
Redis中RDB持久化的示例分析

- PHPz转载
- 2023-05-28 18:11:171027浏览
1、RDB 简介
RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
2、触发方式
RDB 有两种触发方式,分别是自动触发和手动触发。
①、自动触发
在 redis.conf 配置文件中的 SNAPSHOTTING 下,在这篇文章中我们介绍过。
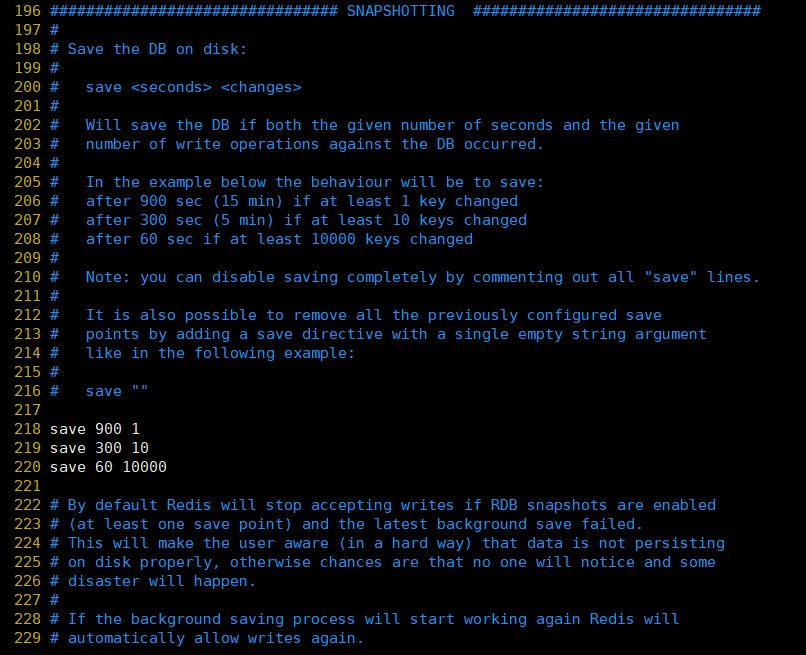
①、save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave(这个命令下面会介绍,手动触发RDB持久化的命令)
默认如下配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
当然如果你只是用Redis的缓存功能,不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。可以使用 save "" 来实现停用
②、stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
③、rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
④、rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
⑤、dbfilename :设置快照的文件名,默认是 dump.rdb
⑥、dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。默认是和当前配置文件保存在同一目录。
也就是说通过在配置文件中配置的 save 方式,当实际操作满足该配置形式时就会进行 RDB 持久化,将当前的内存快照保存在 dir 配置的目录中,文件名由配置的 dbfilename 决定。
②、手动触发
手动触发Redis进行RDB持久化的命令有两种:
1、save
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷,为了解决此问题,Redis提供了第二种方式。
2、bgsave
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。当Redis进程执行fork操作创建子进程时,该子进程将负责执行RDB持久化过程,并在完成后自动终止。阻塞只发生在fork阶段,一般时间很短。
基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
ps:执行执行 flushall 命令,也会产生dump.rdb文件,但里面是空的,无意义
3、恢复数据
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis服务器会在加载RDB文件期间一直阻塞,直到加载工作完成。
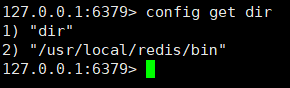
获取 redis 的安装目录可以使用 config get dir 命令
4、停止 RDB 持久化
有些情况下,我们只想利用Redis的缓存功能,并不像使用 Redis 的持久化功能,那么这时候我们最好停掉 RDB 持久化。可以通过上面讲的在配置文件 redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者直接一个空字符串来实现停用:save ""
也可以通过命令:
|
redis-cli config set save " "
|
5、RDB 的优势和劣势
①、优势
Redis的数据集在特定时间点上保存在RDB文件中,这个文件非常紧凑。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
1、RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2、RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
3、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
6、RDB 自动保存的原理
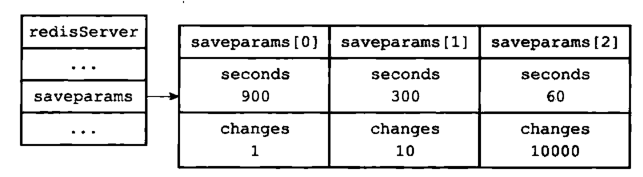
Redis有个服务器状态结构:
3
7 8 9 |
long long dirty; time_t lastsave;}
|
 6
6| 123456 |
struct saveparam{ time_t seconds; int changes;};
|
| 123 |
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
|
以上是Redis中RDB持久化的示例分析的详细内容。更多信息请关注PHP中文网其他相关文章!