



Spark 是一种专门用于交互式查询、机器学习和实时工作负载的开源框架,而 PySpark 是 Python 使用 Spark 的库。
PySpark 是一种用于大规模执行探索性数据分析、构建机器学习管道以及为数据平台创建 ETL 的出色语言。如果你已经熟悉 Python 和 Pandas 等库,那么 PySpark 是一种很好的学习语言,可以创建更具可扩展性的分析和管道。
这篇文章的目的是展示如何使用 PySpark 构建机器学习模型。
Conda 创建 python 虚拟环境
conda将几乎所有的工具、第三方包都当作package进行管理,甚至包括python 和conda自身。Anaconda是一个打包的集合,里面预装好了conda、某个版本的python、各种packages等。
1.安装Anaconda。
打开命令行输入conda -V检验是否安装及当前conda的版本。
通过Anaconda安装默认版本的Python,3.6的对应的是 Anaconda3-5.2,5.3以后的都是python 3.7。
(https://repo.anaconda.com/archive/)
2.conda常用的命令
1) 查看安装了哪些包
conda list
2) 查看当前存在哪些虚拟环境
conda env list <br>conda info -e
3) 检查更新当前conda
conda update conda
3.Python创建虚拟环境
conda create -n your_env_name python=x.x
anaconda命令创建python版本为x.x,名字为your_env_name的虚拟环境。your_env_name文件可以在Anaconda安装目录envs文件下找到。
4.激活或者切换虚拟环境
打开命令行,输入python --version检查当前 python 版本。
Linux:source activate your_env_nam<br>Windows: activate your_env_name
5.对虚拟环境中安装额外的包
conda install -n your_env_name [package]
6.关闭虚拟环境
(即从当前环境退出返回使用PATH环境中的默认python版本)
deactivate env_name<br># 或者`activate root`切回root环境<br>Linux下:source deactivate
7.删除虚拟环境
conda remove -n your_env_name --all
8.删除环境钟的某个包
conda remove --name $your_env_name$package_name
9.设置国内镜像
http://Anaconda.org 的服务器在国外,安装多个packages时,conda下载的速度经常很慢。清华TUNA镜像源有Anaconda仓库的镜像,将其加入conda的配置即可:
# 添加Anaconda的TUNA镜像<br>conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/<br><br># 设置搜索时显示通道地址<br>conda config --set show_channel_urls yes
10.恢复默认镜像
conda config --remove-key channels
安装 PySpark
PySpark 的安装过程和其他 python 的包一样简单(例如 Pandas、Numpy、scikit-learn)。
一件重要的事情是,首先确保你的机器上已经安装了java。然后你可以在你的 jupyter notebook 上运行 PySpark。

探索数据
我们使用糖尿病数据集,它与美国国家糖尿病、消化和肾脏疾病研究所的糖尿病疾病有关。分类目标是预测患者是否患有糖尿病(是/否)。
from pyspark.sql import SparkSession<br>spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()<br>df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)<br>df.printSchema()
数据集由几个医学预测变量和一个目标变量 Outcome 组成。预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。
- Pregnancies:怀孕次数
- Glucose:2小时内口服葡萄糖耐量试验的血糖浓度
- BloodPressure:舒张压(mm Hg)
- SkinThickness:三头肌皮肤褶皱厚度(mm)
- Insulin:2小时血清胰岛素(mu U/ml)
- BMI:身体质量指数(体重单位kg/(身高单位m)²)
- diabespedigreefunction:糖尿病谱系功能
- Age:年龄(年)
- Outcome:类变量(0或1)
- 输入变量: 葡萄糖、血压、BMI、年龄、怀孕、胰岛素、皮肤厚度、糖尿病谱系函数。
- 输出变量: 结果。
看看前五个观察结果。Pandas 数据框比 Spark DataFrame.show() 更漂亮。
import pandas as pd<br>pd.DataFrame(df.take(5), <br> columns=df.columns).transpose()
在 PySpark 中,您可以使用 Pandas 的 DataFrame 显示数据 toPandas()。
df.toPandas()

检查类是完全平衡的!
df.groupby('Outcome').count().toPandas()

描述性统计
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']<br>df.select(numeric_features)<br>.describe()<br>.toPandas()<br>.transpose()
自变量之间的相关性
from pandas.plotting import scatter_matrix<br>numeric_data = df.select(numeric_features).toPandas()<br><br>axs = scatter_matrix(numeric_data, figsize=(8, 8));<br><br># Rotate axis labels and remove axis ticks<br>n = len(numeric_data.columns)<br>for i in range(n):<br>v = axs[i, 0]<br>v.yaxis.label.set_rotation(0)<br>v.yaxis.label.set_ha('right')<br>v.set_yticks(())<br>h = axs[n-1, i]<br>h.xaxis.label.set_rotation(90)<br>h.set_xticks(())

数据准备和特征工程
在这一部分中,我们将删除不必要的列并填充缺失值。最后,为机器学习模型选择特征。这些功能将分为训练和测试两部分。
缺失数据处理
from pyspark.sql.functions import isnull, when, count, col<br>df.select([count(when(isnull(c), c)).alias(c)<br> for c in df.columns]).show()
这个数据集很棒,没有任何缺失值。
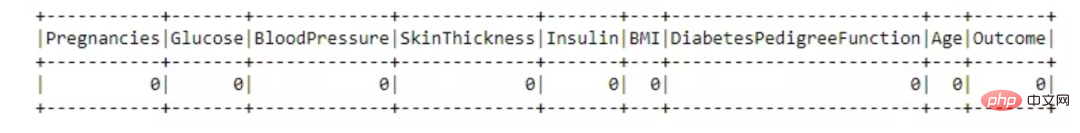
不必要的列丢弃
dataset = dataset.drop('SkinThickness')<br>dataset = dataset.drop('Insulin')<br>dataset = dataset.drop('DiabetesPedigreeFunction')<br>dataset = dataset.drop('Pregnancies')<br><br>dataset.show()

特征转换为向量
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性<br>required_features = ['Glucose',<br>'BloodPressure',<br>'BMI',<br>'Age']<br><br>from pyspark.ml.feature import VectorAssembler<br><br>assembler = VectorAssembler(<br>inputCols=required_features, <br>outputCol='features')<br><br>transformed_data = assembler.transform(dataset)<br>transformed_data.show()
现在特征转换为向量已完成。
训练和测试拆分
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)<br>print("训练数据集总数: " + str(training_data.count()))<br>print("测试数据集总数: " + str(test_data.count()))
训练数据集总数:620<br>测试数据集数量:148
机器学习模型构建
随机森林分类器
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier<br><br>rf = RandomForestClassifier(labelCol='Outcome', <br>featuresCol='features',<br>maxDepth=5)<br>model = rf.fit(training_data)<br>rf_predictions = model.transform(test_data)
评估随机森林分类器模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', metricName = 'accuracy')<br>print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))
Random Forest classifier Accuracy:0.79452
决策树分类器
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier<br><br>dt = DecisionTreeClassifier(featuresCol = 'features',<br>labelCol = 'Outcome',<br>maxDepth = 3)<br>dtModel = dt.fit(training_data)<br>dt_predictions = dtModel.transform(test_data)<br>dt_predictions.select('Glucose', 'BloodPressure', <br>'BMI', 'Age', 'Outcome').show(10)
评估决策树模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', <br>metricName = 'accuracy')<br>print('Decision Tree Accuracy:', <br>multi_evaluator.evaluate(dt_predictions))
Decision Tree Accuracy: 0.78767
逻辑回归模型
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression<br><br>lr = LogisticRegression(featuresCol = 'features', <br>labelCol = 'Outcome', <br>maxIter=10)<br>lrModel = lr.fit(training_data)<br>lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Logistic Regression Accuracy:', <br>multi_evaluator.evaluate(lr_predictions))
Logistic Regression Accuracy:0.78767
梯度提升树分类器模型
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier<br>gb = GBTClassifier(<br>labelCol = 'Outcome', <br>featuresCol = 'features')<br>gbModel = gb.fit(training_data)<br>gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Gradient-boosted Trees Accuracy:',<br>multi_evaluator.evaluate(gb_predictions))
Gradient-boosted Trees Accuracy:0.80137
结论
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。
以上是用 PySpark ML 构建机器学习模型的详细内容。更多信息请关注PHP中文网其他相关文章!


 软AI的兴起及其对当今企业的意义Apr 15, 2025 am 11:36 AM
软AI的兴起及其对当今企业的意义Apr 15, 2025 am 11:36 AM软AI(被定义为AI系统,旨在使用近似推理,模式识别和灵活的决策执行特定的狭窄任务 - 试图通过拥抱歧义来模仿类似人类的思维。 但是这对业务意味着什么
 为AI前沿的不断发展的安全框架Apr 15, 2025 am 11:34 AM
为AI前沿的不断发展的安全框架Apr 15, 2025 am 11:34 AM答案很明确 - 只是云计算需要向云本地安全工具转变,AI需要专门为AI独特需求而设计的新型安全解决方案。 云计算和安全课程的兴起 在
 生成AI的3种方法放大了企业家:当心平均值!Apr 15, 2025 am 11:33 AM
生成AI的3种方法放大了企业家:当心平均值!Apr 15, 2025 am 11:33 AM企业家,并使用AI和Generative AI来改善其业务。同时,重要的是要记住生成的AI,就像所有技术一样,都是一个放大器 - 使得伟大和平庸,更糟。严格的2024研究O
 Andrew Ng的新简短课程Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程Apr 15, 2025 am 11:32 AM解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 大语言模型(LLM)中的幻觉是不可避免的吗?Apr 15, 2025 am 11:31 AM
大语言模型(LLM)中的幻觉是不可避免的吗?Apr 15, 2025 am 11:31 AM大型语言模型(LLM)和不可避免的幻觉问题 您可能使用了诸如Chatgpt,Claude和Gemini之类的AI模型。 这些都是大型语言模型(LLM)的示例,在大规模文本数据集上训练的功能强大的AI系统
 60%的问题 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM
60%的问题 - AI搜索如何消耗您的流量Apr 15, 2025 am 11:28 AM最近的研究表明,根据行业和搜索类型,AI概述可能导致有机交通下降15-64%。这种根本性的变化导致营销人员重新考虑其在数字可见性方面的整个策略。 新的
 麻省理工学院媒体实验室将人类蓬勃发展成为AI R&D的核心Apr 15, 2025 am 11:26 AM
麻省理工学院媒体实验室将人类蓬勃发展成为AI R&D的核心Apr 15, 2025 am 11:26 AM埃隆大学(Elon University)想象的数字未来中心的最新报告对近300名全球技术专家进行了调查。由此产生的报告“ 2035年成为人类”,得出的结论是,大多数人担心AI系统加深的采用


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

记事本++7.3.1
好用且免费的代码编辑器

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

