
如何利用Node静态资源服务器
- php中世界最好的语言原创
- 2018-06-15 10:55:292427浏览
这次给大家带来如何利用Node静态资源服务器,Node静态资源服务器的注意事项有哪些,下面就是实战案例,一起来看一下。
http服务器是继承自tcp服务器 http协议是应用层协议,是基于TCP的
http的原理是对请求和响应进行了包装,当客户端连接上来之后先触发connection事件,然后可以多次发送请求,每次请求都会触发request事件
let server = http.createServer();
let url = require('url');
server.on('connection', function (socket) {
console.log('客户端连接 ');
});
server.on('request', function (req, res) {
let { pathname, query } = url.parse(req.url, true);
let result = [];
req.on('data', function (data) {
result.push(data);
});
req.on('end', function () {
let r = Buffer.concat(result);
res.end(r);
})
});
server.on('close', function (req, res) {
console.log('服务器关闭 ');
});
server.on('error', function (err) {
console.log('服务器错误 ');
});
server.listen(8080, function () {
console.log('server started at http://localhost:8080');
});
req 代表客户端的连接,server服务器把客户端的请求信息进行解析,然后放在req上面
res 代表响应,如果希望向客户端回应消息,需要通过 res
req和res都是从socket来的,先监听socket的data事件,然后等事件发生的时候,进行解析,解析出请头对象,再创建请求对象,再根据请求对象创建响应对象
req.url 获取请求路径
req.headers 请求头对象
接下来我们对一些核心功能进行讲解
深刻理解并实现压缩和解压
为什么要压缩呢?有什么好处?
可以使用zlib模块进行压缩及解压缩处理,压缩文件以后可以减少体积,加快传输速度和节约带宽代码
压缩和解压缩对象都是transform转换流,继承自duplex双工流即可读可写流
zlib.createGzip:返回Gzip流对象,使用Gzip算法对数据进行压缩处理
zlib.createGunzip:返回Gzip流对象,使用Gzip算法对压缩的数据进行解压缩处理
zlib.createDeflate:返回Deflate流对象,使用Deflate算法对数据进行压缩处理
zlib.createInflate:返回Deflate流对象,使用Deflate算法对数据进行解压缩处理
实现压缩和解压
因为压缩我文件可能很大也可能很小,所以为了提高处理速度,我们用流来实现
let fs = require("fs");
let path = require("path");
let zlib = require("zlib");
function gzip(src) {
fs
.createReadStream(src)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(src + ".gz"));
}
gzip(path.join(__dirname,'msg.txt'));
function gunzip(src) {
fs
.createReadStream(src)
.pipe(zlib.createGunzip())
.pipe(
fs.createWriteStream(path.join(__dirname, path.basename(src, ".gz")))
);
}
gunzip(path.join(__dirname, "msg.txt.gz"));
gzip方法用于实现压缩
gunzip方法用于实现解压
其中文件msg.txt是同级目录
为什么需要这么写:gzip(path.join(__dirname,'msg.txt'));
因为console.log(process.cwd());打印出当前工作目录是根目录,并不是文件所在目录,如果这么写gzip('msg.txt');找不到文件就会报错
basename 从一个路径中得到文件名,包括扩展名的,可以传一个扩展名参数,去掉扩展名
extname 获取扩展名
压缩的格式和解压的格式需要对上,否则会报错
有些时候我们拿到的字符串不是一个流,那怎么解决呢
let zlib=require('zlib');
let str='hello';
zlib.gzip(str,(err,buffer)=>{
console.log(buffer.length);
zlib.unzip(buffer,(err,data)=>{
console.log(data.toString());
})
});
有可能压缩后的内容比原来还大,要是内容太少的话,压缩也没什么意义了
文本压缩的效果会好一点,因为有规律
在http中应用压缩和解压
下面实现这样一个功能,如图:
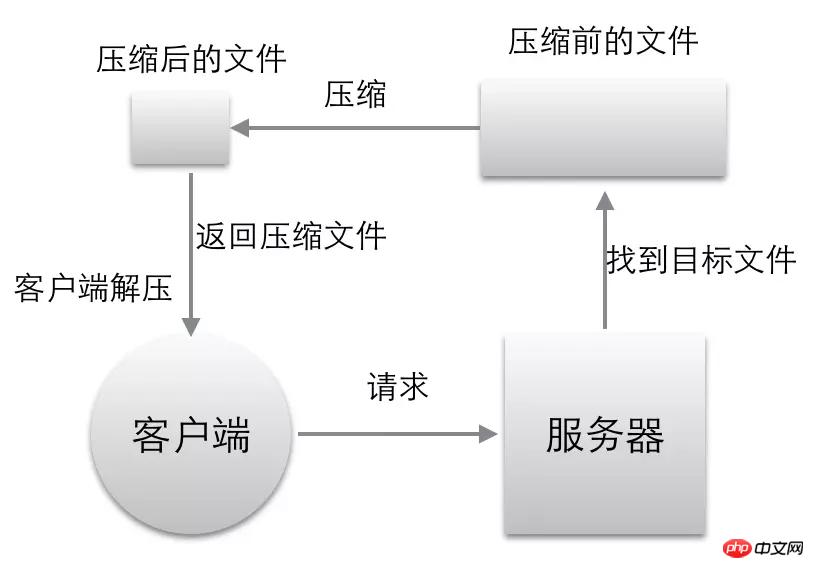
客户端向服务器发起请求的时候,会通过accept-encoding(比如:Accept-Encoding:gzip,default)告诉服务器我支持的解压缩的格式
服务器端需要根据Accept-Encoding显示的格式进行压缩,没有的格式就不能压缩,因为浏览器无法解压
如果客户端需要的Accept-Encoding中的格式服务端没有,也无法实现压缩
let http = require("http");
let path = require("path");
let url = require("url");
let zlib = require("zlib");
let fs = require("fs");
let { promisify } = require("util");
let mime = require("mime");
//把一个异步方法转成一个返回promise的方法
let stat = promisify(fs.stat);
http.createServer(request).listen(8080);
async function request(req, res) {
let { pathname } = url.parse(req.url);
let filepath = path.join(__dirname, pathname);
// fs.stat(filepath,(err,stat)=>{});现在不这么写了,异步的处理起来比较麻烦
try {
let statObj = await stat(filepath);
res.setHeader("Content-Type", mime.getType(pathname));
let acceptEncoding = req.headers["accept-encoding"];
if (acceptEncoding) {
if (acceptEncoding.match(/\bgzip\b/)) {
res.setHeader("Content-Encoding", "gzip");
fs
.createReadStream(filepath)
.pipe(zlib.createGzip())
.pipe(res);
} else if (acceptEncoding.match(/\bdeflate\b/)) {
res.setHeader("Content-Encoding", "deflate");
fs
.createReadStream(filepath)
.pipe(zlib.createDeflate())
.pipe(res);
} else {
fs.createReadStream(filepath).pipe(res);
}
} else {
fs.createReadStream(filepath).pipe(res);
}
} catch (e) {
res.statusCode = 404;
res.end("Not Found");
}
}
mime:通过文件的名称、路径拿到一个文件的内容类型, 可以根据不同的文件内容类型返回不同的Content-Type
acceptEncoding:全部写成小写是为了兼容不同的浏览器,node把所有的请求头全转成了小写
filepath:得到文件的绝对路径
启动服务后,访问http://localhost:8080/msg.txt 可看到结果
深刻理解并实现缓存
为什么要缓存呢,缓存有什么好处?
减少了冗余的数据传输,节省了网费。
减少了服务器的负担, 大大提高了网站的性能
加快了客户端加载网页的速度
缓存的分类
强制缓存:
强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据
在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中
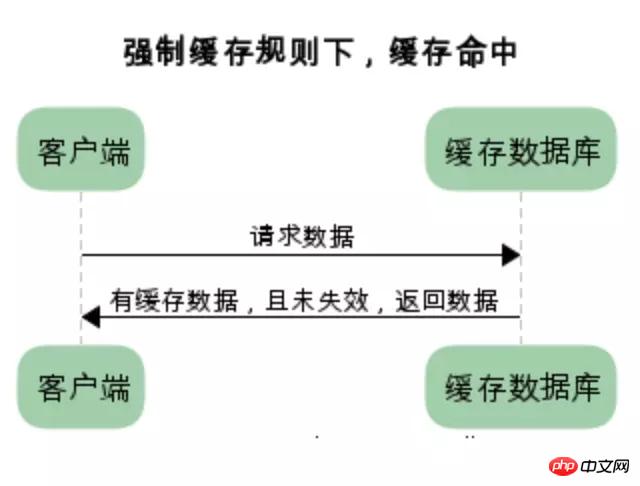
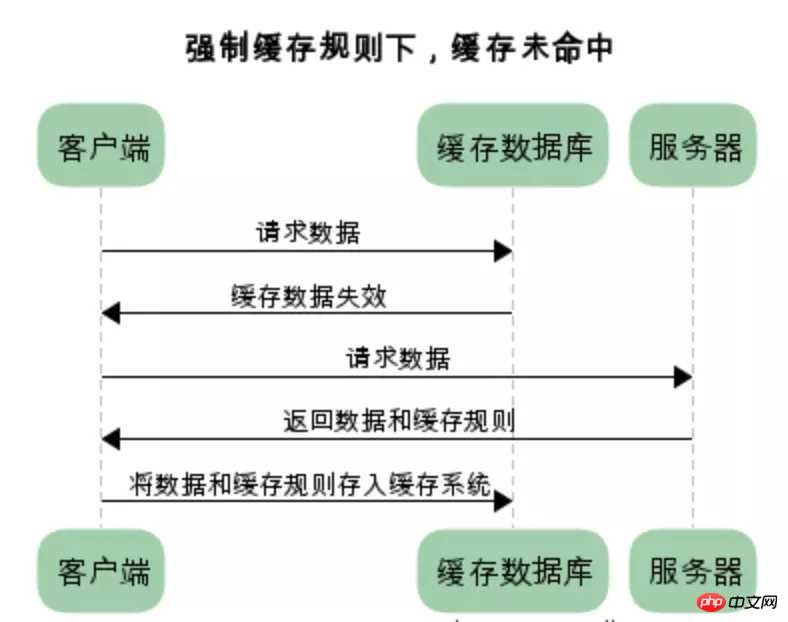
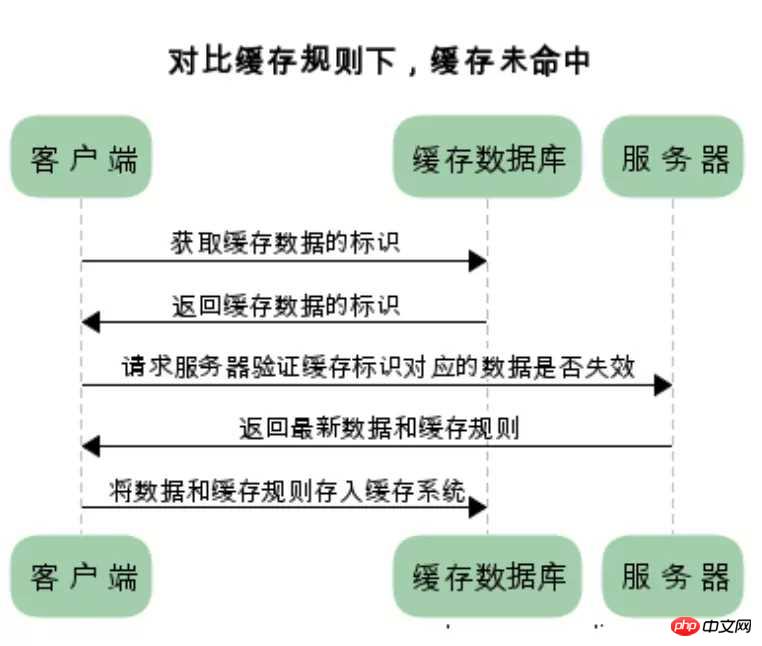
对比缓存:
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据
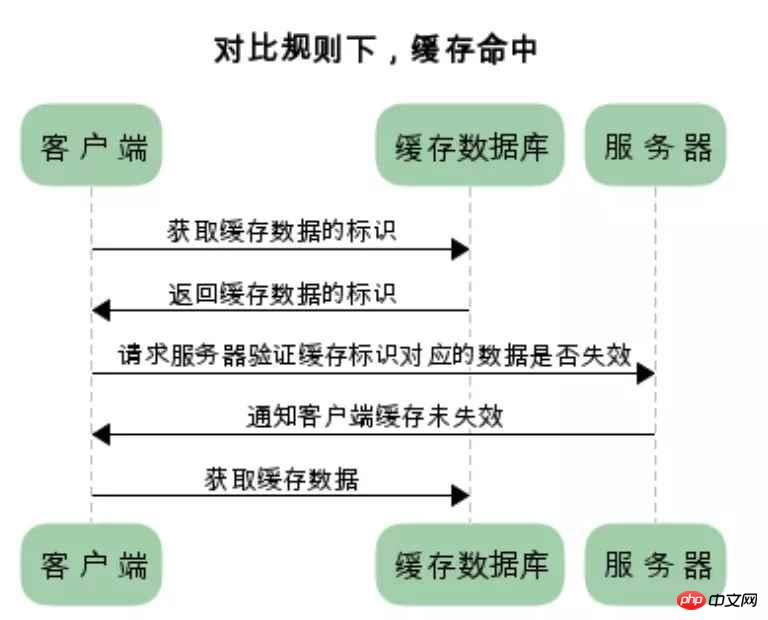
两类缓存的区别和联系
强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则
实现对比缓存
实现对比缓存一般是按照以下步骤:
第一次访问服务器的时候,服务器返回资源和缓存的标识,客户端则会把此资源缓存在本地的缓存数据库中。
第二次客户端需要此数据的时候,要取得缓存的标识,然后去问一下服务器我的资源是否是最新的。
如果是最新的则直接使用缓存数据,如果不是最新的则服务器返回新的资源和缓存规则,客户端根据缓存规则缓存新的数据
实现对比缓存一般有两种方式
通过最后修改时间来判断缓存是否可用
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
// http://localhost:8080/index.html
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
//D:\vipcode\201801\20.cache\index.html
let filepath = path.join(__dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifModifiedSince = req.headers['if-modified-since'];
let LastModified = stat.ctime.toGMTString();
if (ifModifiedSince == LastModified) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, stat);
}
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, stat) {
res.setHeader('Content-Type', mime.getType(filepath));
//发给客户端之后,客户端会把此时间保存起来,下次再获取此资源的时候会把这个时间再发回服务器
res.setHeader('Last-Modified', stat.ctime.toGMTString());
fs.createReadStream(filepath).pipe(res);
}
这种方式有很多缺陷
某些服务器不能精确得到文件的最后修改时间, 这样就无法通过最后修改时间来判断文件是否更新了
某些文件的修改非常频繁,在秒以下的时间内进行修改.Last-Modified只能精确到秒。
一些文件的最后修改时间改变了,但是内容并未改变。 我们不希望客户端认为这个文件修改了
如果同样的一个文件位于多个CDN服务器上的时候内容虽然一样,修改时间不一样
ETag
ETag是根据实体内容生成的一段hash字符串,可以标识资源的状态
资源发生改变时,ETag也随之发生变化。 ETag是Web服务端产生的,然后发给浏览器客户端
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(__dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifNoneMatch = req.headers['if-none-match'];
let out = fs.createReadStream(filepath);
let md5 = crypto.createHash('md5');
out.on('data', function (data) {
md5.update(data);
});
out.on('end', function () {
let etag = md5.digest('hex');
let etag = `${stat.size}`;
if (ifNoneMatch == etag) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, etag);
}
});
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, etag) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('ETag', etag);
fs.createReadStream(filepath).pipe(res);
}
客户端想判断缓存是否可用可以先获取缓存中文档的ETag,然后通过If-None-Match发送请求给Web服务器询问此缓存是否可用。
服务器收到请求,将服务器的中此文件的ETag,跟请求头中的If-None-Match相比较,如果值是一样的,说明缓存还是最新的,Web服务器将发送304 Not Modified响应码给客户端表示缓存未修改过,可以使用。
如果不一样则Web服务器将发送该文档的最新版本给浏览器客户端
实现强制缓存
把资源缓存在客户端,如果客户端再次需要此资源的时候,先获取到缓存中的数据,看是否过期,如果过期了。再请求服务器
如果没过期,则根本不需要向服务器确认,直接使用本地缓存即可
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(__dirname, pathname);
console.log(filepath);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
send(req, res, filepath);
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toUTCString());
res.setHeader('Cache-Control', 'max-age=30');
fs.createReadStream(filepath).pipe(res);
}
浏览器会将文件缓存到Cache目录,第二次请求时浏览器会先检查Cache目录下是否含有该文件,如果有,并且还没到Expires设置的时间,即文件还没有过期,那么此时浏览器将直接从Cache目录中读取文件,而不再发送请求
Expires是服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据,如果同时设置的话,其优先级高于Expires
下面开始写静态服务器
首先创建一个http服务,配置监听端口
let http = require('http');
let server = http.createServer();
server.on('request', this.request.bind(this));
server.listen(this.config.port, () => {
let url = `http://${this.config.host}:${this.config.port}`;
debug(`server started at ${chalk.green(url)}`);
});
下面写个静态文件服务器
先取到客户端想说的文件或文件夹路径,如果是目录的话,应该显示目录下面的文件列表
async request(req, res) {
let { pathname } = url.parse(req.url);
if (pathname == '/favicon.ico') {
return this.sendError('not found', req, res);
}
let filepath = path.join(this.config.root, pathname);
try {
let statObj = await stat(filepath);
if (statObj.isDirectory()) {
let files = await readdir(filepath);
files = files.map(file => ({
name: file,
url: path.join(pathname, file)
}));
let html = this.list({
title: pathname,
files
});
res.setHeader('Content-Type', 'text/html');
res.end(html);
} else {
this.sendFile(req, res, filepath, statObj);
}
} catch (e) {
debug(inspect(e));
this.sendError(e, req, res);
}
}
sendFile(req, res, filepath, statObj) {
if (this.handleCache(req, res, filepath, statObj)) return;
res.setHeader('Content-Type', mime.getType(filepath) + ';charset=utf-8');
let encoding = this.getEncoding(req, res);
let rs = this.getStream(req, res, filepath, statObj);
if (encoding) {
rs.pipe(encoding).pipe(res);
} else {
rs.pipe(res);
}
}
支持断点续传
getStream(req, res, filepath, statObj) {
let start = 0;
let end = statObj.size - 1;
let range = req.headers['range'];
if (range) {
res.setHeader('Accept-Range', 'bytes');
res.statusCode = 206;
let result = range.match(/bytes=(\d*)-(\d*)/);
if (result) {
start = isNaN(result[1]) ? start : parseInt(result[1]);
end = isNaN(result[2]) ? end : parseInt(result[2]) - 1;
}
}
return fs.createReadStream(filepath, {
start, end
});
}
支持对比缓存,通过etag的方式
handleCache(req, res, filepath, statObj) {
let ifModifiedSince = req.headers['if-modified-since'];
let isNoneMatch = req.headers['is-none-match'];
res.setHeader('Cache-Control', 'private,max-age=30');
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toGMTString());
let etag = statObj.size;
let lastModified = statObj.ctime.toGMTString();
res.setHeader('ETag', etag);
res.setHeader('Last-Modified', lastModified);
if (isNoneMatch && isNoneMatch != etag) {
return fasle;
}
if (ifModifiedSince && ifModifiedSince != lastModified) {
return fasle;
}
if (isNoneMatch || ifModifiedSince) {
res.writeHead(304);
res.end();
return true;
} else {
return false;
}
}
支持文件压缩
getEncoding(req, res) {
let acceptEncoding = req.headers['accept-encoding'];
if (/\bgzip\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'gzip');
return zlib.createGzip();
} else if (/\bdeflate\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'deflate');
return zlib.createDeflate();
} else {
return null;
}
}
编译模板,得到一个渲染的方法,然后传入实际数据数据就可以得到渲染后的HTML了
function list() {
let tmpl = fs.readFileSync(path.resolve(__dirname, 'template', 'list.html'), 'utf8');
return handlebars.compile(tmpl);
}
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
以上是如何利用Node静态资源服务器的详细内容。更多信息请关注PHP中文网其他相关文章!