
实现高效逼真的超大规模城市渲染:联合NeRF和特征网格技术

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-05-06 17:04:171223浏览
纯基于 MLP 的神经辐射场(NeRF)由于模型容量有限,在大规模场景模糊渲染中往往存在欠拟合现象。最近有研究者提出对场景进行地理划分、并采用多个子 NeRF,分别对每个区域进行建模,然而,这样做带来的问题是随着场景的逐渐扩展,训练成本和子 NeRF 的数量呈线性扩大。
另一种解决方案是使用体素特征网格表示,该方法计算效率高,可以自然地扩展到具有增加网格分辨率的大场景。然而,特征网格由于约束较少往往只能达到次优解,在渲染中产生一些噪声伪影,特别是在具有复杂几何和纹理的区域。
本文中,来自香港中文大学、上海人工智能实验室等机构的研究者提出了一个新的框架,用来实现高保真渲染的城市(Ubran)场景,同时兼顾计算效率,入选 CVPR 2023。该研究使用一个紧凑的多分辨率 ground 特征平面表示来粗略地捕获场景,并通过一个 NeRF 分支网络用位置编码输入来补充它,以联合学习的方式进行渲染。这种方式集成了两种方案的优点:在特征网格表示的指导下,轻加权 NeRF 足以呈现具有细节的逼真新视角;联合优化的 ground 特征平面可以获得进一步的细化,形成更精确、更紧凑的特征空间,输出更自然的渲染结果。

- 论文地址:https://arxiv.org/pdf/2303.14001.pdf
- 项目主页:https://city-super.github.io/gridnerf/
下图为该研究方法对真实世界 Ubran 场景的示例结果,给人一种沉浸式城市漫游体验:

方法介绍
为了有效利用隐式神经表示重建大型城市场景,该研究提出了一个双分支模型架构,它采用统一的场景表示,集成了基于显式体素网格和基于隐式的 NeRF 方法,这两种类型的表示可以互补。
首先在预训练阶段使用特征网格对目标场景进行建模,从而粗糙地捕捉场景的几何形状和外观。然后使用粗特征网格,1) 引导 NeRF 点采样,使其集中在场景表面周围;2) 为 NeRF 的位置编码提供关于场景几何形状和在采样位置上的外观额外特征。在这样的指导下,NeRF 可以在一个大大压缩的采样空间中有效地获取更精细的细节。此外,由于粗层级的几何图形和外观信息被明确地提供给 NeRF,一个轻量级的 MLP 就足以学习从全局坐标到体积密度和颜色值的映射。在第二个联合学习阶段,通过来自 NeRF 分支的梯度对粗特征网格进行进一步优化,并对其进行规范化,从而在单独应用时产生更准确和自然的渲染结果。
该研究的核心是一个新的双分支结构,即网格分支和 NeRF 分支。1) 研究人员首先在预训练阶段捕捉特征平面的金字塔场景,并通过浅 MLP 渲染器(网格分支)对射线点进行粗略的采样,并预测它们的辐射值,由体积积分像素颜色上的 MSE 损失监督。这一步生成一组信息丰富的多分辨率密度 / 外观特征平面。2) 接下来,研究人员进入联合学习阶段,并进行更精细的抽样。研究人员使用学习到的特征网格来指导 NeRF 分支采样,以集中在场景表面。通过在特征平面上的双线性插值法,推导出采样点的网格特征。然后将这些特征与位置编码连接,并输入 NeRF 分支以预测体积密度和颜色。请注意,在联合训练过程中,网格分支的输出仍然使用 ground 真实图像以及来自 NeRF 分支的精细渲染结果进行监督。
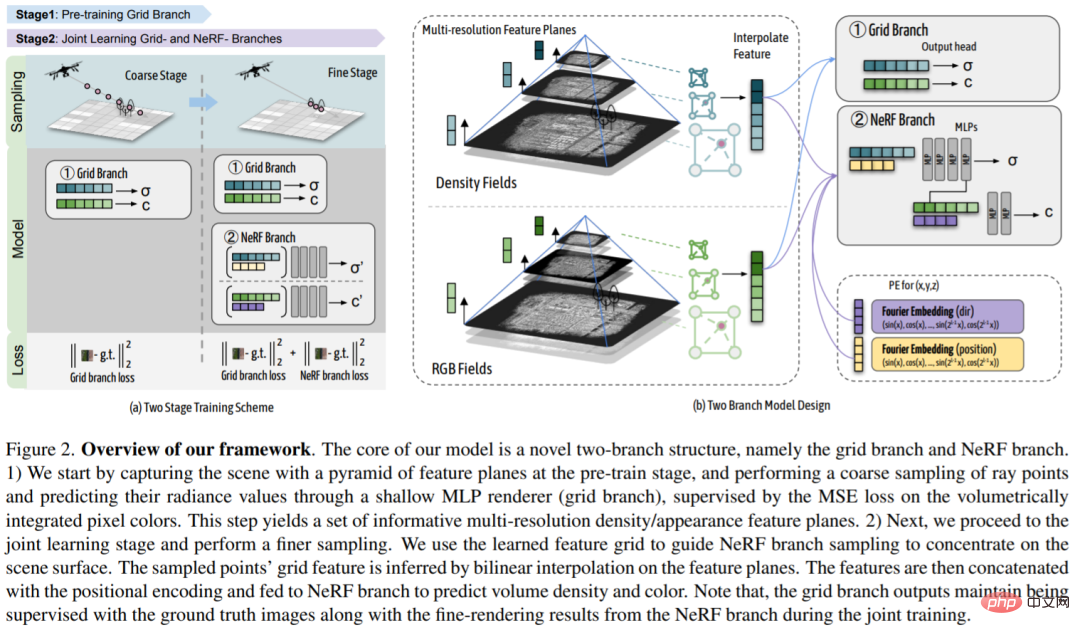
目标场景:在这项工作中,该研究使用新颖的网格引导神经辐射场执行大型城市场景渲染。下图左侧显示了一个大型城市场景的示例,它跨越 2.7km^2 的地面区域,由超过 5k 的无人机图像捕获。研究表明,基于 NeRF 方法渲染结果模糊且过度平滑且模型容量有限,而基于特征网格的方法在适应具有高分辨率特征网格的大规模场景时往往会显示嘈杂的伪影。该研究提出的双分支模型结合了两种方法的优点,并通过对现有方法的显着改进实现了逼真的新颖视图渲染。这两个分支都比各自的基线获得了显着增强。

实验
研究人员在下图和表格中报告了 baseline 的性能和研究人员的方法作对比。无论从定性和定量上看。在视觉质量和所有指标方面都可以观察到显著的改善。与纯粹的基于 MLP 的方法(NeRF 和 Mega-NeRF)相比,研究人员的方法揭示了更清晰的几何形状和更精细的细节。特别是由于 NeRF 的有限容量和光谱偏差,它总是不能模拟几何形状和颜色的快速变化,如操场上的植被和条纹。尽管像 Mega-NeRF 的 baseline 中显示的那样,在地理位置上将场景划分为小区域稍有帮助,但呈现的结果仍然显得过于平滑。相反,在学习特征网格的引导下,NeRF 的采样空间被有效地、大大地压缩到场景表面附近。从 ground 特征平面采样的密度和外观特征明确地表示了场景内容,如图 3 所示。尽管不那么准确,但它已经提供了信息丰富的局部几何图形和纹理,并鼓励 NeRF 的位置编码来收集缺失的场景细节。

下表 1 为定量结果:
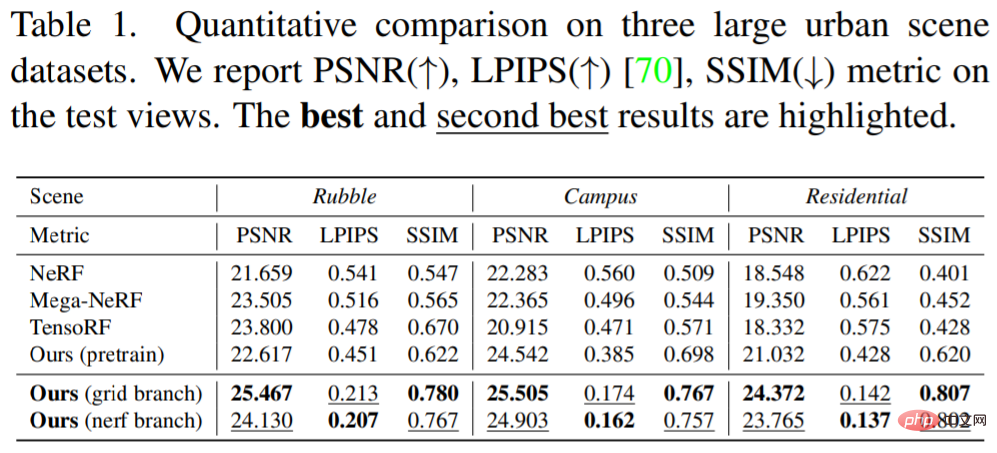
图 6 可以观察到渲染保真度的快速提高:

了解更多内容,请参考原论文。
以上是实现高效逼真的超大规模城市渲染:联合NeRF和特征网格技术的详细内容。更多信息请关注PHP中文网其他相关文章!