



DALL-E 2刚发布的时候,生成的画作几乎能完美复现输入的文本,高清的分辨率、强大的绘图脑洞也是让各路网友直呼「太炫酷」。

但最近哈佛大学的一份新研究论文表明,尽管DALL-E 2生成的图像很精致,但它可能只是把文本中的几个实体粘合在一起,甚至都没有理解文本中表述的空间关系!

论文链接:https://arxiv.org/pdf/2208.00005.pdf
数据链接:https://osf.io/sm68h/
比如说给出一句文本提示为「A cup on a spoon」,可以看到DALL-E 2生成的图像中,可以看到有部分图像就没有满足「on」关系。
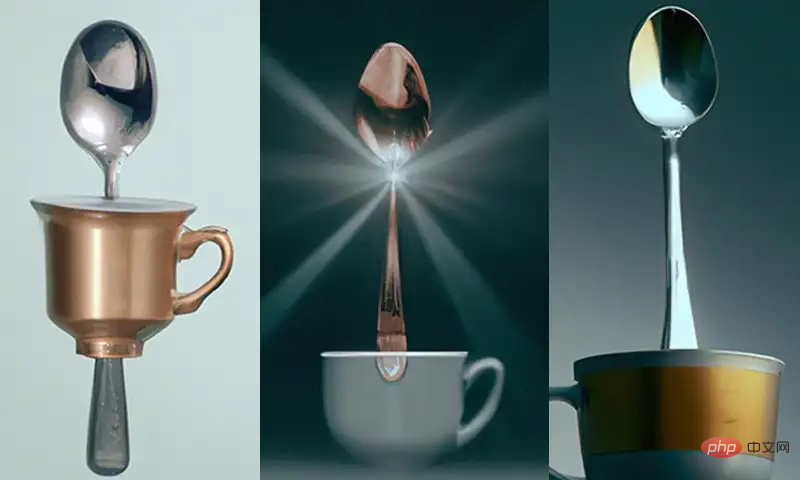
但在训练集中,DALL-E 2可能见到的茶杯和勺子的组合都是「in」,而「on」则比较少见,所以在两种关系的生成上,准确率也并不相同。

所以为了探究DALL-E 2是否真的能理解文本中的语义关系,研究人员选择了15类关系,其中8个为空间关系(physical relation),包括in, on, under, covering, near, occluded by, hanging over和tied to;7个动作关系(agentic relation),包括pushing, pulling, touching, hitting, kicking, helping和hindering.
文本中的实体集合限制为12个,选取的都是简单的、各个数据集中常见的物品,分别为:box, cylinder, blanket, bowl, teacup, knife; man, woman, child, robot, monkey和iguana(鬣蜥).

对于每类关系,创建5个prompts,每次随机选择2个实体进行替换,最终生成75个文本提示。提交到DALL-E 2渲染引擎后,选择前18张生成图像,最终获得1350张图像。
随后研究人员从180名标注人员中通过常识推理测试选拔出169名参与到标注的过程。
实验结果发现,DALL-E 2生成的图像和用于生成图像的文本提示之间一致性的平均值在75个prompt中仅为22.2%
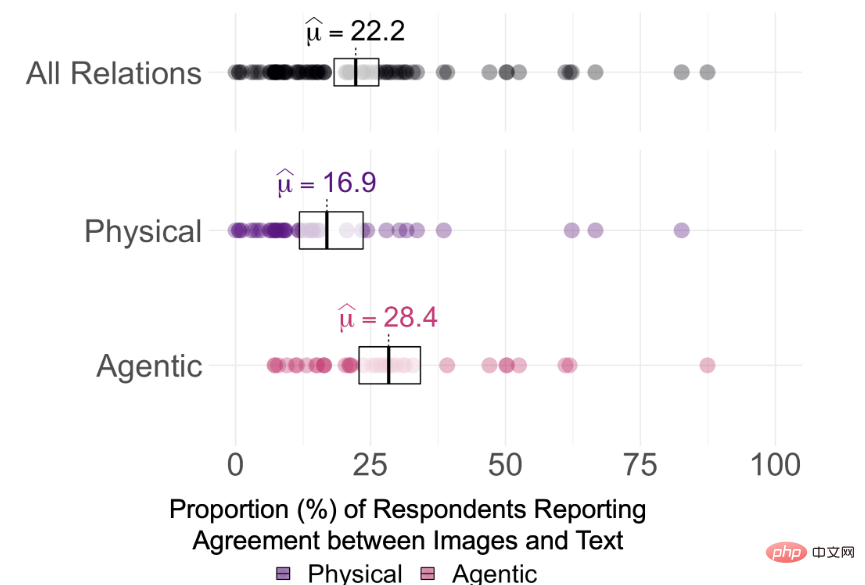
不过很难说DALL-E 2到底是否真正「理解」了文本中的关系,通过观察标注人员的一致性评分,按照0%、25%和50%的一致同意阈值来看,对每个关系进行的Holm-corrected的单样本显著性检验表明,所有15个关系的参与者同意率在α = 0.95(pHolm
所以即使不对多重比较进行校正,事实就是DALL-E 2生成的图像并不能理解文本中两个物体的关系。
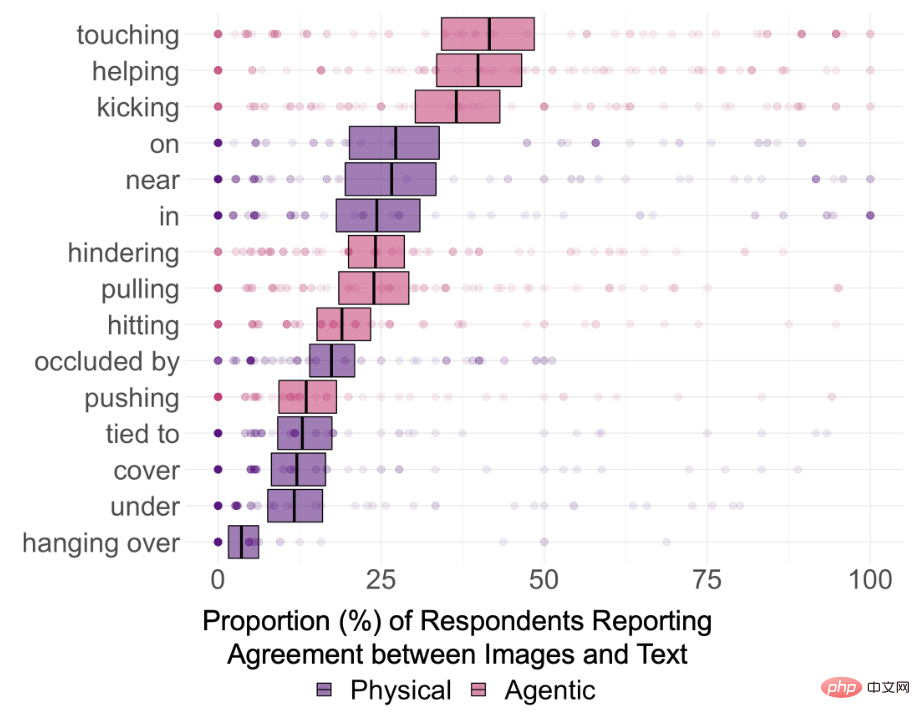
结果还表明,DALL-E在把两个不相关物体联系在一起的能力可能没有想象中那么强,比如说「A child touching a bowl」的一致性达到了87%,因为在现实世界中的图像,孩子和碗出现在一起的频率很高。

而「A monkey touching an iguana」生成的图像,最终一致率只有11%,而且在渲染出来的图像中甚至会出现物种错误。

所以DALL-E 2中的图像部分类别是开发较完善的,比如孩子与食物,但有些类别的数据中还需要继续训练。
不过当前DALL-E 2在官网上还是主要展示其高清晰度和写实风格,还没有搞清楚其内在到底是把两个物体「粘在一起」,还是真正理解文本信息后再进行图像生成。
研究人员表示,关系理解是人类智力的基本组成部分,DALL-E 2在基本的空间关系方面表现不佳(例如on,of)表明,它还无法像人类一样如此灵活、稳健地构建和理解这个世界。
不过网友表示,能开发出「胶水」把东西粘在一起已经是一个相当伟大的成就了!DALL-E 2并非AGI,未来仍然有很大的进步空间,至少我们已经开启了自动化生成图像的大门!
DALL-E 2还有啥问题?
实际上,DALL-E 2一发布,就有大量的从业者对其优点与缺陷进行了深入剖析。

博客链接:https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot-do
用GPT-3写小说略显单调,DALL-E 2可以为文本生成一些插图,甚至对长文本生成连环画。
比如说DALL-E 2可以为图片增加特征,如「A woman at a coffeeshop working on her laptop and wearing headphones, painting by Alphonse Mucha」,可以精确生成绘画风格、咖啡店、戴耳机、笔记本电脑,等等。

但如果文本中的特征描述涉及两个人,DALL-E 2可能就会忘了哪些特征属于哪个人物,比如输入文本为:
a young dark-haired boy resting in bed, and a grey-haired older woman sitting in a chair beside the bed underneath a window with sun streaming through, Pixar style digital art.
一个年轻的黑发男孩躺在床上,一个灰头发的老妇坐在窗户下面的床旁边的椅子上,阳光穿过,皮克斯风格的数字艺术。

可以看到,DALL-E 2可以正确生成窗户、椅子和床,但在年龄、性别和头发颜色的特征组合上,生成的图像略显迷茫。
另一个例子是让「美国队长和钢铁侠并排站」,可以看到生成的结果很明显具有美国队长和钢铁侠的特征,但具体的元素却安在了不同的人身上(比如钢铁侠带着美国队长的盾牌)。

如果是特别细节的前景与背景,模型可能也无法生成。
比如输入文本是:
Two dogs dressed like roman soldiers on a pirate ship looking at New York City through a spyglass.
两只狗在海盗船上像罗马士兵一样用小望远镜看纽约市。
这回DALL-E 2直接就罢工了,博文作者花了半个小时也没搞定,最终需要在「纽约市和海盗船」或「带着望远镜、穿着罗马士兵制服的狗」之间进行选择。
Dall-E 2可以使用通用的背景来生成图像,比如城市、图书馆中的书架,但如果这不是图像的主要重点,那么想要获得更细的细节往往会变得非常难。
尽管DALL-E 2能生成常见的物体,比如各种花里胡哨的椅子,但要是让它生成一个「奥拓自行车」,结果生成的图片和自行车有点像,又不完全是。

而谷歌图片下搜索的Otto Bicycle则是下面这样的。

DALL-E 2也无法拼写,但偶尔也会完全巧合地正确拼写出一个单词,比如让它在停车标志上写下STOP
虽然模型确实能生成一些「可识别」的英语字母,但连起来的语义和预期的单词还有差别,这也是DALL-E 2不如第一代DALL-E的地方。

在生成乐器相关的图像时,DALL-E 2似乎是记住了人手在演奏时的位置,但没有琴弦,演奏起来稍显尴尬。

DALL-E 2还提供了一个编辑功能,比如生成一个图像后,可以使用光标突出显示其区域,并添加修改的完整说明即可。
但这项功能并非一直有效,比如想给原图加个「短发」,编辑功能总是能在奇怪的地方加点东西。

技术还在不断更新发展,期待DALL-E 3!
以上是哈佛大学砸场子:DALL-E 2只是「粘合怪」,生成正确率只有22%的详细内容。更多信息请关注PHP中文网其他相关文章!

 烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PM
烹饪创新:人工智能如何改变食品服务Apr 12, 2025 pm 12:09 PMAI增强食物准备 在新生的使用中,AI系统越来越多地用于食品制备中。 AI驱动的机器人在厨房中用于自动化食物准备任务,例如翻转汉堡,制作披萨或组装SA
 Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM
Python名称空间和可变范围的综合指南Apr 12, 2025 pm 12:00 PM介绍 了解Python功能中变量的名称空间,范围和行为对于有效编写和避免运行时错误或异常至关重要。在本文中,我们将研究各种ASP
 视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM
视觉语言模型(VLMS)的综合指南Apr 12, 2025 am 11:58 AM介绍 想象一下,穿过美术馆,周围是生动的绘画和雕塑。现在,如果您可以向每一部分提出一个问题并获得有意义的答案,该怎么办?您可能会问:“您在讲什么故事?
 联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM
联发科技与kompanio Ultra和Dimenty 9400增强优质阵容Apr 12, 2025 am 11:52 AM继续使用产品节奏,本月,Mediatek发表了一系列公告,包括新的Kompanio Ultra和Dimenty 9400。这些产品填补了Mediatek业务中更传统的部分,其中包括智能手机的芯片
 本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM
本周在AI:沃尔玛在时尚趋势之前设定了时尚趋势Apr 12, 2025 am 11:51 AM#1 Google推出了Agent2Agent 故事:现在是星期一早上。作为AI驱动的招聘人员,您更聪明,而不是更努力。您在手机上登录公司的仪表板。它告诉您三个关键角色已被采购,审查和计划的FO
 生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM
生成的AI遇到心理摩托车Apr 12, 2025 am 11:50 AM我猜你一定是。 我们似乎都知道,心理障碍包括各种chat不休,这些chat不休,这些chat不休,混合了各种心理术语,并且常常是难以理解的或完全荒谬的。您需要做的一切才能喷出fo
 原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM
原型:科学家将纸变成塑料Apr 12, 2025 am 11:49 AM根据本周发表的一项新研究,只有在2022年制造的塑料中,只有9.5%的塑料是由回收材料制成的。同时,塑料在垃圾填埋场和生态系统中继续堆积。 但是有帮助。一支恩金团队
 AI分析师的崛起:为什么这可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM
AI分析师的崛起:为什么这可能是AI革命中最重要的工作Apr 12, 2025 am 11:41 AM我最近与领先的企业分析平台Alteryx首席执行官安迪·麦克米伦(Andy Macmillan)的对话强调了这一在AI革命中的关键但不足的作用。正如Macmillan所解释的那样,原始业务数据与AI-Ready Informat之间的差距


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Atom编辑器mac版下载
最流行的的开源编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

