas的指南 - 分析VidhyaApr 14, 2025 am 09:12 AMPython:掌握功能和lambda功能,以实现高效且可读的代码 我们探索了Python的多功能性;现在,让我们深入研究其提高代码效率和可读性的功能。 维持生产级别的代码模块化

 优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM
优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM介绍 恭喜!您经营一家成功的业务。通过您的网页,社交媒体活动,网络研讨会,会议,免费资源和其他来源,您每天收集5000个电子邮件ID。下一个明显的步骤是
 Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM
Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM介绍 在当今快节奏的软件开发环境中,确保最佳应用程序性能至关重要。监视实时指标,例如响应时间,错误率和资源利用率可以帮助MAIN
 Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM
Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM“您有几个用户?”他扮演。 阿尔特曼回答说:“我认为我们上次说的是每周5亿个活跃者,而且它正在迅速增长。” “你告诉我,就像在短短几周内翻了一番,”安德森继续说道。 “我说那个私人
 pixtral -12b:Mistral AI'第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM介绍 Mistral发布了其第一个多模式模型,即Pixtral-12b-2409。该模型建立在Mistral的120亿参数Nemo 12B之上。是什么设置了该模型?现在可以拍摄图像和Tex
 生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想象一下,拥有一个由AI驱动的助手,不仅可以响应您的查询,还可以自主收集信息,执行任务甚至处理多种类型的数据(TEXT,图像和代码)。听起来有未来派?在这个a


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

Dreamweaver CS6
视觉化网页开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

