



ChatGPT发布后,自然语言处理领域的生态彻底发生了变化,很多之前无法完成的问题都可以利用ChatGPT解决。
不过也带来了一个问题:大模型的性能都太强了,光靠肉眼很难评估各个模型的差异。
比如用不同的基座模型和超参数训练了几版模型,从样例来看性能可能都差不多,无法完全量化两个模型之间的性能差距。
目前评估大语言模型主要有两个方案:
1、调用OpenAI的API接口评估。
ChatGPT可以用来评估两个模型输出的质量,不过ChatGPT一直在迭代升级,不同时间对同一个问题的回复可能会有所不同,评估结果存在无法复现的问题。
2、人工标注
如果在众包平台上请人工标注的话,经费不足的团队可能无力负担,也存在第三方公司泄露数据的情况。
为了解决诸如此类的「大模型评估问题」,来自北京大学、西湖大学、北卡罗来纳州立大学、卡内基梅隆大学、MSRA的研究人员合作开发了一个全新的语言模型评估框架PandaLM,致力于实现保护隐私、可靠、可复现及廉价的大模型评估方案。

项目链接:https://github.com/WeOpenML/PandaLM
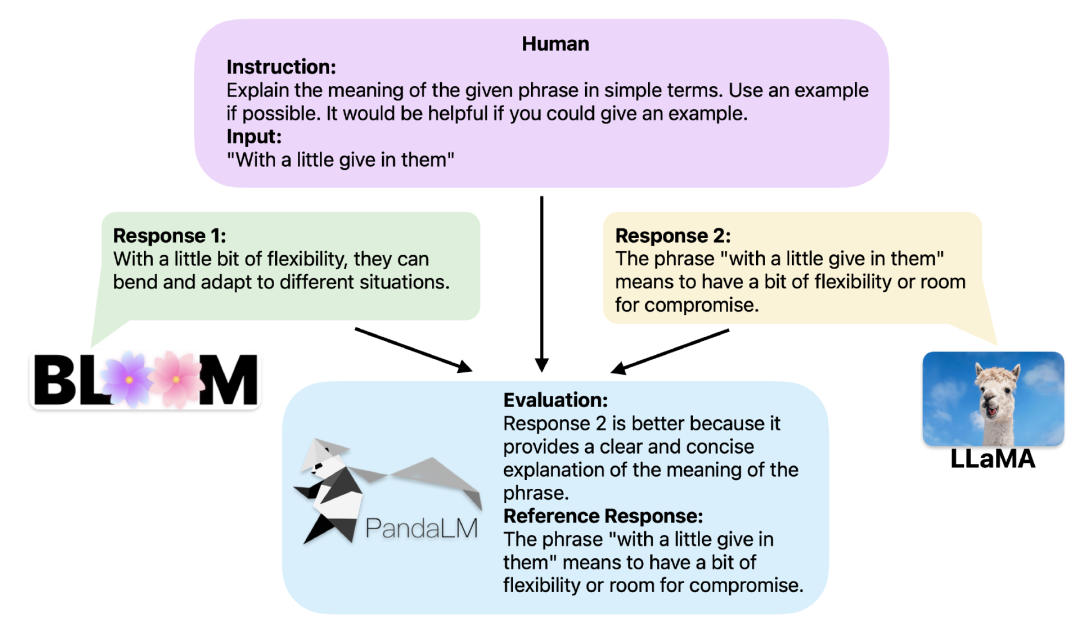
提供相同的上下文,PandaLM可以比较不同LLM的响应输出,并提供具体的理由。
为了证明该工具的可靠性和一致性,研究人员创建了一个由大约1000个样本组成的多样化的人类标注测试数据集,其中PandaLM-7B的准确率达到了ChatGPT的94%评估能力。
三行代码用上PandaLM
当两个不同的大模型对同一个指令和上下文产生不同响应时,PandaLM旨在比较这两个大模型的响应质量,并输出比较结果,比较理由以及可供参考的响应。
比较结果有三种:响应1更好,响应2更好,响应1与响应2质量相似。
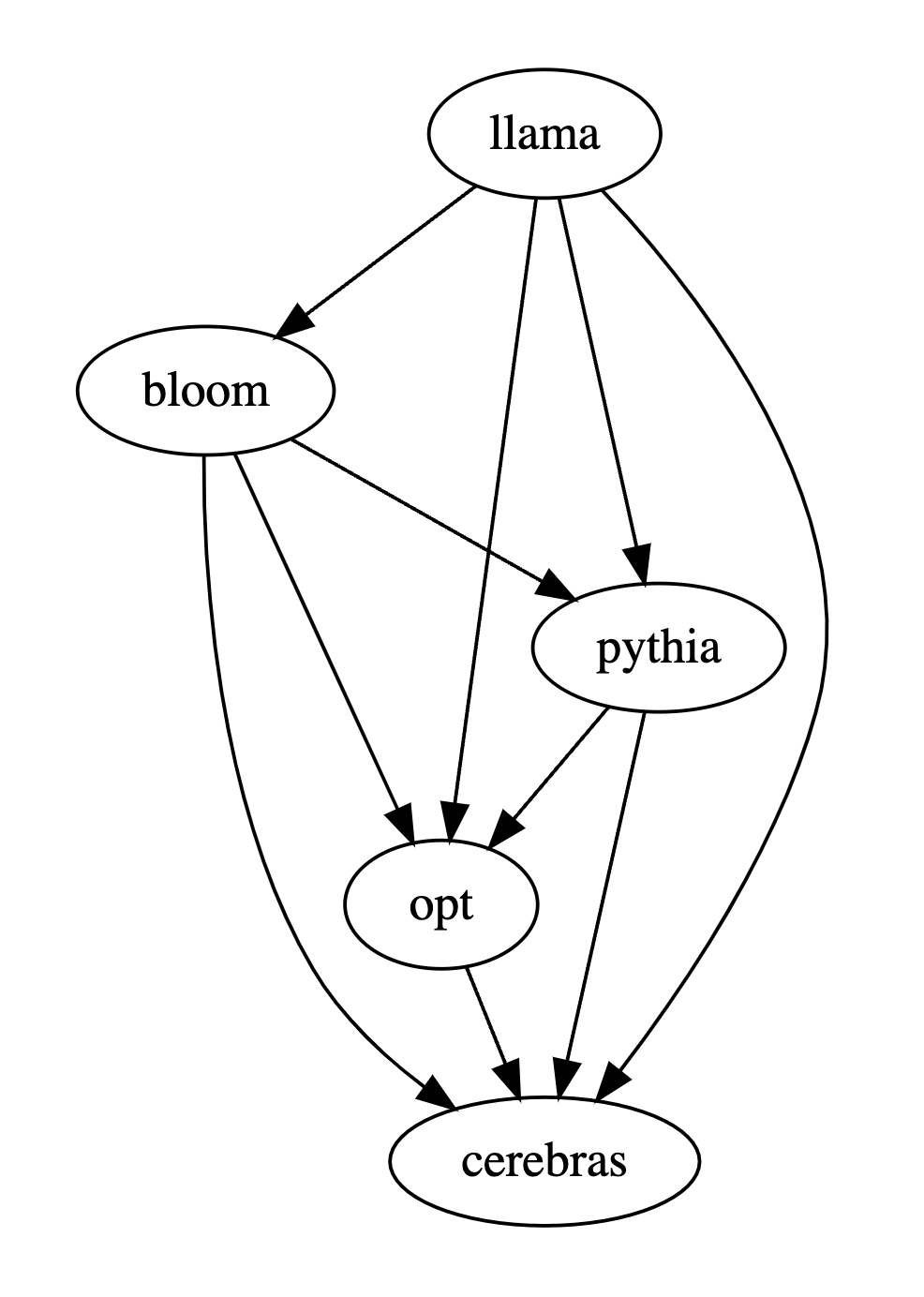
比较多个大模型的性能时,只需使用PandaLM对其进行两两比较,再汇总两两比较的结果进行多个大模型的性能排名或画出模型偏序关系图,即可清晰直观地分析不同模型间的性能差异。
PandaLM只需要在「本地部署」,且「不需要人类参与」,因此PandaLM的评估是可以保护隐私且相当廉价的。
为了提供更好的可解释性,PandaLM亦可用自然语言对其选择进行解释,并额外生成一组参考响应。
在项目中,研究人员不仅支持使用Web UI使用PandaLM以便于进行案例分析,为了方便使用,还支持三行代码调用PandaLM对任意模型和数据生成的文本评估。
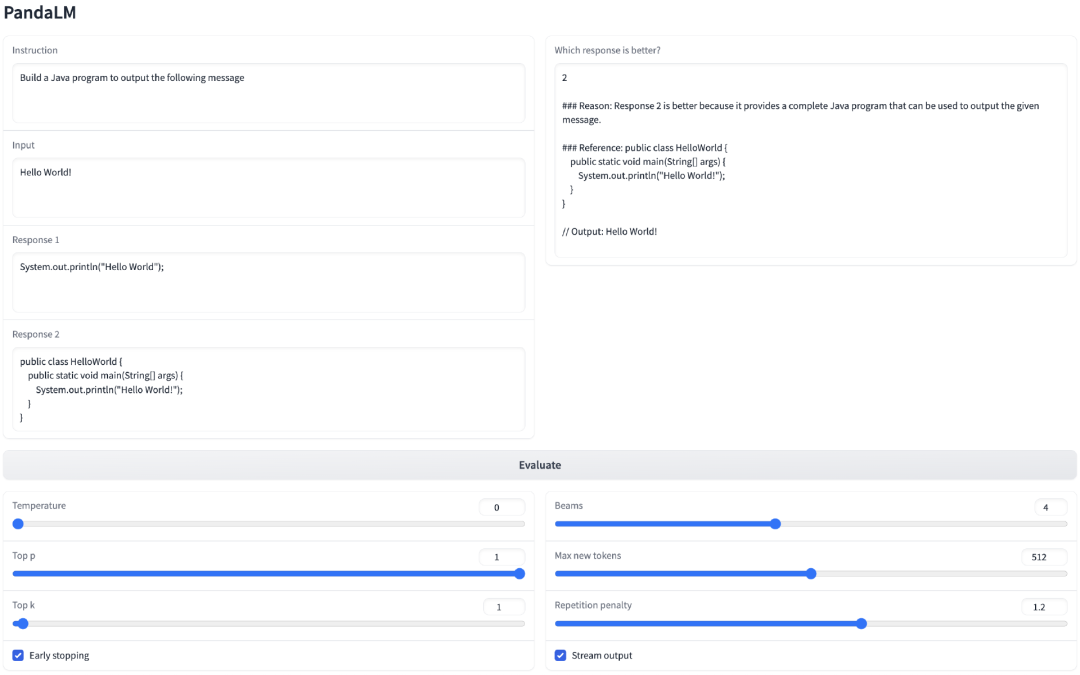
考虑到现有的许多模型、框架并不开源或难以在本地完成推理,PandaLM支持利用指定模型权重生成待评估文本,或直接传入包含待评估文本的.json文件。
用户只需传入一个包含模型名称/HuggingFace模型ID或.json文件路径的列表,即可利用PandaLM对用户定义的模型和输入数据进行评估。下面是一个极简的使用示例:

为了能让大家灵活的运用PandaLM进行自由评测,研究人员也将PandaLM的模型权重公布在了huggingface网站上,可以通过以下命令加载PandaLM-7B模型:

PandaLM的特点
可复现性
因为PandaLM的权重是公开的,即使语言模型的输出有随机性,当固定随机种子之后,PandaLM的评价结果仍可始终保持一致。
而基于在线API的模型的更新不透明,其输出在不同时间有可能很不一致,且旧版模型不再可访问,因此基于在线API的评测往往不具有可复现性。
自动化、保护隐私性和开销低
只需本地部署PandaLM模型,调用现成的命令即可开始评估各种大模型,不需像雇佣专家标注时要时刻与专家保持沟通,也不会存在数据泄露的问题,同时也不涉及任何API费用以及劳务费用,非常廉价。
评估水平
为了证明PandaLM的可靠性,研究人员雇佣了三个专家进行独立重复标注,创建了一个人工标注的测试集。
测试集包含50个不同的场景,每个场景中又包含若干任务。这个测试集是多样化、可靠且与人类对文本的偏好相一致的。测试集的每个样本由一个指令和上下文,以及两个由不同大模型生成的响应共同组成,并由人类来比较这两个响应的质量。
筛除了标注员之间有较大差异的样本,以确保每个标注者在最终测试集上的IAA(Inter Annotator Agreement)接近0.85。值得注意的是,PandaLM的训练集与创建的人工标注测试集无任何重叠。
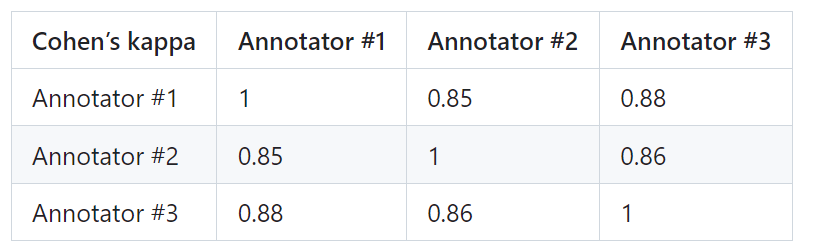
这些被过滤的样本需要额外的知识或难以获取的信息来辅助判断,这使得人类也难以对它们进行准确标注。
经过筛选的测试集包含1000个样本,而原始未经过滤的测试集包含2500个样本。测试集的分布为{0:105,1:422,2:472},其中0表示两个响应质量相似,1表示响应1更好,2表示响应2更好。以人类测试集为基准,PandaLM与gpt-3.5-turbo的性能对比如下:
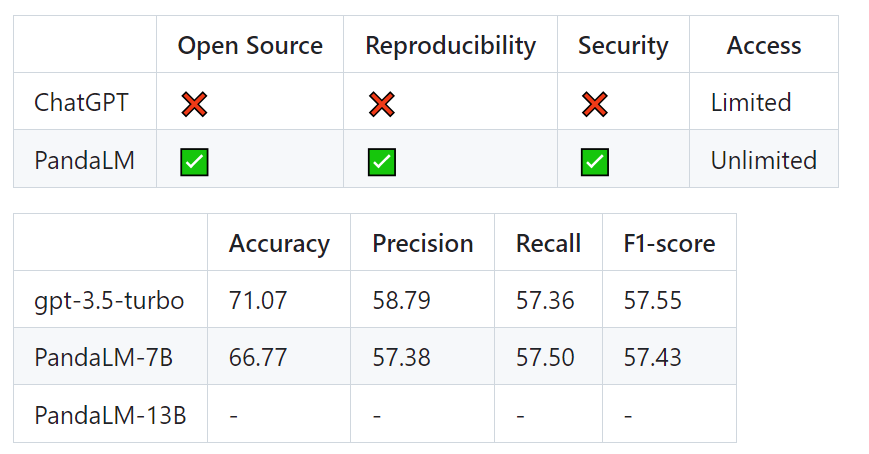
可以看到,PandaLM-7B在准确度上已经达到了gpt-3.5-turbo 94%的水平,而在精确率,召回率,F1分数上,PandaLM-7B已于gpt-3.5-turbo相差无几。
因此,相比于gpt-3.5-turbo而言,可以认为PandaLM-7B已经具备了相当的大模型评估能力。
除了在测试集上的准确度,精确率,召回率,F1分数之外,还提供了5个大小相近且开源的大模型之间比较的结果。
首先使用了相同的训练数据对这个5个模型进行指令微调,接着用人类,gpt-3.5-turbo,PandaLM对这5个模型分别进行两两比较。
下表中第一行第一个元组(72,28,11)表示有72个LLaMA-7B的响应比Bloom-7B的好,有28个LLaMA-7B的响应比Bloom-7B的差,两个模型有11个响应质量相似。
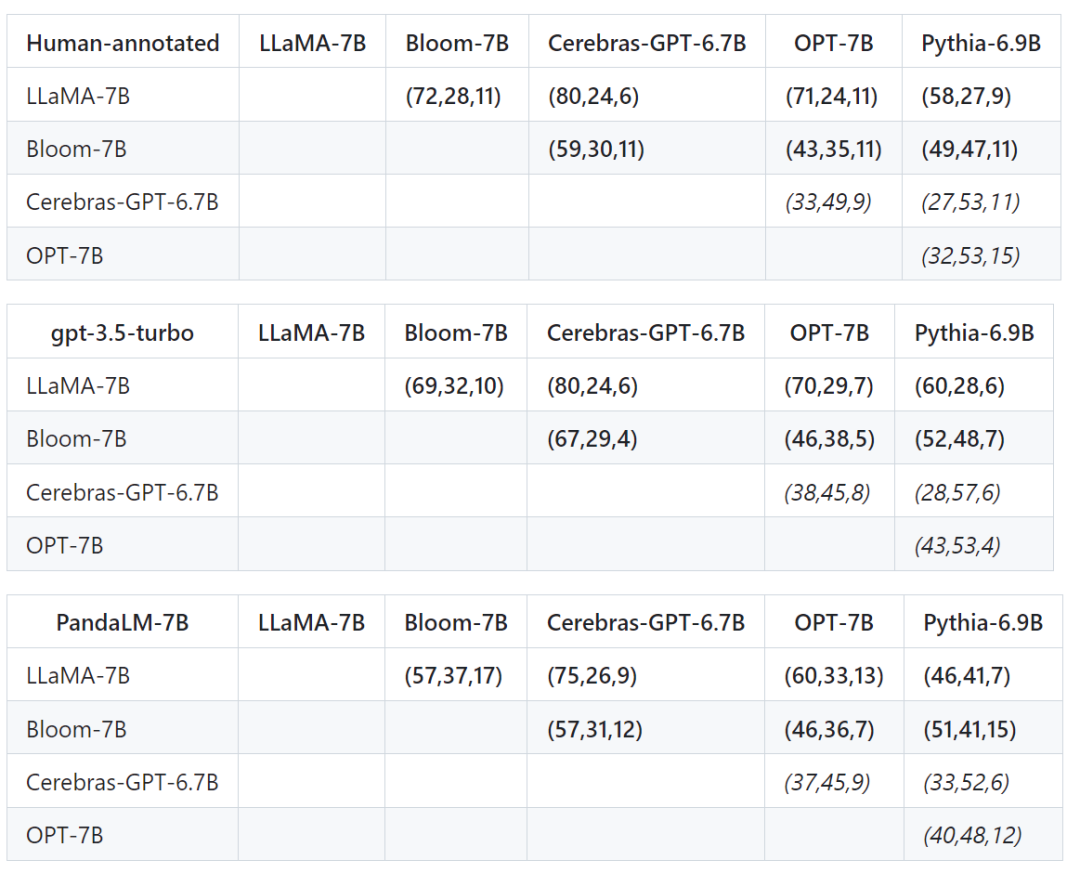
因此在这个例子中,人类认为LLaMA-7B优于Bloom-7B。下面三张表的结果说明人类,gpt-3.5-turbo与PandaLM-7B对于各个模型之间优劣关系的判断完全一致。
总结
PandaLM提供了除人类评估与OpenAI API评估之外的第三条评估大模型的方案,PandaLM不仅评估水平高,而且评估结果可复现,评估流程自动化,保护隐私且开销低。
未来,PandaLM将推动学术界和工业界关于大模型的研究,使得更多人受益于大模型的发展。
以上是北大、西湖大学等开源「裁判大模型」PandaLM:三行代码全自动评估LLM,准确率达ChatGPT的94%的详细内容。更多信息请关注PHP中文网其他相关文章!

 从摩擦到流:AI如何重塑法律工作May 09, 2025 am 11:29 AM
从摩擦到流:AI如何重塑法律工作May 09, 2025 am 11:29 AM法律技术革命正在获得动力,促使法律专业人员积极采用AI解决方案。 对于那些旨在保持竞争力的人来说,被动抵抗不再是可行的选择。 为什么技术采用至关重要? 法律专业人员
 这就是AI对您的看法,对您的了解May 09, 2025 am 11:24 AM
这就是AI对您的看法,对您的了解May 09, 2025 am 11:24 AM许多人认为与AI的互动是匿名的,与人类交流形成了鲜明的对比。 但是,AI在每次聊天期间都会积极介绍用户。 每个单词的每个提示都经过分析和分类。让我们探索AI Revo的这一关键方面
 建立蓬勃发展的AI-Ready企业文化的7个步骤May 09, 2025 am 11:23 AM
建立蓬勃发展的AI-Ready企业文化的7个步骤May 09, 2025 am 11:23 AM成功的人工智能战略,离不开强大的企业文化支撑。正如彼得·德鲁克所言,企业运作依赖于人,人工智能的成功也同样如此。 对于积极拥抱人工智能的组织而言,构建适应AI的企业文化至关重要,它甚至决定着AI战略的成败。 西蒙诺咨询公司(West Monroe)近期发布了构建蓬勃发展的AI友好型企业文化的实用指南,以下是一些关键要点: 1. 明确AI的成功模式: 首先,要对AI如何赋能业务有清晰的愿景。理想的AI运作文化,能够实现人与AI系统之间工作流程的自然融合。AI擅长某些任务,而人类则擅长创造力、判
 Netflix New Scroll,Meta AI的游戏规则改变者,Neuralink价值85亿美元May 09, 2025 am 11:22 AM
Netflix New Scroll,Meta AI的游戏规则改变者,Neuralink价值85亿美元May 09, 2025 am 11:22 AMMeta升级AI助手应用,可穿戴式AI时代来临!这款旨在与ChatGPT竞争的应用,提供文本、语音交互、图像生成和网络搜索等标准AI功能,但现在首次增加了地理位置功能。这意味着Meta AI在回答你的问题时,知道你的位置和正在查看的内容。它利用你的兴趣、位置、个人资料和活动信息,提供最新的情境信息,这在以前是无法实现的。该应用还支持实时翻译,这彻底改变了Ray-Ban眼镜上的AI体验,使其实用性大大提升。 对外国电影征收关税是对媒体和文化的赤裸裸的权力行使。如果实施,这将加速向AI和虚拟制作的
 今天采取这些步骤以保护自己免受AI网络犯罪的侵害May 09, 2025 am 11:19 AM
今天采取这些步骤以保护自己免受AI网络犯罪的侵害May 09, 2025 am 11:19 AM人工智能正在彻底改变网络犯罪领域,这迫使我们必须学习新的防御技巧。网络罪犯日益利用深度伪造和智能网络攻击等强大的人工智能技术进行欺诈和破坏,其规模前所未有。据报道,87%的全球企业在过去一年中都成为人工智能网络犯罪的目标。 那么,我们该如何避免成为这波智能犯罪的受害者呢?让我们探讨如何在个人和组织层面识别风险并采取防护措施。 网络罪犯如何利用人工智能 随着技术的进步,犯罪分子不断寻找新的方法来攻击个人、企业和政府。人工智能的广泛应用可能是最新的一个方面,但其潜在危害是前所未有的。 特别是,人工智
 共生舞蹈:人工和自然感知的循环May 09, 2025 am 11:13 AM
共生舞蹈:人工和自然感知的循环May 09, 2025 am 11:13 AM最好将人工智能(AI)与人类智力(NI)之间的复杂关系理解为反馈循环。 人类创建AI,对人类活动产生的数据进行培训,以增强或复制人类能力。 这个AI
 AI最大的秘密 - 创作者不了解,专家分裂May 09, 2025 am 11:09 AM
AI最大的秘密 - 创作者不了解,专家分裂May 09, 2025 am 11:09 AMAnthropic最近的声明强调了关于尖端AI模型缺乏了解,引发了专家之间的激烈辩论。 这是一个真正的技术危机,还是仅仅是通往更秘密的道路上的临时障碍
 Sarvam AI的Bulbul-V2:印度最佳TTS模型May 09, 2025 am 10:52 AM
Sarvam AI的Bulbul-V2:印度最佳TTS模型May 09, 2025 am 10:52 AM印度是一个多元化的国家,具有丰富的语言,使整个地区的无缝沟通成为持续的挑战。但是,Sarvam的Bulbul-V2正在帮助弥合其高级文本到语音(TTS)T


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

Atom编辑器mac版下载
最流行的的开源编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

WebStorm Mac版
好用的JavaScript开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

