



神经网络之父Geoffrey Hinton离职谷歌,直言对毕生工作感到后悔。
现在看来,他对AI的害怕,不是没有道理。
因为,一种类ChatGPT模型已经学会了读心术,准确率高达82%!
来自德克萨斯大学奥斯汀分校的研究者开发了一种基于GPT的语言解码器。
它能通过非侵入性的MRI/fMRI收集大脑活动信息,并将思维转化为语言文字。

论文地址:https://www.nature.com/articles/s41593-023-01304-9
令人震惊的是,当你在看皮克斯无声电影时,大脑解码器都能读出你的想法。
这个类ChatGPT模型,以前所未有的准确率解码人类思想,不仅开启了大脑成像的新潜力,并引发了人们对隐私的担忧。
研究一出,在网上掀起了轩然大波。网友惊呼,太恐怖了。

我们离真正的思想警察更近了一步。

GPT读心,准确率高达82%
那么,这个恐怖的大脑解码器是怎么实现「读心」的?
这里,不得不提功能性磁共振成像(fMRI)技术,它能通过监测大脑皮层不同部位的血氧水平得到大脑的动态变化图像。
因此只需分析功能磁共振成像数据,就可以以非侵入性的方式,将参与者大脑中所想的故事甚至图像用语言描述出来。
脑部活动就像是加密过的信号,而经过预训练的大型语言模型提供了破译的途径。
在此,研究人员基于GPT-1训练了一个神经网络语言模型。
Alexander Huth让3名受试者,连续听16个小时的语音播客,并收集他们聆听时的fMRI数据。
这些语言播客主要是一些脱口秀和TED的演讲,比如纽约时报的Modern Love。
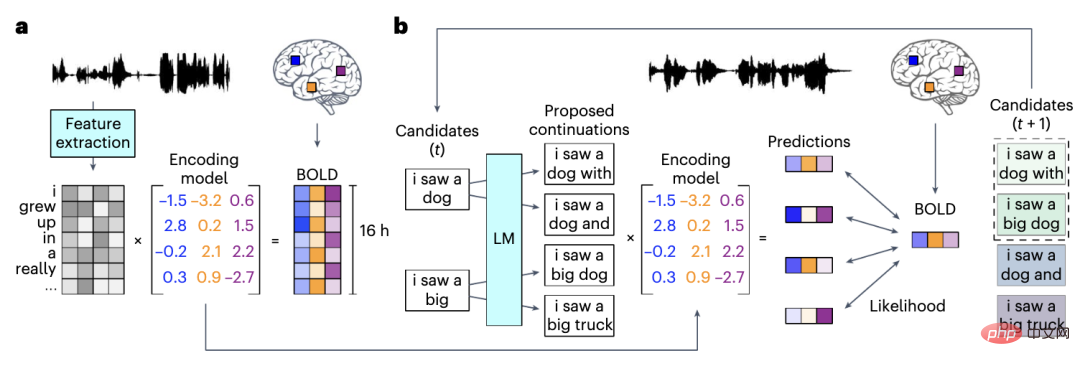
接下来研究人员借助大型语言模型将参与者的fMRI数据集翻译成单词和短语。
随后测试参与者听新录音的脑部活动,通过观察翻译文本与参与者听到的文本的接近程度,就可以知道解码器到底准不准。
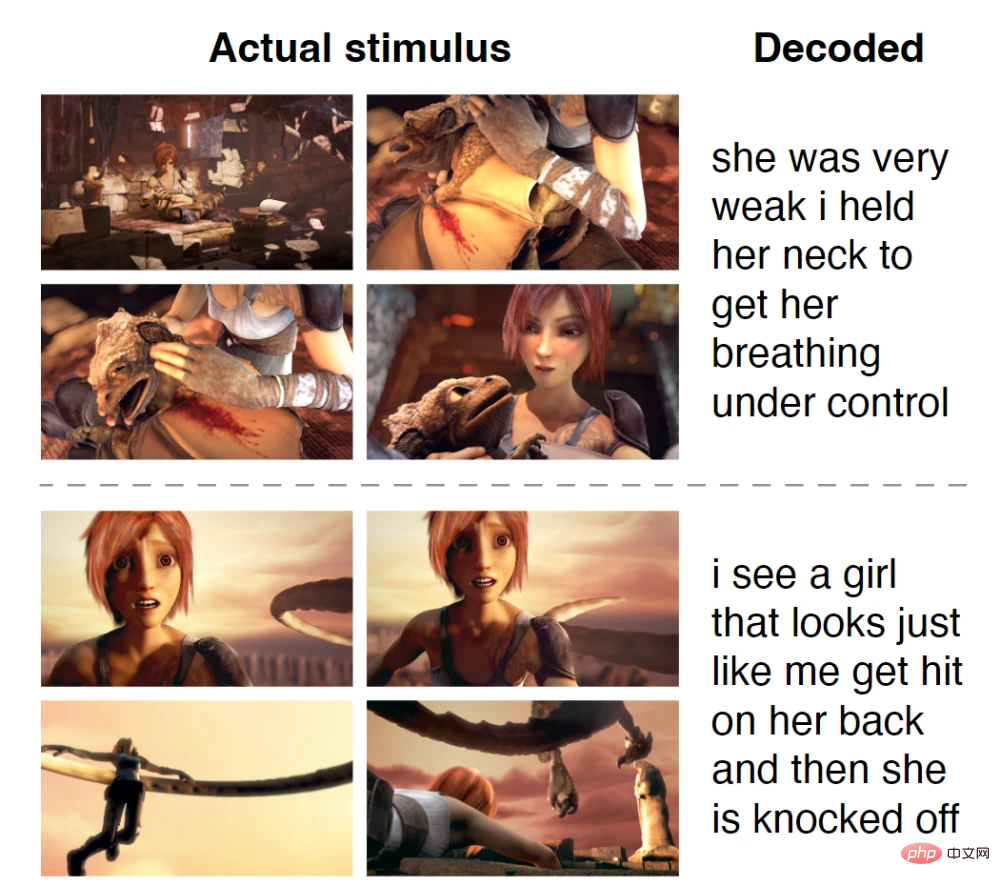
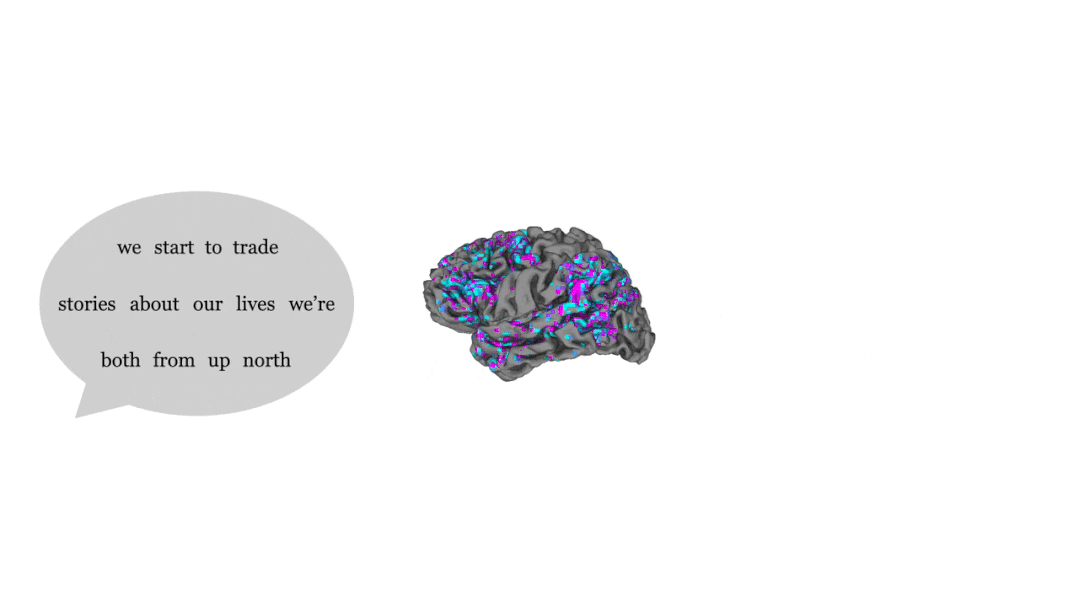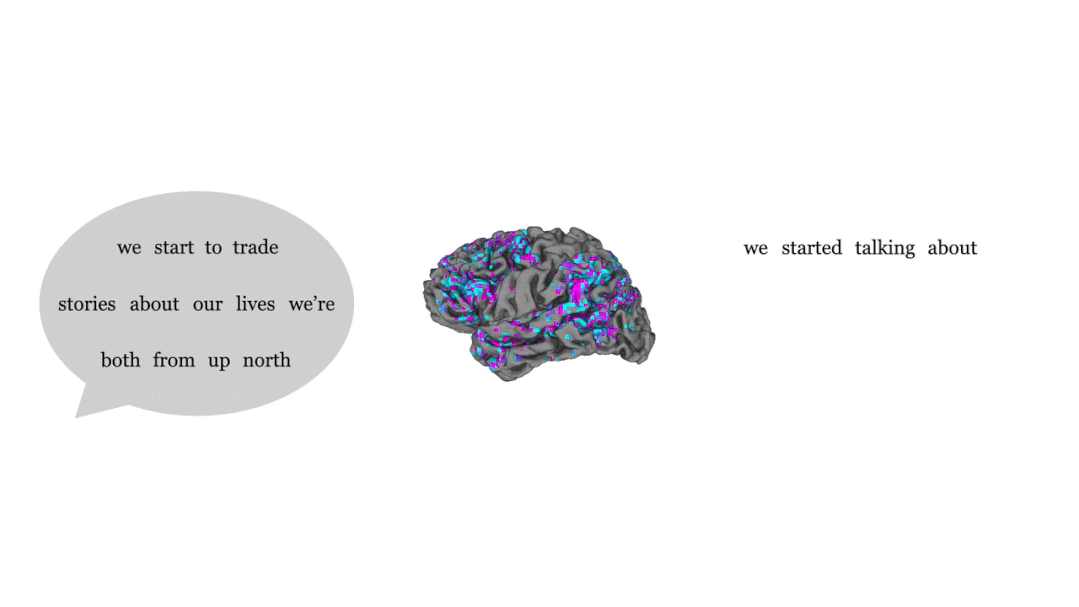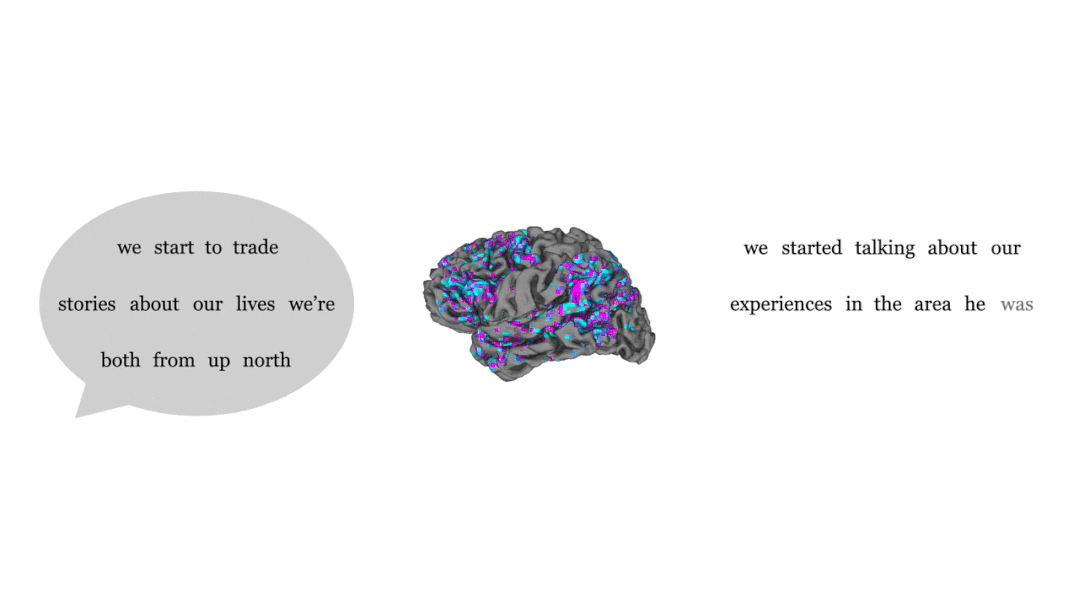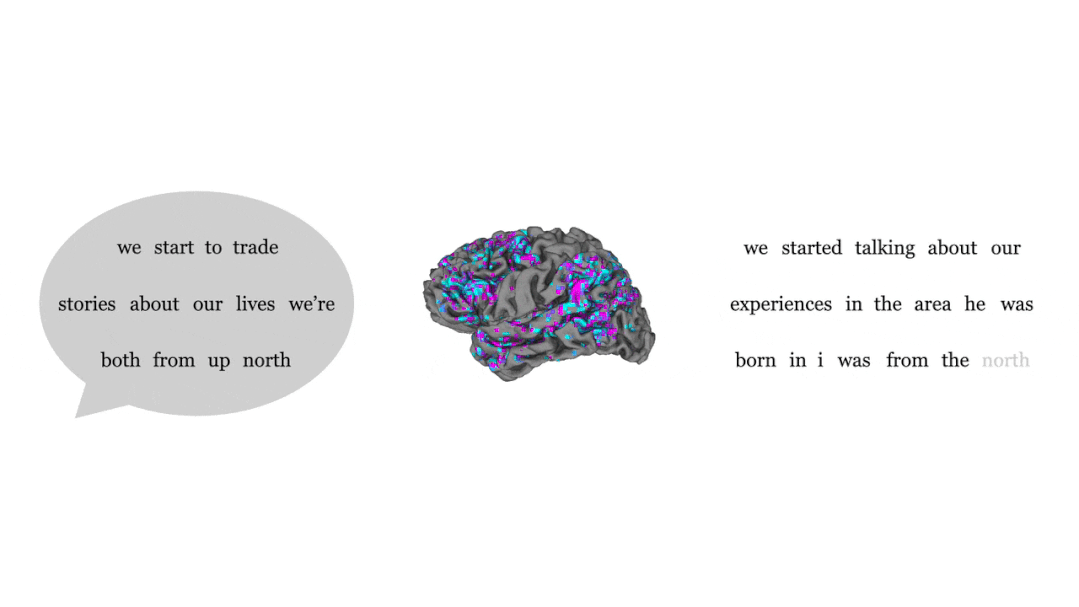
通过对比人听到的语句(左)和解码器根据大脑活动输出的语句(右)可以发现,蓝色和紫色部分占绝大多数,蓝色代表完全一致,紫色代表大意准确。

虽然几乎每个单词都不是一一对应,但是整个句子的意义被保留了下来,也就是解码器在给大脑信号「释义」。
比如最后一句,受试者听到的是「我还没拿到驾照」,而解码器给出的回答是「她还没准备好开始学车」。
正如研究者所称,人工智能无法将思想转化确切词汇或句子,而是改写。
随后,受试者被要求安静地在脑中构思一个故事,然后大声复述出来,来看看复述版本和解码器翻译版的差别。

可以看到,意义的重合度还是很高的。
最后,受试者观看了一段动画电影,这段电影没有任何声音,但通过分析他们的大脑活动,解码器可以了解他们正在观看的内容的概要。
实验结果发现,GPT模型从感知语音、想象语音、甚至无声视频中生成可理解的单词序列,其准确性令人惊叹。
具体准确率如下:
感知语音(受试者听录音) : 72-82%
想象语言(受试者在内心讲述一个一分钟的故事) : 41-74%
无声电影(受试者观看皮克斯无声电影剪辑): 21-45%
麻省理工大学的神经科学家Greta Tuckute说,语言感知是一个外部驱动的过程,而想象力是一个活跃的内部过程,通过大型语言模型可以将内在的脑部活动展示在我们眼前。
我们现在是否能从大脑读取信息?是的,某种程度上可以。

有朝一日,这个解码器可能会被用来帮助那些丧失说话能力,或者调查心理健康状况的人们。
精神隐私,也没了
然而,解码人类思想的前景还引发了关于精神隐私的问题。

Huth博士指出,这种语言解码方法存在一定局限性。
因为,fMRI扫描仪体积庞大且价格昂贵,此外训练模型是一个漫长而乏味的过程,也就是必须对每个人都进行单独的训练。
对此,研究小组进行了一项额外的研究,使用接受过其他受试者数据训练的解码器,来解码新受试者的想法。
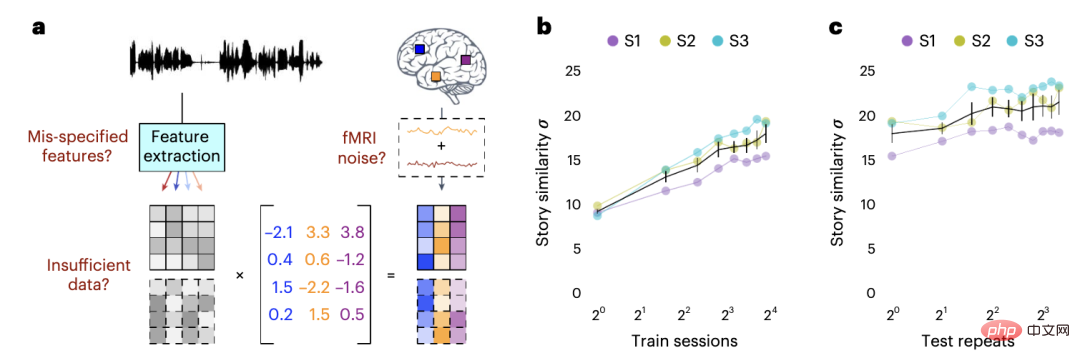
研究发现,对使用不同受试者数据进行训练的解码器,其表现几乎不怎么样。
简言之,只有使用受试者自己大脑记录的数据,来训练AI模型,其准确率才会非常高。
这表明每个大脑都有独特的表示意义的方式。

另外,参与者还能够屏蔽他们内心的独白,通过思考其他事情来摆脱解码器。比如数到七、列出农场动物,或叙述一个完全不同的故事。
也就是说,这一解码器要想要获得准确的结果,必须需要志愿者的配合。
然而,科学家们承认,未来的解码器可能会克服这些限制,未来可能会被滥用,就像测谎仪一样。
研究人员总结道,一个美丽的新世界正在到来,由于这些和其他不可预见的原因。
提高人们对大脑解码技术风险的认识并制定保护每个人精神隐私的政策是至关重要的。
在《黑镜》中有这样一幕,一位保险代理人使用一台机器(配备了视觉监控器和大脑传感器)读取人们的记忆,来调查一起意外死亡事件。

然而,这一未来或许就是现在。
德克萨斯大学研究者这一突破,直接推动了神经科学、通信和人机交互等领域潜在应用。

尽管「大脑解码器」还在研究中早期阶段,但有朝一日它可能被用于记录人们的梦境,并为脑机接口进一步发展提供动力。
负责这项研究的神经科学家Alexander Huth博士称,我们对这项工作的原理感到震惊。我为此研究了15年... ... 所以当它最终成功时,我感到非常震惊和兴奋。
看来,我们离《X战警》中X教授查尔斯大脑扫描技术又近了一步。

网友:AI通灵者
看过这项研究后,让许多人瞬间「炸脑」。有网友称,
人工智能不仅可以比我们快一万倍地交流,而且现在甚至可以读取我们的思想。在 「这太酷了」和 「等等,我们是不是要被淘汰了」之间只有一线之隔。
AI现在可以像通灵者一样读心。「Keep in mind」,这只是1.0版本。在未来,我们的想法将不再是隐私。世界经济论坛的第四次工业革命非常清晰地阐述了这一点。
这是首次以非侵入性方式从人类大脑活动中重建连续的语言!

对于这项研究,生物伦理学家 Rodriguez-Arias Vailhen称,目前为止,人类大脑一直是我们隐私的守护者。
「这一发现可能是在未来牺牲这种自由的第一步。」

以上是AI通灵模型成功解码大脑信息,准确率达到82%的详细内容。更多信息请关注PHP中文网其他相关文章!

 用Ollama -Analytics Vidhya简化本地LLM部署Apr 19, 2025 am 11:01 AM
用Ollama -Analytics Vidhya简化本地LLM部署Apr 19, 2025 am 11:01 AM利用Ollama本地开源LLMS的力量:综合指南 运行大型语言模型(LLMS)本地提供无与伦比的控制和透明度,但是设置环境可能令人生畏。 Ollama简化了这个过程
 如何使用Monsterapi微调大语言模型Apr 19, 2025 am 10:49 AM
如何使用Monsterapi微调大语言模型Apr 19, 2025 am 10:49 AM利用微调LLM的功能与Monsterapi:综合指南 想象一个虚拟助手完美理解并预测您的需求。 由于大型语言模型(LLMS)的进步,这已成为现实。 但是,
 5统计测试每个数据科学家都应该知道-Analytics VidhyaApr 19, 2025 am 10:27 AM
5统计测试每个数据科学家都应该知道-Analytics VidhyaApr 19, 2025 am 10:27 AM数据科学的基本统计测试:综合指南 从数据中解锁有价值的见解至关重要。 掌握统计测试对于实现这一目标至关重要。这些测试使数据科学家能够严格瓦尔
 如何使用Florence -2 -Analytics Vidhya执行计算机视觉任务Apr 19, 2025 am 10:21 AM
如何使用Florence -2 -Analytics Vidhya执行计算机视觉任务Apr 19, 2025 am 10:21 AM介绍 原始变压器的引入为当前的大语言模型铺平了道路。同样,在引入变压器模型之后,引入了视觉变压器(VIT)。喜欢
 使用Langchain Text Splitters -Analytics Vidhya拆分数据的7种方法Apr 19, 2025 am 10:11 AM
使用Langchain Text Splitters -Analytics Vidhya拆分数据的7种方法Apr 19, 2025 am 10:11 AMLangchain文本拆分器:优化LLM输入以提高效率和准确性 我们上一篇文章介绍了Langchain的文档加载程序。 但是,LLM具有上下文窗口大小的限制(以代币测量)。 超过此限制会截断数据,comp
 免费生成的AI课程:开创创新的未来Apr 19, 2025 am 10:01 AM
免费生成的AI课程:开创创新的未来Apr 19, 2025 am 10:01 AM生成的AI:革命性的创造力和创新 生成的AI通过按下按钮来创建文本,图像,音乐和虚拟世界来改变行业。 它的影响跨越视频编辑,音乐制作,艺术,娱乐,HEA
 使用通用句子编码器和Wikiqa创建QA模型Apr 19, 2025 am 10:00 AM
使用通用句子编码器和Wikiqa创建QA模型Apr 19, 2025 am 10:00 AM利用嵌入模型的力量来回答高级问题 在当今信息丰富的世界中,立即获得精确答案的能力至关重要。 本文展示了使用强大的提问(QA)模型
 前十名必须阅读机器学习研究论文Apr 19, 2025 am 09:53 AM
前十名必须阅读机器学习研究论文Apr 19, 2025 am 09:53 AM本文探讨了十个彻底改变人工智能(AI)和机器学习(ML)的开创性出版物。 我们将研究神经网络和算法的最新突破,并解释驱动现代AI的核心概念。 Th


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

记事本++7.3.1
好用且免费的代码编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

