
隐私计算在大数据AI领域的应用实践

- 王林转载
- 2023-04-28 15:13:061636浏览
01 隐私计算的背景和现状
1. 隐私计算的背景
隐私计算目前已经成为刚需。一方面,个人用户对个人隐私和信息安全的需求变强了。另一方面,有大量隐私安全相关的法律法规发布,例如欧盟的GDPR,美国的CCPA和国内的个人信息保护法等,法规政策也逐渐从宽松走向严格,主要体现在权力权益、执行范围和执行力度等方面。以GDPR为例,自2018年生效后,已出现了1000多个判例,罚款总额超过110亿,单笔最高罚款超过50亿(Amazon)。


2. 隐私计算的现状
在这样的大背景下,数据安全从可选项变成了必选项。这导致大量企业、投资、初创公司和从业者投入到安全和隐私技术的生态中,学术圈更是针对工业界的需求进行很多前瞻性的探索。这些因素促使近几年安全和隐私技术和生态蓬勃发展,其中的差分隐私、可信执行环境、同态加密、安全多方计算和联邦学习等技术都得到了长足发展。Gartner 对这一领域的发展也秉持着乐观的态度,认为其在未来将会是一个百亿甚至千亿的市场。

02 大数据AI+隐私计算
1. 大数据AI背景
回到大数据AI这个背景,从行业的宏观角度来看,大数据框架和技术已经大规模商用和普及。我们可能每时每刻都在使用大数据的技术,但我们却感受不到程序和模型训练是跑在一个上千甚至上万节点的服务器集群和大规模数据上。近年来,该领域的发展方向有两个新趋势:一是易用性的提高,二是应用方向的细化。前者大大降低的大数据技术的使用门槛,而后者不断为新出现的需求和问题提供新的解决方案,比如数据湖等。
从与AI框架的结合来看,现在大数据和AI生态是紧密结合的。因为对于AI模型来说,数据量越大、质量越高,模型的训练效果就越好,所以大数据和AI这两个领域会天然地结合在一起。
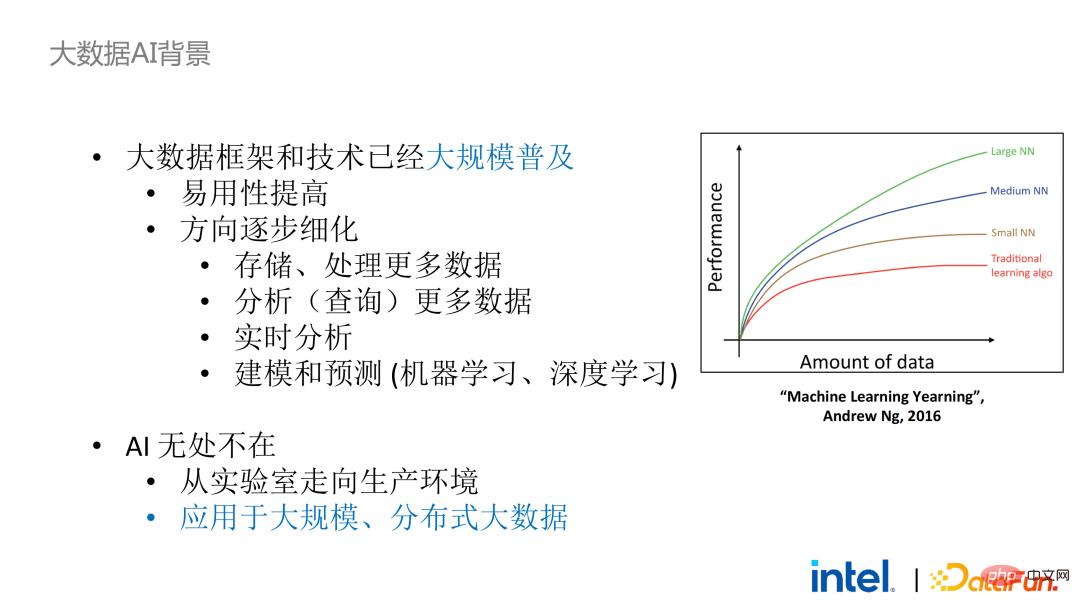
然而即使如此,将大数据框架和AI框架进行融合也并非易事。在应用的开发、数据的获取、清洗、分析和部署的过程中,会涉及很多大数据和AI框架。如果需要保障在关键流程中的数据安全和隐私,就会涉及到很多环节和框架,包括不同的安全技术、加密技术和密钥管理技术等,使得改造和迁移成本大大提高。

2. 大数据AI+隐私计算
两年前,在和行业内大数据及AI应用相关的客户沟通的过程中,我们收集到了一些用户痛点。除了常规的性能问题之外,大多数客户关心的第一个问题是兼容性问题。比如,一些客户已经有了上千甚至上万节点的集群,如果需要将其中的部分模块或者环节进行安全处理,应用隐私计算的技术从而实现隐私保护的功能,则可能需要对现有应用进行更改,甚至引入一些全新的框架或基础设施,这些冲击是客户需要考虑的首要问题。其次,客户会考虑数据规模对安全技术的影响,希望引入的新框架和技术能够支持大规模数据的计算且具有较高的计算效率。最后客户才会考虑联邦学习技术是否能解决数据孤岛的问题。

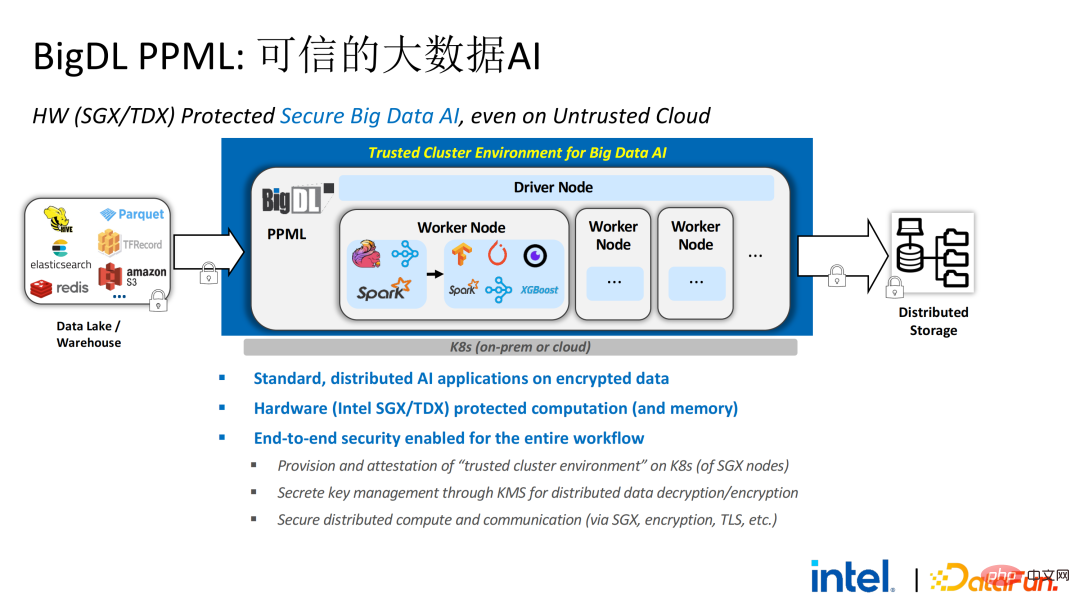
基于调研得出的客户需求,我们推出了BigDL PPML方案,其首要目标是让常规的、标准的大数据及AI方案能在安全环境中运行,确保端到端都是安全的。为此,计算过程需要被SGX(硬件级的TEE)保护。同时,需要保证存储和网络被加密,整个链路需要进行远程证明(也被称为远程签鉴),确保计算的机密性和完整性。
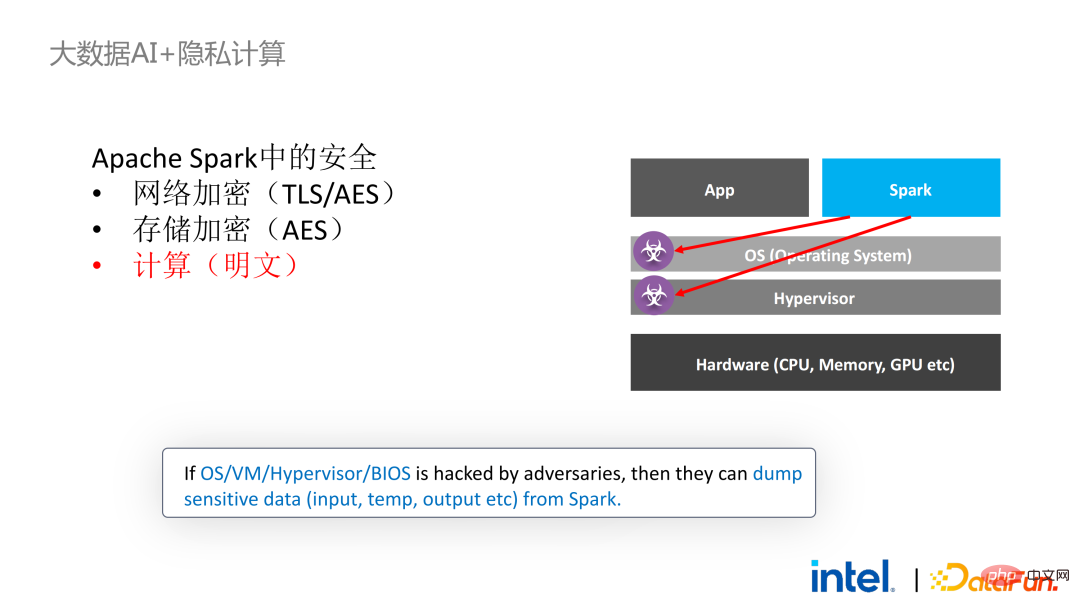
接下来我们以Apache Spark这一常用的大数据框架为例详细阐述该方案的必要性。Apache Spark是大数据AI领域比较常用的分布式计算框架,它已经有很多与安全相关的功能了,例如,网络方面可以进行加密和认证,通信和RPC都被TLS和AES保护;存储方面主要涉及本地shuffle存储,也采用AES保护;但计算方面存在较大的问题,因为即使是最新版本的Spark也只能进行明文计算。万一计算环境或者节点被攻破,其就能获取到大量敏感数据。
SGX技术是以Intel CPU为底层设施的软硬件结合的可信计算环境技术,它具有:
- 硬件级的可信执行环境
- 相对小的攻击面:哪怕部分系统已经被攻破,只要CPU是安全的就能够确保整个程序的安全性
- 性能影响小
- 足够大的飞地(最大1TB)
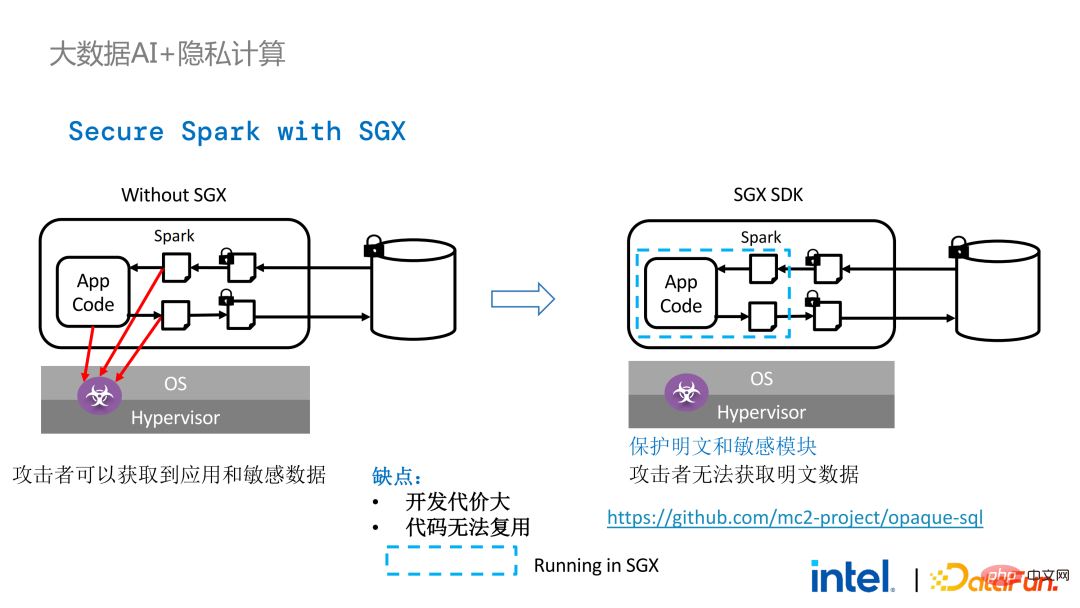
回到之前提到的Apache Spark这个应用场景:
左边是计算环境没有受到保护的情况,哪怕使用了加密存储,只要在明文计算阶段遭到攻击,就会有数据泄露的风险;右边则是Spark社区的一些尝试,通过把SparkSQL相关的一些关键步骤提取出来,用SGX SDK重写这部分逻辑,既能够实现性能的最大化,又能实现攻击面最小化。但这一方法缺点也很明显,即开发代价太大,成本太高。重新SparkSQL核心逻辑,需要对Spark有清晰明确的认识;同时,代码无法复用到其他项目。
为了解决以上提到的缺点,我们使用了LibOS方案,简而言之就是通过LibOS这一中间层,降低开发和迁移的难度,将系统API的调用转换成SGX SDK能够识别的形式,从而实现一些常规应用的无缝迁移。常见的LibOS解决方案有蚂蚁集团的Occlum、英特尔参与的Gramine以及帝国理工主导的sgx-lkl方案等。以上LibOS都有各自的特性和优势,它们通过不同的方式解决了SGX的易用性和易迁移性的问题。
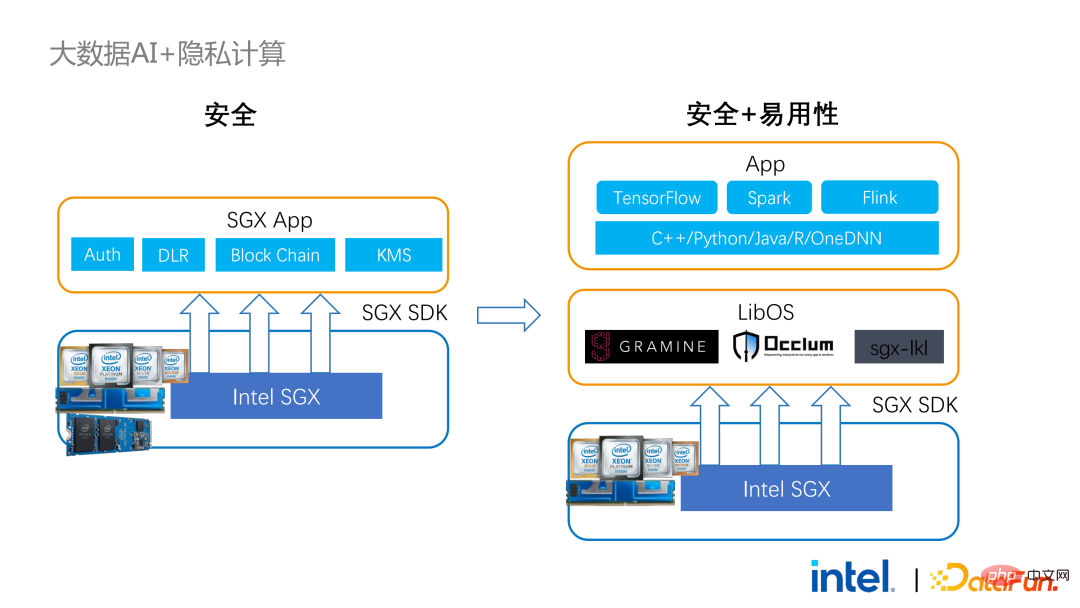
有了LibOS就不再需要重写Spark中的核心逻辑,而是能够通过LibOS将整个Spark放入SGX中,同时无需修改Spark和现有应用。
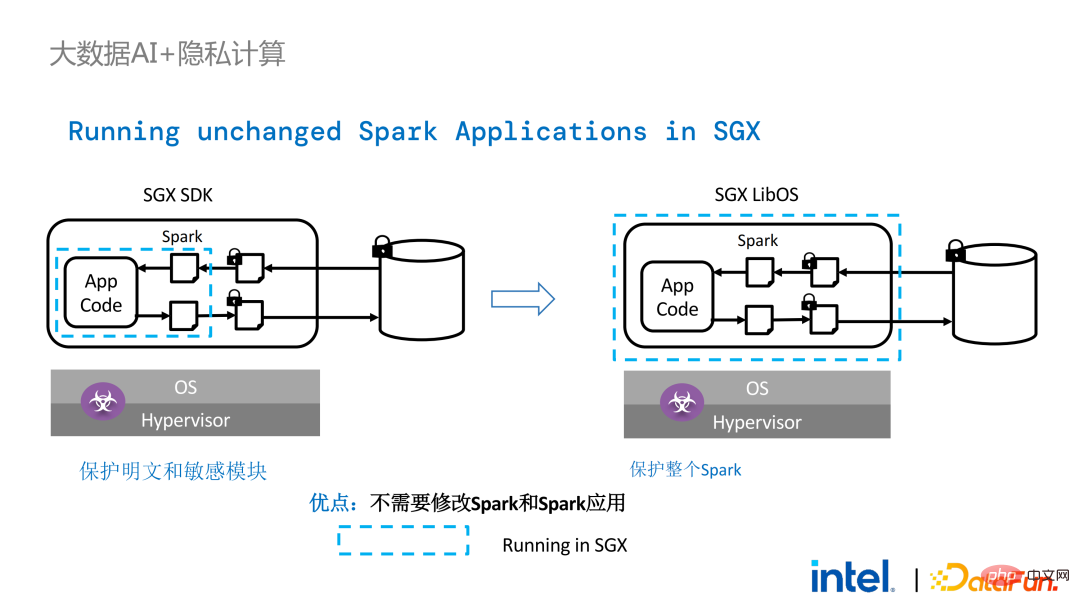
在Spark的分布式计算中,可以将分布式中的各个模块分别用LibOS和SGX保护,存储端可以配置密钥管理和加密存储,executor获取密文数据后在SGX中解密并计算。整个流程对开发人员较为无感,对现有应用的冲击较少。
不过,与单机应用相比,分布式应用中的安全问题也更为复杂。攻击者可能将部分运行节点攻破,或者与资源管理节点形成共谋,从而用恶意的运行环境替换SGX环境。这样就能非法获取密钥和加密数据,并最终造成隐私数据泄露。
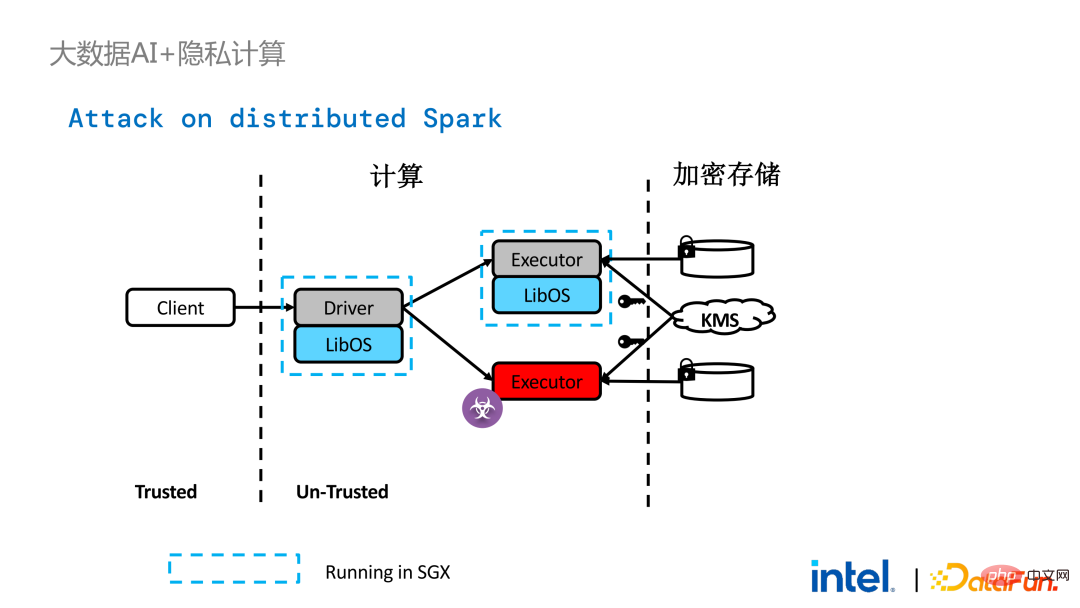
为了解决这问题,需要应用远程证明技术。简单来说,就是跑在SGX中的应用可以提供证明或证书,且该证明或证书是不可篡改的。证书能够证实该应用是否在SGX中运行、应用是否被篡改,平台是否符合安全标准等。
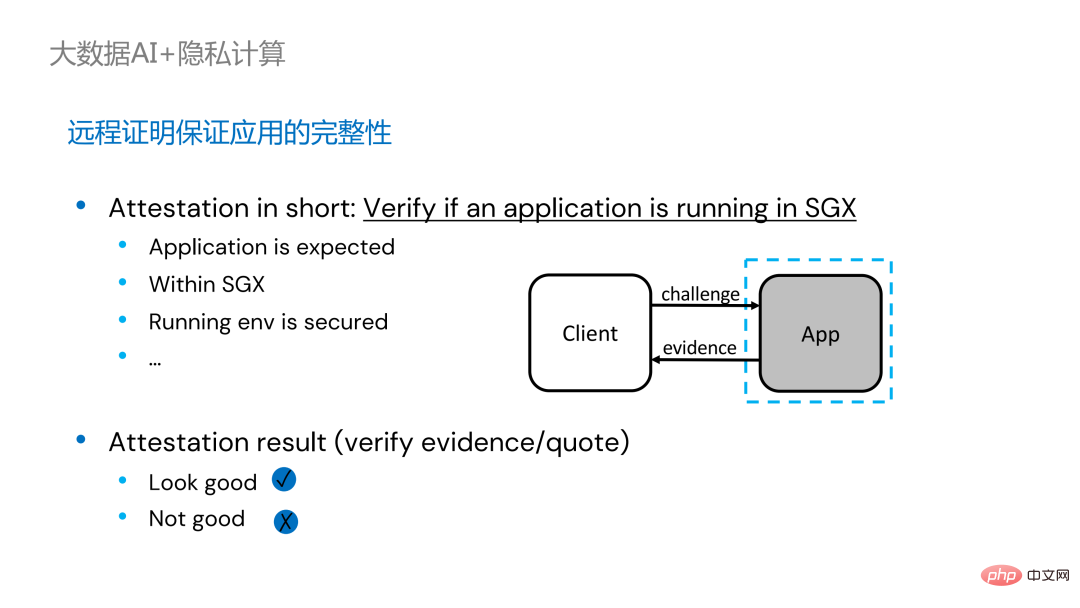
为分布式应用加入远程证明存在两种实现方式。左边是一套比较完备但改动较大的方案,在driver端和executor端互相做远程证明,需要对Spark做一定程度的修改。另外一种方案则通过第三方的远程证明服务器实现集中式的远程证明,并使用不可更改的证书阻断被攻击者控制的模块获取数据。第二种方案不需要修改应用程序,只需对小部分启动脚本进行修改即可。
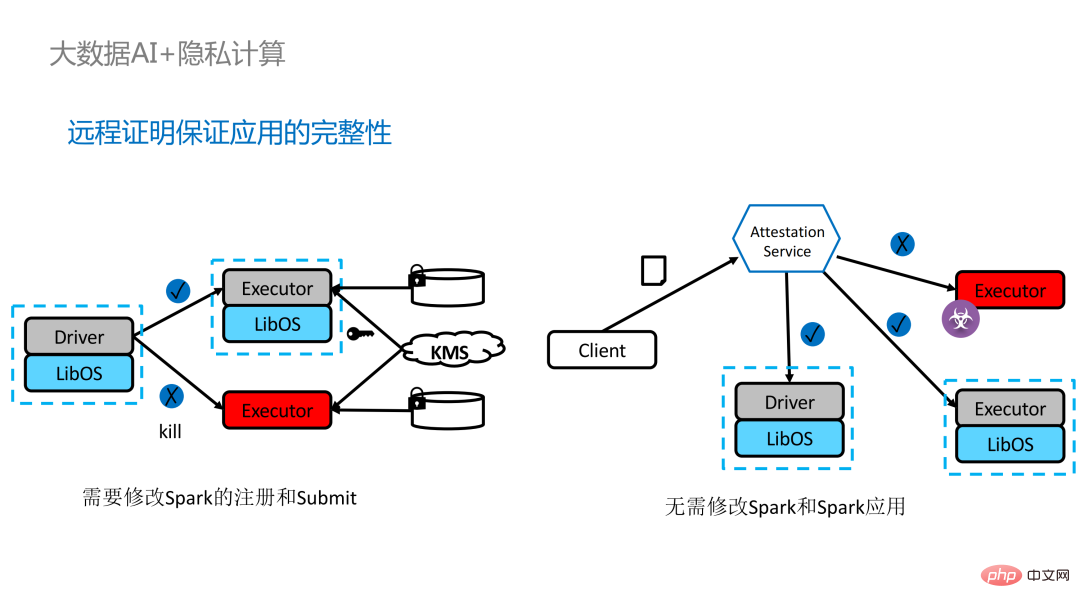
虽然LibOS可以让Spark运行在SGX中,但进行Spark的LibOS和SGX适配依旧需要花费一定人力和时间成本。为此我们推出了PPML的一站式解决方案,其中很多步骤都能实现自动化处理,并且实现无缝迁移,极大地减少迁移成本。
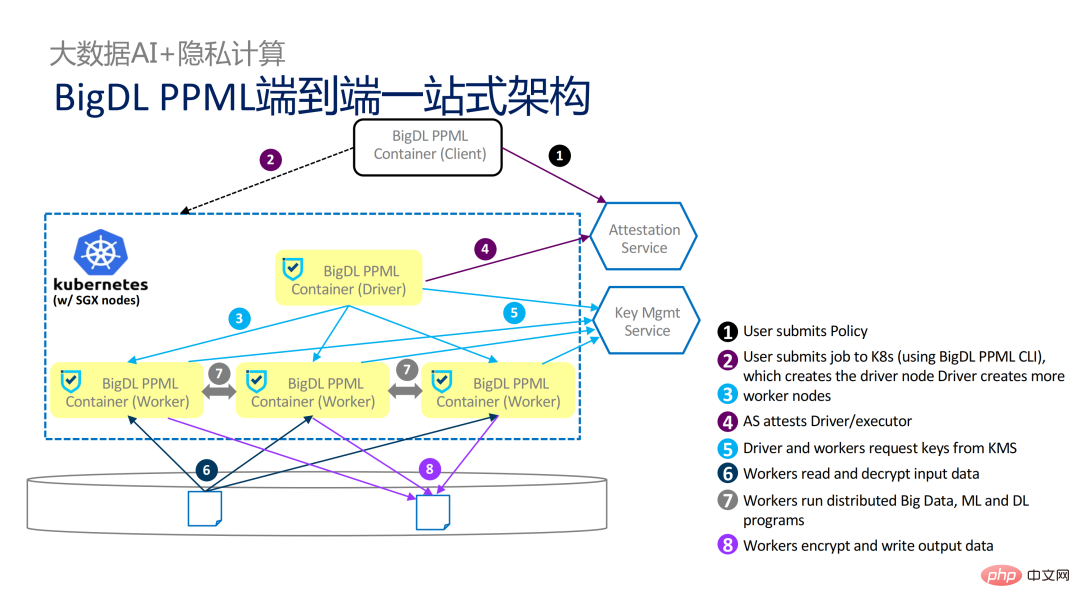
从工作流的角度来说,此方案还有另外一个优点,即数据科学家感知不到底层的变化,只有集群管理员需要参与SGX的部署和准备工作,数据科学家可以正常地进行建模和查询工作,完全感知不到底层的环境已经发生了变化。这样就可以很好地解决现有应用的兼容性和迁移问题,也不会阻碍数据科学家和开发人员的日常工作。
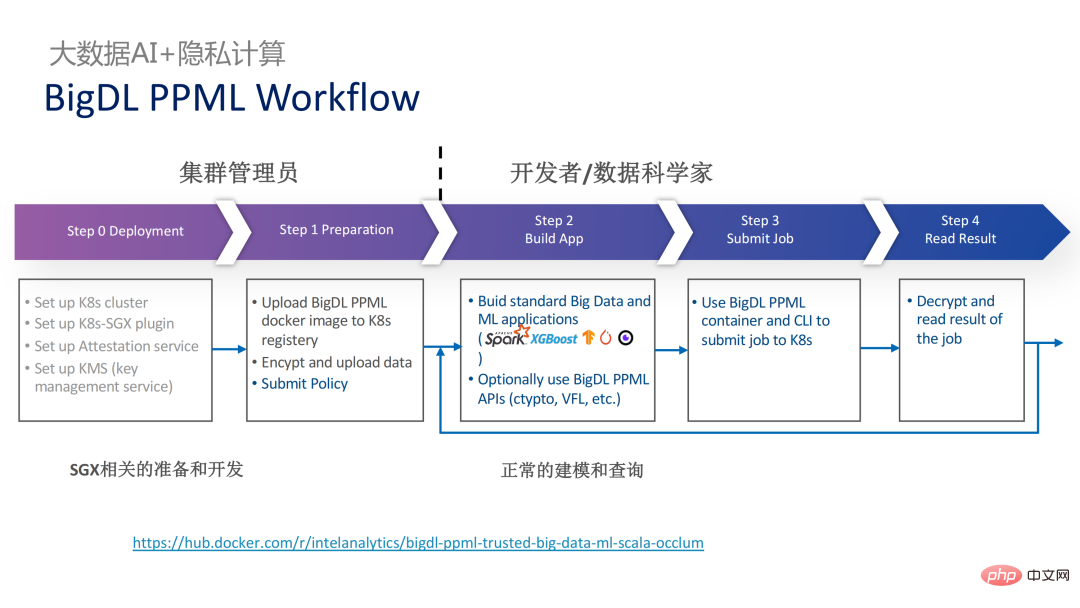
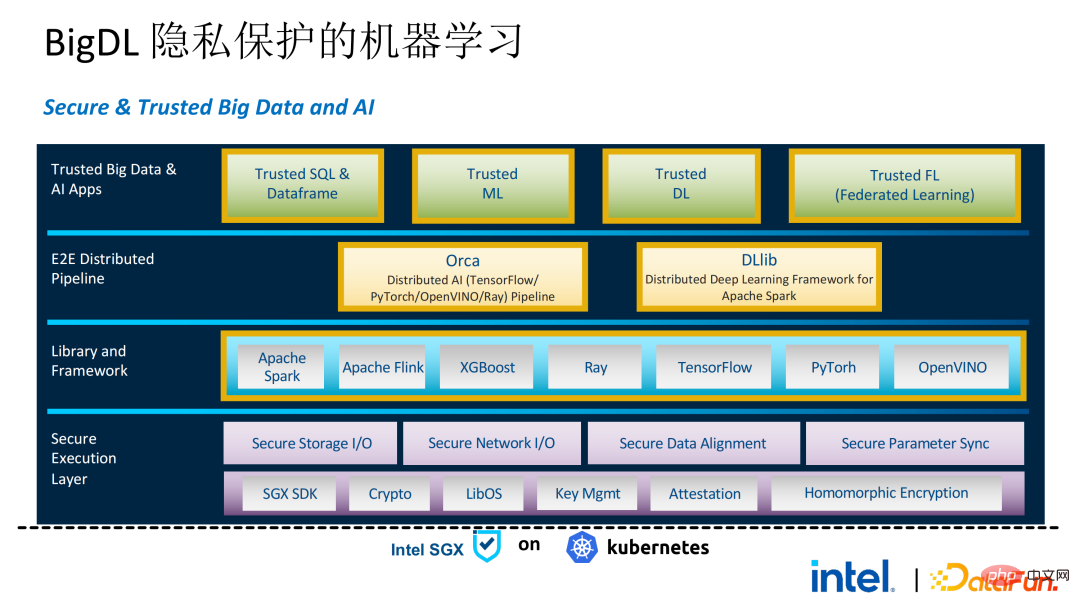
以下是整个PPML方案的全貌。为了满足客户的不同需求,在最近这两年内PPML支持的功能也在不断拓展。例如,中间层Library and Framework中,Spark、Flink和Ray等常用的计算框架均在支持范围内;同时PPML也支持机器学习、深度学习、联邦学习功能,并配有加密存储和同态加密的支持,保证端到端的全链路安全性。
03 应用实践
下面是一些客户的应用实践案例,其中比较有名的是去年的天池大赛。在去年的一个分赛中,参赛方希望训练和模型推理过程能完全被SGX保护,通过PPML提供的Flink功能,结合蚂蚁集团的LibOS项目Occlum,实现训练和模型推理在应用层面无感。最终整个比赛有4000多支队伍参加,应用了上百台服务器,证明了PPML能够支持大规模商用,并且整体而言,运营方并没有感知到很大的变化。

在同年9-10月份,韩国电信希望搭建一个端到端安全的、基于BigDL和Flink的实时模型推理环境,他们对性能的要求更加苛刻。经过天池的历练,BigDL基于Flink和SGX的实时模型推理的方案更加成熟,端到端的性能损失小于5%,吞吐量也达到了韩国电信的基本需求。
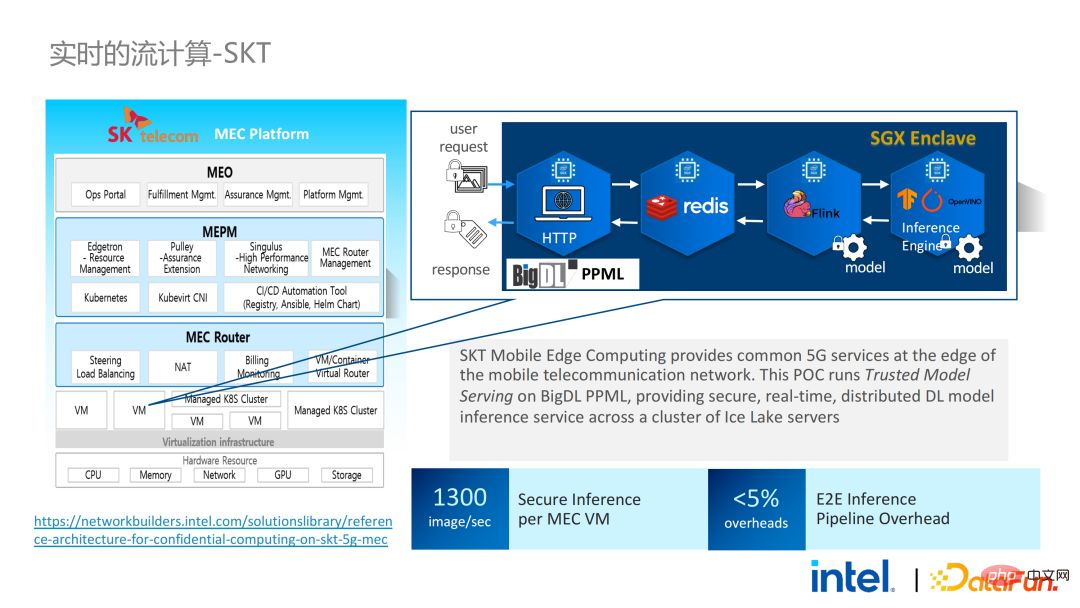
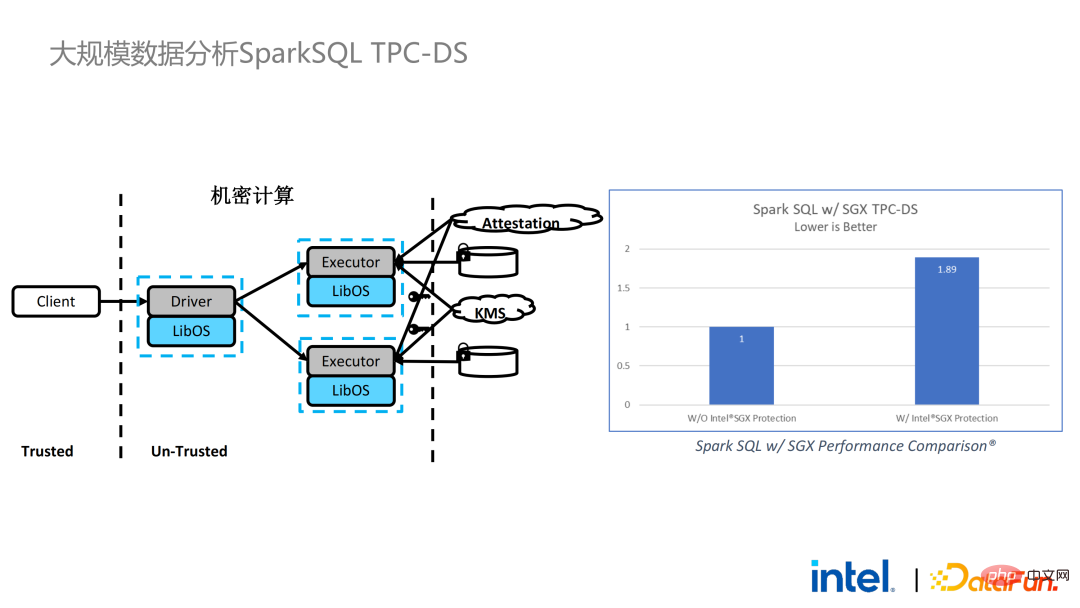
我们也进行了Spark的性能测试。结论而言,即使测试数据达到上百GB,PPML方案运行Spark也没有出现拓展性和性能问题。根据客户的需求,我们专门选了一个对SGX不友好的IO密集型应用TPC-DS。TPC-DS是一个常用的SQL benchmark标准,它对IO和计算的要求比较高,在数据量较大时,会出现大规模的磁盘、内存和网络IO。而作为硬件级的TEE,数据进出SGX都需要经过解密和加密,因此读取和写出数据的开销会比非SGX大。经过完整的TPC-DS测试,整个端到端的损失在2倍以内,达到了客户的预期。通过TPC-DS的benchmark,我们证明了,哪怕是在这种最坏的情况下,我们都能确保端到端的损失降到可接受的范围内(1.8)。
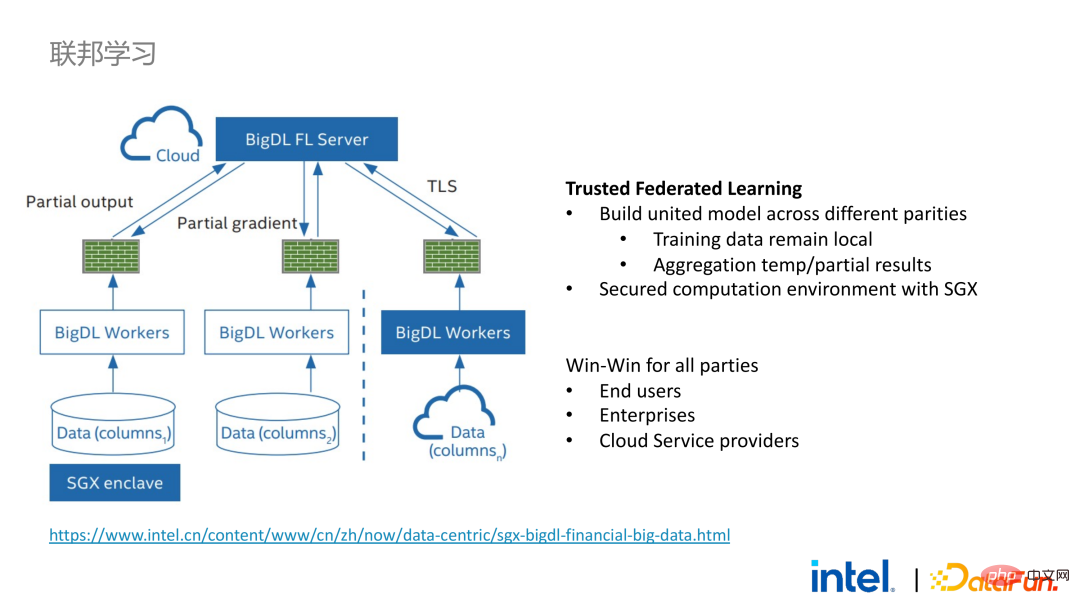
实现了大数据应用的无缝迁移之后,我们也和部分客户进行了联邦学习的尝试。因为SGX提供了安全的环境,恰好可以解决联邦学习过程中最关键的服务器和本地数据的安全问题。BigDL提供的联邦学习方案和一般方案有一个很大的差异,即整个方案本质上是一个面向大规模数据的联邦学习方案。其中,每个worker的工作负载和针对的数据规模较大,每一个worker相当于一个小集群。我们和部分客户验证了该方案的可行性和有效性。
04 总结和展望
如前文所说,在和客户两年多的沟通和合作中,我们挖掘到了隐私计算和大数据AI相关的若干痛点。这些痛点均可以通过SGX等安全技术解决。其中,LibOS能够解决兼容性问题,SGX能够解决安全环境和性能问题;Spark或Flink的支持能够解决大数据及迁移的问题;联邦学习能够解决数据孤岛问题。BigDL PPML则是综合了上述服务的一站式隐私计算方案。

SGX和TEE的生态目前正在快速发展。在可预见的未来,TEE在易用性、安全性和性能等方面会有很大的提高,例如英特尔下一代的TDX能直接提供OS的支持,可以从根本上解决应用的兼容性问题;开源社区也在完善机密容器的支持,确保container的安全性,大大降低应用迁移的成本。从安全性角度来说,也会出现如微内核之类工作,进一步强化TEE生态的安全性。从拓展性的角度来看,英特尔和社区也在推进对加速器和IO设备的支持,将其纳入可信域内,降低数据流转的性能开销。

以上是隐私计算在大数据AI领域的应用实践的详细内容。更多信息请关注PHP中文网其他相关文章!