



近几年,在 Transformer 的推动下,机器学习正在经历复兴。过去五年中,用于自然语言处理、计算机视觉以及其他领域的神经架构在很大程度上已被 transformer 所占据。
不过还有许多图像级生成模型仍然不受这一趋势的影响,例如过去一年扩散模型在图像生成方面取得了惊人的成果,几乎所有这些模型都使用卷积 U-Net 作为主干。这有点令人惊讶!在过去的几年中,深度学习的大事件一直是跨领域的 Transformer 的主导地位。U-Net 或卷积是否有什么特别之处使它们在扩散模型中表现得如此出色?
将 U-Net 主干网络首次引入扩散模型的研究可追溯到 Ho 等人,这种设计模式继承了自回归生成模型 PixelCNN++,只是稍微进行了一些改动。而 PixelCNN++ 由卷积层组成,其包含许多的 ResNet 块。其与标准的 U-Net 相比,PixelCNN++ 附加的空间自注意力块成为 transformer 中的基本组件。不同于其他人的研究,Dhariwal 和 Nichol 等人消除了 U-Net 的几种架构选择,例如使用自适应归一化层为卷积层注入条件信息和通道计数。
本文中来自 UC 伯克利的 William Peebles 以及纽约大学的谢赛宁撰文《 Scalable Diffusion Models with Transformers 》,目标是揭开扩散模型中架构选择的意义,并为未来的生成模型研究提供经验基线。该研究表明,U-Net 归纳偏置对扩散模型的性能不是至关重要的,并且可以很容易地用标准设计(如 transformer)取代。
这一发现表明,扩散模型可以从架构统一趋势中受益,例如,扩散模型可以继承其他领域的最佳实践和训练方法,保留这些模型的可扩展性、鲁棒性和效率等有利特性。标准化架构也将为跨领域研究开辟新的可能性。

- 论文地址:https://arxiv.org/pdf/2212.09748.pdf
- 项目地址:https://github.com/facebookresearch/DiT
- 论文主页:https://www.wpeebles.com/DiT
该研究专注于一类新的基于 Transformer 的扩散模型:Diffusion Transformers(简称 DiTs)。DiTs 遵循 Vision Transformers (ViTs) 的最佳实践,有一些小但重要的调整。DiT 已被证明比传统的卷积网络(例如 ResNet )具有更有效地扩展性。
具体而言,本文研究了 Transformer 在网络复杂度与样本质量方面的扩展行为。研究表明,通过在潜在扩散模型 (LDM) 框架下构建 DiT 设计空间并对其进行基准测试,其中扩散模型在 VAE 的潜在空间内进行训练,可以成功地用 transformer 替换 U-Net 主干。本文进一步表明 DiT 是扩散模型的可扩展架构:网络复杂性(由 Gflops 测量)与样本质量(由 FID 测量)之间存在很强的相关性。通过简单地扩展 DiT 并训练具有高容量主干(118.6 Gflops)的 LDM,可以在类条件 256 × 256 ImageNet 生成基准上实现 2.27 FID 的最新结果。
Diffusion Transformers
DiTs 是一种用于扩散模型的新架构,目标是尽可能忠实于标准 transformer 架构,以保留其可扩展性。DiT 保留了 ViT 的许多最佳实践,图 3 显示了完整 DiT 体系架构。
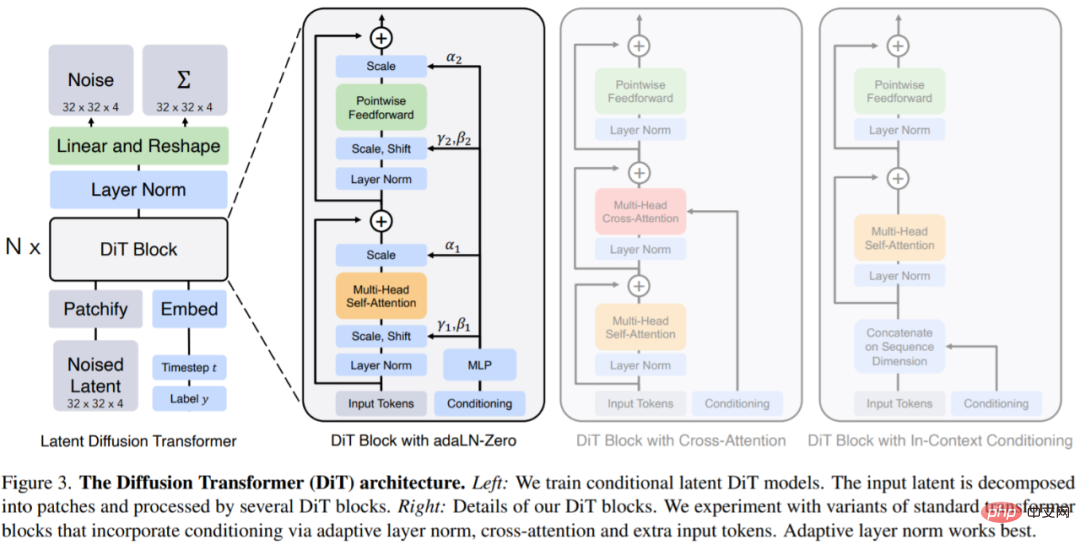
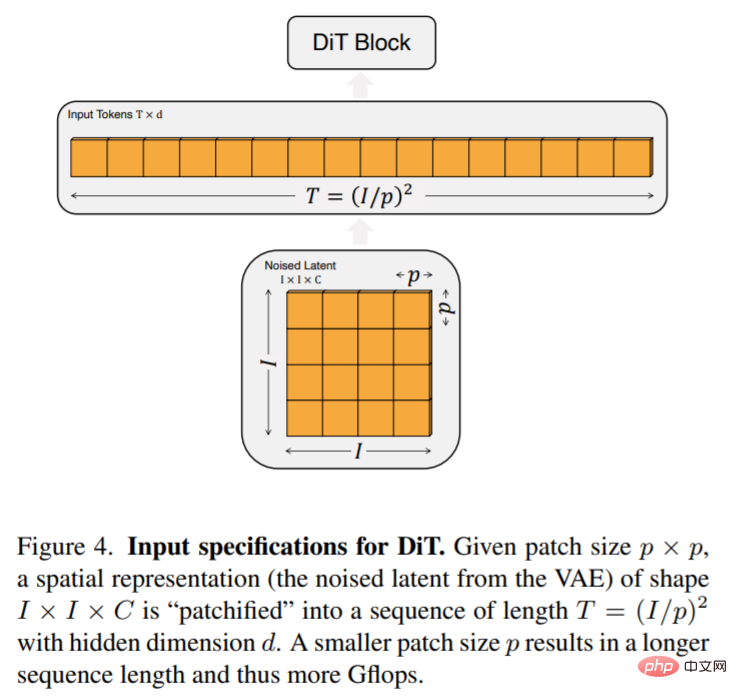
DiT 的输入为空间表示 z(对于 256 × 256 × 3 图像,z 的形状为 32 × 32 × 4)。DiT 的第一层是 patchify,该层通过将每个 patch 线性嵌入到输入中,以此将空间输入转换为一个 T token 序列。patchify 之后,本文将标准的基于 ViT 频率的位置嵌入应用于所有输入 token。
patchify 创建的 token T 的数量由 patch 大小超参数 p 决定。如图 4 所示,将 p 减半将使 T 翻四倍,因此至少能使 transformer Gflops 翻四倍。本文将 p = 2,4,8 添加到 DiT 设计空间。
DiT 块设计:在 patchify 之后,输入 token 由一系列 transformer 块处理。除了噪声图像输入之外,扩散模型有时还会处理额外的条件信息,例如噪声时间步长 t、类标签 c、自然语言等。本文探索了四种以不同方式处理条件输入的 transformer 块变体。这些设计对标准 ViT 块设计进行了微小但重要的修改。所有模块的设计如图 3 所示。
本文尝试了四种因模型深度和宽度而异的配置:DiT-S、DiT-B、DiT-L 和 DiT-XL。这些模型配置范围从 33M 到 675M 参数,Gflops 从 0.4 到 119 。
实验
研究者训练了四个最高 Gflop 的 DiT-XL/2 模型,每个模型使用不同的 block 设计 ——in-context(119.4Gflops)、cross-attention(137.6Gflops)、adaptive layer norm(adaLN,118.6Gflops)或 adaLN-zero(118.6Gflops)。然后在训练过程中测量 FID,图 5 为结果。
扩展模型大小和 patch 大小。图 2(左)给出了每个模型的 Gflops 和它们在 400K 训练迭代时的 FID 概况。可以发现,增加模型大小和减少 patch 大小会对扩散模型产生相当大的改进。
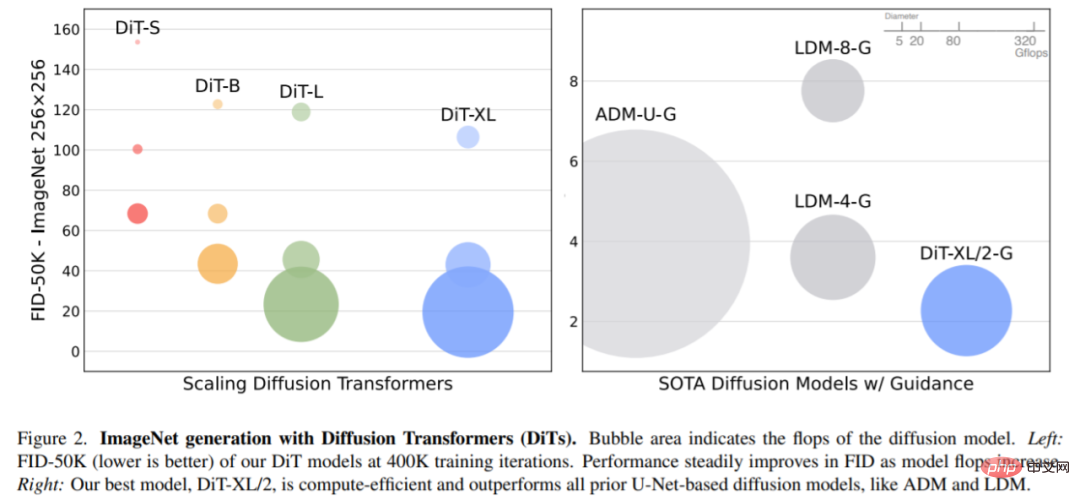
图 6(顶部)展示了 FID 是如何随着模型大小的增加和 patch 大小保持不变而变化的。在四种设置中,通过使 Transformer 更深、更宽,训练的所有阶段都获得了 FID 的明显提升。同样,图 6(底部)展示了 patch 大小减少和模型大小保持不变时的 FID。研究者再次观察到,在整个训练过程中,通过简单地扩大 DiT 处理的 token 数量,并保持参数的大致固定,FID 会得到相当大的改善。
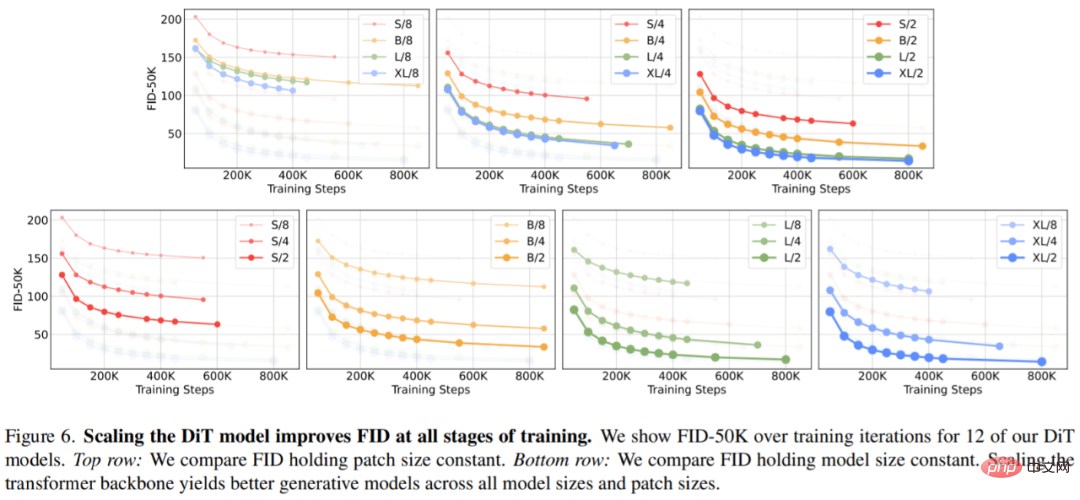
图 8 中展示了 FID-50K 在 400K 训练步数下与模型 Gflops 的对比:
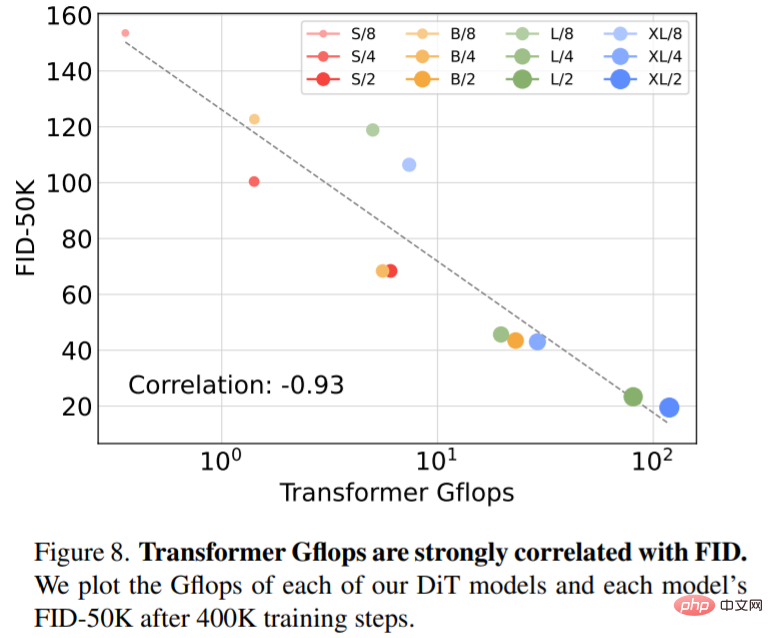
SOTA 扩散模型 256×256 ImageNet。在对扩展分析之后,研究者继续训练最高 Gflop 模型 DiT-XL/2,步数为 7M。图 1 展示了该模型的样本,并与类别条件生成 SOTA 模型进行比较,表 2 中展示了结果。

当使用无分类器指导时,DiT-XL/2 优于之前所有的扩散模型,将之前由 LDM 实现的 3.60 的最佳 FID-50K 降至 2.27。如图 2(右)所示,相对于 LDM-4(103.6 Gflops)这样的潜在空间 U-Net 模型来说,DiT-XL/2(118.6 Gflops)计算效率高得多,也比 ADM(1120 Gflops)或 ADM-U(742 Gflops)这样的像素空间 U-Net 模型效率高很多。
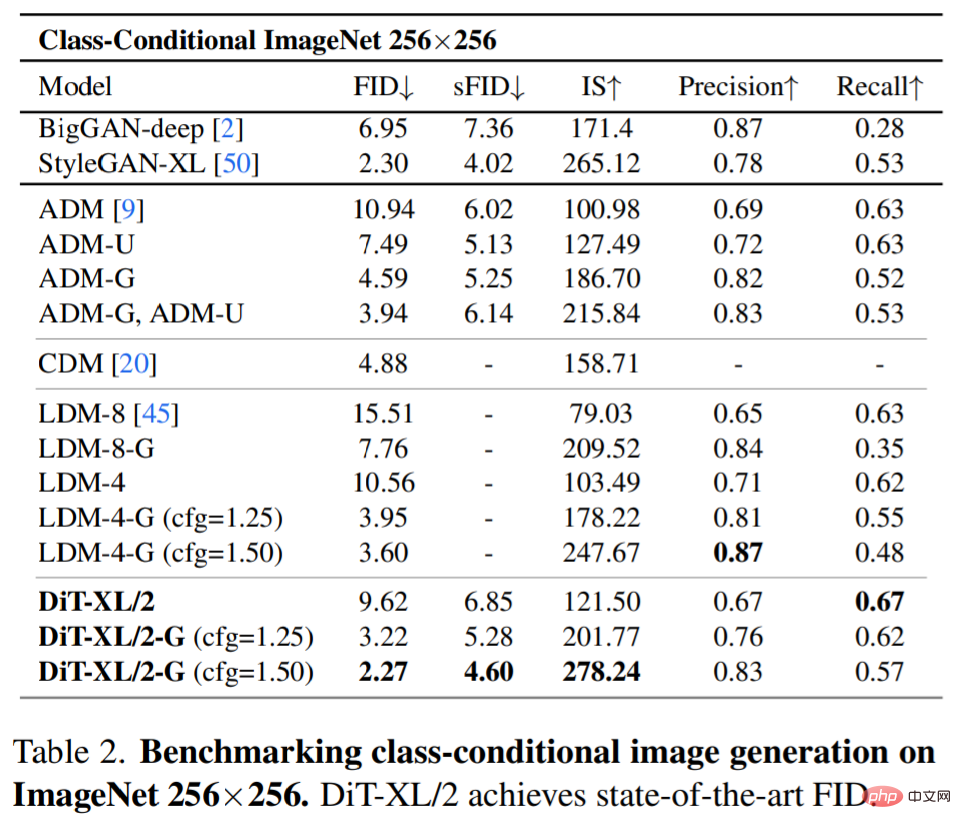
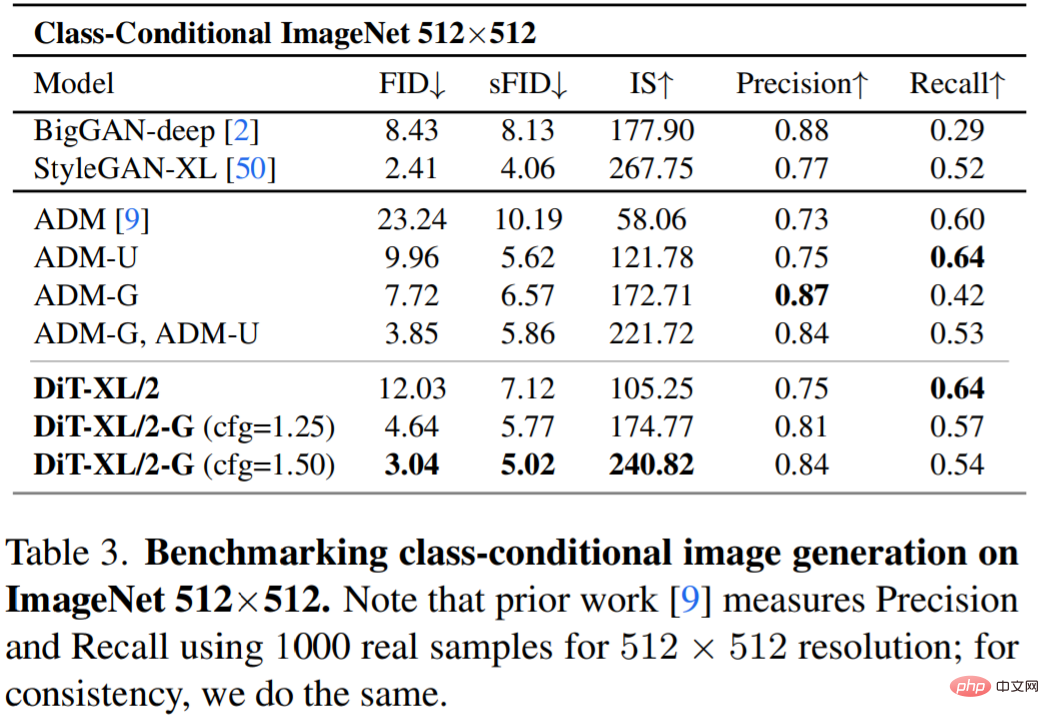
表 3 展示了与 SOTA 方法的比较。XL/2 在这一分辨率下再次胜过之前的所有扩散模型,将 ADM 之前取得的 3.85 的最佳 FID 提高到 3.04。
更多研究细节,可参考原论文。
以上是从U-Net到DiT:Transformer技术在统治扩散模型中的应用的详细内容。更多信息请关注PHP中文网其他相关文章!

 让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM
让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM科学家已经广泛研究了人类和更简单的神经网络(如秀丽隐杆线虫中的神经网络),以了解其功能。 但是,出现了一个关键问题:我们如何使自己的神经网络与新颖的AI一起有效地工作
 新的Google泄漏揭示了双子AI的订阅更改Apr 27, 2025 am 11:08 AM
新的Google泄漏揭示了双子AI的订阅更改Apr 27, 2025 am 11:08 AMGoogle的双子座高级:新的订阅层即将到来 目前,访问Gemini Advanced需要$ 19.99/月Google One AI高级计划。 但是,Android Authority报告暗示了即将发生的变化。 最新的Google P中的代码
 数据分析加速度如何求解AI的隐藏瓶颈Apr 27, 2025 am 11:07 AM
数据分析加速度如何求解AI的隐藏瓶颈Apr 27, 2025 am 11:07 AM尽管围绕高级AI功能炒作,但企业AI部署中潜伏的巨大挑战:数据处理瓶颈。首席执行官庆祝AI的进步时,工程师努力应对缓慢的查询时间,管道超载,一个
 Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP可以将任何文档转换为Markdowns!Apr 27, 2025 am 09:47 AM处理文档不再只是在您的AI项目中打开文件,而是将混乱变成清晰度。诸如PDF,PowerPoints和Word之类的文档以各种形状和大小淹没了我们的工作流程。检索结构化
 如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM
如何使用Google ADK进行建筑代理? - 分析VidhyaApr 27, 2025 am 09:42 AM利用Google的代理开发套件(ADK)的力量创建具有现实世界功能的智能代理!该教程通过使用ADK来构建对话代理,并支持Gemini和GPT等各种语言模型。 w
 在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM
在LLM上使用SLM进行有效解决问题-Analytics VidhyaApr 27, 2025 am 09:27 AM摘要: 小型语言模型 (SLM) 专为效率而设计。在资源匮乏、实时性和隐私敏感的环境中,它们比大型语言模型 (LLM) 更胜一筹。 最适合专注型任务,尤其是在领域特异性、控制性和可解释性比通用知识或创造力更重要的情况下。 SLM 并非 LLMs 的替代品,但在精度、速度和成本效益至关重要时,它们是理想之选。 技术帮助我们用更少的资源取得更多成就。它一直是推动者,而非驱动者。从蒸汽机时代到互联网泡沫时期,技术的威力在于它帮助我们解决问题的程度。人工智能 (AI) 以及最近的生成式 AI 也不例
 如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM
如何将Google Gemini模型用于计算机视觉任务? - 分析VidhyaApr 27, 2025 am 09:26 AM利用Google双子座的力量用于计算机视觉:综合指南 领先的AI聊天机器人Google Gemini扩展了其功能,超越了对话,以涵盖强大的计算机视觉功能。 本指南详细说明了如何利用
 Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:Google可以比OpenAI更好吗?Apr 27, 2025 am 09:20 AM2025年的AI景观正在充满活力,而Google的Gemini 2.0 Flash和Openai的O4-Mini的到来。 这些尖端的车型分开了几周,具有可比的高级功能和令人印象深刻的基准分数。这个深入的比较


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Dreamweaver CS6
视觉化网页开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

Atom编辑器mac版下载
最流行的的开源编辑器

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

