



Python生产者消费者模型
一、消费模式
生产者消费者模式 是Controlnet网络中特有的一种传输数据的模式。用于两个CPU之间传输数据,即使是不同类型同一厂家的CPU也可以通过设置来使用。
二、传输原理
类似与点对点传送,又略有不同,一个生产者可以对应N个消费者,但是一个消费者只能对应一个生产者;
每个生产者消费者对应一个地址,占一个网络节点,属于预定性数据,在网络中优先级最高;
此模式如果在网络中设置过多会影响网络传输速度,一般用在传输比较重要的信息上,比如设备的启动、停止、故障、急停等等;
在Controlnet网络中节点数是有限制的,最高节点数为99。
如果两个控制器之前建立了多个生产者消费者的连接,只要一个失败,则所有的均失败,将数据整合到用户自定义结构或数组中 ,两个控制器中只保留一个连接。
生产者消费者信息可以通过以太网和Controlnet传输,但是同时只能通过一种途径传输;
建立标签时必须建立在全局变量里面,不能建立在局部变量里标签的大小不能超过500B;
如果生产者几个数据传输到到同一个控制器的的几个消费者中,将几个数据合并在一个用户自定义标签中,可以减少连接数,但合并后的数据将会会用相同的RPI。
生产者消费者标签只能用DINT和REAL,或它们的数组,或用户自定义结构数据,因为对外操作数据必须是32位的,如果有SINT和INT的数据要传输,必须将它们组合在用户自定义结构中传送,生产者和消费者的标签数据格式必须一致,才能确保数据的准确性,如果数据打包后超过了 32位,那么生产者和消费者双方必须使用一个复制缓冲指令,以获得数据的同步,例如Control Logix中的CPS指令。
如果生产者要发送的32位数据,与非Control Logix的对方设备的数据结构不匹配,例如对方是16位的数据,为避免偏差,改为用户自定义结构。
消费者的 RPI必须大于等于网络刷新时间NUT,如果几个消费者请求同一个生产者,则会以最小最快的RPI为准。
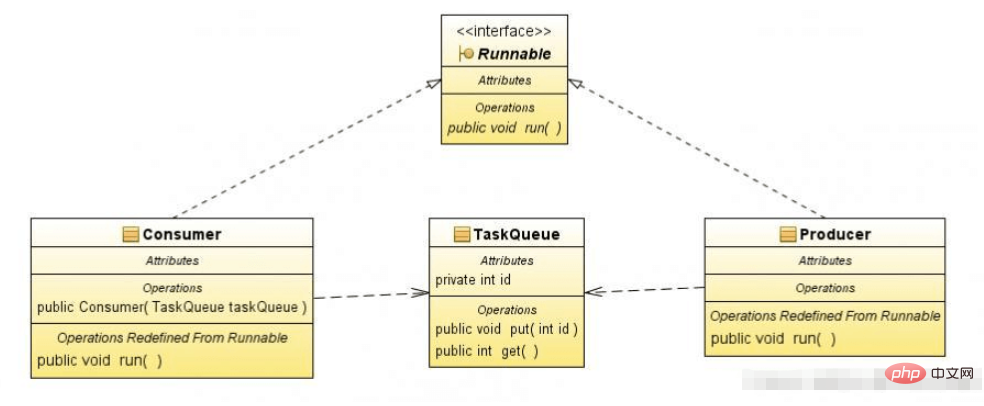
三、实现方式
方法一:
import threading,queue,time
# 创建一个队列,队列最大长度为2
q = queue.Queue(maxsize=2)
def product():
while True:
# 生产者往队列塞数据
q.put('money')
print('生产了money, 生产时间:', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
def consume():
while True:
time.sleep(0.5)
# 消费者取出数据
data = q.get()
print('消费了%s, 消费时间%s' % (data, time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())))
t = threading.Thread(target=product)
t1 = threading.Thread(target=consume)
t.start()
t1.start()缺点:
实现了多少个消费者consumer进程,就需要在最后往队列中添加多少个None标识,方便生产完毕结束消费者consumer进程。否则,p.get() 不到任务会阻塞子进程,因为while循环,直到队列q中有新的任务加进来,才会再次执行。而我们的生产者只能生产这么多东西,所以相当于程序卡死。
方法二:
from multiprocessing import JoinableQueue,Process
import time
def producer(q):
for i in range(4):
time.sleep(0.5)
f = '生产者:已经生产'
q.put(f)
print(f)
q.join() # 一直阻塞,等待消耗完所有的数据后才释放
def consumer(name, q):
while True:
food = q.get()
print('\033[消费者:消费了%s\033' % name)
time.sleep(0.5)
q.task_done() # 每次消耗减1
if __name__ == '__main__':
q = JoinableQueue() # 创建队列
# 模拟生产者队列
p1 = Process(target=producer, args=(q, ))
p1.start()
# 模拟消费者队列
c1 = Process(target=consumer, args=('money', q))
c1.daemon = True # 守护进程:主进程结束,子进程也会结束
c1.start()
p1.join() # 阻塞主进程,等到p1子进程结束才往下执行优点:
使用JoinableQueue组件,是因为JoinableQueue中有两个方法:task_done()和join() 。首先说join()和Process中的join()的效果类似,都是阻塞当前进程,防止当前进程结束。但是JoinableQueue的join()是和task_down()配合使用的。
Process中的join()是等到子进程中的代码执行完毕,就会执行主进程join()下面的代码。而JoinableQueue中的join()是等到队列中的任务数量为0的时候才会执行q.join()下面的代码,否则会一直阻塞。
task_down()方法是每获取一次队列中的任务,就需要执行一次。直到队列中的任务数为0的时候,就会执行JoinableQueue的join()后面的方法了。所以生产者生产完所有的数据后,会一直阻塞着。不让p1和p2进程结束。等到消费者get()一次数据,就会执行一次task_down()方法,从而队列中的任务数量减1,当数量为0后,执行JoinableQueue的join()后面代码,从而p1和p2进程结束。
因为p1和p2添加了join()方法,所以当子进程中的consumer方法执行完后,才会往下执行。从而主进程结束。因为这里把消费者进程c1和c2 设置成了守护进程,主进程结束的同时,c1和c2 进程也会随之结束,进程都结束了。所以消费者consumer方法也会结束。
以上是python多进程中的生产者和消费者模型怎么实现的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python脚本可能无法在UNIX上执行的一些常见原因是什么?Apr 28, 2025 am 12:18 AM
Python脚本可能无法在UNIX上执行的一些常见原因是什么?Apr 28, 2025 am 12:18 AMPython脚本在Unix系统上无法运行的原因包括:1)权限不足,使用chmod xyour_script.py赋予执行权限;2)Shebang行错误或缺失,应使用#!/usr/bin/envpython;3)环境变量设置不当,可打印os.environ调试;4)使用错误的Python版本,可在Shebang行或命令行指定版本;5)依赖问题,使用虚拟环境隔离依赖;6)语法错误,使用python-mpy_compileyour_script.py检测。
 举一个场景的示例,其中使用Python数组比使用列表更合适。Apr 28, 2025 am 12:15 AM
举一个场景的示例,其中使用Python数组比使用列表更合适。Apr 28, 2025 am 12:15 AM使用Python数组比列表更适合处理大量数值数据。1)数组更节省内存,2)数组对数值运算更快,3)数组强制类型一致性,4)数组与C语言数组兼容,但在灵活性和便捷性上不如列表。
 在Python中使用列表与数组的性能含义是什么?Apr 28, 2025 am 12:10 AM
在Python中使用列表与数组的性能含义是什么?Apr 28, 2025 am 12:10 AM列表列表更好的forflexibility andmixDatatatypes,何时出色的Sumerical Computitation sand larged数据集。1)不可使用的列表xbilese xibility xibility xibility xibility xibility xibility xibility xibility xibility xibility xibles and comply offrequent elementChanges.2)
 Numpy如何处理大型数组的内存管理?Apr 28, 2025 am 12:07 AM
Numpy如何处理大型数组的内存管理?Apr 28, 2025 am 12:07 AMnumpymanagesmemoryforlargearraysefefticefticefipedlyuseviews,副本和内存模拟文件.1)viewsAllowSinglicingWithOutCopying,直接modifytheoriginalArray.2)copiesCanbecopy canbecreatedwitheDedwithTheceDwithThecevithThece()methodervingdata.3)metservingdata.3)memore memore-mappingfileShessandAstaStaStstbassbassbassbassbassbassbassbassbassbassbb
 哪个需要导入模块:列表或数组?Apr 28, 2025 am 12:06 AM
哪个需要导入模块:列表或数组?Apr 28, 2025 am 12:06 AMListsinpythondonotrequireimportingamodule,helilearraysfomthearraymoduledoneedanimport.1)列表列表,列表,多功能和canholdMixedDatatatepes.2)arraysaremoremoremoremoremoremoremoremoremoremoremoremoremoremoremoremoremeremeremeremericdatabuteffeftlessdatabutlessdatabutlessfiblesible suriplyElsilesteletselementEltecteSemeTemeSemeSemeSemeTypysemeTypysemeTysemeTypysemeTypepe。
 可以在Python数组中存储哪些数据类型?Apr 27, 2025 am 12:11 AM
可以在Python数组中存储哪些数据类型?Apr 27, 2025 am 12:11 AMpythonlistscanStoryDatatepe,ArrayModulearRaysStoreOneType,and numpyArraySareSareAraysareSareAraysareSareComputations.1)列出sareversArversAtileButlessMemory-Felide.2)arraymoduleareareMogeMogeNareSaremogeNormogeNoreSoustAta.3)
 如果您尝试将错误的数据类型的值存储在Python数组中,该怎么办?Apr 27, 2025 am 12:10 AM
如果您尝试将错误的数据类型的值存储在Python数组中,该怎么办?Apr 27, 2025 am 12:10 AMWhenyouattempttostoreavalueofthewrongdatatypeinaPythonarray,you'llencounteraTypeError.Thisisduetothearraymodule'sstricttypeenforcement,whichrequiresallelementstobeofthesametypeasspecifiedbythetypecode.Forperformancereasons,arraysaremoreefficientthanl
 Python标准库的哪一部分是:列表或数组?Apr 27, 2025 am 12:03 AM
Python标准库的哪一部分是:列表或数组?Apr 27, 2025 am 12:03 AMpythonlistsarepartofthestAndArdLibrary,herilearRaysarenot.listsarebuilt-In,多功能,和Rused ForStoringCollections,而EasaraySaraySaraySaraysaraySaraySaraysaraySaraysarrayModuleandleandleandlesscommonlyusedDduetolimitedFunctionalityFunctionalityFunctionality。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

Dreamweaver Mac版
视觉化网页开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

