



译者 | 布加迪
审校 | 孙淑娟
过去十年是深度学习的时代。我们为从AlphaGo到DELL-E 2的一系列重大事件而激动不已。日常生活中出现了不计其数的由人工智能(AI)驱动的产品或服务,包括Alexa设备、广告推荐、仓库机器人和自动驾驶汽车等。

近年来,深度学习模型的规模呈指数级增长。这不是什么新闻了:Wu Dao 2.0模型含有1.75万亿参数,在SageMaker训练平台的240个ml.p4d.24xlarge实例上训练GPT-3大约只需25天。
但随着深度学习训练和部署的发展,它变得越来越具有挑战性。由于深度学习模型的发展,可扩展性和效率是训练和部署面临的两大挑战。
本文将总结机器学习(ML)加速器的五大类型。
了解AI工程中的ML生命周期
在全面介绍ML加速器之前,不妨先看看ML生命周期。
ML生命周期是数据和模型的生命周期。数据可谓是ML的根源,决定着模型的质量。生命周期中的每个方面都有机会加速。
MLOps可以使ML模型部署的过程实现自动化。但由于操作性质,它局限于AI工作流的横向过程,无法从根本上改善训练和部署。
AI工程远超MLOps的范畴,它可以整体(横向和纵向)设计机器学习工作流的过程以及训练和部署的架构。此外,它可以通过整个ML生命周期的有效编排来加速部署和训练。
基于整体式ML生命周期和AI工程,有五种主要类型的ML加速器(或加速方面):硬件加速器、AI计算平台、AI框架、ML编译器和云服务。先看下面的关系图。
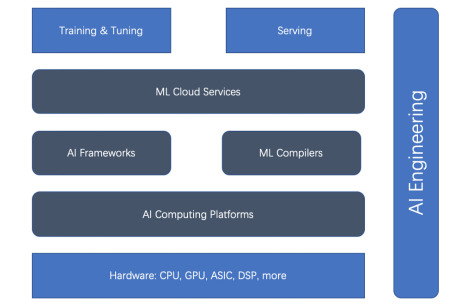
图1. 训练与部署加速器的关系
我们可以看到,硬件加速器和AI框架是加速的主流。但最近,ML编译器、AI计算平台和ML云服务已变得越来越重要。
下面逐一介绍。
1. AI框架
在谈到加速ML训练和部署时,选择合适的AI框架无法回避。遗憾的是,不存在一应俱全的完美或最佳AI框架。广泛用于研究和生产的三种AI框架是TensorFlow、PyTorch和JAX。它们在不同的方面各有千秋,比如易用性、产品成熟度和可扩展性。
TensorFlow:TensorFlow是旗舰AI框架。TensorFlow一开始就主导深度学习开源社区。TensorFlow Serving是一个定义完备的成熟平台。对于互联网和物联网来说,TensorFlow.js和TensorFlow Lite也已成熟。
但由于深度学习早期探索的局限性,TensorFlow 1.x旨在以一种非Python的方式构建静态图。这成为使用“eager”模式进行即时评估的障碍,这种模式让PyTorch可以在研究领域迅速提升。TensorFlow 2.x试图迎头赶上,但遗憾的是,从TensorFlow 1.x升级到2.x很麻烦。
TensorFlow还引入了Keras,以便总体上更易使用,另引入了优化编译器的XLA(加速线性代数),以加快底层速度。
PyTorch:凭借其eager模式和类似Python的方法,PyTorch是如今深度学习界的主力军,用于从研究到生产的各个领域。除了TorchServe外,PyTorch还与跟框架无关的平台(比如Kubeflow)集成。此外,PyTorch的人气与Hugging Face的Transformers库大获成功密不可分。
JAX:谷歌推出了JAX,基于设备加速的NumPy和JIT。正如PyTorch几年前所做的那样,它是一种更原生的深度学习框架,在研究领域迅速受到追捧。但它还不是谷歌声称的“官方”谷歌产品。
2. 硬件加速器
毫无疑问,英伟达的GPU 可以加速深度学习训练,不过它最初是为视频卡设计的。
通用GPU出现后,用于神经网络训练的图形卡人气爆棚。这些通用GPU可以执行任意代码,不仅仅是渲染子例程。英伟达的CUDA编程语言提供了一种用类似C的语言编写任意代码的方法。通用GPU有相对方便的编程模型、大规模并行机制和高内存带宽,现在为神经网络编程提供了一种理想的平台。
如今,英伟达支持从桌面到移动、工作站、移动工作站、游戏机和数据中心的一系列GPU。
随着英伟达GPU大获成功,一路走来不乏后继者,比如AMD的GPU和谷歌的TPU ASIC等。
3. AI计算平台
如前所述,ML训练和部署的速度很大程度上依赖硬件(比如GPU和TPU)。这些驱动平台(即AI计算平台)对性能至关重要。有两个众所周知的AI计算平台:CUDA和OpenCL。
CUDA:CUDA(计算统一设备架构)是英伟达于2007年发布的并行编程范式。它是为图形处理器和GPU的众多通用应用设计的。CUDA是专有API,仅支持英伟达的Tesla架构GPU。CUDA支持的显卡包括GeForce 8系列、Tesla和Quadro。
OpenCL:OpenCL(开放计算语言)最初由苹果公司开发,现由Khronos团队维护,用于异构计算,包括CPU、GPU、DSP及其他类型的处理器。这种可移植语言的适应性足够强,可以让每个硬件平台实现高性能,包括英伟达的GPU。
英伟达现在符合OpenCL 3.0,可用于R465及更高版本的驱动程序。使用OpenCL API,人们可以在GPU上启动使用C编程语言的有限子集编写的计算内核。
4. ML编译器
ML编译器在加速训练和部署方面起着至关重要的作用。ML编译器可显著提高大规模模型部署的效率。有很多流行的编译器,比如Apache TVM、LLVM、谷歌MLIR、TensorFlow XLA、Meta Glow、PyTorch nvFuser和Intel PlaidML。
5. ML云服务
ML云平台和服务在云端管理ML平台。它们可以通过几种方式来优化,以提高效率。
以Amazon SageMaker为例。这是一种领先的ML云平台服务。SageMaker为ML生命周期提供了广泛的功能特性:从准备、构建、训练/调优到部署/管理,不一而足。
它优化了许多方面以提高训练和部署效率,比如GPU上的多模型端点、使用异构集群的经济高效的训练,以及适合基于CPU的ML推理的专有Graviton处理器。
结语
随着深度学习训练和部署规模不断扩大,挑战性也越来越大。提高深度学习训练和部署的效率很复杂。基于ML生命周期,有五个方面可以加速ML训练和部署:AI框架、硬件加速器、计算平台、ML编译器和云服务。AI工程可以将所有这些协调起来,利用工程原理全面提高效率。
原文标题:5 Types of ML Accelerators,作者:Luhui Hu
以上是简述机器学习加速器的五种类型的详细内容。更多信息请关注PHP中文网其他相关文章!

 10个生成AI编码扩展,在VS代码中,您必须探索Apr 13, 2025 am 01:14 AM
10个生成AI编码扩展,在VS代码中,您必须探索Apr 13, 2025 am 01:14 AM嘿,编码忍者!您当天计划哪些与编码有关的任务?在您进一步研究此博客之前,我希望您考虑所有与编码相关的困境,这是将其列出的。 完毕? - 让&#8217
 烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PM
烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PMAI增强食物准备 在新生的使用中,AI系统越来越多地用于食品制备中。 AI驱动的机器人在厨房中用于自动化食物准备任务,例如翻转汉堡,制作披萨或组装SA
 Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM
Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM介绍 了解Python功能中变量的名称空间,范围和行为对于有效编写和避免运行时错误或异常至关重要。在本文中,我们将研究各种ASP
 视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM
视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM介绍 想象一下,穿过美术馆,周围是生动的绘画和雕塑。现在,如果您可以向每一部分提出一个问题并获得有意义的答案,该怎么办?您可能会问:“您在讲什么故事?
 联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM
联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM继续使用产品节奏,本月,Mediatek发表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。这些产品填补了Mediatek业务中更传统的部分,其中包括智能手机的芯片
 本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM
本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:现在是星期一早上。作为AI驱动的招聘人员,您更聪明,而不是更努力。您在手机上登录公司的仪表板。它告诉您三个关键角色已被采购,审查和计划的FO
 生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM我猜你一定是。 我们似乎都知道,心理障碍包括各种chat不休,这些chat不休,这些chat不休,混合了各种心理术语,并且常常是难以理解的或完全荒谬的。您需要做的一切才能喷出fo
 原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM
原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM根据本周发表的一项新研究,只有在2022年制造的塑料中,只有9.5%的塑料是由回收材料制成的。同时,塑料在垃圾填埋场和生态系统中继续堆积。 但是有帮助。一支恩金团队


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Atom编辑器mac版下载
最流行的的开源编辑器

