



分子是维持物质化学稳定性的最小单位。对分子的研究,是药学、材料学、生物学、化学等众多科学领域的基础性问题。
分子的表征学习(Molecular Representation Learning)是近年来非常热门的方向,目前可分为诸多门派:
- 计算药学家说:分子可以表示为一串指纹,或者描述符,如上海药物所提出的 AttentiveFP,是这方面的杰出代表。
- NLPer 说:分子可以表示为 SMILES(序列),然后当作自然语言处理,如百度的 X-Mol,是这方面的杰出代表。
- 图神经网络研究者说:分子可以表示为一个图(Graph),也就是邻接矩阵,然后使用图神经网络处理,如腾讯的 GROVER, MIT 的 DMPNN,CMU 的 MOLCLR 等方法,都是这方面的杰出代表。
但是,目前的表征方法仍存在一些局限性。比如,序列表征缺乏分子的显式结构信息,现有图神经网络的表达能力仍有诸多局限(中科院计算所沈华伟老师对此有论述,见沈老师报告“图神经网络的表达能力”)。
有趣的是,在高中化学学习分子的时候,我们看到的是分子的图像,化学家在设计分子时,也是对照分子图像进行观察和思考。一个自然的想法油然而生:“为什么不直接用分子图像来表征分子呢?”如果可以直接用图像来表征分子,那 CV(计算机视觉)里面的十八般武艺,不都可以用来研究分子吗?
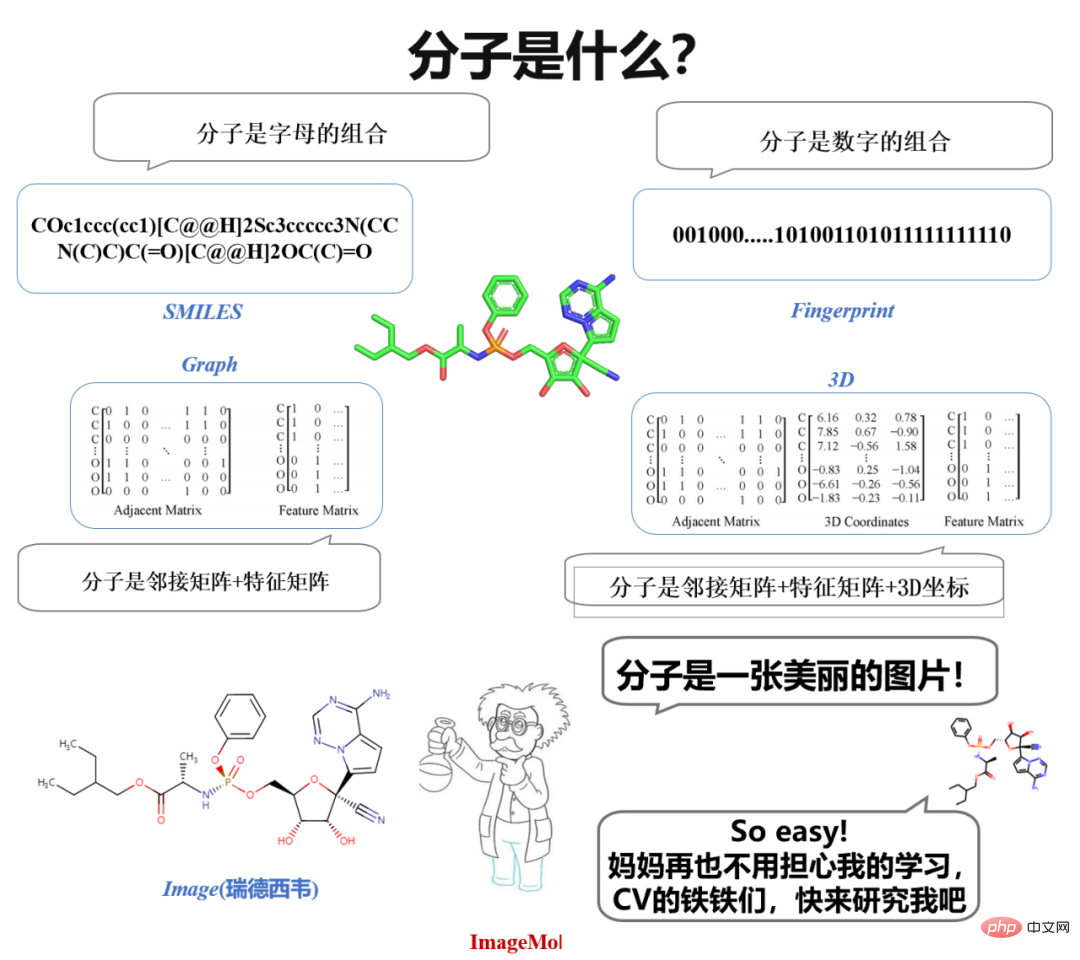
说干就干,CV 里面的模型那么多,拿过来学习分子呗?打住,还有一个重要的问题——数据!特别是带标签的数据!在 CV 领域,数据标注这件事似乎并不困难。对于图像识别或者情感分类这些 CV 和 NLP 的经典问题来说,一个人平均能标注 800 条数据。但是在分子领域,只能通过湿实验和临床实验的方式评估分子性质,因此带标签的数据非常稀缺。
基于此,来自湖南大学的研究者们提出了全球首个分子图像的无监督学习框架 ImageMol,利用大规模无标签分子图像数据进行无监督预训练,为分子性质与药物靶点理解提供了新范式,证明了分子图像在智能药物研发领域具有巨大的潜力。该成果以 “Accurate prediction of molecular properties and drug targets using a self-supervised image representation learning framework” 为题发表于国际顶级期刊《Nature Machine Intelligence》。此次计算机视觉与分子领域交叉取得的成功展示了利用计算机视觉技术理解分子性质与药物靶点机制的巨大潜力,并为分子领域的研究提供了新的机遇。
论文链接:https://www.nature.com/articles/s42256-022-00557-6.pdf
ImageMol 模型结构
ImageMol 的整体架构如下图所示,总共分为三部分:
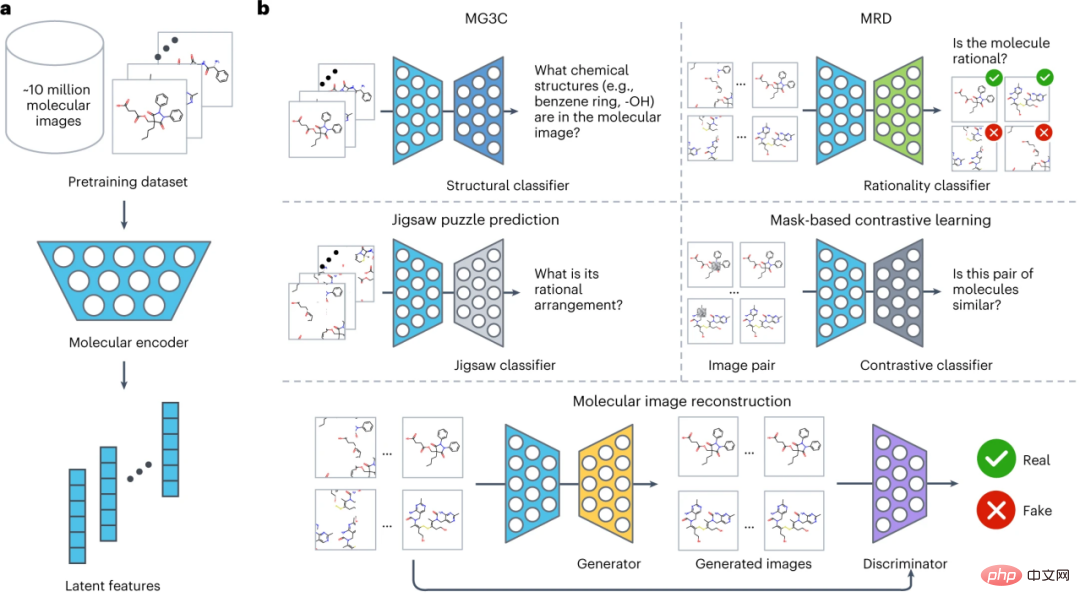
(1) 设计一个分子编码器 ResNet18(浅蓝色),能够从约 1000 万张分子图像中提取潜在特征 (a) 。
(2)考虑分子图像中的化学知识和结构信息,利用五个预训练策略(MG3C、MRD、JPP、MCL、MIR)来优化分子编码器的潜在表示 (b) 。具体来说为:
① MG3C(Muti-granularity chemical clusters classification 多粒度化学簇分类):其中的结构分类器 Structure classifier(深蓝色)用于预测分子图像中的化学结构信息;
② MRD(Molecular rationality discrimination 分子合理性判别器):其中的合理性分类器 Rationality classifier(绿色),它用于区分合理与不合理的分子;
③ JPP(Jigsaw puzzle predicition 拼图预测):其中的拼图分类器 Jigsaw classifier(浅灰色)用于预测分子的合理排列;
④ MCL(MASK-based contrastive learning 基于 MASK 的对比学习):其中的对比分类器 Contrastive classifier(深灰色)用于最大化原始图像和 mask 图像之间的相似性;
⑤ MIR(Molecular image reconstruction 分子图像重建):其中的生成器 Generator(黄色)用于将潜在特征恢复分子图像,判别器 Discriminator(紫色)用于区分真实图像和生成器生成的假的分子图像。
(3)在下游任务中对预处理的分子编码器进行微调,以进一步提高模型性能 (c) 。
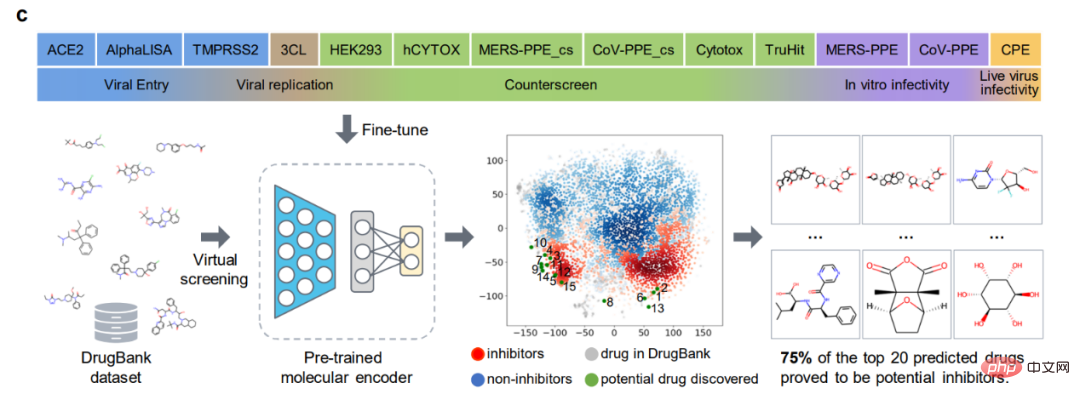
基准评估
作者首先使用 8 种药物发现的基准数据集来评估 ImageMol 的性能,并且使用两种最流行的拆分策略(scaffold split 与 random scaffold split)来评估 ImageMol 在所有基准数据集上的性能。在分类任务中,利用受试者工作特性(Receiver Operating Characteristic, ROC)曲线以及曲线下的面积(Area Under Curve, AUC)来评估,从实验结果可以看出,ImageMol 均能得到较高的 AUC 值 (图 a) 。
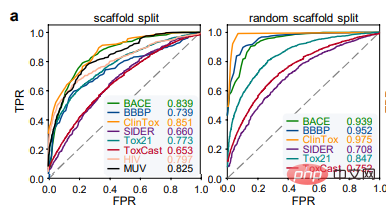
ImageMol 与预测分子图像的经典卷积神经网络框架 Chemception 在 HIV 和 Tox21 的检测结果对比 (图 b) ,ImageMol 的 AUC 值更高。本文进一步评估了 ImageMol 在预测五种主要代谢酶(CYP1A2, CYP2C9, CYP2C19, CYP2D6 和 CYP3A4)药物代谢方面的性能。图 c 显示,ImageMol 在五种主要药物代谢酶的抑制剂与非抑制剂的预测中,与三种最先进的基于分子图像的表示模型(Chemception46、ADMET-CNN12 和 QSAR-CNN47)相比,获得了更高的 AUC 值(范围从 0.799 到 0.893)。
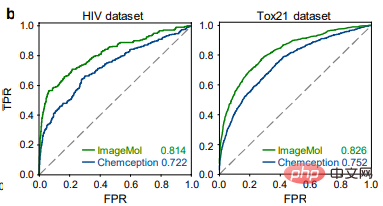

本文进一步将 ImageMol 的性能与三种最先进的分子表示模型进行了比较,如图 d、e 所示。ImageMol 与使用随机骨架划分的基于指纹的模型(如 AttentiveFP)、基于序列的模型(如 TF_Robust)和基于图的模型(如 N-GRAM、GROVER 和 MPG)相比具有更好的性能。此外,与传统的基于 MACCS 的方法和基于 FP4 的方法相比,ImageMol 在 CYP1A2,CYP2C9,CYP2C19,CYP2D6 和 CYP3A4 上实现了更高的 AUC 值(图 f)。
ImageMol 与基于序列的模型(包括 RNN_LR、TRFM_LR、RNN_MLP、TRFM_MLP、RNN_RF、TRFM_RF 和 CHEM-BERT)和基于图的模型(包括 MolCLRGIN、MolCLRGCN 和 GROVER)相比,如图 g 所示,ImageMol 在 CYP1A2、CYP2C9、CYP2C19、CYP2D6、CYP3A4 上实现了更好的 AUC 性能。
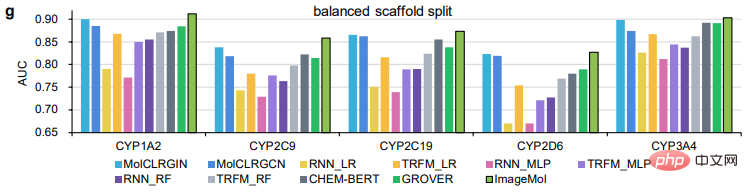
在以上 ImageMol 与其他先进的模型对比中,可以看出 ImageMol 的优越性。
自新冠疫情爆发以来,我们迫切需要为新冠疫情制定有效的治疗策略。因此,作者在该方面对 ImageMol 做了相应的评估。
对 13 个 SARS-CoV-2 靶点进行预测
ImageMol 对现如今关注的SARS-CoV-2 进行了预测实验,在 13 个 SARS-CoV-2 生物测定数据集中,ImageMol 实现了 72.6% 至 83.7% 的高 AUC 值。图 a 揭示了通过 ImageMol 鉴定的潜在特征,它在 13 个靶点(target)或终点(endpoints)活性和无活性的抗 SARS-CoV-2 上很好的聚集,且 AUC 值均比另一种模型 Jure’s GNN 要高 12% 以上 ,体现出该模型的高精度和很强的泛化性。
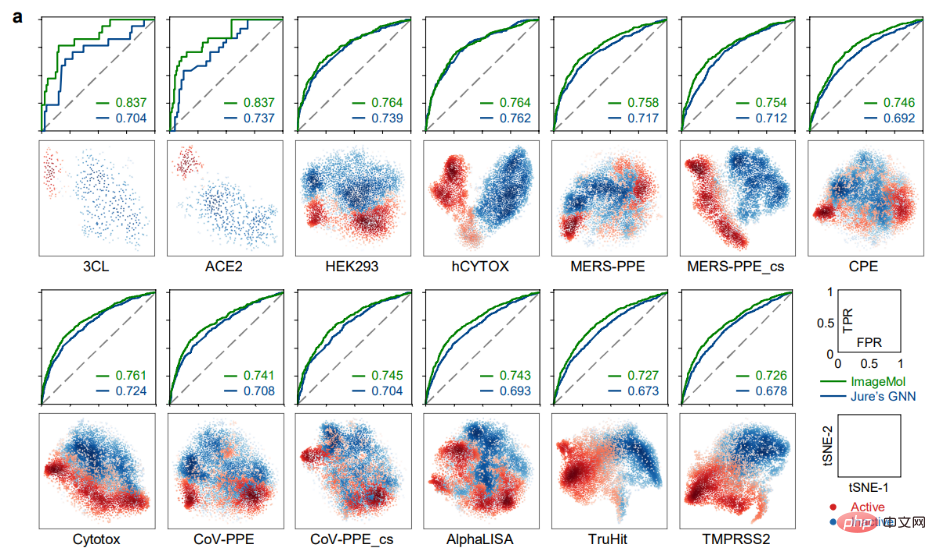
识别抗 SARS-CoV-2 抑制剂
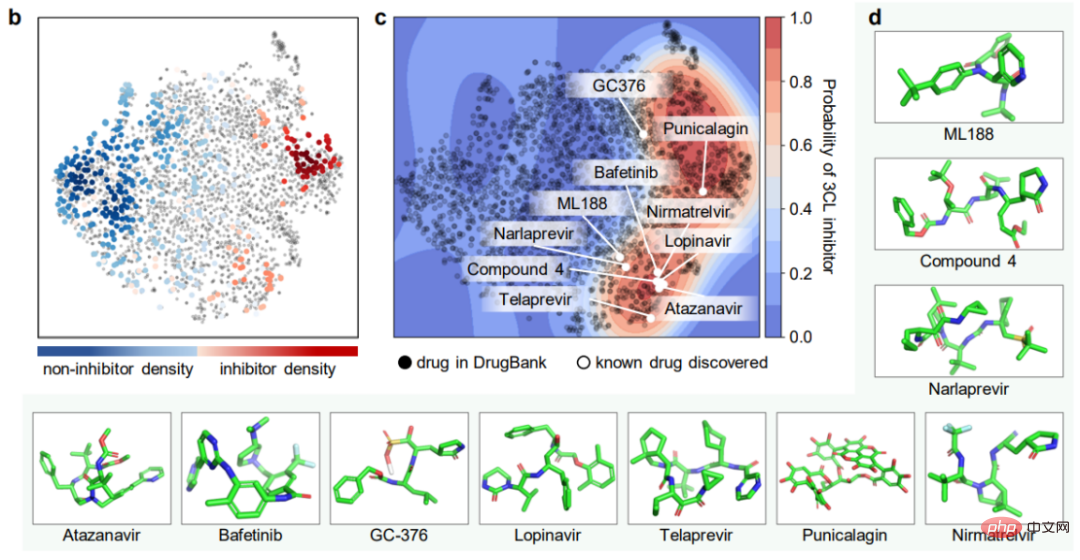
对药物分子研究关乎最直接的实验来了,利用 ImageMol 直接识别抑制剂分子!通过 ImageMol 框架下 3CL 蛋白酶(已被证实是治疗 COVID-19 的有希望的治疗发展靶点)抑制剂与非抑制剂数据集的分子图像表示,该研究发现 3CL 抑制剂和非抑制剂在 t-SNE 图中很好地分离,如下图 b 。
另外,ImageMol 鉴定出 16 种已知 3CL 蛋白酶抑制剂中的 10 种,并将这 10 种药物可视化到图中的包埋空间(成功率 62.5%),表明在抗 SARS-CoV-2 药物发现中具有较高的泛化能力。使用 HEY293 测定来预测抗 SARS-CoV-2 可再利用药物时,ImageMol 成功预测了 70 种药物中的 42 种(成功率为 60%),这表明 ImageMol 在推断 HEY293 测定中的潜在候选药物方面也具有很高的推广性。下图 c 展示了 ImageMol 在 DrugBank 数据集上发现 3CL 潜在抑制剂的药物。图 d 展示了 ImageMol 发现的 3CL 抑制剂的分子结构。
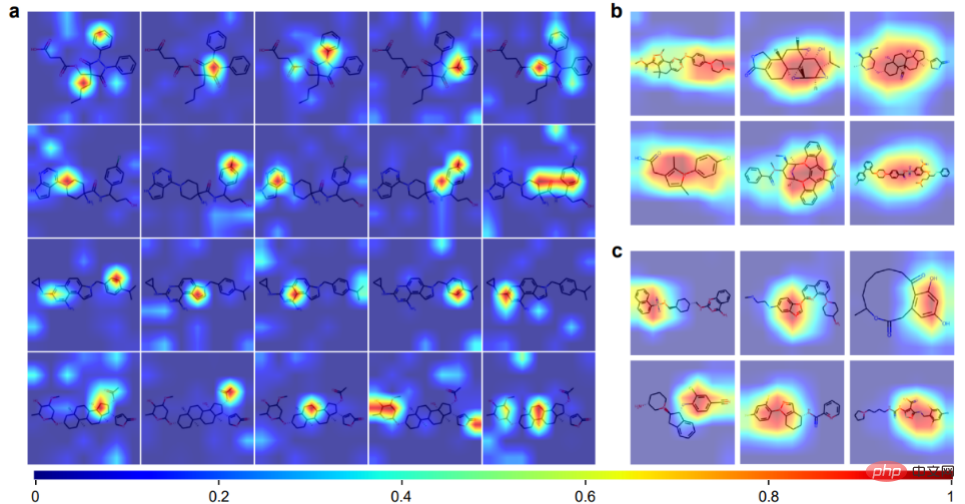
注意力可视化
ImageMol 可以从分子图像表示中获取化学信息的先验知识,包括 = O 键、-OH 键、-NH3 键和苯环。图 b 和 c 为 ImageMol 的 Grad-CAM 可视化的 12 个示例分子。这表示 ImageMol 同时准确地对全局 (b) 和局部 (c) 结构信息进行注意捕获,这些结果使研究人员能够在视觉上直观地理解分子结构是如何影响性质和靶点。
以上是介绍全球首个基于自监督学习的分子图像生成框架ImageMol的详细内容。更多信息请关注PHP中文网其他相关文章!

 烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PM
烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PMAI增强食物准备 在新生的使用中,AI系统越来越多地用于食品制备中。 AI驱动的机器人在厨房中用于自动化食物准备任务,例如翻转汉堡,制作披萨或组装SA
 Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM
Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM介绍 了解Python功能中变量的名称空间,范围和行为对于有效编写和避免运行时错误或异常至关重要。在本文中,我们将研究各种ASP
 视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM
视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM介绍 想象一下,穿过美术馆,周围是生动的绘画和雕塑。现在,如果您可以向每一部分提出一个问题并获得有意义的答案,该怎么办?您可能会问:“您在讲什么故事?
 联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM
联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM继续使用产品节奏,本月,Mediatek发表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。这些产品填补了Mediatek业务中更传统的部分,其中包括智能手机的芯片
 本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM
本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:现在是星期一早上。作为AI驱动的招聘人员,您更聪明,而不是更努力。您在手机上登录公司的仪表板。它告诉您三个关键角色已被采购,审查和计划的FO
 生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM我猜你一定是。 我们似乎都知道,心理障碍包括各种chat不休,这些chat不休,这些chat不休,混合了各种心理术语,并且常常是难以理解的或完全荒谬的。您需要做的一切才能喷出fo
 原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM
原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM根据本周发表的一项新研究,只有在2022年制造的塑料中,只有9.5%的塑料是由回收材料制成的。同时,塑料在垃圾填埋场和生态系统中继续堆积。 但是有帮助。一支恩金团队
 AI分析师的崛起:为什么这可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM
AI分析师的崛起:为什么这可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM我最近与领先的企业分析平台Alteryx首席执行官安迪·麦克米伦(Andy Macmillan)的对话强调了这一在AI革命中的关键但不足的作用。正如Macmillan所解释的那样,原始业务数据与AI-Ready Informat之间的差距


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

记事本++7.3.1
好用且免费的代码编辑器

Dreamweaver Mac版
视觉化网页开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

