



OpenRL 是由第四范式强化学习团队开发的基于 PyTorch 的强化学习研究框架,支持单智能体、多智能体、自然语言等多种任务的训练。OpenRL 基于 PyTorch 进行开发,目标是为强化学习研究社区提供一个简单易用、灵活高效、可持续扩展的平台。目前,OpenRL 支持的特性包括:
- 简单易用且支持单智能体、多智能体训练的通用接口
- 支持自然语言任务(如对话任务)的强化学习训练
- 支持从 Hugging Face 上导入模型和数据
- 支持 LSTM,GRU,Transformer 等模型
- 支持多种训练加速,例如:自动混合精度训练,半精度策略网络收集数据等
- 支持用户自定义训练模型、奖励模型、训练数据以及环境
- 支持 gymnasium 环境
- 支持字典观测空间
- 支持 wandb,tensorboardX 等主流训练可视化工具
- 支持环境的串行和并行训练,同时保证两种模式下的训练效果一致
- 中英文文档
- 提供单元测试和代码覆盖测试
- 符合 Black Code Style 和类型检查
目前,OpenRL 已经在 GitHub 开源:
项目地址:https://github.com/OpenRL-Lab/openrl
OpenRL 初体验
OpenRL 目前可以通过 pip 进行安装:
<code>pip install openrl</code>
也可以通过 conda 安装:
<code>conda install -c openrl openrl</code>
OpenRL 为强化学习入门用户提供了简单易用的接口, 下面是一个使用 PPO 算法训练 CartPole 环境的例子:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>
使用 OpenRL 训练智能体只需要简单的四步:创建环境 => 初始化模型 => 初始化智能体 => 开始训练!
在普通笔记本电脑上执行以上代码,只需要几秒钟,便可以完成该智能体的训练:
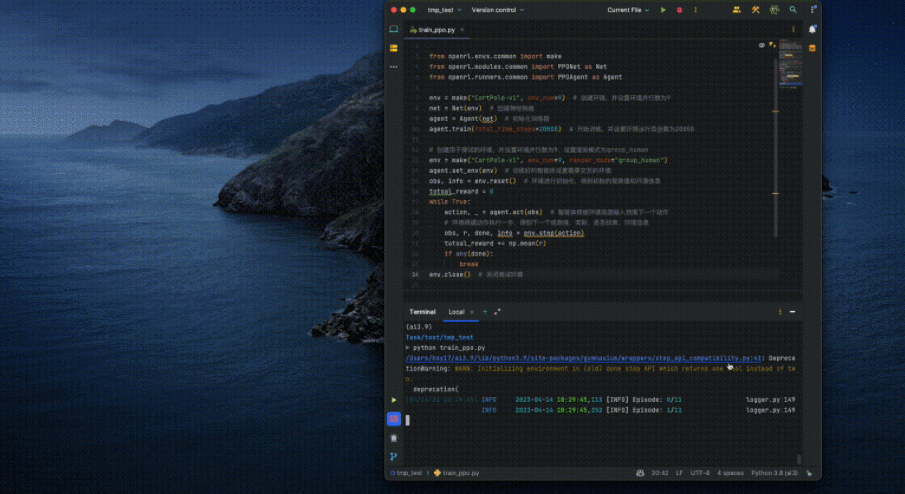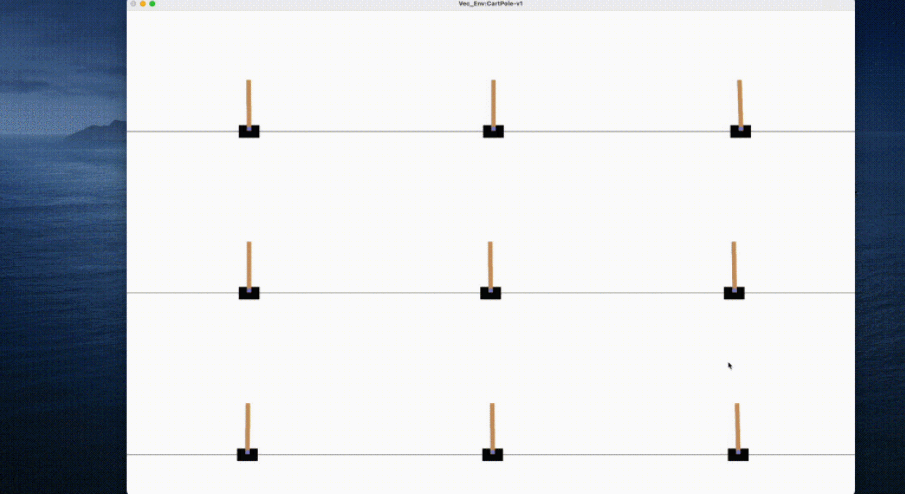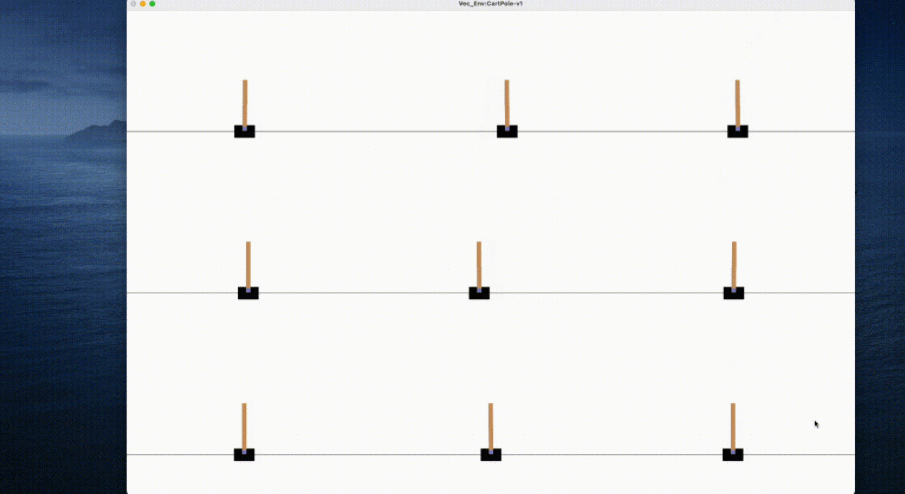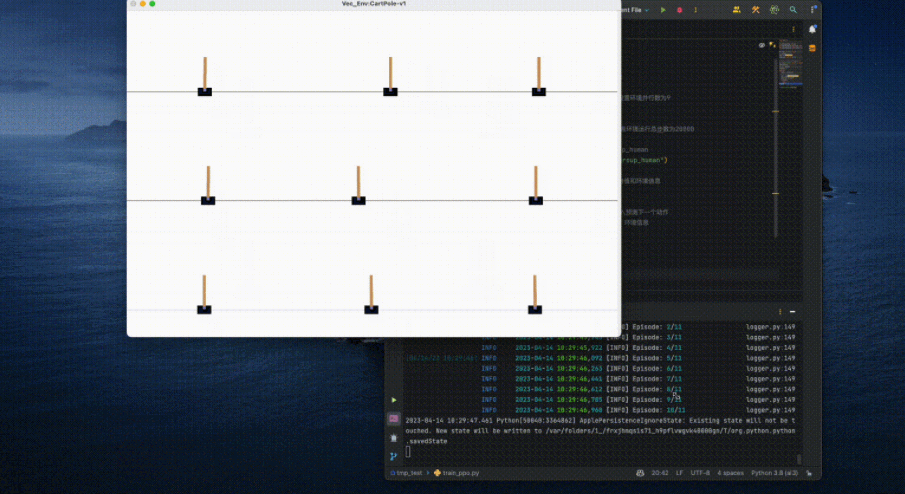
此外,对于多智能体、自然语言等任务的训练,OpenRL 也提供了同样简单易用的接口。例如,对于多智能体任务中的 MPE 环境,OpenRL 也只需要调用几行代码便可以完成训练:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>
下图展示了通过 OpenRL 训练前后智能体的表现:
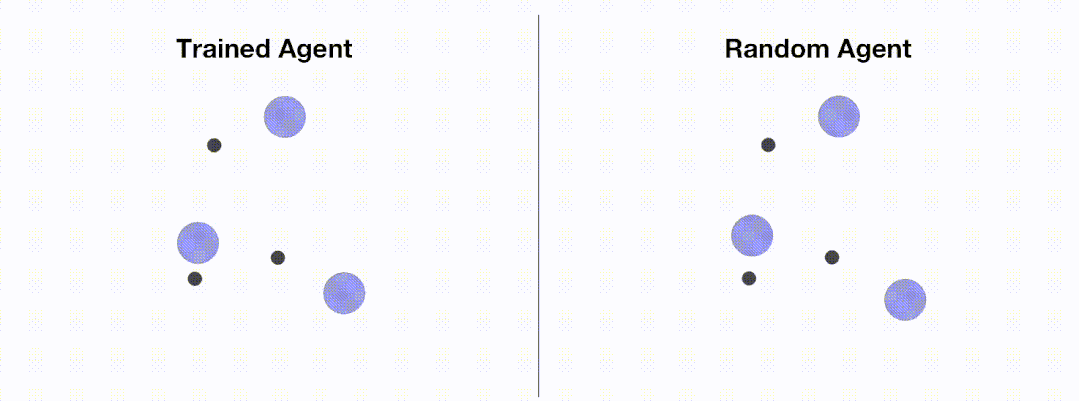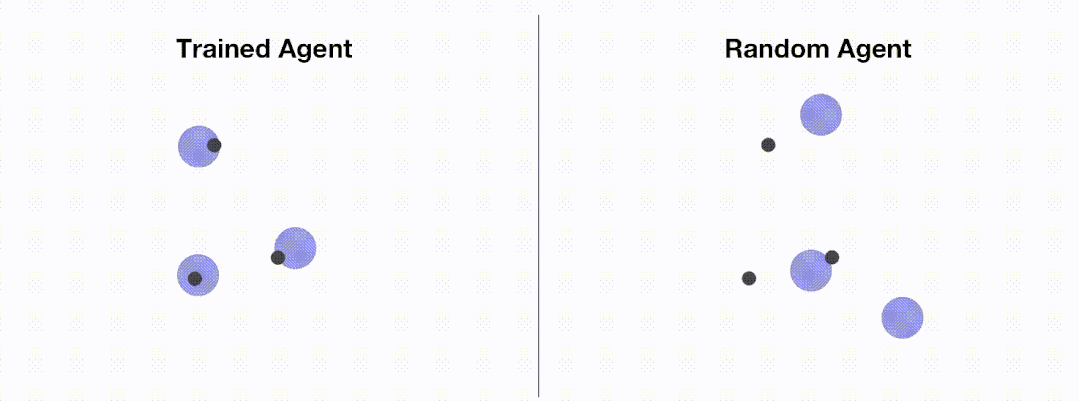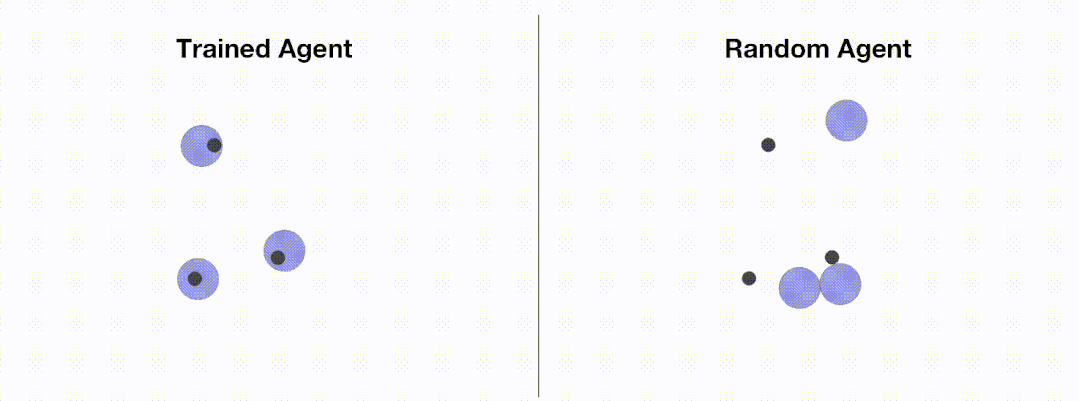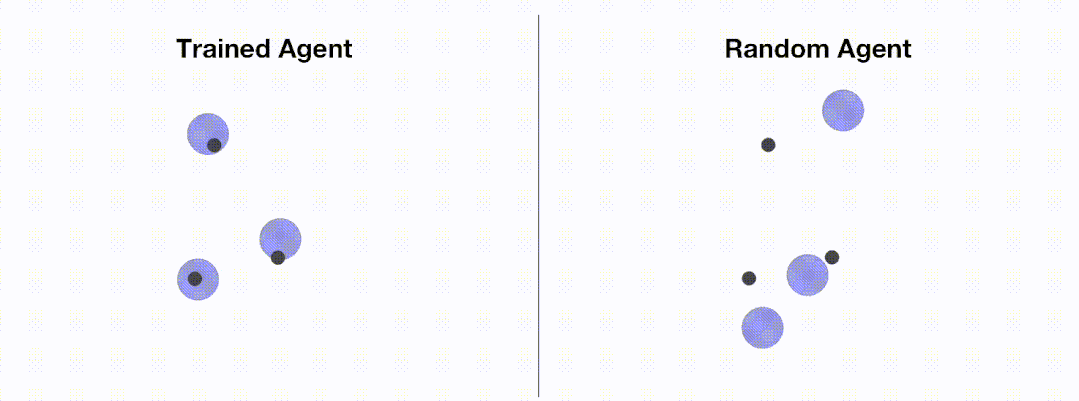
加载配置文件
此外,OpenRL 还同时支持从命令行和配置文件对训练参数进行修改。比如,用户可以通过执行 python train_ppo.py --lr 5e-4 来快速修改训练时候的学习率。
当配置参数非常多的时候,OpenRL 还支持用户编写自己的配置文件来修改训练参数。例如,用户可以自行创建以下配置文件 (mpe_ppo.yaml),并修改其中的参数:
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
最后,用户只需要在执行程序的时候指定该配置文件即可:
<code>python train_ppo.py --config mpe_ppo.yaml</code>
训练与测试可视化
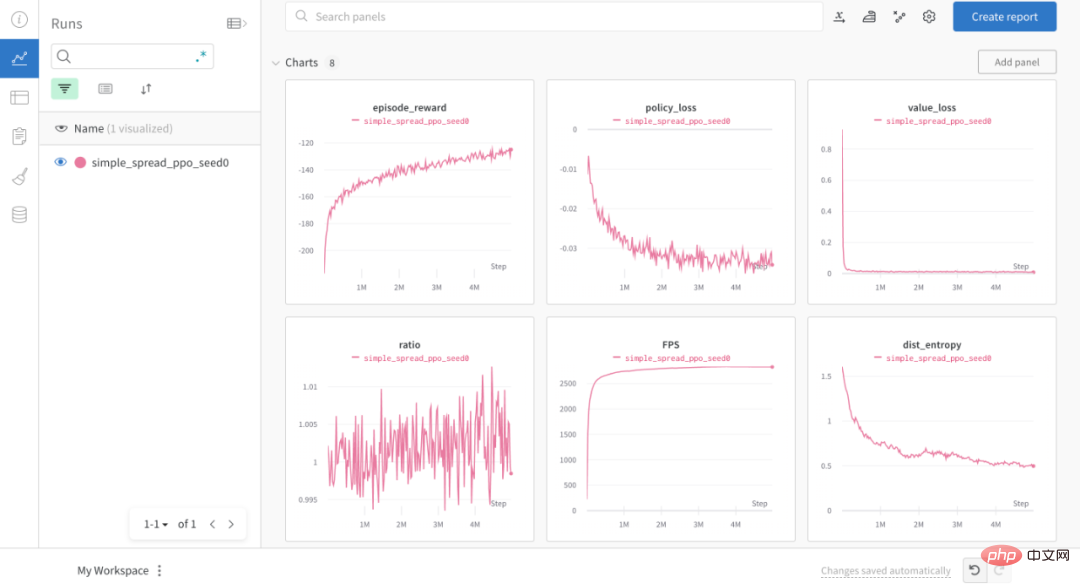
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:
OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化:
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code>
此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
<code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
智能体的保存和加载
OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作:
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>
执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>
上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>
然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>
自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>
OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>
最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>
自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
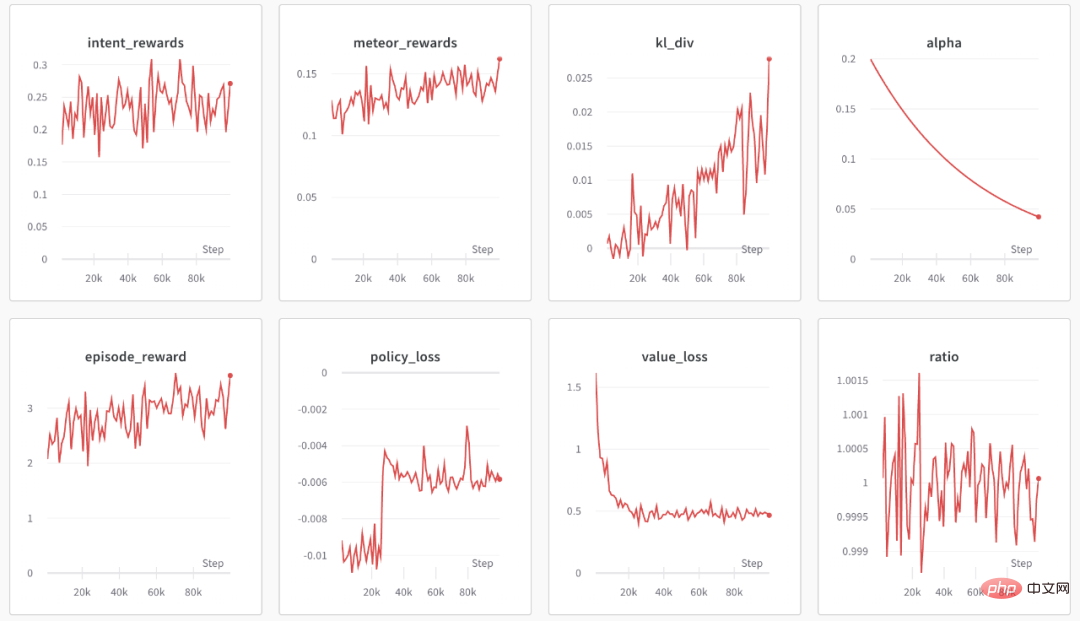
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>
最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
对比评测
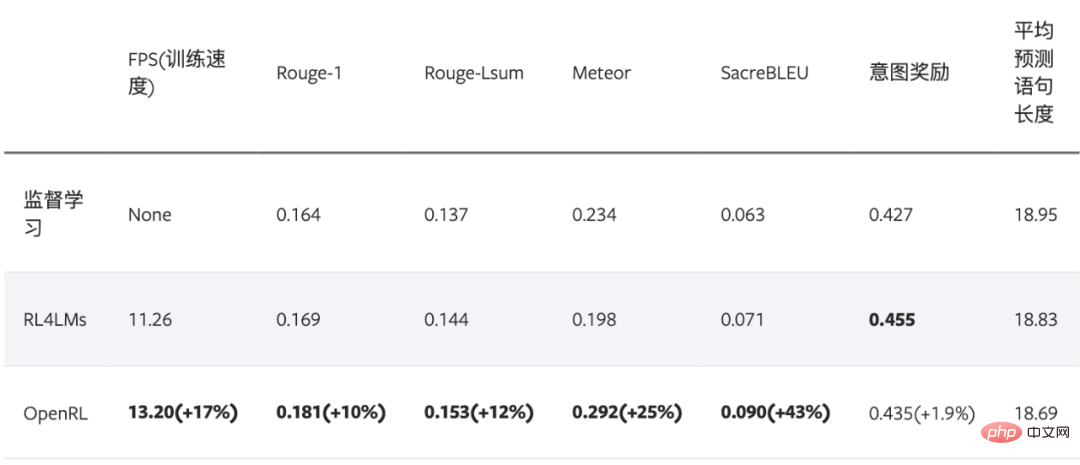
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>
执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
- OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
- OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail:https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- MAPPO: https://github.com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-engine:https://github.com/opendilab/DI-engine/
- Tianshou: https://github.com/thu-ml/tianshou
- RL4LMs: https://github.com/allenai/RL4LMs
未来工作
目前,OpenRL 还处于持续开发和建设阶段,未来 OpenRL 将会开源更多功能:
- 支持智能体自博弈训练
- 加入离线强化学习、模范学习、逆强化学习算法
- 加入更多强化学习环境和算法
- 集成 Deepspeed 等加速框架
- 支持多机分布式训练
OpenRL Lab 团队
OpenRL框架是由OpenRL Lab团队开发,该团队是第四范式公司旗下的强化学习研究团队。第四范式长期致力于强化学习的研发和工业应用。为了促进强化学习的产学研一体化,第四范式成立了OpenRL Lab研究团队,目标是先进技术开源和人工智能前沿探索。成立不到一年,OpenRL Lab团队已经在AAMAS发表过三篇论文,参加谷歌足球游戏 11 vs 11比赛并获得第三的成绩。团队提出的TiZero智能体,实现了首个从零开始,通过课程学习、分布式强化学习、自博弈等技术完成谷歌足球全场游戏智能体的训练:
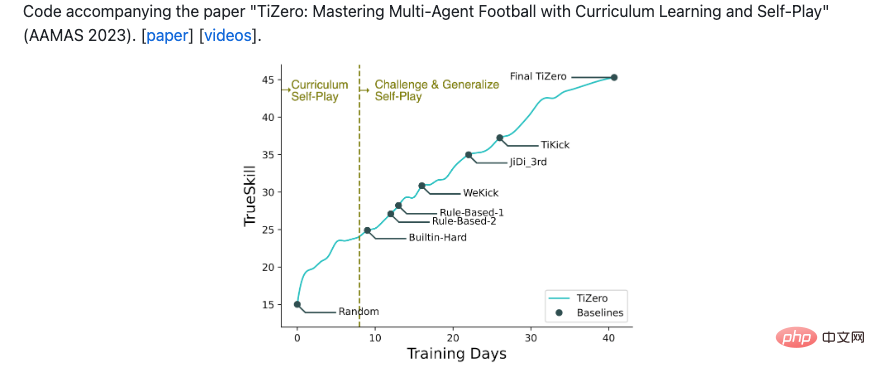
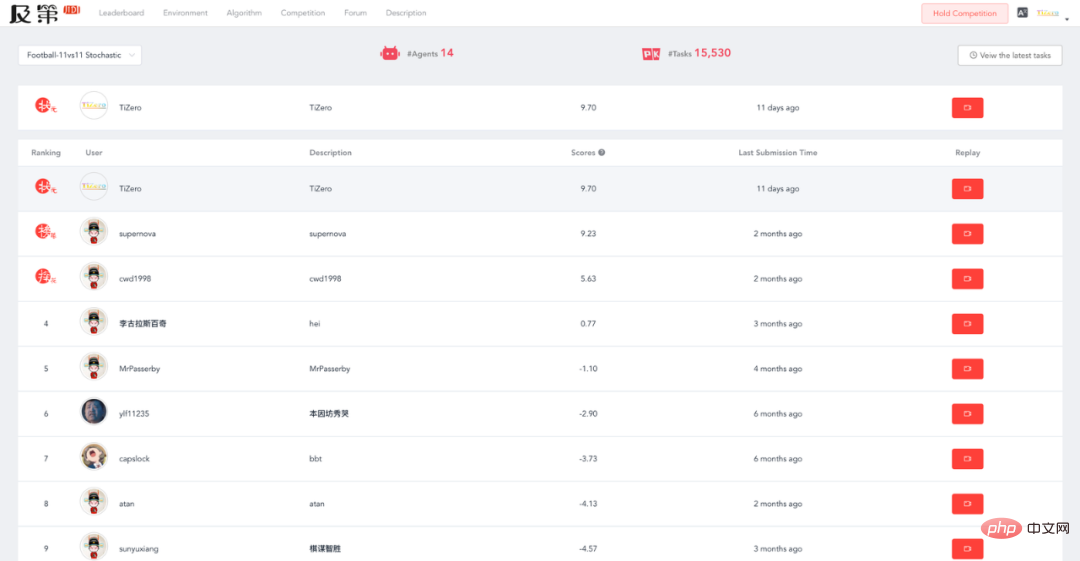
截止 2022 年 10 月 28 日,Tizero 在及第评测平台上排名第一:
以上是训练提速17%,第四范式开源强化学习研究框架,支持单、多智能体训练的详细内容。更多信息请关注PHP中文网其他相关文章!

 从摩擦到流:AI如何重塑法律工作May 09, 2025 am 11:29 AM
从摩擦到流:AI如何重塑法律工作May 09, 2025 am 11:29 AM法律技术革命正在获得动力,促使法律专业人员积极采用AI解决方案。 对于那些旨在保持竞争力的人来说,被动抵抗不再是可行的选择。 为什么技术采用至关重要? 法律专业人员
 这就是AI对您的看法,对您的了解May 09, 2025 am 11:24 AM
这就是AI对您的看法,对您的了解May 09, 2025 am 11:24 AM许多人认为与AI的互动是匿名的,与人类交流形成了鲜明的对比。 但是,AI在每次聊天期间都会积极介绍用户。 每个单词的每个提示都经过分析和分类。让我们探索AI Revo的这一关键方面
 建立蓬勃发展的AI-Ready企业文化的7个步骤May 09, 2025 am 11:23 AM
建立蓬勃发展的AI-Ready企业文化的7个步骤May 09, 2025 am 11:23 AM成功的人工智能战略,离不开强大的企业文化支撑。正如彼得·德鲁克所言,企业运作依赖于人,人工智能的成功也同样如此。 对于积极拥抱人工智能的组织而言,构建适应AI的企业文化至关重要,它甚至决定着AI战略的成败。 西蒙诺咨询公司(West Monroe)近期发布了构建蓬勃发展的AI友好型企业文化的实用指南,以下是一些关键要点: 1. 明确AI的成功模式: 首先,要对AI如何赋能业务有清晰的愿景。理想的AI运作文化,能够实现人与AI系统之间工作流程的自然融合。AI擅长某些任务,而人类则擅长创造力、判
 Netflix New Scroll,Meta AI的游戏规则改变者,Neuralink价值85亿美元May 09, 2025 am 11:22 AM
Netflix New Scroll,Meta AI的游戏规则改变者,Neuralink价值85亿美元May 09, 2025 am 11:22 AMMeta升级AI助手应用,可穿戴式AI时代来临!这款旨在与ChatGPT竞争的应用,提供文本、语音交互、图像生成和网络搜索等标准AI功能,但现在首次增加了地理位置功能。这意味着Meta AI在回答你的问题时,知道你的位置和正在查看的内容。它利用你的兴趣、位置、个人资料和活动信息,提供最新的情境信息,这在以前是无法实现的。该应用还支持实时翻译,这彻底改变了Ray-Ban眼镜上的AI体验,使其实用性大大提升。 对外国电影征收关税是对媒体和文化的赤裸裸的权力行使。如果实施,这将加速向AI和虚拟制作的
 今天采取这些步骤以保护自己免受AI网络犯罪的侵害May 09, 2025 am 11:19 AM
今天采取这些步骤以保护自己免受AI网络犯罪的侵害May 09, 2025 am 11:19 AM人工智能正在彻底改变网络犯罪领域,这迫使我们必须学习新的防御技巧。网络罪犯日益利用深度伪造和智能网络攻击等强大的人工智能技术进行欺诈和破坏,其规模前所未有。据报道,87%的全球企业在过去一年中都成为人工智能网络犯罪的目标。 那么,我们该如何避免成为这波智能犯罪的受害者呢?让我们探讨如何在个人和组织层面识别风险并采取防护措施。 网络罪犯如何利用人工智能 随着技术的进步,犯罪分子不断寻找新的方法来攻击个人、企业和政府。人工智能的广泛应用可能是最新的一个方面,但其潜在危害是前所未有的。 特别是,人工智
 共生舞蹈:人工和自然感知的循环May 09, 2025 am 11:13 AM
共生舞蹈:人工和自然感知的循环May 09, 2025 am 11:13 AM最好将人工智能(AI)与人类智力(NI)之间的复杂关系理解为反馈循环。 人类创建AI,对人类活动产生的数据进行培训,以增强或复制人类能力。 这个AI
 AI最大的秘密 - 创作者不了解,专家分裂May 09, 2025 am 11:09 AM
AI最大的秘密 - 创作者不了解,专家分裂May 09, 2025 am 11:09 AMAnthropic最近的声明强调了关于尖端AI模型缺乏了解,引发了专家之间的激烈辩论。 这是一个真正的技术危机,还是仅仅是通往更秘密的道路上的临时障碍
 Sarvam AI的Bulbul-V2:印度最佳TTS模型May 09, 2025 am 10:52 AM
Sarvam AI的Bulbul-V2:印度最佳TTS模型May 09, 2025 am 10:52 AM印度是一个多元化的国家,具有丰富的语言,使整个地区的无缝沟通成为持续的挑战。但是,Sarvam的Bulbul-V2正在帮助弥合其高级文本到语音(TTS)T


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

记事本++7.3.1
好用且免费的代码编辑器

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

