


Meta 公司发布了一个新的开源人工智能模型 ImageBind,该模型能够将多种数据流,包括文本、音频、视觉数据、温度和运动读数等整合在一起。该模型目前只是一个研究项目,还没有直接的消费者或实际应用,但它展示了未来生成式人工智能系统的可能性,这些系统能够创造出沉浸式、多感官的体验。同时,该模型也表明了 Meta 公司在人工智能研究领域的开放态度,而其竞争对手如 OpenAI 和谷歌则变得越来越封闭。
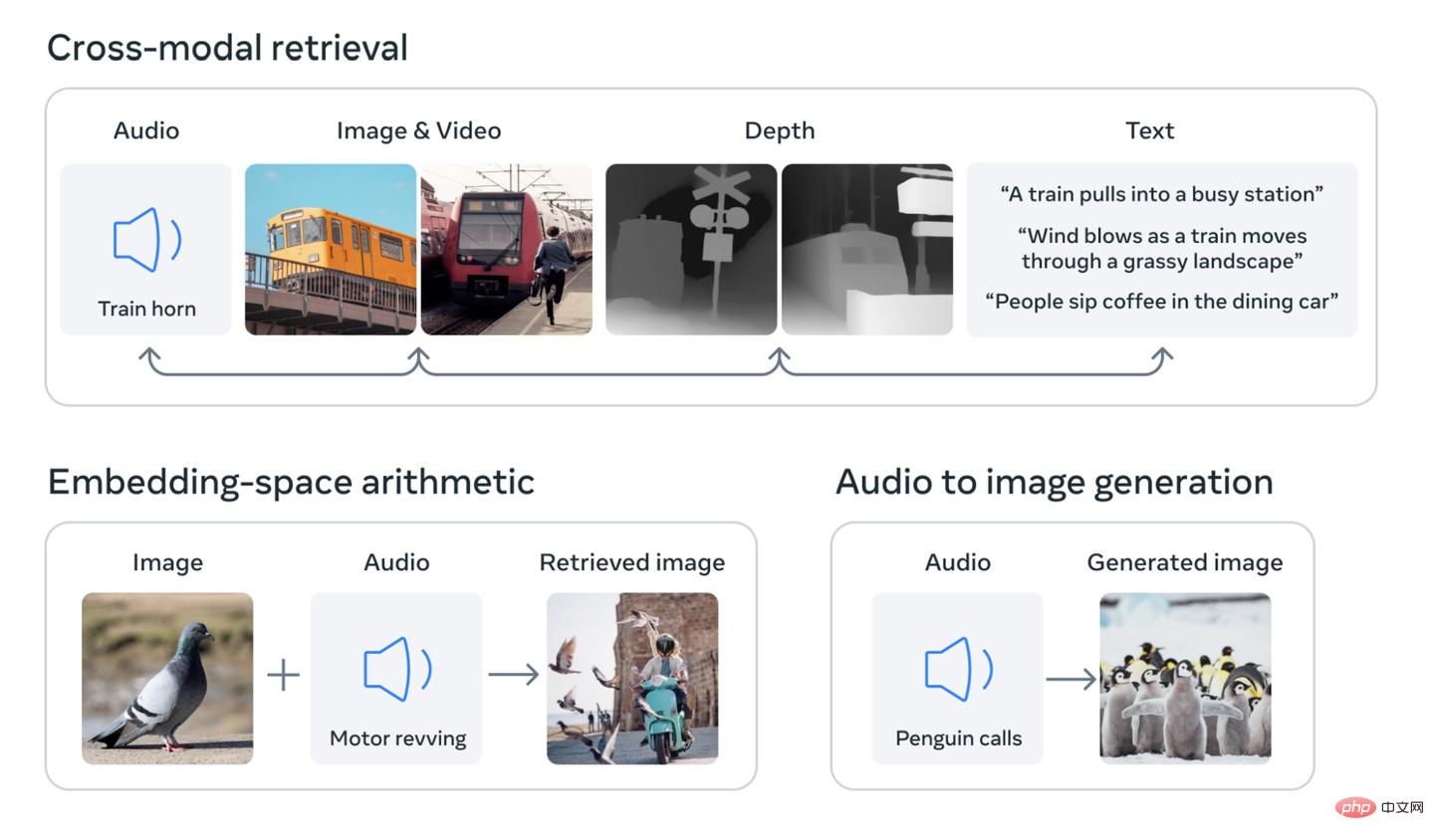
该研究的核心概念是将多种类型的数据整合到一个多维索引(或用人工智能术语来说,“嵌入空间”)中。这个概念可能有些抽象,但它正是近期生成式人工智能热潮的基础。例如,人工智能图像生成器,如 DALL-E、Stable Diffusion 和 Midjourney 等,都依赖于在训练阶段将文本和图像联系在一起的系统。它们在寻找视觉数据中的模式的同时,将这些信息与图像的描述相连。这就是为什么这些系统能够根据用户的文本输入生成图片。同样的道理也适用于许多能够以同样方式生成视频或音频的人工智能工具。
Meta 公司称,其模型 ImageBind 是第一个将六种类型的数据整合到一个嵌入空间中的模型。这六种类型的数据包括:视觉(包括图像和视频);热力(红外图像);文本;音频;深度信息;以及最有趣的一种 —— 由惯性测量单元(IMU)产生的运动读数。(IMU 存在于手机和智能手表中,用于执行各种任务,从手机从横屏切换到竖屏,到区分不同类型的运动。)
未来的人工智能系统将能够像当前针对文本输入的系统一样,交叉引用这些数据。例如,想象一下一个未来的虚拟现实设备,它不仅能够生成音频和视觉输入,还能够生成你所处的环境和物理站台的运动。你可以要求它模拟一次漫长的海上旅行,它不仅会让你置身于一艘船上,并且有海浪的声音作为背景,还会让你感受到甲板在脚下摇晃和海风吹拂。
Meta 公司在博客文章中指出,未来的模型还可以添加其他感官输入流,包括“触觉、语音、气味和大脑功能磁共振成像信号”。该公司还声称,这项研究“让机器更接近于人类同时、全面、直接地从多种不同的信息形式中学习的能力。”
当然,这很多都是基于预测的,而且很可能这项研究的直接应用会非常有限。例如,去年,Meta 公司展示了一个人工智能模型,能够根据文本描述生成短而模糊的视频。像 ImageBind 这样的研究显示了未来版本的系统如何能够整合其他数据流,例如生成与视频输出匹配的音频。
对于行业观察者来说,这项研究也很有趣,因为IT之家注意到 Meta 公司是开源了底层模型的,这在人工智能领域是一个越来越受到关注的做法。
以上是Meta 开源多感官人工智能模型,整合文本、音频、视觉等六类数据的详细内容。更多信息请关注PHP中文网其他相关文章!


 软AI的兴起及其对当今企业的意义Apr 15, 2025 am 11:36 AM
软AI的兴起及其对当今企业的意义Apr 15, 2025 am 11:36 AM软AI(被定义为AI系统,旨在使用近似推理,模式识别和灵活的决策执行特定的狭窄任务 - 试图通过拥抱歧义来模仿类似人类的思维。 但是这对业务意味着什么
 为AI前沿的不断发展的安全框架Apr 15, 2025 am 11:34 AM
为AI前沿的不断发展的安全框架Apr 15, 2025 am 11:34 AM答案很明确 - 只是云计算需要向云本地安全工具转变,AI需要专门为AI独特需求而设计的新型安全解决方案。 云计算和安全课程的兴起 在
 生成AI的3种方法放大了企业家:当心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3种方法放大了企业家:当心平均值!Apr 15, 2025 am 11:33 AM企业家,并使用AI和Generative AI来改善其业务。同时,重要的是要记住生成的AI,就像所有技术一样,都是一个放大器 - 使得伟大和平庸,更糟。严格的2024研究O
 Andrew Ng的新简短课程Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程Apr 15, 2025 am 11:32 AM解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 大语言模型(LLM)中的幻觉是不可避免的吗?Apr 15, 2025 am 11:31 AM
大语言模型(LLM)中的幻觉是不可避免的吗?Apr 15, 2025 am 11:31 AM大型语言模型(LLM)和不可避免的幻觉问题 您可能使用了诸如Chatgpt,Claude和Gemini之类的AI模型。 这些都是大型语言模型(LLM)的示例,在大规模文本数据集上训练的功能强大的AI系统
 60%的问题 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的问题 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根据行业和搜索类型,AI概述可能导致有机交通下降15-64%。这种根本性的变化导致营销人员重新考虑其在数字可见性方面的整个策略。 新的
 麻省理工学院媒体实验室将人类蓬勃发展成为AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工学院媒体实验室将人类蓬勃发展成为AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大学(Elon University)想象的数字未来中心的最新报告对近300名全球技术专家进行了调查。由此产生的报告“ 2035年成为人类”,得出的结论是,大多数人担心AI系统加深的采用


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

Atom编辑器mac版下载
最流行的的开源编辑器

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

