



梯度提升算法是最常用的集成机器学习技术之一,该模型使用弱决策树序列来构建强学习器。这也是XGBoost和LightGBM模型的理论基础,所以在这篇文章中,我们将从头开始构建一个梯度增强模型并将其可视化。
梯度提升算法介绍
梯度提升算法(Gradient Boosting)是一种集成学习算法,它通过构建多个弱分类器,然后将它们组合成一个强分类器来提高模型的预测准确率。
梯度提升算法的原理可以分为以下几个步骤:
- 初始化模型:一般来说,我们可以使用一个简单的模型(比如说决策树)作为初始的分类器。
- 计算损失函数的负梯度:计算出每个样本点在当前模型下的损失函数的负梯度。这相当于是让新的分类器去拟合当前模型下的误差。
- 训练新的分类器:用这些负梯度作为目标变量,训练一个新的弱分类器。这个弱分类器可以是任意的分类器,比如说决策树、线性模型等。
- 更新模型:将新的分类器加入到原来的模型中,可以用加权平均或者其他方法将它们组合起来。
- 重复迭代:重复上述步骤,直到达到预设的迭代次数或者达到预设的准确率。
由于梯度提升算法是一种串行算法,所以它的训练速度可能会比较慢,我们以一个实际的例子来介绍:
假设我们有一个特征集Xi和值Yi,要计算y的最佳估计

我们从y的平均值开始

每一步我们都想让F_m(x)更接近y|x。

在每一步中,我们都想要F_m(x)一个更好的y给定x的近似。
首先,我们定义一个损失函数
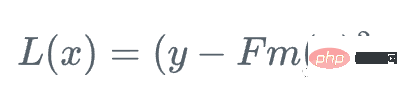
然后,我们向损失函数相对于学习者Fm下降最快的方向前进:
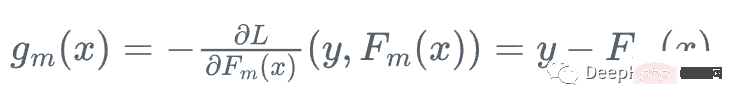
因为我们不能为每个x计算y,所以不知道这个梯度的确切值,但是对于训练数据中的每一个x_i,梯度完全等于步骤m的残差:r_i!
所以我们可以用弱回归树h_m来近似梯度函数g_m,对残差进行训练:
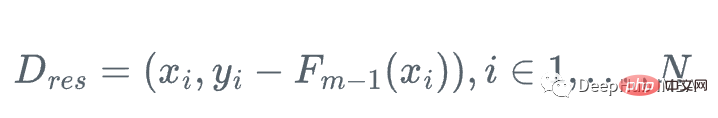
然后,我们更新学习器
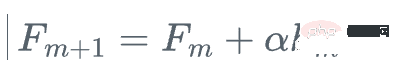
这就是梯度提升,我们不是使用损失函数相对于当前学习器的真实梯度g_m来更新当前学习器F_{m},而是使用弱回归树h_m来更新它。

也就是重复下面的步骤
1、计算残差:

2、将回归树h_m拟合到训练样本及其残差(x_i, r_i)上
3、用步长alpha更新模型

看着很复杂对吧,下面我们可视化一下这个过程就会变得非常清晰了
决策过程可视化
这里我们使用sklearn的moons 数据集,因为这是一个经典的非线性分类数据
import numpy as np import sklearn.datasets as ds import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import tree from itertools import product,islice import seaborn as snsmoonDS = ds.make_moons(200, noise = 0.15, random_state=16) moon = moonDS[0] color = -1*(moonDS[1]*2-1) df =pd.DataFrame(moon, columns = ['x','y']) df['z'] = color df['f0'] =df.y.mean() df['r0'] = df['z'] - df['f0'] df.head(10)
让我们可视化数据:
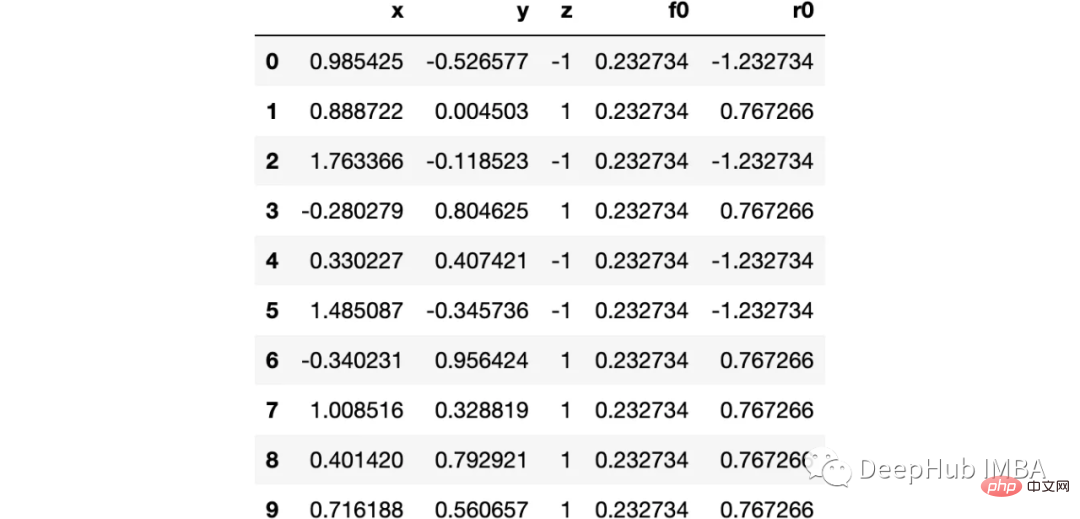
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。
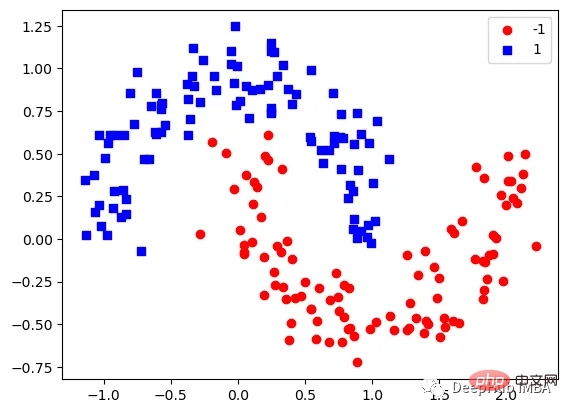
那么我们先编写一个简单的梯度增强模型:
def makeiteration(i:int):
"""Takes the dataframe ith f_i and r_i and approximated r_i from the features, then computes f_i+1 and r_i+1"""
clf = tree.DecisionTreeRegressor(max_depth=1)
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)
eta = 0.9
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']
df[f'r{i}'] = df['z'] - df[f'f{i}']
rmse = (df[f'r{i}']**2).sum()
clfs.append(clf)
rmses.append(rmse)上面代码执行3个简单步骤:
将决策树与残差进行拟合:
clf.fit(X=df[['x','y']].values, y = df[f'r{i-1}'])
df[f'r{i-1}hat'] = clf.predict(df[['x','y']].values)然后,我们将这个近似的梯度与之前的学习器相加:
df[f'f{i}'] = df[f'f{i-1}'] + eta*df[f'r{i-1}hat']最后重新计算残差:
df[f'r{i}'] = df['z'] - df[f'f{i}']步骤就是这样简单,下面我们来一步一步执行这个过程。
第1次决策

Tree Split for 0 and level 1.563690960407257

第2次决策
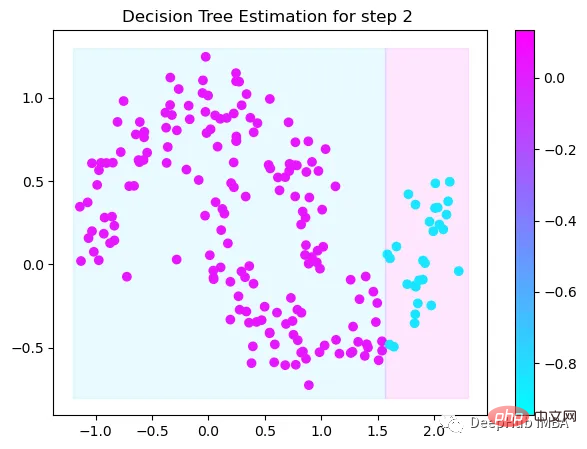
Tree Split for 1 and level 0.5143677890300751
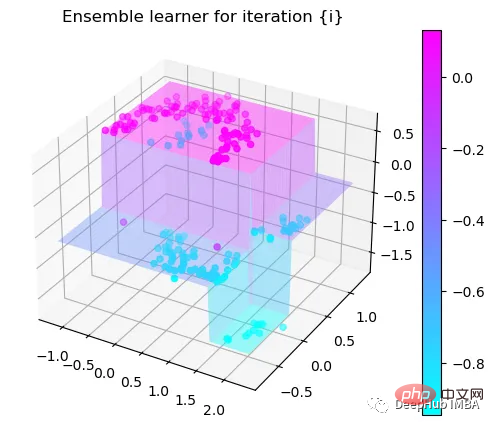
第3次决策
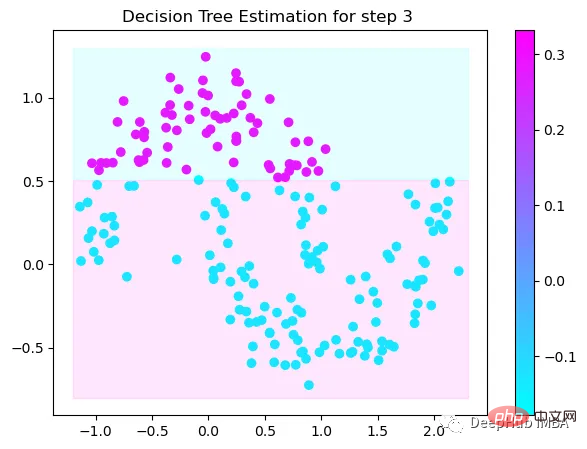
Tree Split for 0 and level -0.6523728966712952

第4次决策

Tree Split for 0 and level 0.3370491564273834

第5次决策

Tree Split for 0 and level 0.3370491564273834

第6次决策

Tree Split for 1 and level 0.022058885544538498

第7次决策

Tree Split for 0 and level -0.3030575215816498

第8次决策

Tree Split for 0 and level 0.6119407713413239

第9次决策

可以看到通过9次的计算,基本上已经把上面的分类进行了区分

我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
plt.plot(rmses)

这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
https://www.php.cn/link/bfc89c3ee67d881255f8b097c4ed2d67
以上是梯度提升算法决策过程的逐步可视化的详细内容。更多信息请关注PHP中文网其他相关文章!

![[带AI的吉卜力风格图像]介绍如何使用Chatgpt和版权创建免费图像](https://img.php.cn/upload/article/001/242/473/174707263295098.jpg?x-oss-process=image/resize,p_40) [带AI的吉卜力风格图像]介绍如何使用Chatgpt和版权创建免费图像May 13, 2025 am 01:57 AM
[带AI的吉卜力风格图像]介绍如何使用Chatgpt和版权创建免费图像May 13, 2025 am 01:57 AMOpenAI发布的最新模型GPT-4o,不仅能生成文本,还具备图像生成功能,引发广泛关注。其中最受瞩目的功能便是“吉卜力风格插画”的生成。只需将照片上传至ChatGPT,并给出简单的指令,即可生成宛如吉卜力工作室作品般梦幻的图像。本文将详细解读实际操作流程、效果感受,以及需要注意的错误和版权问题。 OpenAI发布的最新模型“o3”详情请点击此处⬇️ OpenAI o3(ChatGPT o3)详解:特性、定价体系及o4-mini介绍 吉卜力风格文章的英文版请点击此处⬇️ 利用ChatGPT创作吉
 解释在地方政府中使用和实施CANTGPT的示例!还介绍了禁止的地方政府May 13, 2025 am 01:53 AM
解释在地方政府中使用和实施CANTGPT的示例!还介绍了禁止的地方政府May 13, 2025 am 01:53 AM作为一种新的交流方法,在地方政府中使用和引入Chatgpt引起了人们的关注。尽管这种趋势在广泛的领域正在发展,但一些地方政府拒绝使用Chatgpt。 在本文中,我们将介绍地方政府中ChatGPT实施的示例。我们将通过各种改革实例,包括支持文件创建和与公民对话,从而探索如何通过各种改革实例来实现地方政府服务的质量和效率提高。 不仅旨在减少员工工作量并改善公民的便利性的地方政府官员,而且都对高级用例感兴趣。
 chatgpt中的福卡式风格提示是什么?示例句子的详尽解释!May 13, 2025 am 01:52 AM
chatgpt中的福卡式风格提示是什么?示例句子的详尽解释!May 13, 2025 am 01:52 AM您是否听说过一个名为“福卡斯提示系统”的框架?诸如ChatGpt之类的语言模型非常出色,但是适当的提示对于发挥其潜力至关重要。福卡(Fukatsu)提示是旨在提高输出准确性的最受欢迎的提示技术之一。 本文解释了福卡式风格提示的原理和特征,包括特定的用法方法和示例。此外,我们还引入了其他众所周知的及时模板和有用的技术来及时设计,因此,根据这些设计,我们将介绍C。
 什么是chatgpt搜索?解释主要功能,用法和费用结构!May 13, 2025 am 01:51 AM
什么是chatgpt搜索?解释主要功能,用法和费用结构!May 13, 2025 am 01:51 AMCHATGPT搜索:使用创新的AI搜索引擎有效获取最新信息! 在本文中,我们将彻底解释OpenAI提供的新的ChatGpt功能“ ChatGpt搜索”。让我们仔细研究一下功能,用法以及该工具如何根据实时网络信息和直观的易用性来帮助您提高信息收集效率。 chatgpt搜索提供了一种对话互动搜索体验,该体验在舒适,隐藏的环境中回答用户问题,以隐藏广告
 易于理解的解释如何在Chatgpt和提示中创建构图!May 13, 2025 am 01:50 AM
易于理解的解释如何在Chatgpt和提示中创建构图!May 13, 2025 am 01:50 AM信息爆炸的现代社会,创作出令人信服的文章并非易事。如何在有限的时间和精力内,发挥创造力,撰写出吸引读者的文章,需要高超的技巧和丰富的经验。 这时,作为革命性的写作辅助工具,ChatGPT 备受瞩目。ChatGPT 利用庞大的数据训练出的语言生成模型,能够生成自然流畅、精炼的文章。 本文将介绍如何有效利用 ChatGPT,高效创作高质量文章的技巧。我们将逐步讲解使用 ChatGPT 的写作流程,并结合具体案例,详细阐述其优缺点、适用场景以及安全使用注意事项。ChatGPT 将成为作家克服各种障碍,
 如何使用chatgpt创建图!还解释了插图的加载和插件May 13, 2025 am 01:49 AM
如何使用chatgpt创建图!还解释了插图的加载和插件May 13, 2025 am 01:49 AM使用AI创建图表的有效指南 视觉材料对于有效传达信息至关重要,但是创建它需要大量时间和精力。但是,由于AI技术(例如Chatgpt和dall-e 3)的兴起,图表创建过程正在发生巨大变化。本文使用这些尖端工具提供了有关有效而有吸引力的图创建方法的详细说明。它涵盖了从想法到完成的所有内容,并包含大量信息,可用于创建图表,从可以使用的特定步骤,提示,插件和API以及如何使用图像一代AI“ dall-e 3.”)
 易于理解的解释Chatgpt加上定价结构和付款方式!May 13, 2025 am 01:48 AM
易于理解的解释Chatgpt加上定价结构和付款方式!May 13, 2025 am 01:48 AM解锁ChatGPT Plus:费用、支付方式及升级指南 全球瞩目的顶尖生成式AI,ChatGPT已广泛应用于日常生活和商业领域。虽然ChatGPT基本免费,但付费版ChatGPT Plus提供多种增值服务,例如插件、图像识别等,显着提升工作效率。本文将详细解读ChatGPT Plus的收费标准、支付方式及升级流程。 OpenAI最新图像生成技术“GPT-4o图像生成”详情请点击: GPT-4o图像生成详解:使用方法、提示词示例、商业应用及与其他AI的差异 目录 ChatGPT Plus费用 Ch
 解释如何使用chatgpt创建设计!我们还介绍了使用和提示示例May 13, 2025 am 01:47 AM
解释如何使用chatgpt创建设计!我们还介绍了使用和提示示例May 13, 2025 am 01:47 AM如何使用Chatgpt简化您的设计工作并提高创造力 本文将详细说明如何使用ChatGpt创建设计。我们将介绍在各个设计领域中使用Chatgpt的示例,例如思想,文本生成和网页设计。我们还将介绍点,以帮助您提高各种创意作品的效率和质量,例如图形设计,插图和徽标设计。请看一下AI如何大大扩展您的设计可能性。 目录 chatgpt:设计创建的强大工具


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

记事本++7.3.1
好用且免费的代码编辑器

