



通过合并信息检索,检索增强的生成(RAG)赋予大型语言模型(LLMS)。这使LLM可以访问外部知识库,从而产生更准确,最新和上下文适当的响应。高级抹布技术矫正抹布(crag),通过引入自我反射和自我评估机制来进一步提高准确性。
关键学习目标
本文涵盖:
- CRAG的核心机制及其与Web搜索的集成。
- CRAG的文档相关性评估使用二进制评分和查询重写。
- 岩壁和传统抹布之间的关键区别。
- 使用Python,Langchain和Tavily实施动手CRAG实施。
- 配置评估人员,查询重写器和Web搜索工具的实用技能,以优化检索和响应准确性。
作为数据科学博客马拉松的一部分出版。
目录
- 克拉格的基本机制
- 岩壁与传统抹布
- 实用的crag实施
- 克拉格的挑战
- 结论
- 常见问题
克拉格的基本机制
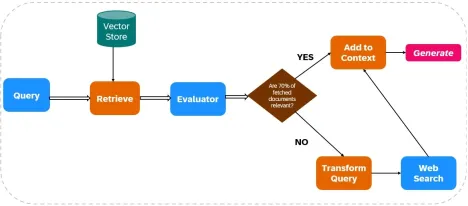
CRAG通过将Web搜索集成到其检索和生成过程中来增强LLM输出的可靠性(见图1)。
文件检索:
- 数据摄入:索引相关数据,并配置了Web搜索工具(例如Tavily AI)以实时数据检索。
- 初始检索:基于用户查询的静态知识库检索文档。
相关性评估:
评估者评估检索的文件相关性。如果超过70%的文件被视为无关紧要,则启动纠正措施;否则,响应产生将进行。
Web搜索集成:
如果文档相关性不足,则CRAG使用Web搜索:
- 查询细化:对原始查询进行了修改以优化Web搜索结果。
- Web搜索执行:诸如Tavily AI之类的工具获取其他数据,以确保访问当前和不同的信息。
响应生成:
CRAG从初始检索和Web搜索中综合数据,以创建一个连贯,准确的响应。
岩壁与传统抹布
与传统抹布不同,Crag会积极验证和完善检索到的信息,这与传统的抹布不同,这依赖于未经验证的文档检索。 CRAG经常合并实时的Web搜索,从而提供对最新信息的访问,这与传统抹布对静态知识库的依赖不同。这使得crag非常适合需要高精度和实时数据集成的应用程序。
实用的crag实施
本节详细介绍了使用Python,Langchain和Tavily的CRAG实施。
步骤1:库安装
安装必要的库:
! !
步骤2:API密钥配置
设置您的API键:
导入操作系统 os.environ [“ tavily_api_key”] =“” os.environ [“ openai_api_key”] =“”
步骤3:库导入
导入所需的库(省略了简短的代码,但类似于原始示例)。
步骤4:记录分块和猎犬的创建
(对于简短而省略了代码,但类似于原始示例,使用pypdfloader,递归cearsivecharactertextsplitter,openaiembeddings和Chroma)。
步骤5:抹布链设置
(对于简短而省略了代码,但类似于原始示例,使用hub.pull("rlm/rag-prompt")和ChatOpenAI )。
步骤6:评估器设置
(为简洁而省略了代码,但类似于原始示例,定义Evaluator类并使用ChatOpenAI进行评估)。
步骤7:查询重写器设置
(为简洁而省略了代码,但类似于原始示例,使用ChatOpenAI进行查询重写)。
步骤8:Web搜索设置
来自langchain_community.tools.tavily_search导入tavilySearchResults web_search_tool = tavilySearchResults(k = 3)
步骤9-12:Langgraph Workflow设置和执行
(为简短而省略了代码,但在概念上与原始示例相似,定义GraphState ,函数节点( retrieve , generate , evaluate_documents , transform_query , web_search ),并使用StateGraph进行连接。)最终输出和与传统抹布的比较也非常相似。
克拉格的挑战
CRAG的有效性在很大程度上取决于评估者的准确性。弱评估者可能会引入错误。可伸缩性和适应性也是关注点,需要持续更新和培训。 Web搜索集成引入了偏见或不可靠的信息的风险,需要强大的过滤机制。
结论
CRAG显着提高了LLM输出精度和可靠性。其评估和补充使用实时Web数据检索信息的能力使其对于要求高精度和最新信息的应用程序很有价值。但是,持续改进对于解决与评估者准确性和Web数据可靠性相关的挑战至关重要。
关键要点(类似于原始的,但为简洁而改写)
- CRAG使用Web搜索当前相关信息来增强LLM响应。
- 它的评估者确保了响应生成的高质量信息。
- 查询转换优化了Web搜索结果。
- 与传统的抹布不同,CRAG会动态整合实时网络数据。
- crag积极验证信息,减少错误。
- CRAG对需要高精度和实时数据的应用是有益的。
经常询问的问题(类似于原始问题,但为简洁而改写)
- Q1:什么是crag?答:高级抹布框架集成了Web搜索,以提高准确性和可靠性。
- Q2:岩壁与传统抹布?答:crag积极验证并完善检索到的信息。
- Q3:评估者的角色?答:评估文档相关性并触发更正。
- 问题4:文件不足?答:用网络搜索补充crag。
- Q5:处理不可靠的Web内容?答:需要高级过滤方法。
(注意:图像保持不变,并且如原始输入所示。)
以上是矫正抹布(crag)行动的详细内容。更多信息请关注PHP中文网其他相关文章!

 商业领袖生成引擎优化指南(GEO)May 03, 2025 am 11:14 AM
商业领袖生成引擎优化指南(GEO)May 03, 2025 am 11:14 AMGoogle正在领导这一转变。它的“ AI概述”功能已经为10亿用户提供服务,在任何人单击链接之前提供完整的答案。[^2] 其他球员也正在迅速获得地面。 Chatgpt,Microsoft Copilot和PE
 该初创公司正在使用AI代理来与恶意广告和模仿帐户进行战斗May 03, 2025 am 11:13 AM
该初创公司正在使用AI代理来与恶意广告和模仿帐户进行战斗May 03, 2025 am 11:13 AM2022年,他创立了社会工程防御初创公司Doppel,以此做到这一点。随着网络犯罪分子越来越高级的AI模型来涡轮增压,Doppel的AI系统帮助企业对其进行了大规模的对抗 - 更快,更快,
 世界模型如何从根本上重塑生成AI和LLM的未来May 03, 2025 am 11:12 AM
世界模型如何从根本上重塑生成AI和LLM的未来May 03, 2025 am 11:12 AM瞧,通过与合适的世界模型进行交互,可以实质上提高生成的AI和LLM。 让我们来谈谈。 对创新AI突破的这种分析是我正在进行的《福布斯》列的最新覆盖范围的一部分,包括
 2050年五月:我们要庆祝什么?May 03, 2025 am 11:11 AM
2050年五月:我们要庆祝什么?May 03, 2025 am 11:11 AM劳动节2050年。全国范围内的公园充满了享受传统烧烤的家庭,而怀旧游行则穿过城市街道。然而,庆祝活动现在具有像博物馆般的品质 - 历史重演而不是纪念C
 您从未听说过的DeepFake探测器准确是98%May 03, 2025 am 11:10 AM
您从未听说过的DeepFake探测器准确是98%May 03, 2025 am 11:10 AM为了帮助解决这一紧急且令人不安的趋势,在2025年2月的TEM期刊上进行了同行评审的文章,提供了有关该技术深击目前面对的最清晰,数据驱动的评估之一。 研究员
 量子人才战争:隐藏的危机威胁技术的下一个边界May 03, 2025 am 11:09 AM
量子人才战争:隐藏的危机威胁技术的下一个边界May 03, 2025 am 11:09 AM从大大减少制定新药所需的时间到创造更绿色的能源,企业将有巨大的机会打破新的地面。 不过,有一个很大的问题:严重缺乏技能的人
 原型:这些细菌可以产生电力May 03, 2025 am 11:08 AM
原型:这些细菌可以产生电力May 03, 2025 am 11:08 AM几年前,科学家发现某些类型的细菌似乎通过发电而不是吸收氧气而呼吸,但是它们是如何做到的,这是一个谜。一项发表在“杂志”杂志上的新研究确定了这种情况的发生方式:Microb
 AI和网络安全:新政府的100天估算May 03, 2025 am 11:07 AM
AI和网络安全:新政府的100天估算May 03, 2025 am 11:07 AM在本周的RSAC 2025会议上,Snyk举办了一个及时的小组,标题为“前100天:AI,Policy&Cybersecurity Collide如何相撞”,其中包括全明星阵容:前CISA董事Jen Easterly;妮可·珀洛斯(Nicole Perlroth),前记者和帕特纳(Partne)


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3 Linux新版
SublimeText3 Linux最新版

